Die Sache mit den Beziehungen – RM, ERM, OOM. Zerlegungen und Verknüpfungen in Datenmodellen (Version 11/2023)
| |
©2023 Josef L. Staud |
|
Autor: Josef L. Staud |
|
Stand: November 2023 |
|
Umfang des gedruckten Textes: ca. 40 Seiten |
|
Dieser Text richtet sich an die Teilnehmer meiner Seminare.
Geplanter Erscheinungstermin der Endfassung: 2024 |
|
Aufbereitung für's Web |
|
Diese HTML-Seiten wurden mithilfe eines von mir erstellten Programms erzeugt: WebGenerator2 (Version 2021). Es setzt Texte in HTML-Seiten um und ist noch in der Entwicklung. Die „maschinelle“ Erstellung erlaubt es, nach jeder Änderung des Textes diesen unmittelbar neu in HTML-Seiten umzusetzen. Da es nicht möglich ist, nach jeder Neuerstellung alle Seiten zu prüfen, ist es durchaus möglich, dass irgendwo auf einer „abgelegenen“ Seite Fehler auftreten. Ich bitte dafür um Verzeihung und um Hinweise (hs@staud.info). |
|
Die Veröffentlichung im Web erfolgt ab 2022 in zwei Versionen: Mit und ohne Frame-Technologien. Zu meinem Bedauern wird die Frame-Technologie inzwischen von den Verantwortlichen als unerwünscht angesehen und es häufen sich die Hinweise, dass bestimmte Browser Frame-basierte Seiten nicht mehr korrekt interpretieren können. Deshalb habe ich eine zweite Version meines Programms WebGenerator erstellt, die ohne Frames realisiert ist. |
|
Urheberrecht |
|
Dieser Text ist urheberrechtlich geschützt. Die dadurch begründeten Rechte, insbesondere die der Übersetzung, des Nachdrucks, des Vortrags, der Entnahme von Abbildungen und Tabellen oder der Vervielfältigung auf anderen Wegen und der Speicherung in Datenverarbeitungsanlagen, bleiben, auch bei nur auszugsweiser Verwertung, vorbehalten. Eine Vervielfältigung dieses Textes oder von Teilen dieses Textes ist auch im Einzelfall nur in den Grenzen der gesetzlichen Bestimmungen des Urheberrechtsgesetzes der Bundesrepublik Deutschland vom 9. September 1965 in der jeweils geltenden Fassung zulässig. Sie ist grundsätzlich vergütungspflichtig. Zuwiderhandlungen unterliegen den Strafbestimmungen des Urheberrechtsgesetzes. |
|
Warenzeichen und Markenschutz |
|
Alle in diesem Text genannten Gebrauchsnamen, Handelsnamen, Marken, Produktnamen, usw. unterliegen warenzeichen-, marken- oder patentrechtlichem Schutz bzw. sind Warenzeichen oder eingetragene Warenzeichen der jeweiligen Inhaber. Die Wiedergabe solcher Namen und Bezeichnungen in diesem Text berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Gesetzgebung zu Warenzeichen und Markenschutz als frei zu betrachten wären und daher von jedermann benutzt werden dürften. |
|
Didaktisch motivierte Beispiele |
|
Die hier vorgestellten didaktisch motivierten Modellierungsbeispiele dienen der Ausbildung, dem vertieften Erlernen und Einüben der jeweiligen Theorie und Methode, nichts anderem. |
|
Prof. Dr. Josef L. Staud |
|
|
|
Inhaltsverzeichnis der Druck- und PDF-Version |
|
1 Einführung.. 6 |
|
1.1 Um was geht es?. 6 |
|
1.2 Bezeichnung der Methodenelemente. 7 |
|
1.3 Semantik und Methode. 8 |
|
1.3.1 Die semantische Seite. 8 |
|
1.3.2 Methodische Seite. 8 |
|
1.4 Attribute auf Beziehungen. 8 |
|
2 Relationale Beziehungen.. 9 |
|
2.1 Lesehinweis. 9 |
|
2.2 Einstellig. 9 |
|
2.3 Zweistellig - 1:1. 10 |
|
2.4 Zweistellig - 1:n. 12 |
|
2.5 Zweistellig - N:m.. 14 |
|
2.6 Mehrstellig. 15 |
|
2.7 Muster Generalisierung/Spezialisierung. 15 |
|
2.8 Muster Aggregation. 16 |
|
2.9 Muster Komposition. 17 |
|
2.10 Muster Einzel/Typ. 18 |
|
3 Beziehungen in ER-Modellen.. 20 |
|
3.1 Lesehinweis. 20 |
|
3.2 Einstellig. 21 |
|
3.3 Zweistellig - 1:1. 22 |
|
3.4 Zweistellig - 1:n. 22 |
|
3.5 Zweistellig - n:m.. 23 |
|
3.6 Mehrstellig. 24 |
|
3.7 Muster Generalisierung/Spezialisierung. 25 |
|
3.8 Muster Aggregation. 26 |
|
3.9 Muster Komposition. 27 |
|
3.10 Muster Einzel/Typ. 28 |
|
4 Beziehungen in objektorientierten Modellen.. 29 |
|
4.1 Assoziationen. 29 |
|
4.2 Lesehinweis. 29 |
|
4.3 Einstellig. 30 |
|
4.4 Zweistellig - 1:1. 31 |
|
4.5 Zweistellig - 1:n. 32 |
|
4.6 Zweistellig - n:m.. 32 |
|
4.7 Mehrstellig. 33 |
|
4.8 Eigenschaften von Beziehungen. 34 |
|
4.9 Das Klassendiagramm als Ganzes. 35 |
|
4.10 Muster Generalisierung/Spezialisierung. 35 |
|
4.11 Muster Aggregation. 36 |
|
4.12 Muster Komposition. 37 |
|
4.13 Muster Einzel/Typ. 37 |
|
4.14 Das Zoo-Modell als Ganzes. 37 |
|
5 Literatur.. 39 |
|
|
|
Abkürzungsverzeichnis |
|
|
|
| DBS |
Datenbanksysteme |
| DV |
Datenverarbeitung |
| ERM |
Entity Relationship-Modellierung |
| fA |
Funktionale Abhängigkeit |
| FA-Diagramm |
Diagramm der funktionalen Abhängigkeiten |
| OODBS |
Objektorientiertes Datenbanksystem |
| OOM |
Objektorientierte Modellierung |
| PC |
Personal Computer |
| RDBS |
Relationales Datenbanksystem |
| RM |
Relationale Modellierung |
| |
|
|
1 Einführung |
|
1.1 Um was geht es? |
|
Am Anfang einer jeder Datenbank steht das Datenbankdesign und die Datenmodellierung. In allen dafür zur Verfügung stehenden Methoden kommt gleich nach der Festlegung der Basiselemente (Relationen, Entitätstypen, Klassen) die Frage nach den Beziehungen zwischen diesen. |
|
Meist sind diese semantisch fixiert, teilweise auch methodisch, v.a. bei den Relationen der relationalen Theorie. Die drei wichtigsten Gestaltungsvorschläge für Datenbanken sind derzeit die Folgenden: |
|
- Entity Relationship – Modellierung (ERM).
- Relationale Modellierung.
- Objektorientierte Modellierung.
|
|
Für diese drei wird in diesem Text die Umsetzung der Beziehungen dargestellt. Alle drei sind vollumfänglich attributbasiert . Sie beschreiben die Elemente des Anwendungsbereichs mit Attributen und auch die Beziehungen zwischen diesen werden mit Hilfe von Attributen realisiert. |
Attributbasiert |
Die ER-Modellierung gehört zum Bereich der Semantischen Datenmodellierung. Sie wird auch heute noch gern für einen ersten Modellierungsschritt genutzt, auf dem Weg vom Anwendungsbereich zur Datenbank. Die Beziehungen sind hier semantisch begründet. Sie werden hier und im Modell ausgedrückt. |
ERM |
Die relationale Modellierung setzt zum einen semantisch begründete Beziehungen um, zum anderen methodische. Der Grund ist, dass die Anwendung der relationalen Methode direkt zur Datenbank führt, weshalb die Beziehungen genauer erarbeitet werden müssen. |
RM – direkt zur Datenbank |
Die objektorientierte Modellierung führt zu Klassen und Beziehungen zwischen diesen, wie es in der UML 2.5 vorgeschlagen wird. Auch wenn dies dann die semantische Seite des Anwendungsbereichs recht gut beschreibt, muss es beim Einsatz eines Softwaresystems (objektorientierte Programmiersprache oder objektorientiertes Datenbanksystem) angepasst werden. |
OOM |
Warum überhaupt „Beziehungen“ |
|
Beim Datenbankdesign muss in der Phase der Datenmodellierung (des Schemaentwurfs) die zu verarbeitende Information des Anwendungsbereichs in semantisch und/oder methodisch sinnvolle Einheiten zerlegt werden. Diese müssen dann aber, weil sie ja denselben Anwendungsbereich betreffen, bei der Arbeit mit der Datenbank im weiteren auch wieder verknüpft werden (können). So kommt es zu den Beziehungen und Verknüpfungen im Datenmodell und in der Datenbank. |
|
Kardinalitäten |
|
Die Beziehungen können aufgrund der Wertigkeit der Teilnahme an der Beziehung in einfachster Form unterschieden werden in |
|
- Einstellige (rekursive)
- Zweistellige 1:1 – Beziehungen
- Zweistellige 1:n – Beziehungen
- Zweistellige n:m – Beziehungen
- Mehrstellige Beziehungen
|
|
Dabei stehen n und m für positive Zahlen größer Null. |
|
Min-/Max-Angaben |
|
Diese Kardinalitäten werden i.d.R. durch präzisere Angaben ergänzt (oder auch ersetzt), die jeweils die minimale und maximale Teilnahme an der Beziehung angeben. |
|
Eine Min-/Max-Angabe besteht immer aus zwei durch ein Komma (bei einigen Autoren auch durch Punkte, in der objektorientierten Theorie durch mehrere Punkte) getrennten Zahlen. Jede Beziehung hat zwei solche Angaben, die bei jeweils einem der beteiligten Basiselemente (Entitätstypen, Relationen, Klassen) stehen. Die zwei Werte halten dann fest, mit wie vielen Basiselementen minimal (erster Wert) und maximal (zweiter Wert) an der Beziehung teilgenommen wird. |
|
Liegt bei Min-/Max-Angaben eine feste Unter- oder Obergrenze vor, werden diese angegeben, also z.B. 11,14 (vgl. unten). Liegt keine feste Obergrenze vor, wird n oder m genommen, als ganzzahlige positive Werte größer 1. |
|
