DBTraining – Datenbanktraining zu RM, ERM, SQL und OOM:
121 einführende Aufgaben und Lösungen (Entwurf/Version 1/2024)
| |
Aufgaben und Lösungen zum Training folgender Aspekte rund um Datenbanken: |
|
- Modellierung relationaler Datenbanken
- Einrichten relationaler Datenbanken mit XAMPP/mySQL
- Abfragen und Arbeiten von Datenbanken mit SQL
- Web-Oberfläche einrichten mit PHP
- Entity Relationship - Modellierung
- Objektorientierte Modellierung nach der UML 2.5
|
|
|
|
©2024 Josef L. Staud |
|
Autor: Josef L. Staud |
|
Stand: Februar 2024 |
|
Umfang des gedruckten Textes: ca. 300 Seiten |
|
Dieser Text richtet sich an die Teilnehmer meiner Seminare und sonstige Interessenten.
Geplanter Erscheinungstermin der Endfassung: 2025 |
|
Aufbereitung für's Web |
|
Diese HTML-Seiten wurden mithilfe eines von mir erstellten Programms erzeugt: WebGenerator2 (Version 2021). Es setzt Texte in HTML-Seiten um und ist noch in der Entwicklung. Die „maschinelle“ Erstellung erlaubt es, nach jeder Änderung des Textes diesen unmittelbar neu in HTML-Seiten umzusetzen. Da es nicht möglich ist, nach jeder Neuerstellung alle Seiten zu prüfen, ist es durchaus möglich, dass irgendwo auf einer „abgelegenen“ Seite Fehler auftreten. Ich bitte dafür um Verzeihung und um Hinweise (hs@staud.info). |
|
Die Veröffentlichung im Web erfolgt ab 2022 in zwei Versionen: Mit und ohne Frame-Technologien. Zu meinem Bedauern wird die Frame-Technologie inzwischen von den Verantwortlichen als unerwünscht angesehen und es häufen sich die Hinweise, dass bestimmte Browser Frame-basierte Seiten nicht mehr korrekt interpretieren können. Deshalb habe ich eine zweite Version meines Programms WebGenerator erstellt, die ohne Frames realisiert ist. |
|
Urheberrecht |
|
Dieser Text ist urheberrechtlich geschützt. Die dadurch begründeten Rechte, insbesondere die der Übersetzung, des Nachdrucks, des Vortrags, der Entnahme von Abbildungen und Tabellen oder der Vervielfältigung auf anderen Wegen und der Speicherung in Datenverarbeitungsanlagen, bleiben, auch bei nur auszugsweiser Verwertung, vorbehalten. Eine Vervielfältigung dieses Textes oder von Teilen dieses Textes ist auch im Einzelfall nur in den Grenzen der gesetzlichen Bestimmungen des Urheberrechtsgesetzes der Bundesrepublik Deutschland vom 9. September 1965 in der jeweils geltenden Fassung zulässig. Sie ist grundsätzlich vergütungspflichtig. Zuwiderhandlungen unterliegen den Strafbestimmungen des Urheberrechtsgesetzes. |
|
Warenzeichen und Markenschutz |
|
Alle in diesem Text genannten Gebrauchsnamen, Handelsnamen, Marken, Produktnamen, usw. unterliegen warenzeichen-, marken- oder patentrechtlichem Schutz bzw. sind Warenzeichen oder eingetragene Warenzeichen der jeweiligen Inhaber. Die Wiedergabe solcher Namen und Bezeichnungen in diesem Text berechtigt auch ohne besondere Kennzeichnung nicht zu der Annahme, dass solche Namen im Sinne der Gesetzgebung zu Warenzeichen und Markenschutz als frei zu betrachten wären und daher von jedermann benutzt werden dürften. |
|
Didaktisch motivierte Aufgaben |
|
Die hier vorgestellten didaktisch motivierten Modellierungsbeispiele dienen der Ausbildung, dem vertieften Erlernen und Einüben der jeweiligen Theorie und Methode, nichts anderem. |
|
Prof. Dr. Josef L. Staud |
|
|
|
1 Einführung |
|
1.1 Motivation |
|
Methodenwissen erlangt man am besten, indem man die Methode anwendet. Dann entsteht nach einiger Zeit Methodenkompetenz. Dies gilt auch für die verschiedenen Methoden des Datenbankdesigns und des Umgangs mit Datenbanken. |
|
Nach dem Erwerb des notwendigen Theoriewissens sollte diese Phase des Trainierens angestrebt werden. Im Kontext der Programmierung ist dies schon länger klar. Gute Lehrbücher für den Erwerb von Programmierkompetenz enthalten zahlreiche nachvollziehbare Beispiele, von einfach bis komplex. Der Verfasser hat es selbst erlebt. Vor Jahrzehnten beim Lernen von C++ mit dem legendären Buch von Stephen Prata und danach immer wieder beim Erlernen weiterer Programmiersprachen. |
|
Dieser Text will ähnliches für die Datenmodellierung und das Datenbankdesign leisten. Anhand zahlreicher Beispiele soll das Theoriewissen zur Anwendung und zu einer bestimmten Exzellenz geführt werden. Dass außerdem auch einige wichtige Theoriefragen angesprochen (wiederholt) werden, stört dabei sicher nicht. Das Motto ist: |
|
Festigung, Vertiefung und Verbreiterung der Methodenkompetenz (bzgl. Datenbankdesign) durch Anwenden der Methoden. |
|
Sozusagen als Nebeneffekt ergibt sich, dass bei der Durcharbeitung der Aufgaben die verschiedenen Ansätze zur Modellierung von Daten verglichen werden können, was erfahrungsgemäß auch beim Erlernen von Methodenwissen hilft. Wer z.B. erstmal begriffen hat, dass alle diese Modellierungsansätze weitgehend attributgeprägt sind, wird das Attributkonzept nicht mehr so stiefmütterlich behandeln, wie es heute leider an vielen Stellen in der Lehre geschieht. Wer die gängigen Muster in einem Ansatz begriffen hat, tut sich leichter im nächsten. |
Methodenvergleich |
Noch nicht vollständig gelungen ist, die Aufgaben in jedem Bereich nach Schwierigkeitsgrad zu ordnen. Dies soll aber im weiteren Ausbau geschehen. Gerne nehme ich hier Vorschläge und Wünsche entgegen. |
|
1.2 Voraussetzungen |
|
Voraussetzung für die erfolgreiche Arbeit mit dem Text sind Basiskenntnisse der folgenden Systeme und Methoden. |
|
Den größten Anteil hat das relationale Datenbankdesign, die relationale Modellierung. Anwendungsbeispiele aus vielen Anwendungsbereichen, in denen in unterschiedlichen Schwierigkeitsgraden alle Aspekte des relationalen Datenbankdesigns thematisiert werden, sollten einen umfassenden Kompetenzerwerb ermöglichen. |
Relationales Datenbankdesign |
Aber auch das Einrichten der Datenbanken, die Umsetzung relationaler Datenmodelle mittels SQL in konkrete relationale Datenbanken, wird trainiert. Mit mySQL unter XAMPP, einer hervorragenden und – das ist ja auch sehr wichtig – leicht und kostenlos verfügbaren Entwicklungsumgebung. |
mySQL, XAMPP |
Ein Kapitel enthält Aufgaben zu Abfragen und Auswertungen von Datenbanken mit SQL - ungefähr auf dem Niveau nach einer einführenden Lehrveranstaltung. Dabei wird phpMyAdmin unter XAMPP genutzt, eine leistungsstarke Bedienoberfläche für Relationale Datenbanken. |
SQL |
Für den hier letztendlich betrachteten Gesamtweg, … |
|
Anforderungen – Datenmodell (Schema) – Datenbank – Web-Benutzeroberfläche |
|
… fehlt jetzt nur noch der letzte Schritt, von der Datenbank zu einer Benutzeroberfläche ohne SQL. Dafür wird hier „das Web“ genommen, da heutzutage die meisten Benutzeroberflächen für Datenbestände webbasiert sind. Die Methoden der Wahl sind dabei PHP, HTML und JavaScript. Deshalb sind hier in einem Kapitel auch Aufgaben, mit denen das Einrichten einfacher Web-Benutzeroberflächen für Datenbanken geübt wird. |
PHP, HTML |
Einige Aufgaben widmen sich auch wichtigen Aspekten der relationalen Theorie. Vor allem denen, die das Datenbankdesign unterstützen. |
Relationale Theorie |
Die semantische Modellierung gerät schon seit einiger Zeit etwas ins Vergessen, sehr zu unrecht. Sie hat weiterhin Bedeutung und ist deshalb auch hier mit einigen Aufgaben vertreten. Hauptsächlich in ihrer Ausprägung als Entity Relationship-Modellierung. |