Zu beachten ist, dass der jeweils erste Wert einer Min-/Max-Angabe auch festlegt, ob die Basiselemente an der Beziehung teilhaben müssen oder nicht. Der Wert 0 signalisiert eine optionale Teilhabe, Werte größer Null eine Pflichteilnahme. In den nach der Modellierung entstehenden Datenbanken werden daraus optionale Felder oder Pflichtfelder. |
Pflicht oder Option |
Die Festlegung dieses ersten Werts der Min-/Max-Angaben ist nicht immer Ausdruck der realen Semantik, sondern oftmals Ausdruck des Wollens der Modellierer/innen. Nehmen wir als Beispiel die Beziehung PC / Angestellte in einer Unternehmensdatenbank. Der Wert 0 in der 0,m-Angabe könnte bedeuten, dass es die Möglichkeit geben soll, neu angeschaffte PC in der Datenbank zu erfassen, ohne ihnen gleich eine/n Angestellte/n zuzuordnen. Umgekehrt würde 1,m bedeuten, dass jeder neue angeschaffte PC beim Erfassen in der Datenbank gleich den für ihn geplanten Nutzer zugeordnet bekommt. |
|
Die Syntax der Notation ist in den drei Methoden leicht unterschiedlich, besteht aber immer aus einem minimalen und maximalen Wert für die eine und für die andere Seite. Bei mehr als zweistelligen Beziehungen entsprechend (vgl. unten). |
|
Bei zweistelligen Beziehungen sind für die Min-/Max-Angaben Werte möglich wie: |
|
|
1,1 : 1,1 (Pflichtteilnahme: Genau einer von „jeder Seite“ nimmt Teil)
|
|
|
0,1 : 1,1 (optionales Feld für die linke Seite)
|
|
|
1,1 : 0,1
|
|
|
0,1 : 0,1 (optionale Teilnahme für beide „Seiten“)
|
|
|
|
|
|
1,1 : 1,n (Pflichtteilnahme für beide „Seiten“, mindestens einer von der rechten Seite))
|
|
|
0,1 : 1,n
|
|
|
1,1 : 0,n
|
|
|
0,1 : 0,n
|
|
|
|
|
|
1,n : 1,m (Pflichtteilnahme für beide Seiten, jeweils mindestens einer)
|
|
|
0,n : 1,m
|
|
|
1,n : 0,m
|
|
|
0,n : 0,m
|
|
1.2 Bezeichnung der Methodenelemente |
|
Was die zu beschreibenden Elemente in der Datenmodellierung angeht, kann man einen Ausgangspunkt und drei Modellebenen unterscheiden. Der Ausgangspunkt ist der zu modellierende Anwendungsbereich, manchmal auch Weltausschnitt genannt. Die erste Modellebene ist die der Attribute, durch die Objekte und Beziehungen beschrieben werden. Die zweite die Ebene der Basiselemente im jeweiligen Ansatz (Relationen, Entitätstypen, Klassen). Die dritte Ebene die des gesamten Datenmodells. Um diesbezüglich im Text die Übersichtlichkeit zu erhöhen wird folgende typographische Festlegung getroffen: |
Überblick durch Typographie |
Anwendungsbereiche. Bezeichnungen von Anwendungsbereichen werden etwas vergrößert, in Kapitälchen und in Arial gesetzt: Hochschule, Personalwesen, WebShop. In der Web-Version sind sie zusätzlich in roter Farbe gehalten. |
|
Datenmodelle und Datenbanken. Bezeichnungen von Datenmodellen und Datenbanken sind in normaler Größe, fett und in Arial gesetzt: Vertrieb, Zoo, WebShop, Datenbanksysteme (Markt für Datenbanksysteme). In der Web-Version zusätzlich in rot. |
|
Relationen, Entitätstypen und Klassen. Bezeichnungen von Relationen, Entitätstypen und Klassen (Basiselemente) sind etwas verkleinert und in Arial gesetzt: Angestellte, Abteilungen, Projekte. In der Web-Version zusätzlich in rot. |
|
Attribute. Bezeichnungen von Attributen sind etwas verkleinert, fett und in Arial gesetzt: Gehalt, Name, Datum. Bei zusammengesetzten Benennungen wird der nachfolgende Begriff wieder groß begonnen: PersNr (Personalnummer), BezProj (Bezeichnung Projekt). |
|
Die kombinierte Angabe von Attributen und Relationen erfolgt wie üblich: Relationenbezeichnung.Attributsbezeichnung, also z.B. Angestellte.PersNr für das Attribut PersNr der Relation Angestellte. |
|
Ausprägungen von Attributen werden in normaler Größe und in Courier gesetzt, z.B. Brauer für das Attribut Name. |
|
Für die Basiselemente (Relationen, Entitätstypen, Klassen) wird bei der Bezeichnung immer die Mehrzahl gewählt, da ja in der Regel mehrere Objekte bzw. Beziehungen erfasst sind. |
|
1.3 Semantik und Methode |
|
1.3.1 Die semantische Seite |
|
Die Basis des Beziehungsgeschehens ist die Semantik des Anwendungsbereichs. Sie bestimmt zusammengehörige Attribute (in Relationen, Entitätstypen, Klassen), klärt also die „Zusammengehörigkeit von Information“ bzgl. der Informationsträger. Zusammengehörigkeit durch gemeinsame Attribute. Gehen wir aus vom Begriff Realweltphänomen und konzentrieren wir uns auf Attribute, kann die zentrale Regel des Datenbankdesigns so formuliert werden: |
|
Alle Realweltphänomene, die durch ein Attribut (oder mehrere) identifiziert und die durch weitere Attribute beschrieben werden, bilden ein Basiselement des Modells, das dann Entitätstyp, Relation oder Klasse genannt wird. |
|
So weit so klar. In Datenmodellen und später Datenbanken sind nun i.d.R. mehrere solche Basiselemente vorhanden, die - wie oben beschrieben - miteinander in Verbindung stehen,. Z.B. Kunden mit Rechnungen oder Kunden mit Adressen. |
|
Zu diesen kommen noch weitere Zerlegungs- und Verknüpfungsnotwendigkeiten dazu, die durch die Betrachtung semantischer Muster entstehen. Dies sind |
|
- die Generalisierung/Spezialisierung,
- die Aggregation,
- die Komposition,
- das Muster Einzel/Typ.
|
|
Diese werden unten betrachtet. |
|
1.3.2 Methodische Seite |
|
Dies betrifft v.a. die relationale Modellierung, da diese ja zu einem Datenmodell führen muss, das direkt mit Hilfe eines relationalen Datenbanksystems in eine Datenbank umgesetzt werden kann. |
|
Dafür müssen die Relationen (Tabellen!) in die von der relationalen Datenbanktheorie geforderte Form einer normalisierten flachen Tabelle gebracht werden. Dies führt meist zu Zerlegungen von Relationen und damit zu Beziehungen im Datenmodell. |
|
Der wichtigste Punkt dabei sind die Mehrfacheinträge. Diese führen im relationalen Datenbankdesign zur Auslagerung, zu einer eigenen Relation und damit zu einer Beziehung. |
|
Eine andere Quelle von Zerlegung und nachfolgender Beziehung sind Relationen, die wegen optionaler Beziehungen eingerichtet werden müssen. Vgl. [Staud 2021, Kapitel 5] sowie die Ausführungen und Beispiele unten. |
|
Weitere Zerlegungen ergeben sich durch die Normalisierungsschritte. Vgl. [Staud 2021, Kapitel 7 - 13]. |
|
1.4 Attribute auf Beziehungen |
|
Beziehungen können Attribute haben. Dies sind dann immer Attribute, die sich nicht den beteiligten Relationen / Entitätstypen / Klassen zuordnen lassen, sondern nur der Beziehung zwischen diesen. |
|
Nehmen wir als Beispiel Angestellte und Projekte sowie Projektmitarbeit als Beziehung, die festhält, wer in welchen Projekten mitarbeitet. Will man dabei den Beginn und das Ende der Projektmitarbeit festhalten, können diese Attribute (Beginn und Ende) nicht den Angestellten und auch nicht den Projekten zugeordnet werden, sondern nur der Beziehung Projektmitarbeit. |
|
2 Relationale Beziehungen |
|
Vgl. für eine umfassende Einführung in die relationale Modellierung [Staud 2021]. |
|
|
|
2.1 Lesehinweis |
|
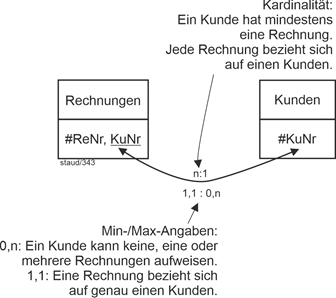
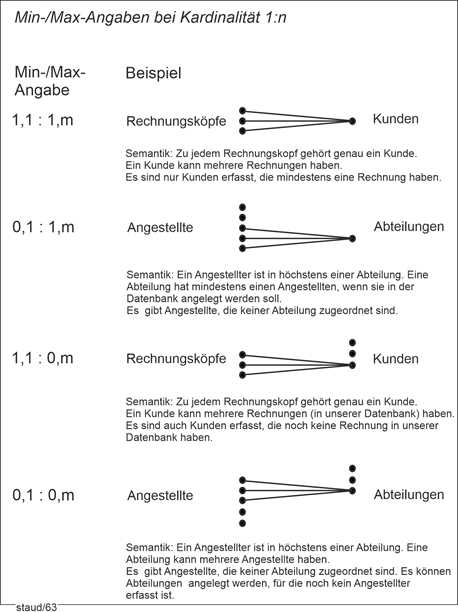
Zuerst ein Lesehinweis. Die Kardinalitäten und Min-/Max-Angaben werden immer für eine bestimmte Richtung angegeben. Entweder textlich oder durch eine Grafik. Die grafische Umsetzung zeigt die folgende Abbildung. |
|
In dieser soll gelten: Ein Kunde kann mehrere Rechnungen verursacht haben, eine Rechnung gehört zu einem Kunden. Die Null bei „0,n“ drückt aus, dass wir auch potentielle Kunden erfassen wollen, z.B. solche, die durch Werbeaktionen gewonnen wurden, bisher aber keine Rechnung erzeugt haben. |
|
|
|
Abbildung 2.1-1: Lesehinweis für Kardinalitäten und Min-/Max-Angaben bei zweistelligen relationalen Verknüpfungen |
|
ReNr: Rechnungsnummer; KuNr: Kundennummer |
|
2.2 Einstellige Beziehungen |
|
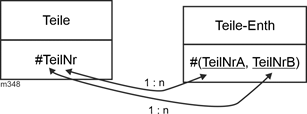
Betrachten wir als Beispiel eine Stückliste, die für (technische) Teile angibt, welche Teile ineinander enthalten sind. Eine Relation Teile beschreibt die Teile (z.B. von Fahrrädern), die rekursive Beziehung (das Enthaltensein) wird von der Relation Teile-Enth(alten) erfasst. |
|
|
|
Abbildung 2.2-1: Einstellige Beziehunge - Rekursive Aggregation |
|
Eine mögliche textliche Version: |
|
Teile-Enth (#(TeilNrA, TeilNrB), Anzahl) |
|
Teile (#TeilNr, TeilBez, Preis) |
|
Dieses Modellfragment kann wie folgt interpretiert werden: |
|
- Jedes Tupel in Teile-Enth gibt Enthaltensein an. Das Teil von TeilNrB ist enthalten im Teil von TeilNrA. Hier wurde angenommen, dass auch mehrere identische Teile enthalten sein können, deshalb das Attribut Anzahl in Teile-Enth.