Semantische Modellierung |
Ein weiteres Kapitel widmet sich der objektorientierten Modellierung nach der UML 2.5. Dabei geht es um die inhaltlichen und semantischen Aspekte des Anwendungsbereichs, nicht um die Klassenbildung im Rahmen der Programmentwicklung, die ja eher funktionsorientiert sein muss. Ziel ist das, was auch Objektmodell genannt wird. |
Objektorientierte Modellierung |
„Verschüttetes Wissen“ |
|
Um zu helfen, falls das Wissen um die jeweiligen Methoden etwas in Vergessenheit geraten ist, sind im Anhang drei Kapitel, die hier benötigte wesentliche Aspekte der jeweiligen Methoden für die Wiederholung anbieten: |
|
- Kapitel 10: Etwas relationale Theorie
- Kapitel 11: Etwas HTML
- Kapitel 12: Etwas PHP – Vom Web zur Datenbank
|
|
Ausgangspunkt |
|
In diesem Text wird davon ausgegangen, dass bei der Leserin bzw. beim Leser Kenntnisse bezüglich Datenbankdesign (Datenmodellierung) vorhanden sind. Vor allem zu relationalen Datenbanken. Dazu gehört ein Verständnis von Attributen, Relationen und der elementaren Normalform (1NF). Diesbezügliche Lücken können mit Hilfe von [Staud 2021] beseitigt werden: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
Lücken bzgl. „inhaltlicher“ objektorientierter Modellierung beseitigt [Staud 2019]: |
|
Staud, Josef: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler) |
|
1.3 Attributbasiertheit |
|
Für sehr viele Datenbanken und ihre Methoden gilt: sie sind attributbasiert. D.h. sie beruhen auf Attributen, wie sie von den Eigenschaften der Alltagswelt abgeleitet wurden. Vgl. [Staud 2021, Abschnitt 2.4]. Dies gilt für alle relationalen Datenbanken, aber auch für objektorientierte, genauso wie für die semantische Datenmodellierung. Umso überraschender, dass der Attributsbegriff in Informatikkreisen nur stiefmütterlich behandelt wird. |
|
Bei den Modellierungsaufgaben wird mit einer Beschreibung des Anwendungsbereichs und der Anforderungen begonnen. Dabei liegen dann bereits die Attribute vor. Konzeptionelle Modellierung, der Weg von der Beschreibung des Anwendungsbereichs bis zu den Attributen und Datenmodellen, wird hier nicht betrachtet. |
Aufgabengestaltung |
Der Lösungsweg wird jeweils detailliert aufgezeigt. Die Vorgehensweise ist dabei unterschiedlich, um die möglichen unterschiedlichen Wege aufzuzeigen. |
|
Obwohl es vielerorts beim relationalen Datenbankentwurf nicht üblich ist, werden, wie beim objektorientierten Entwurf, Beziehungswertigkeiten angegeben. Sie werden hier Min-/Max-Angaben genannt. „Min/Max“ steht für minimalen und maximalen Wert der Teilnahme an der Beziehung. Sie zeigen nicht nur, ob eine Beziehung Pflicht ist oder optional, sondern auch, welchen Umfang die Wertigkeiten haben können. |
Min/Max |
1.4 Bezeichnung der Methodenelemente |
|
Was die zu beschreibenden Elemente in der Datenmodellierung angeht, kann man einen Ausgangspunkt und drei Modellebenen unterscheiden. Der Ausgangspunkt ist der zu modellierende Anwendungsbereich, manchmal auch Weltausschnitt genannt. Die erste Modellebene ist die der Attribute, durch die Objekte und Beziehungen beschrieben werden. Die zweite die Ebene der Basiselemente im jeweiligen Ansatz (Relationen, Entitätstypen, Klassen). Die dritte Ebene ist die des gesamten Datenmodells. Um diesbezüglich im Text die Übersichtlichkeit zu erhöhen wird folgende typographische Festlegung getroffen: |
Überblick durch Typographie |
- Bezeichnungen von Anwendungsbereichen werden etwas vergrößert, in Kapitälchen und in Arial gesetzt: Hochschule, Personalwesen, WebShop. In der Web-Version sind sie zusätzlich in roter Farbe gehalten.
- Bezeichnungen von Datenmodellen und Datenbanken sind in normaler Größe, fett und in Arial gesetzt: Vertrieb, Zoo, WebShop, Datenbanksysteme (Markt für Datenbanksysteme). In der Web-Version zusätzlich in rot.
- Bezeichnungen von Relationen, Entitätstypen und Klassen (Basiselemente) sind etwas verkleinert und in Arial gesetzt: Angestellte, Abteilungen, Projekte. In der Web-Version zusätzlich in rot.
- Bezeichnungen von Attributen sind etwas verkleinert, fett und in Arial gesetzt: Gehalt, Name, Datum. Bei zusammengesetzten Benennungen wird der nachfolgende Begriff wieder groß begonnen: PersNr (Personalnummer), BezProj (Bezeichnung Projekt).
- Für die kombinierte Angabe von Attributen und Relationen: Relationenbezeichnung.Attributsbezeichnung, also z.B. Angestellte.PersNr für das Attribut PersNr der Relation Angestellte.
- Ausprägungen von Attributen werden in normaler Größe und in Courier gesetzt, z.B. Müller für das Attribut Name.
|
|
Für die Basiselemente (Relationen, Entitätstypen, Klassen) wird bei der Bezeichnung immer die Mehrzahl gewählt, da ja in der Regel mehrere Objekte bzw. Beziehungen erfasst sind. |
|
|
|
2 Relationale Datenbanken – Von der Anforderung zum Datenmodell |
|
Für eine umfassende Einführung in die relationale Modellierung vgl. [Staud 2021]: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
Auszüge finden sich auf http://www.staud.info/rm1/rm_t_1.htm |
|
Erster Schritt des Gesamtwegs:
Anforderungen – Datenmodell (Schema) – Datenbank – Web-Benutzeroberfläche |
|
Die Aufgaben dieses Kapitel beziehen sich auf den ersten Schritt des Gesamtwegs, von der Anforderungsbeschreibung zum Datenmodell. |
|
|
|
2.1 Basisübung 1 |
|
Zu Beginn eines jeden Datenbankprojekts müssen aus der Beschreibung des Anwendungsbereichs und den Anforderungen die relevanten Relationen abgeleitet werden. In dieser Aufgabe geht es um diesen Schritt. Mit im Mittelpunkt sind dabei methodenbedingte Zerlegungen der Relationen. |
|
2.1.1 Anforderungsbeschreibung |
|
Im Rahmen des Datenbankdesigns für einen Sportverein wurden für die Mitglieder folgende Anforderungen formuliert: |
|
Die Mitglieder des Vereins werden durch Name, Vorname (VName), Telefon (Tel), Geburtstag (GebTag), Alter, eine Mitgliedsnummer (MiNr) und die Hauptadresse (PLZ, Ort, Straße) festgehalten. Erfasst wird außerdem der Tag des Eintritts (Eintritt) in den Verein. Bei ausgetretenen Mitgliedern ebenfalls der des Austritts (Austritt). Es kommt leider vor, dass ein Mitglied austritt und später wieder eintritt. Auch dies soll in vollem Umfang dokumentiert werden, d.h. vorherige Mitgliedschaften werden nicht gelöscht. Es entsteht so eine Dokumentation aller Ein- und Austritte eines Vereinsmitglieds. Bei verstorbenen Mitgliedern wird der Todestag (Todestag) vermerkt. |
|
Daraus sind die Relationen abzuleiten. |
|
2.1.2 Lösungsschritte |
|
Die erste Relation liegt nahe: Mitglieder mit dem Schlüssel #MiNr. Welche Attribute können ihr zugeordnet werden? Sicherlich der Name und Vorname (VName), denn diese sind eindeutig für jedes Mitglied: |
|
Mitglieder (#MiNr, Name, Vorname, …) |
|