- Ein Teil kann mehrfach als übergeordnetes Teil in Teile-Enth erscheinen.
- Ein Teil kann mehrfach als enthaltenes Teil in Teile-Enth erscheinen.
|
|
2.3 Zweistellige Beziehungen - 1:1 |
|
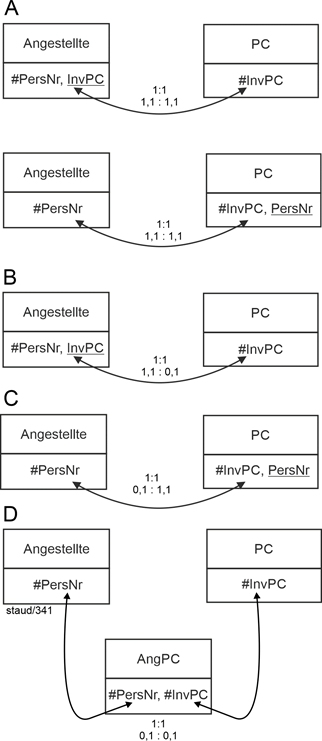
Die Kardinalität 1:1 bedeutet, dass von jeder Seite maximal 1 Tupel an der Beziehung teilnimmt. Die folgende Abbildung zeigt, wieviele Varianten dabei mit den Min-/Max-Angaben ausgedrückt werden können. |
|
A mit 1,1 : 1,1 |
|
A beschreibt beiderseitige Pflichtteilnahmen. Ein Angestellter bekommt in diesem Unternehmen genau einen PC zugewiesen. Dies kann methodentechnisch auf zwei unterschiedliche Weisen gelöst werden. Bei beiden muss der Schlüssel der einen Relation als Fremdschlüssel in die andere. Wegen der Forderung nach referentieller Integrität erzwingt diese Attributanordnung für jeweils eine Seite die Pflichtteilnahme. Für die andere nicht, dies muss auf andere Weise datenbanktechnisch abgesichert werden. |
|
Hier liegt also der Fall vor, dass eine durch die Semantik geforderte Eigenschaft durch die Modellierungsmethode nicht realisiert werden kann. Im ersten Fall kann es PC geben, die keiner Angestellten zugewiesen sind. Im zweiten Fall sind Angestellte möglich, denen kein PC zugewiesen ist. |
Methodendefizit |
B mit 1,1 : 0,1 |
|
In B ist für die linke Seite (Angestellte) Pflichtteilnahme mit maximal einem Objekt gefordert. Für die rechte Seite (PC) ist Optionalität vorgesehen. D.h., es ollen auch PC in der späteren Datenbank erfasst werden können, denen (noch) kein Angestellter zugewiesen ist. Dies wird durch den Fremdschlüssel InvPC in Angestellte realisiert. |
|
C mit 0,1 : 1,1 |
|
In C ist für die linke Seite (Angestellte) Optionalität vorgesehen: Ein Angestellter hat keinen oder maximal einen zugewiesenen PC. Für die rechte Seite (PC) ist dagegen Pflichtteilnahme gefordert. Jeder PC wird beim Erfassen für die Datenbank gleich einer Person zugewiesen. Dies wird durch den Fremdschlüssel PersNr in PC realisiert. |
|
D mit 0,1 : 0,1 |
|
In D ist auf beiden Seiten Optionalität vorgesehen: Ein Angestellter hat keinen oder maximal einen zugewiesenen PC, einem PC ist kein oder maximal ein Angestellter zugewiesen. Damit fallen obige Lösungen mit Fremdschlüsseln weg. Notwendig ist hier eine neue Relation, sie wird AngPC genannt. |
|
Diese Lösung macht oft Probleme beim Erkennen, Umsetzen und Akzeptieren, deshalb ein paar Erläuterungen: |
|
- Jedes Tupel drückt eine Beziehung zwischen Angestellten und PC aus. Damit entspricht diese Lösung der relationalen Philosophie: in einem Tupel wird „flach“ eine Beziehung ausgedrückt.
- Da nur wirklich existierende Beziehungen erfasst werden und da es sich um die Kardinalität 1:1 handelt, ist PersNr alleine(!) Schlüssel von AngPC, genauso wie InvPC!
|
|
Die Relation AngPC ist also keine Verbindungsrelation wie sie bei n:m-Kardinalitäten notwendig werden. |
|
|
|
Abbildung 2.3-1: Kardinalität 1:1 mit möglichen Min-/Max-Angaben |
|
Die folgende Abbildung veranschaulicht die für die Kardinalität 1:1 möglichen Verknüpfungsarten mengentechnisch. Es verdeutlicht insbesondere die Teilnahme bzw. Nichtteilnahme an der Beziehung und gibt damit Hinweise auf die Gestaltung der späteren grafischen Bedienoberfläche (GUI). |
|

|
|
Abbildung 2.3-2: Mengentechnische Ausrichtung relationaler 1:1-Verknüpfungen |
|
2.4 Zweistellige Beziehungen - 1:n |
|
Die Kardinalität 1:n bedeutet, dass von „der einen Seite“ keiner, einer oder mehrere an der Verknüpfung teilhaben, von der anderen Seite keiner oder einer. |
|
Die folgende Abbildung zeigt, wieviele Varianten dabei mit den Min-/Max-Angaben ausgedrückt werden können. |
|
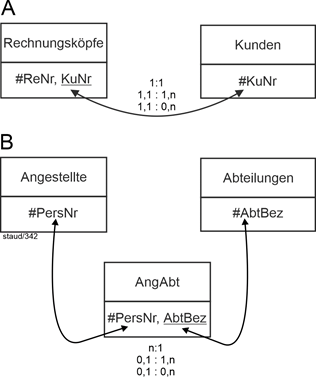
A mit 1,1 : 1,n oder 1,1 : 0,n |
|
A beschreibt folgende Situation: Ein Rechnungskopf bezieht sich immer auf genau einen Kunden. KuNr ist hier Fremdschlüssel und (später) ein Pflichtfeld. |
|
Für Kunden gilt: Ein Kunde kann mit mehreren Rechnungen und damit Rechnungsköpfen in Verbindung stehen. 1,n beschreibt die Situation, dass nur Kunden in die Datenbank kommen, die tatsächlich schon mal gekauft haben. 0,n dagen die Möglichkeit, auch Kunden zu erfassen, die noch nicht gekauft haben, die also potentielle Kunden sind. |
|
B mit 0,1 : 1,n oder 0,1 : 0,n |
|
Die allgemeine durch die Kardinalität ausgedrückte Semantik in B ist so, dass ein/e Angestellte/r zu einer Abteilung gehört und eine Abteilung mehrere Angestellte haben kann. |
|
Hier ist für die linke Seite (Angestellte) in allen Fällen nur eine optionale Teilnahme gefordert. Es gibt also Angestellte, die keiner Abteilung zugewiesen sind. Dies verbietet einen Fremdschlüssel AbtBez in Angestellte. Die Verknüpfung kann aber auch nicht durch einen Fremdschlüssel PersNr in Abteilungen realisiert werden, denn dies würde zu Mehrfacheinträgen führen. |
|
Damit bleibt nur eine neue Relation, die diese Verknüpfung ausdrückt. Sie soll AngAbt genannt werden und hat den Schlüssel #PersNr sowie den Fremdschlüssel AbtBez. |
|
Dies ist einer der seltenen Fälle, wo es methodenbedingt zwei unterschiedliche Relationen mit gleichem Schlüssel gibt. |
|
Der Fall 0,1 : 0,n wird damit auch abgedeckt, so dass man auch Abteilungen erfassen kann, denen (noch) keine Person zugeordnet ist. |
|
|
|
Abbildung 2.4-1: Kardinalität 1:n mit möglichen Min-/Max-Angaben |
|
Die folgende Abbildung veranschaulicht die für die Kardinalität 1:n möglichen mengentechnischen Verknüpfungsarten visuell. Es verdeutlicht insbesondere die Teilnahme bzw. Nichtteilnahme an der Beziehung und gibt damit Hinweise auf die Gestaltung der späteren grafischen Bedienoberfläche (GUI). |
|
|
|
Abbildung 2.4-2: Mengentechnische Ausrichtung relationaler 1:n-Verknüpfungen |
|
2.5 Zweistellige Beziehungen - N:m |
|
Die Kardinalität n:m bedeutet, dass von beiden beteiligten Relationen mehrere Tupel an der Beziehung teilhaben können. Dies erfordert eine neue Relation mit einem zusammengesetztem Schlüssel, dessen Schlüsselattribute den Primärschlüsseln der beteiligten Relationen entsprechen und die in der neuen Relation Fremdschlüssel sind. Sie wird Verbindungsrelationgenannt. |
|
Betrachten wir als Beispiel die Beziehung zwischen Angestellte und Adressen. Die Semantik soll so sein: |
|
- Ein Projekt kann mehrere zugewiesene Angestellte haben.
- Ein/e Angestellte/r kann in mehreren Projekten mitarbeiten.
|
|
Wir nehmen auch gleich die optionalen Beziehungen mit auf: |
|
- Es gibt Angestellte, die in keinem Projekt mitarbeiten.
- Es gibt Projekte, denen noch kein/e Angestellte/r zugewiesen ist. Z.B. nach der datenbanktechnischen Einrichtung und vor der Personalklärung.
|
|
Damit sind für die Kardinalität n:m die in der folgenden Abbildung angeführten Min-/Max-Angaben möglich. Für alle kann dieselbe relationentechnische Lösung gewählt werden. |
|
|
|
Abbildung 2.5-1: Kardinalität n:m mit möglichen Min-/Max-Angaben |
|
Will man Pflichtteilnahmen realisieren, z.B. indem man fordert, |
|
|
„datenbanktechnisch kein Projekt ohne wenigstens die Projektleitung“,
|
|
muss man dies dann mit Hilfe des Datenbanksystems realisieren, meist bei der Gestaltung der grafischen Bedienoberfläche. |
|
2.6 Mehrstellige Beziehungen |
|
Mehrstellige Beziehungen werden in einer Relation mit den Schlüsseln der beteiligten Relationen erfasst. Dann drückt jedes Tupel eine Beziehung aus. Sind also R1, R2 und R3 drei Relationen, die zu verknüpfen sind und #KeyR1, #KeyR2, #KeyR3 die zugehörigen Schlüssel, hätte die mehrstellige Relation R1-R2-R3 folgenden Aufbau: |
|
R1-R2-R3 (#(KeyR1, KeyR2, KeyR3)) |
|
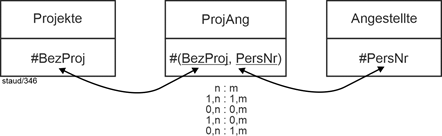
Im folgenden Beispiel (Ausschnitt eines größeren Datenmodells) hat ein Kunde mehrere Adressen und er lässt sich die Rechnungen mal für die eine, mal für die andere Adresse ausstellen. Es gibt also eine dreistellige Beziehung zwischen Kunden, Adressen und Rechnungsköpfen (ReKöpfe). Vgl. die folgende Abbildung für die grafische Darstellung: |
Beispiel |
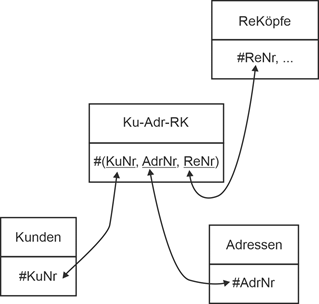
|
|
Abbildung 2.6-1: Mehrstellige Beziehung Kunden / Adressen / Rechnungsköpfe |
|
ReKöpfe: Rechnungsköpfe |
|
2.7 Muster Generalisierung/Spezialisierung |
|
Auch die Umsetzung einer Generalisierung/Spezialisierung führt beim relationalen Design zu Zerlegungen und Verknüpfungen. |
|
Jede Spezialisierung erhält denselben Schlüssel wie die Generalisierung und die spezifischen Attribute. Die wichtigste Besonderheit ist, dass die Menge der Schlüsselausprägungen in der Spezialisierung eine Teilmenge der Schlüsselausprägungen in der Generalisierung ist. |
|
Falls eine Verknüpfung notwendig ist, falls z.B. die Daten der Spezialisierung ergänzt werden sollen um die/einige der Generalisierung, geschieht dies über einen Join mit Hilfe der Schlüssel. |
|
Beispiel |
|
Angestellte (#PersNr, Name, Vorname, …) |
|
Entwickler (#PersNr, EntwUmg, ProgSpr, …) |
|
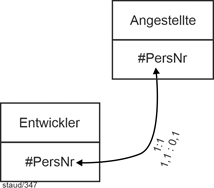
|
|
Abbildung 2.7-1: Generalisierung / Spezialisierung in grafischer Notation |
|
EntwUmg: Entwicklungsumgebung, ProgSpr: Programmiersprache |
|
2.8 Muster Aggregation |
|
Auch Aggregationen erfordern methodenbedingt eine Zerlegung und damit später u.U. eine Verknüpfung. Nehmen wir Objekt und Komponente als Begriffe für die hier in Beziehungen stehenden Informationsträger. Liegt eine Aggregation vor, ist also die Komponente im Objekt enthalten und hat die Komponente eine eigenständige Existenz auch ohne das Objekt, muss dies mit der relationalen Theorie wie folgt gelöst werden: |
|
- Ausgehend vom Schlüssel der Objekte (#ObjektId; Objektidentifikation) erhalten die Komponenten nicht nur einen Schlüssel, eine #KompID (Komponentenidentifikation), sondern auch die ObjektId als Fremdschlüssel. Dabei muss aber jeder Komponente zu jedem Zeitpunkt ein Objekt zugewiesen sein:
|
|
Objekte (#ObjektId, …) |
|
Komponenten (#KompId, …, ObjektId) |
|
- Will man die Komponenten auch ohne Bezug zu einem Objekt datentechnisch verwalten, muss man für die Beziehung eine eigene Relation ObjektKomp einrichten, die den Zusammenhang zwischen Objekten und Komponenten erfasst:
|
|
Objekte (#ObjektId, …) |
|
ObjektKomp (#(ObjektId, KompId)) |
|
Komponenten (#KompId, …) |
|
Beispiel PC |
|
Betrachten wir als Beispiel Personal Computer (PC) und ihre „eigenständigen“ Komponenten, also z.B. Grafikkarten, Speicherbausteine, WLAN-Komponenten, usw. Dann macht eine Aggregation die Aufteilung in PC und Komponenten nötig. Z.B. so: |
|
PC (#InvNrPC, Proz, ArbSp) |
|
Komponenten (#InvNrKomp, Bez, Funktion, InvNrPC) |
|
Die folgende Abbildung gibt neben der grafischen Notation auch die Kardinalität und die möglichen Min-/Max-Angaben an. |
|
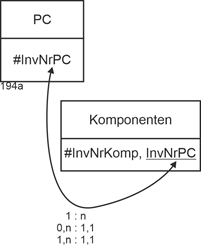
|
|
Abbildung 2.8-1: Muster Aggregation mit Pflichtteilhabe |
|
InvNr: Inventarnummer |
|
PC: Personal Computer |
|
Komp: Komponente |
|
Hier muss die Komponente zu jedem Zeitpunkt (irgend) einem PC zugewiesen sein. Für den Fall, dass die Verknüpfung optional gehalten werden soll, muss für die Verknüpfung eine eigene Relation PCKomp eingerichtet werden. Dann ergeben sich folgende Relationen: |
|
PC (#InvNrPC, Proz, ArbSp) |
|
Komponenten (#InvNrKomp, Bez, Funktion) |
|
PCKomp (#InvNrKomp, InvNrPC) |
|
Bez: Bezeichnung |
|
Proz: Prozessor |
|
ArbSp: Arbeitsspeicher (Größe) |
|
Funktion: Aufgabe der Komponente |
|
Die Min-/Max-Angaben von PC über PCKomp zu Komponenten sind 0,n : 0,1. |
|
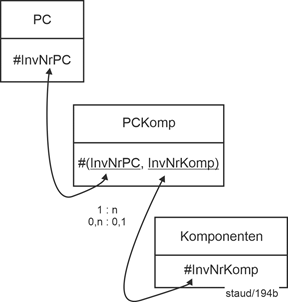
|
|
Abbildung 2.8-2: Muster Aggregation mit optionaler Teilhabe |
|
2.9 Muster Komposition |
|
Verlangt die Semantik einen besonders engen Zusammenhang zwischen Objekt und Teil in Form einer umfassenden Existenzabhängigkeit (in der objektorientierten Theorie Komposition genannt) wird dies in der relationalen Theorie wie folgt ausgedrückt: |
Existenzabhängigkeit |
Der Schlüssel der Objekte wird zu einem Teil des Schlüssels der Teile. Durch die Einbindung in den Teile-Schlüssel kann es dann dort kein Tupel ohne Verweis auf das jeweilige Objekt geben. |
|
Die Min-/Max-Angaben müssen dann bei den Teilen 1,1 sein. Dadurch wird a) die Verknüpfung gesichert und b) garantiert, dass es keine Mehrwertigkeit gibt. |
|
Beispiel Rechnung |
|
Ein Beispiel ist die Verknüpfung von Rechnungsköpfen (RechKöpfe) und Rechnungspositionen (RechPos). Rechnungspositionen kann es nicht ohne zugehörige Rechnungsköpfe geben. Die Lösung für die Umsetzung der Komposition ist wie folgt: |
|
RechKöpfe (#ReNr, …) |
|
RechPos (#(ReNr, PosNr), …) |
|
ReNr in RechPos ist Fremdschlüssel und leistet die Verknüpfung mit RechKöpfe. Damit ist die Kardinalität 1:n festgelegt: Ein Wert von ReNr in RechKöpfe kommt mindestens einmal im Schlüssel von RechPos vor. Ein Wert von ReNr in RechPos kommt genau einmal in ReNr von RechKöpfe vor. Dies drücken dann auch die Min-/Max-Angaben 1,1 : 1,n aus. |
|
Die Existenzabhängigkeit drückt sich darin aus, dass jede Rechnungsposition den Verweis auf einen Rechnungskopf benötigt, weil die ReNr Teil des Schlüssels von RechPos ist und nach der relationalen Theorie ein Schlüssel (natürlich) immer vollständig sein muss. Umgekehrt gilt: Wird ein bestimmter Rechnungskopf gelöscht, müssen auch die existenzabhängigen Rechnungspositionen gelöscht werden. Falls nicht, entsteht ein Beitrag zur sog. Stammdatenkrise. |
|
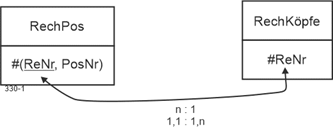
|
|
Abbildung 2.9-1: Existenzabhängigkeit (Komposition) in relationalen Datenmodellen |
|
RechKöpfe: Rechnungsköpfe |
|
RechPos: Rechnungspositionen |
|
PosNr: Positionsnummer |
|
Verknüpfung |
|
Müssen die Rechnungsköpfe und -positionen verknüpft werden, geschieht dies einfach durch einen Join über das Attribut ReNr. |
|
2.10 Muster Einzel/Typ |
|