Die Telefonnummer nur, falls sie auch eindeutig ist. Auf Nachfrage erfahren wir, dass die Mitglieder durchaus mehrere Telefoniermöglichkeiten haben, z.B. einen Festnetz- und einen Mobilfunkanschluss. Dies würde in Mitglieder zu Mehrfacheinträgen führen. Deshalb wird dafür eine eigene Relation eingeführt: |
|
Telefone (#(MiNr, Tel)) |
|
MiNr wird zum Fremdschlüssel. |
|
Den Geburtstag, das Alter und die Hauptadresse können wir wiederum der Relation Mitglieder hinzufügen: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, …) |
|
Das Alter wird später in der Datenbank aus dem Geburtstag und dem Systemdatum regelmäßig berechnet. Solche abgeleiteten Attribute, wie sie in der ER-Modellierung genannt werden, die mittels anderer bestimmt und in die Datenbank eingetragen werden, kommen in Datenbanken durchaus vor. |
Abgeleitete Atribute |
Gäbe es mehrere Adressen je Mitglied, müsste dafür eine eigene Relation eingerichtet werden. Hier wird aber ausdrücklich auf die Hauptadresse verwiesen. Die Situation, mehrere Adressen im Datenmodell anlegen zu müssen, wird unten in den Aufgaben öfters bewältigt. |
Mehrere Adressen |
Mit den Attributen Tag des Eintritts (Eintritt) und des Austritts (Austritt) kommt die zeitliche Dimension in Form einer Zeitspanne ins Spiel. Das Attribut Eintritt kann problemlos in Mitglieder aufgenommen werden. Austritt dagegen nicht, da diese Attribut ja erst beschrieben werden kann, wenn der Austritt geschieht und solche semantisch bedingten Leereinträge sind in relationalen Datenbeständen nicht erwünscht. Es bleibt also nur eine eigene Relation mit den Austritten. Insgesamt also: |
Zeitliche Dimension |
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, Eintritt, …) |
|
Austritte (#MiNr, Austritt) |
|
Es soll nicht verschwiegen werden, dass hier sehr oft die pragmatische Lösung gewählt wird, das Ende der Zeitachse zusammen mit dem Eintritt zu platzieren, obwohl damit semantisch bedingte Leereinträge entstehen: |
Pragmatik |
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, Eintritt, Austritt, …) |
|
Nun findet sich aber in den Anforderungen der Wunsch, auch mehrere Ein- und Austritte eines Mitglieds zu erfassen und zu dokumentieren. Dies verändert den obigen Entwurf. Ein- und Austritte müssen wegen der Möglichkeit der Mehrwertigkeit zusammen mit der Mitgliedsnummer in eine eigene Relation Mitgliedschaften und raus aus Mitglieder: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, …) |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
Mitgliedschaften.MiNr wird Fremdschlüssel. Jetzt kann ein Mitglied alle paar Jahre aus- und später wieder einreten. Bei solchen Zerlegungen ist auf die Korrektheit des Schlüssels zu achten. Er muss jedes Tupel eindeutig identifizieren. Dies ist hier oben der Fall. |
|
Am Schluss der Anforderungsbeschreibung werden die verstorbenen Mitglieder erwähnt. Auch sie sollen erfasst werden. Den Todestag in Mitglieder zu erfassen wäre wegen der semantisch bedingten Leereinträge falsch. Bleibt auch hier nur eine eigene Relation zu den verstorbenen Mitgliedern: |
Verstorbene Mitglieder |
MitglVerstorben (#MiNr, Todestag) |
|