Auch für die Erfassung des Musters Einzel/Typ ist im Designprozess eine Zerlegung und später u.U. eine Verknüpfung nötig. Die Zerlegung ist notwendig, weil die „Typattribute“ andere sind als die „Einzelattribute“. Die Relation mit den „Einzelattributen“ erhält dann den Schlüssel der Relation mit den „Typattributen“ als Fremdschlüssel. Damit ist der Zusammenhang festgelegt und die evtl. notwendige Verknüpfung von Einzel- und Typinformation (Join über „Typ-Schlüssel“ und „Einzel-Fremdschlüssel“) vorbereitet. Die Kardinalität ist, von Typ zu Einzel, 1:n. Die Min-/Max-Angaben ergeben sich zu 1,m : 1,1. |
|
Beispiel Tiere und Tiergattung |
|
Tiergattungen (z.B. in einem Zoo) können vereinfacht so erfasst werden: |
|
Tiere-Gattung (#BezGatt, Anzahl, DuAlter) |
|
BezGatt : Bezeichnung der Gattung |
|
DuAlter : Durchschnitt der Tiere der jeweiligen Gattung, also Z.B. das durchschnittliche Alter der afrikanischen Elefanten. |
|
Die einzelnen Tiere könnten so erfasst werden : |
|
Tiere-Einzeln (#TNr, Name, BezGatt, GebTag, Geschlecht) |
|
TNr: identifizierende Nummer für die Tiere; GebTag: Geburtstag |
|
Das Attribut BezGatt realisiert, als Schlüssel und Fremdschlüssel, die relationale Verknüpfung zwischen den beiden Relationen und hält somit fest, zu welcher Gattung ein einzelnes Tier gehört. Die Kardinalitäten und Min-/Max-Angaben sind von Tiere-Einzeln zu Tiere-Gattung wie folgt: n:1 bzw. 1,1 : 1,m. |
|
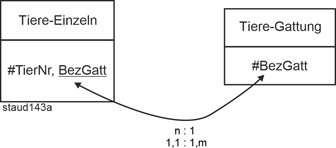
|
|
Abbildung 2.10-1: Muster Einzel/Typ in grafischer Notation |
|
Verknüpfung |
|
Eine Verknüpfung kann mit Hilfe eines Joins über die Gattungsbezeichnung dienen. |
|
3 Beziehungen in ER-Modellen |
|
Vgl. für eine Einführung in die ER-Modellierung: |
|
http://www.staud.info/erm1/er_f_1.htm |
|
|
|
3.1 Lesehinweis |
|
Beziehungen werden in ER-Modellen durch ein eigenes Modellelement, den Beziehungstyp dargestellt, der mit den zu verknüpfenden Entitätstypen durch Linien verbunden ist. Außerdem ist bei den betroffenen Entitätstypen und Linien angeben, wieviele Entitäten jeweils an der Beziehung teilhaben. Die folgenden zwei Abbildungen zeigen Beispiele für Kardinalitäten und Min-/Max-Angaben. |
|
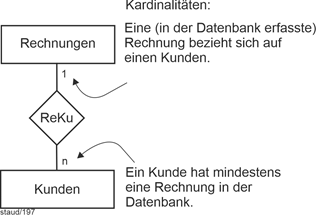
|
|
Abbildung 3.1-1: Lesehinweis für Kardinalitäten bei zweistelligen Verknüpfungen in ER-Modellen |
|
Es ist hier also so, dass die Zahl beim Entitätstyp angibt, mit wievielen Entitäten der „anderen Seite“ die Beziehung bestehen kann. Entsprechend bei Min-/Max-Angaben. Auch hier stehen die möglichen Werte beim Entitätstyp, allerdings mit größerer Präzision. Angegeben ist jeweils die minimale und maximale Teilhabe. |
|
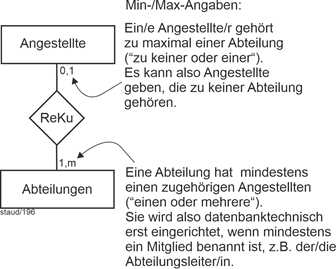
|
|
Abbildung 3.1-2: Lesehinweis für Min-/Max-Angaben bei zweistelligen Verknüpfungen in ER-Modellen |
|
Bei den Min-/Max-Angaben können auch Pflichtteilnahme und optionale Teilnahme festgelegt werden, die später bei der grafischen Bedienoberfläche zu optionalen Feldern bzw. Pflichtfeldern führen. Immer wenn der erste Wert 0 ist, handelt es sich um eine optionale Teilhabe. |
|
3.2 Einstellige Beziehungen |
|
Rekursive Beziehungen |
|
Rekursive Beziehungen werden in der ER-Modellierung wie in der folgenden Abbildung ausgedrückt. |
|
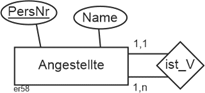
|
|
Abbildung 3.2-1: Rekursive Beziehungen in ER-Modellen |
|
PersNr: Personalnummer |
|
Dabei werden die Entitäten eines Entitätstyps mit Hilfe von Min-/Max-Angaben in Beziehung gebracht. Die Min-/Max-Angaben in obiger Abbildung drücken aus, dass jeder Angestellte genau einen Vorgesetzten hat und ein Vorgesetzter mindestens einen Untergebenen. |
|
3.3 Zweistellige Beziehungen - 1:1 |
|
Kardinalitäten und Min-/Max-Angaben |
|
In den folgenden Beispielen sind Kardinalitäten und mehrere Min-/Max-Angaben oftmals zusammen angegeben. In einer konkreten Modellierungssituation wäre jeweils nur eine einzige Min-/Max-Angabe sinnvoll. |
|
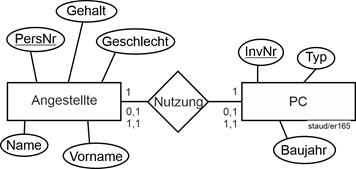
|
|
Abbildung 3.3-1: Kardinalität 1:1 und damit mögliche Min-/Max-Angaben |
|
Obige Werte: Kardinalitäten |
|
Untenstehende Werte: mögliche Min-/Max-Angaben |
|
Somit gibt es vier Konkretisierungen der Kardinalität: |
|
|
0,1 : 0,1
|
|
|
1,1 : 0,1
|
|
|
0,1 : 1,1
|
|
|
1,1 : 1,1
|
|
Hinweis: Die Angabe mehrerer Min-/Max-Angaben, wie in der obigen Abbildung, ist in der konkreten Modellierung nicht üblich. Sie soll hier in kompakter Form alle Möglichkeiten aufzeigen. |
|
3.4 Zweistellige Beziehungen - 1:n |
|
Kardinalitäten und Min-/Max-Angaben |
|
Die folgende Abbildung zeigt ein Beispiel für die Kardinalität 1:m. Es geht um Abteilungszugehörigkeit (AngAbt). Für diese gilt üblicherweise: Ein/e Angestellte/r ist einer Abteilung zugeordnet, eine Abteilung hat mehrere Angestellte. Dies wird in der Kardinalität 1:m ausgedrückt. |
|
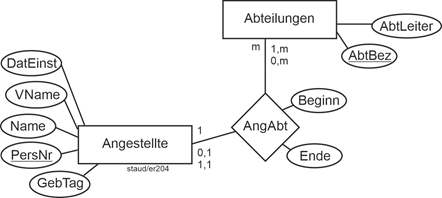
|
|
Abbildung 3.4-1: Kardinalität 1:n und damit mögliche Min-/Max-Angaben |
|
Bei den Min-/Max-Angaben sind wieder alle denkbaren Varianten angegeben. Die optionalen bedeuten: |
|
- 0,1 bei Angestellte: Es gibt auch Personen, die keiner Abteilung zugeordnet sind
- 0,m bei Abteilungen: Es soll eine Abteilung datenbanktechnisch auch angelegt werden können, wenn noch kein Abteilungsmitglied bekannt ist.
|
|
Die Beziehung hat auch Attribute (Beginn und Ende). Diese werden in der ER-Modellierung einfach dem Beziehungstyp hinzugefügt. |
|
3.5 Zweistellige Beziehungen - n:m |
|
Kardinalitäten und Min-/Max-Angaben |
|
Die folgende Abbildung zeigt ein Beispiel für eine n:m-Beziehung. Es geht um Angestellte mit Personalnummer (PersNr), Namen, Vorname (VName), Datum der Einstellung (DatEinst) und Geburtstag (GebTag) sowie um Projekte mit der Projektidentifikation (ProjId) und dem Namen des Projektleiters (Leiter). Dies führt zu den Entitätstypen Angestellte und Projekte. Die Beziehung bedeutet Projektmitarbeit, sie führt zu einem Beziehungstyp AngProj (Angestellte / Projekte), dem auch noch zwei Attribute zugewiesen sind. |
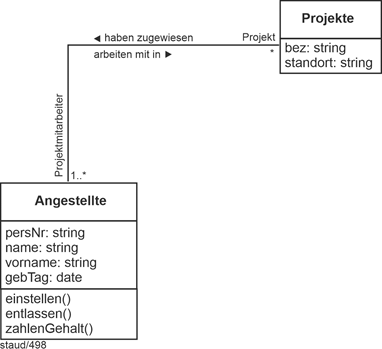
|
Die Kardinalität ist n:m, da gilt: Eine/e Angestellte/r kann in einem oder mehreren Projekten mitarbeiten und ein Projekt kann mehrere zugewiesene Angestellte haben. |
|
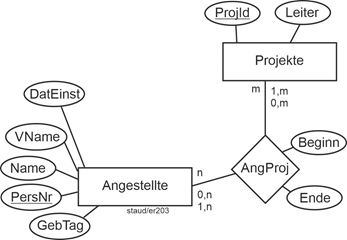
|
|
Abbildung 3.5-1: Kardinalität n:m und damit mögliche Min-/Max-Angaben |
|
Die ebenfalls in der Zeichnung angegebenen Min-/Max-Angaben erlauben die Präzisierung bzgl. der Teilhabe. Die optionalen Varianten bedeuten: |
|
- 0,n bei Angestellte: Es gibt (natürlich) Angestellte, die in keinem Projekt mitarbeiten
- 0,m bei Projekte: Es gibt Projekte, denen noch keine Person zugeordnet ist, d.h. man will datenbanktechnisch Projekte bereits einrichten können, wenn noch keine Person zugewiesen ist.
|
|
Die Beziehung hat auch Attribute (Beginn und Ende). Diese werden in der ER-Modellierung einfach dem Beziehungstyp hinzugefügt. |
|
Es ist auch möglich, die Min-/Max-Angaben ganz konkret zu machen, wie es das folgende Beispiel zeigt. Dabei geht es um einen Sportverein mit Fußballmannschaften. Die Beziehung Mannschaften / Mitglieder (MaMi) hält fest, welches Mitglied in welcher Mannschaft spielt. |
|
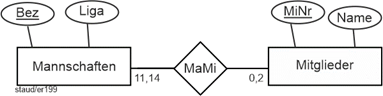
|
|
Abbildung 3.5-2: Konkrete Min-/Max-Angaben |
|
Bez: Bezeichnung der Mannschaft |
|
Liga: Angabe der Liga, in der die Mannschaft spielt |
|
MINr: Mitgliedsnummer |
|
Name: Nachname des Mitglieds |
|
Dabei soll gelten: |
|
- Ein Mitglied spielt in keiner oder maximal zwei Mannschaften.
- Eine Mannschaft hat mindestens 11 und maximal 14 Mitglieder.
|
|
3.6 Mehrstellige Beziehungen |
|
Min-/Max-Angaben bei mehrstelligen Beziehungen |
|
Es gibt in ER-Modellen nicht nur zweistellige Beziehungen. Grundsätzlich sind beliebigstellige möglich. Allerdings ist dann die Bestimmung der Min-/Max-Angaben nicht mehr so einfach wie im zweistelligen Fall. Die Min-/Max-Angaben eines Entitätstyps können nun nicht mehr mit einem konkreten anderen, sondern nur mit dem Beziehungstyp in Verbindung gesetzt werden: Für jeden Entitätstyp wird ausgedrückt, mit wieviel Entitäten er minimal und maximal am Beziehungstyp teilnimmt. Die folgende Abbildung zeigt ein Beispiel. |
|
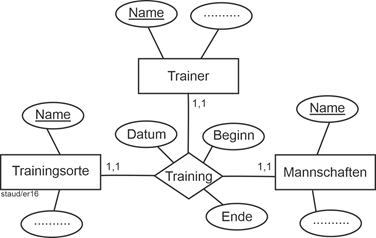
|
|
Abbildung 3.6-1: Dreistelliger Beziehungstyp – Variante 1 |
|
Hier bedeuten die Min-/Max-Angaben: |
|
- Am Training nimmt genau eine Mannschaft teil
- Das Training findet an einem Ort statt
- Es wird durch einen einzigen Trainer durchgeführt
|
|
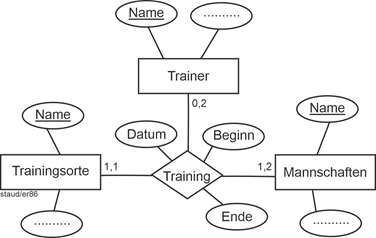
Die folgende Abbildung zeigt eine Variante. |
|
|
|
Abbildung 3.6-2: Dreistelliger Beziehungstyp – Variante 2 |
|
Jetzt ist die Bedeutung der Min-/Max-Angaben wie folgt: |
|
- Am Training nimmt mindestens eine, maximal zwei Mannschaft/en teil
- Das Training findet an genau einem Ort statt
- Es wird nicht immer von einem Trainer durchgeführt. Falls doch, sind höchstens zwei beteiligt.
|
|
Die Beziehung hat in den obigen Beispielen auch Attribute (Datum, Beginn und Ende). Diese werden in der ER-Modellierung einfach dem Beziehungstyp hinzugefügt. |
|
3.7 Muster Generalisierung/Spezialisierung |
|
Dieses Muster ist so wichtig dass es in der ER-Modellierung und in der objektorientierten Theorie dafür eigene Elemente gibt, konzeptionell und grafisch. In der objektorientierten Modellierung wird darauf das Konzept der Vererbung aufgebaut. |
|
Grundlage ist, dass Enitäten zum einen gemeinsame Attribute haben, zum anderen auch unterschiedliche. Die gemeinsamen Attribute kommen in einen eigenen Entitätstyp, die Generalisierung, die unterschiedlichen in andere Entitätstypen, die Spezialisierungen. |
Generalisierung / Spezialisierung |
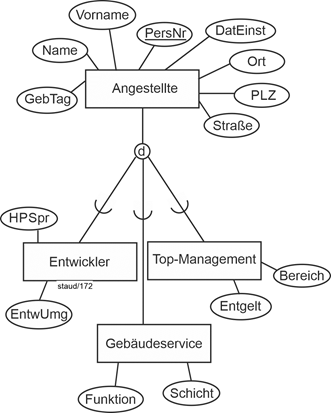
Die folgende Abbildung zeigt die grafische Umsetzung an einem Beispiel. |
|
|
|
Abbildung 3.7-1: Generalisierung / Spezialisierung in der ER-Modellierung |
|
EntwUmg: Entwicklungsumgebung, HPSpr: Hauptprogrammiersprache |
|
Im Bedarsfall werden z.B. die Attribute der Entwickler ergänzt mit denen von Angestellte. |
|
3.8 Muster Aggregation |
|
Bei der Aggregation geht es um ein Strukturmerkmal, das so beschrieben werden kann: Es gibt Dinge, die andere Dinge enthalten. Und auch letztere können wieder aus Dingen bestehen. Die einfachsten Beispiele finden sich im technischen Bereich: Ein Airbus besteht aus Grobkomponenten, diese aus feineren Komponenten, diese auch wieder – bis man bei elementaren Teilen angekommen ist. |
|
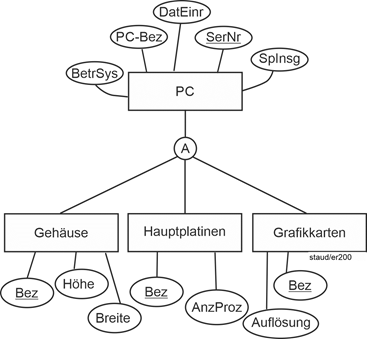
Es geht also um Beziehungen zwischen Entitätstypen, die den Tatbestand beschreiben, dass bestimmte Entitäten in anderen enthalten sind. Die folgende Abbildung zeigt an einem Beispiel die grafische Umsetzung. |
|
|
|
Abbildung 3.8-1: Aggregation in der ER-Modellierung |
|
SerNr: Seriennummer, SpInsg: Speicher insgesamt, AnzProz: Anzahl Prozessoren |
|
Im Gegensatz zur Komposition haben hier die enthaltenen Entitäten eine eigene Existenz. |
|
3.9 Muster Komposition |
|
Auch: singulärerer Entitätstyp, weak entity type |
|
Bei einer Komposition stehen ein unabhängiger Entitätstyp und mindestens ein abhängiger Entitätstyp in Beziehung, wobei die abhängigen nur zusammen mit den unabhängigen existieren können. Es wird also eine Existenzabhängigkeit ausgedrückt. Wenn die jeweils unabhängige Entität gelöscht wird, muss auch die abhängige Entität gelöscht werden. |
|
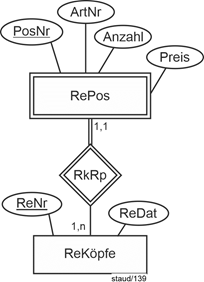
In der ER-Modellierung werden die abhängigen Entitätstypen mit singulärer Entitätstyp (engl.: weak entity type) bezeichnet. Die folgende Abbildung zeigt die grafische Umsetzung am Beispiel eines Anwendungsbereichs Rechnungen. |
Singulärer Entitätstyp |
|
|
Abbildung 3.9-1: Komposition / singulärer Entitätstyp in der ER-Modellierung |
|
RePos: Rechnungspositionen, ReKöpfe: Rechnungsköpfe, ReNr: Rechnungsnummer, ReDat: Rechnungsdatum, RkRp: Beziehungstyp Rechnungköpfe / Rechnungspositionen |
|
Die Min-/Max-Angaben drücken aus, dass ein Rechnungskopf mindestens eine Rechnungsposition hat und dass eine Rechnungsposition zu genau einer Rechnung gehört. |
|
3.10 Muster Einzel/Typ |
|
Vgl. für eine Beschreibung [Staud 2022, Abschnitt 5.3], http://www.staud.info/erm2/er_t_1.htm#Abschnitt5.3 |
|
Das Muster Einzel/Typ kann mit Hilfe zweier Entitätstypen und eines Beziehungstyps modelliert werden. Der eine Entitätstyp enthält die Attribute zu den Typen, der andere zu den Elementen. Die Wertigkeiten der Beziehung sind bei den Typen |
|
|
1,n (zu einem Typ gehört mindestens ein einzelnes Element)
|
|
und bei den Elementen |
|
|
1,1 (ein „Element“ gehört zu genau einem Typ)
|
|
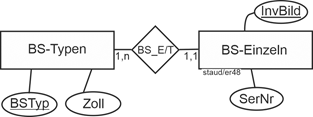
Die folgende Abbildung zeigt ein Beispiel. Es geht um Computerbildschirme (BS) mit den beiden Entitätstypen BS-Typen und BS-Einzeln. Wie es sein muss, besteht bei der Typinformation der Schlüssel aus der Typbezeichnung (BSTyp; z.B. HP xyz) und bei der Einzelinformation aus einer Information, die jedes einzelne Gerät identifiziert, hier aus der Inventarnummer des einzelnen Bildschirms (InvBild). |
|
|
|
Abbildung 3.10-1: Muster Einzel/Typ am Beispiel Computerbildschirme (BS) |
|
Zoll: Größe des Bildschirms bei Geräten dieses Typs; SerNr: Seriennummer |
|
Bei allen weiteren Attributen, die Bildschirme beschreiben, muss dann entschieden werden, zu welchem der beiden Entitätstypen sie gehören. |
|
4 Beziehungen in objektorientierten Modellen |
|
Vgl. für eine Einführung in die objektorientierte Modellierung: |
|
Staud, Josef L.: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler) |
|
|
|
4.1 Assoziationen |
|
Die Beziehungen werden hier Assoziationen genannt (vgl. dazu Kapitel 3 von [Staud 2019]). Es gibt sie, wie in diesen Modellierungsansätzen üblich, zwei- und mehrstellig. |
|
Die Basiselemente sind hier Klassen mit dem üblichen Aufbau oder auch in der Kurzfassung wie im Lesehinweis. |
|
Grundsätzlich gibt es folgende Möglichkeiten der Bildung von Assoziationen: |
Von Ein- bis Mehrstellig |
- Eine Assoziation einer Klasse mit sich selbst (einstellig)
- Eine Assoziation zwischen zwei Klassen (zweistellig, binär)
- Eine Assoziation zwischen mehr als zwei Klassen (mehrstellig, z.B. ternär)
|
|
Hintergrund |
|
Das Konzept der Assoziation, wie es in der objektorientierten Theorie ausformuliert wird, entspricht dem „in Beziehung setzen“ von Modelleinheiten (Relationen, Entitätstypen) in der klassischen Datenbanktheorie, wie oben gezeigt. |
Vorgänger
Datenbanktheorie |
In der objektorientierten Systemanalyse kommt ein weiterer Aspekt dazu. Hier wird betont, dass die Assoziationen notwendig sind, damit Objekte miteinander kommunizieren können (vgl. beispielhaft [Oestereich 1998, S. 268]). Damit wird die Tatsache angesprochen, dass in einem objektorientierten System die einzelnen Klassen und ihre Objekte bei der Erledigung der Aufgaben zusammenwirken (vgl. [Staud 2019, Kapitel 7]). Dies geschieht aber entlang der oben eingeführten semantisch wichtigen Beziehungen zwischen den Klassen. Insofern ergibt sich kein Widerspruch. |
Assoziationen als Kommunikationspfade |
Insbesondere in Abgrenzung zum relationalen Modell muss hier noch darauf hingewiesen werden, dass die konkrete Realisierung dieser Beziehungen zwischen Objekten modelliert wird, indem die entsprechenden Objekte mithilfe ihrer Objektidentifiziererverknüpft werden und nicht mithilfe attributbasierter Schlüssel. |
Verknüpfung durch Objektidentifizierer |
Darstellung der Wertigkeiten |
|
Auch hier geben die Wertigkeiten von Assoziationen an, wieviele Objekte jeder beteiligten Klasse an der Assoziation teil haben. Folgende Darstellung haben die UML-Autoren festgelegt: |
|
- 1 (einfach). Genau ein Objekt der jeweiligen Klasse geht in die Beziehung ein)
- 0..1 (konditionell einfach). Kein oder ein Objekt der jeweiligen Klasse geht in die Beziehung ein.