Wir gehen davon aus, dass die Daten zu den verstorbenen Mitgliedern in Mitglieder erhalten bleiben. Falls dem nicht so wäre, müsste MitglTot um die entsprechenden Attribute erweitert werden. |
|
2.1.3 Lösung |
|
Damit liegen mit den jeweiligen Endfassungen folgende Relationen vor. |
|
Textliche Fassung |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße) |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
MitglVerstorben (#MiNr, Todestag) |
|
Telefone (#(MiNr, Tel)) |
|
|
|
Grafische Fassung |
|
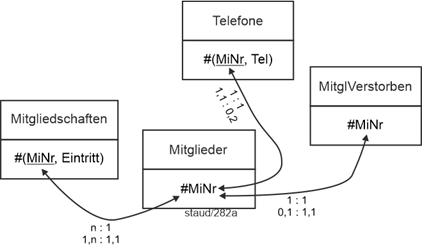
|
|
Abbildung 2.1-1: Grafische Lösung zum Anwendungsbereich Sportverein – Ausschnitt Mitglieder |
|
2.2 Basisübung 2 |
|
Auch in dieser Aufgabe geht es um das Erkennen der Relationen. Dabei steht das Erkennen und Bewältigen des Musters Generalisierung / Spezialisierung (vgl. [Staud 2021, Abschnitt 14.1]) im Mittelpunkt. |
|
2.2.1 Anforderungsbeschreibung |
|
Es liegt bereits eine Relation zu den Mitgliedern des Sportvereins vor: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße) |
|
Folgende zusätzlichen Anforderungen wurden formuliert : |
|
Für die Mitglieder wird erfasst, ob es sich um ein passives oder ein aktives Mitglied handelt. Für jedes aktive Mitglied wird dann noch festgehalten, welche Sportart es in welcher Leistungsstufe (LStufe) betreibt. Für die passiven Mitglieder wird erfasst, für welche ehrenamtliche Tätigkeit sie zur Verfügung stehen (BezTät). Dies können mehrere sein. |
|
2.2.2 Lösungsschritte |
|
Mal angenommen, es würde nur gefordert, dass erfasst wird, ob das Mitglied aktiv oder passiv ist. Dann würde ein Attribut AktPass mit den Ausprägungen aktiv oder passiv in Mitglieder reichen: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, AktPass) |
|
Kommen allerdings weitere Attribute für die Untergruppen hinzu, so wie hier |
|
- Sportart und Leistungsstufe (LStufe) für die aktiven Mitglieder,
- BezTät für die passiven Mitglieder,
|
|
ändert sich die Situation. Oftmals werden dann einfach diese Attribute der Relation hinzugefügt: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, AktPass, Sportart, LStufe, BezTät) |
|
Dies ist falsch, denn damit entstehen semantisch bedingte Leereinträge in der späteren Datenbank. Da ein Mitglied entweder aktiv oder passiv ist, gibt es immer Attribute, die keine Einträge erhalten können. Vgl. dazu das Muster Generalisierung / Spezialisierung in [Staud 2021, Abschnitt 14.1]. |
Falsch |
Die korrekte Lösung besteht darin, zwei neue Relationen anzulegen, eine für die aktiven und eine für die passiven Sportler: |
Korrekt |
MitglAktiv (#MiNr, Sportart, LStufe) |
|
MitglPassiv (#MiNr, BezTät) |
|
Das ist nun schon fast richtig. Da in der Anforderung gefordert ist, auch mehrere ehrenamtliche Tätigkeiten zu berücksichtigen, muss MitglPassiv noch angepasst werden: |
|
MitglPassiv (#(MiNr, BezTät)) |
|
Der zusammengesetzte Schlüssel erfüllt die Anforderung, MiNr wird zum Fremdschlüssel. |
|
2.2.3 Lösung |
|
Damit ergibt sich folgende relationale Lösung für die Generalisierung / Spezialisierung. |
|
Textliche Fassung |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, AktPass) //Generalisierung : |
|
MitglAktiv (#MiNr, Sportart, LStufe) //Spezialisierung 1: |
|