- * (konditionell mehrfach). Null, eines oder viele Objekte der jeweiligen Klasse geht in die Beziehung ein).
|
|
Weitere Konkretisierungen bezüglich der maximalen und minimalen Anzahl von Objekten können erfolgen, so dass z.B. folgende Angaben möglich sind: |
|
- fünf oder mehr: 5..*
- null bis drei: 0..3
- genau fünf: 5
- drei, vier oder acht: 3, 4, 8
- alle natürlichen Zahlen außer elf: 1..10, 12..*
|
|
Balzert führt zusätzlich die Begriffe Kann- und Muss-Assoziationen ein. Kann-Assoziationen haben als Untergrenze die Kardinalität 0, Muss-Assoziationendie Kardinalität 1 oder größer [Balzert 1999a, S. 41f]. |
Kann- und
Muss-Assoziationen |
In den Abbildungen werden die Wertigkeiten an den Assoziationsenden vermerkt. Vgl. den Lesehinweis und die Beispiele unten. |
|
4.2 Lesehinweis |
|
Eine Assoziation wird normalerweise einfach durch eine durchgezogene Linie dargestellt, die entweder die Klasse mit sich selbst verbindet (einstellig) oder mehrere Klassen miteinander. Dies sei am Beispiel zweistelliger Assoziationen näher eräutert. |
Linie mit zwei Bezeichnungen ohne … |
An der Linie sind die Bezeichnungen der Assoziation angegeben. Es sind zwei, eine für jede Richtung. |
|

|
|
Abbildung 4.2-1: Grafische Darstellung einer zweistelligen Assoziation – ohne Raute |
|
Jede Assoziation kann auch mit einer Raute gezeichnet werden. Dann verbindet eine durchgezogene Linie jede beteiligte Klasse mit der Raute. Die nächste Abbildung zeigt ein Beispiel. |
… oder mit Raute |

|
|
Abbildung 4.2-2: Grafische Darstellung einer zweistelligen Assoziation – mit Raute |
|
Liegen mehr als zwei Klassen vor, ist die Assoziation also mehr als zweistellig, kann sie nur auf diese Weise gezeichnet werden. |
|
Die gefüllten Dreiecke bei den Assoziationsbezeichnungen zeigen die Leserichtung (vgl. die Beispiele unten). |
|
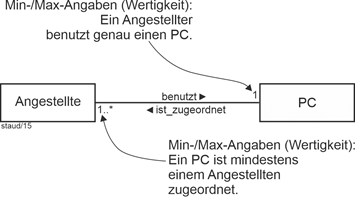
Die Wertigkeiten (Min-/Max-Angaben) der Assoziationen sind in der UML wie im folgenden Beispiel angeordnet. |
|
|
|
Abbildung 4.2-3: Lesehinweis für die Darstellung der Wertigkeiten mit der UML 2.5 |
|
Aufpassen, das macht oft Schwierigkeiten: Die Wertigkeiten bei einer Klasse sind die der „anderen“ Klasse. Dies weicht ab von der Notation bei ER-Modellen. |
|
4.3 Einstellige Beziehungen |
|
Beispiele für einstellige (rekursive) Assoziationen sind Stücklisten („ist enthalten in“) oder ein Vorgesetztenverhältnis („ist vorgesetzt“). Sie werden durch eine durchgezogene Linie dargestellt, die die Klasse mit sich selbst verbindet. An die Enden werden jeweils Assoziationsbezeichnungen angefügt. |
|
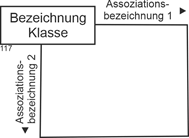
|
|
Abbildung 4.3-1: Grafische Darstellung einer einstelligen Assoziation |
|
Die Darstellung mit einer Raute ist ebenfalls möglich. |
Mit Raute |
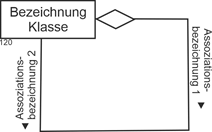
|
|
Abbildung 4.3-2: Grafische Darstellung einer einstelligen Assoziation mit Raute |
|
Hier ein inhaltliches Beispiel. Vgl. [Staud 2019, Abb. 3.20] für das gesamte Klasseniagramm und die Beschreibung. Die einstellige Assoziation drückt das Vorgesetztenverhältnis aus, das es in hierarchisch organisierten Organisationen gibt. Die Min-/Max-Angaben zeigen, dass Abteilungsleiter und Sachbearbeiter betrachtet werden. Ein/e Sachbearbeiter/in hat genau eine/n Abteilungsleiter/in, umgekehrt soll gelten, dass ein/e Abteilungsleiter/in mindestens einen Untergebenen hat. |
|

|
|
Abbildung 4.3-3: Einstellige (rekursive) Assoziation auf der Klasse Angestellte |
|
Quelle: [Staud 2019, S. 63 (Abb. 3.20)] |
|
4.4 Zweistellige Beziehungen - 1:1 |
|
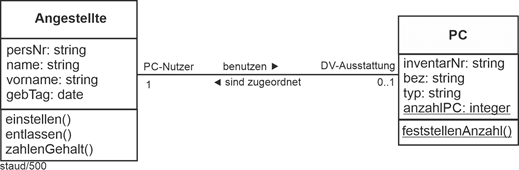
Hier ein Beispiel für eine 1:1-Beziehung. Die Assoziation sagt aus, dass in diesem Unternehmen jede/r Angestellte höchstens einen PC zugewiesen bekommt (0..1) und dass jeder PC genau einer Person zugeordnet ist. |
|
|
|
Abbildung 4.4-1: 1:1-Beziehung in der objektorientierten Modellierung |
|
Attribute und Methoden sind nach den Vorgaben der UML 2.5 gestaltet. |
|
Möglich sind folgende Konstellationen bei den Wertigkeiten: |
|
|
0..1 mit 0..1
|
|
|
1..1 mit 0..1
|
|
|
0..1 mit 1..1
|
|
|
1..1 mit 1..1
|
|
Die evtl. Optionalität der Assoziation wird durch die Null ausgedrückt. |
|
4.5 Zweistellige Beziehungen - 1:n |
|
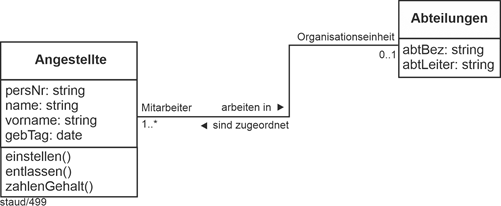
Bei den Assoziationen, die eine 1:n-Beziehung ausdrücken muss auf der einen Seite 1 vorkommen, begleitet von 0 oder 1. Auf der anderen Seite der Stern (*), ebenfalls begleitet von 0 oder 1. Die 0 kann jeweils nur am Anfang stehen. Liegt sie vor, handelt es sich um eine optionale Beteiligung, liegt eine 1 vor, ist die Teilnahme an der Beziehung Pflicht. |
|
|
|
Abbildung 4.5-1: 1:n-Beziehung zwischen zwei Klassen |
|
Damit sind folgende Konstellationen bei den Wertigkeiten möglich: |
|
|
0..1 mit 0..1
|
|
|
1..1 mit 0..1
|
|
|
0..1 mit 1..1
|
|
|
1..1 mit 1..1
|
|
Die evtl. Optionalität der Assoziation wird durch die Null ausgedrückt. |
|
4.6 Zweistellige Beziehungen - n:m |
|
Bei den Assoziationen, die eine n:m-Beziehung ausdrücken, muss bei jeder Wertigkeit auf der einen Seite ein Stern (*) vorkommen, begleitet von 0 oder 1 auf der anderen Seite. Die 0 kann jeweils nur am Anfang stehen. Sie drückt Optionalität aus. Liegt eine 1 vor, ist die Teilnahme an der Beziehung Pflicht. Die folgende Abbildung zeigt ein Beispiel. |
|
|
|
Abbildung 4.6-1: Darstellung einer zweistelligen Assoziation mit n:m-Beziehung |
|
Damit sind folgende Konstellationen bei den Wertigkeiten möglich: |
|
|
0..* mit 0..0
|
|
|
1..* mit 0..*
|
|
|
0..* mit 1..*
|
|
|
1..* mit 1..*
|
|
Die evtl. Optionalität der Assoziation wird durch die Null ausgedrückt. |
|
4.7 Mehrstellige Beziehungen |
|
Auch im objektorientierten Entwurf kommen mehrstellige Assoziationen vor. Betrachten wir dreistellige (ternäre) als Beispiel. Sie werden wie in der folgenden Abbildung grafisch dargestellt, die höherwertigen entsprechend. Dabei wird die Bezeichnung der Assoziation an der Raute angebracht. |
Mehr als zwei Klassen |
|
|
Abbildung 4.7-1: Grafische Darstellung einer dreistelligen Assoziation |
|
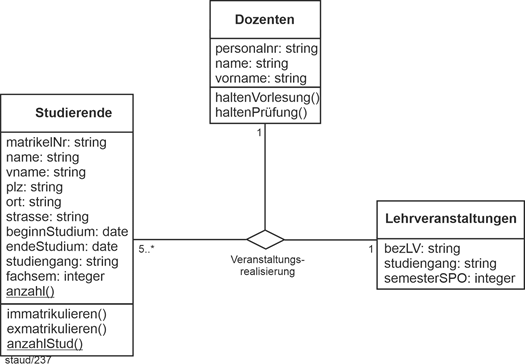
Die folgende Abbildung zeigt ein Beispiel. Hier wird der Besuch von Lehrveranstaltungen durch die kombinierte Information aus Studierenden / Lehrveranstaltung / Dozenten erfasst. Die Wertigkeiten bedeuten: |
|
- Bei Studierende: Mindestens 5 Studierende müssen teilnehmen.
- Bei Lehrveranstaltungen: Es geht jeweils um genau eine Lehrveranstaltung.
- Bei Dozenten: Jeweils ein Dozent hält die Lehrveranstaltung.
|
|
|
|
Abbildung 4.7-2: Dreistellige Assoziation – Beispiel Veranstaltungsbesuch |
|
4.8 Eigenschaften von Beziehungen |
|
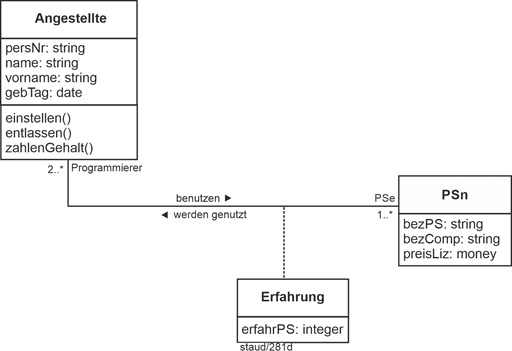
Liegen Attribute auf Beziehungen vor, werden diese durch sog. Assoziationsklassen erfasst. Diese werden, wie es das folgende Beispiel zeigt, mit einer gestrichelten Linie an die Assoziation angefügt. Vgl. [Staud 2019, Kapitel 4] für eine nähere Beschreibung. |
|
Im folgenden Beispiel zu einem Softwarehaus sind Angestellte und Programmiersprachen (PSn) in eine Beziehung gebracht, die die Nutzung der Programmiersprachen durch die Angestellten erfasst. Die Assoziationsklasse erfasst, wieviel Jahre Erfahung jede Person mit ihrer Programmiersprache hat. |
|
Die Min-/Max-Angaben bedeuten: |
|
- Ein/e Angestellte/r nutzt mindestens eine Programmiersprache.
- Jede Programmiersprache wird von mindestens zwei Personen genutzt.
|
|
|
|
Abbildung 4.8-1: Eigenschaften auf Beziehungen - Assoziationsklassen |
|
4.9 Das Klassendiagramm als Ganzes |
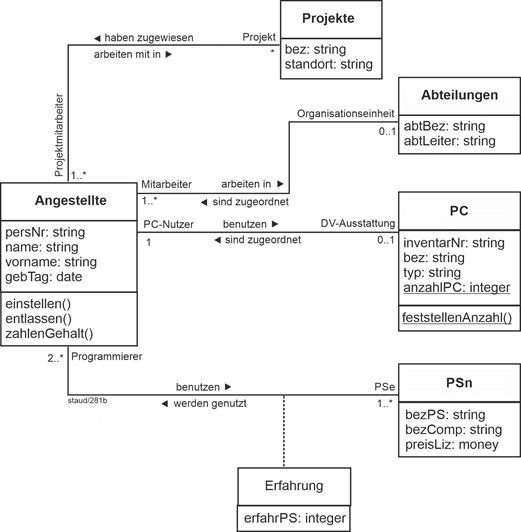
|
Einige der obigen Fragmente entstammen dem nachfolgend angegebenen Klassenmodell. Es zeigt im Zusammenhang die Bedeutung der Aufteilung der Attribute des Anwendungsbereichs auf verschiedene Klassen und die nachfolgende Notwendigkeit, Assoziationen zwischen diesen einzurichten. Vgl. [Staud 2019, Abschnitt 4.3], auch für weitere Beispiele. |
|
|
|
Abbildung 4.9-1: Klassendiagramm Angestellte |
|
4.10 Muster Generalisierung/Spezialisierung |
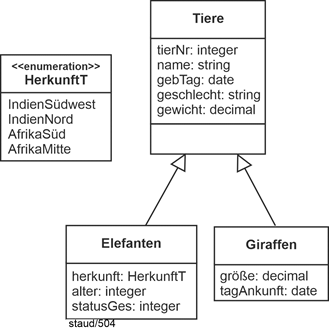
|
Die Generalisierung / Spezialisierung wird in objektorientierten Modellen so dargestellt, dass für die Generalisierung und die Spezialisierungen jeweils eigene Klassen mit ihren spezifischen Attributen angelegt werden. Vgl. [Staud 2019, Kapitel 6] für eine Beschreibung. Die Generalisierung / Spezialisierung wird durch Pfeillinien ausgedrückt, wie das folgende Beispiel zeigt. |
|
|
|
Abbildung 4.10-1: Generalisierung / Spezialisierung in objektorientierten Modellen – am Beispiel Tiere / Elefanten / Giraffen |
|
tierNr: identifizierende Tiernummer, statusGes: Gesundheitsstatus (ausgedrückt in einem Integer-Wert) |
|
4.11 Muster Aggregation |
|
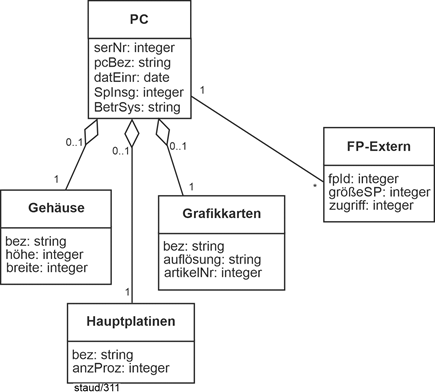
Aggregationen drücken Enthaltensein aus. Dies wird durch Assoziationen ausgedrückt. Entsprechend sind die Min-/Max-Angaben. Im folgenden Beispiel (PC-Produktion) gilt: |
|
- Jeder PC hat genau ein Gehäuse, eine Hauptplatine, eine Grafikkarte und evtl. eine externe Fesplatte (FP)
- Jedes Gehäuse, jede Hauptplatine und jede Grafikkarte sind in keinem oder maximal einem PC. Jede externe Festplatte ist genau einem PC zugeordnet.
|
|
|
|
Abbildung 4.11-1: Aggregationen in objektorientierten Modellen – am Beispiel PC |
|
Wichtig ist, dass man bei Aggregationen davon ausgeht, dass die „enthaltenen“ Objekte auch für sich (real und datenbanktechnisch) existieren können. |
|
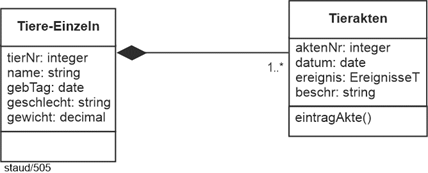
4.12 Muster Komposition |
|
Ganz anders bei Kompositionen. Hier gibt es eine Existenzabhängigkeit. Diese wird durch eine eingeschwärzte Raute wie im folgenden Beispiel ausgedrückt. Für die Datenbank bedeutet dies: Wird das übergeordnete Objekt gelöscht, muss auch das abhängige gelöscht werden. |
|
|
|
Abbildung 4.12-1: Kompositionen in objektorientierten Modellen – am Beispiel Tierakten |
|
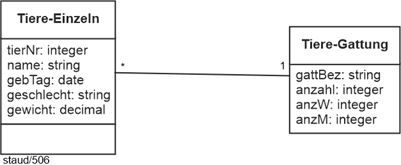
4.13 Muster Einzel/Typ |
|
Das Muster Einzel/Typ kann durch eine Assoziation mit entsprechenden Wertigkeiten dargestellt werden. Wie im folgenden Beispiel. Jedes Tier gehört zu genau einer Tiergattung. Zu einer Tiergattung (im Zoo) gehört kein Tier, eines oder viele. |
|
|
|
Abbildung 4.13-1: Muster Einzel/Typ in objektorientierten Modellen – am Beispiel Tiere |
|
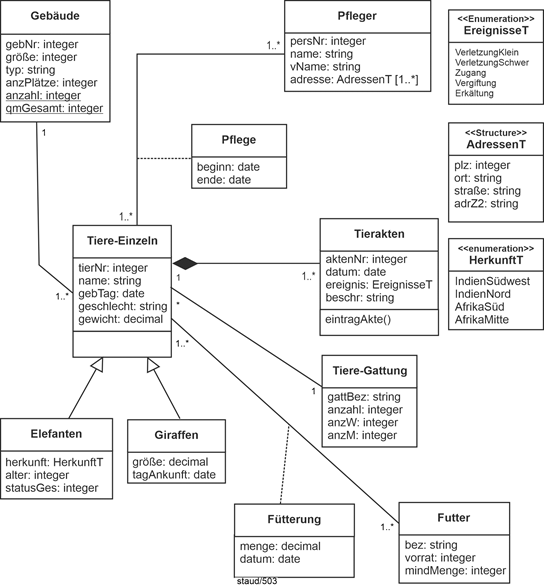
4.14 Das Zoo-Modell als Ganzes |
|
Einige der obigen Fragmente entstammen dem nachfolgend angegebenen Klassenmodell. Es zeigt im Zusammenhang die Bedeutung der Aufteilung der Attribute des Anwendungsbereichs auf verschiedene Klassen und die nachfolgende Notwendigkeit, Assoziationen zwischen diesen einzurichten. |
|
|
|
Abbildung 4.14-1: Objektorientertes Modell Zoo |
|
Anmerkungen zum objektorientierten Modell: |
|
Assoziationsklassen: Pflege, Fütterung |
|
Generalisierung / Spezialisierung Tiere-Einzeln, Elefanten, Giraffen |
|
Muster Einzel/Typ: Tiere-Einzeln, Tiere-Gattung |
|
5 Literatur |
|
Staud 2019
Staud, Josef: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler) |
|
Staud 2021
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen. 2. Auflage 2021. Verlag tredition GmbH,
Paperback: 978-3-347-35883-6
Hardcover: 978-3-347-35884-3
E-Book: 978-3-347-35885-0 |
|
Staud 2022
Staud, Josef Ludwig: Semantische Datenmodellierung für effiziente Datenbanken: ERM, SERM, SAP-SERM. (in Arbeit, Stand 2022/02), http://www.staud.info/erm2/er_t_1.htm |
|
|
|
|
|
|