MitglPassiv (#(MiNr, BezTät)) //Spezialisierung 2: |
|
Mitglieder.AktPass wird von der Methode nicht verlangt, erleichtert aber die späteren Auswertungen und ist daher aus pragmatischen Gründen sinvoll. |
|
Die relationalen Verknüpfungen erfolgen über die MiNr. Zu den Karadinalitäten und Min-/Max-Angaben vgl. die Abbildung. |
|
Grafische Fassung |
|
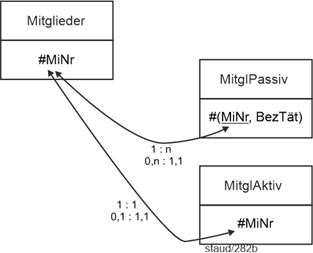
|
|
Abbildung 2.2-1: Grafische Lösung zum Anwendungsbereich Sportverein – Ausschnitt aktiv/passiv |
|
2.3 Basisübung 3 |
|
Auch hier geht es um die Klärung der Relationen in einer Anforderungsbeschreibung und um deren Einbindung in das übrige Datenmodell. |
|
2.3.1 Anforderungsbeschreibung |
|
Es liegt bereits aus den obigen zwei Aufgaben ein Datenmodell vor, das ergänzt werden soll: |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, AktPass) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
MitglPassiv (#(MiNr, BezTät)) |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
MitglVerstorben (#MiNr, Todestag) |
|
Telefone (#(MiNr, Tel)) |
|
Nun soll dieses Datenmodell um (Sport-)Abteilungen und Mannschaften ergänzt werden. Hier die diesbezüglichen Anforderungen: |
|
Der Sportverein ist in Abteilungen (AbtNr, AbtBez) gegliedert (Handball, Fußball, Volleyball, usw.). |
|
Jede Abteilung hat einen Leiter, dessen Mitgliedsnummer hier erfasst werden soll (AbtLeiter). Dieser zählt als aktives Mitglied. |
|
Eine Abteilung kann mehrere Mannschaften haben. Natürlich gehört eine Mannschaft zu genau einer Abteilung. |
|
Von jeder Mannschaft (MaNr, MaBez) werden mit Hilfe der Mitgliedsnummer die Spieler und der Kapitän (KapNr) festgehalten sowie die Liga, in der sie spielt (Bundesliga, usw.). |
|
Jede Mannschaft hat einen (einzigen) Trainer (TrNr). Auch dieser wird festgehalten. Er zählt als aktives Mitglied. |
|
2.3.2 Lösungsschritte |
|
Die sicherlich erste Überlegung nach der Analyse der Anforderungen ist, die Mannschaften als Relation anzulegen und dort die Abteilungszugehörigkeit zu vermerken. Dies wäre aber nicht korrekt, da die Abteilungen nicht nur identifiziert (AbtNr, AbtBez), sondern auch beschrieben werden (AbtLeiter). Deshalb wird für sie eine eigene Relation angelegt: |
|
Abteilungen (#AbtNr, #AbtBez, AbtLeiter) |
|
Da ein Abteilungsleiter aktives Mitglied ist, wird das Attribut Abteilungen.AbtLeiter zum Fremdschlüssel bzgl. der Relation MitglAktiv: |
|
Abteilungen (#AbtNr, #AbtBez, AbtLeiter) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
Anschließend werden in den Anforderungen die Mannschaften angesprochen. Da sie identifiziert (MaNr) und weiter beschrieben werden durch die Mitgliedsnummern des Kapitäns (KapNr), des Trainers (TrNr) und durch die Liga, in der sie spielen, wird auch für sie eine Relation angelegt: |
Mannschaften |
Mannschaften (#MaNr, MaBez, Liga, KapNr, TrNr, …) |
|
In den Anforderungen wurde auch das Verhältnis Abteilungen/Mannschaften beschrieben. Diese 1 :n-Beziehung kann dadurch modelliert werden, dass die Mannschaften die AbtNr als Fremdschlüssel erhalten : |
|
Mannschaften (#MaNr, #MaBez, Liga, KapNr, TrNr, AbtNr, …) |
|
Mehrere Schlüssel können Relationen durchaus haben. Sie werden dann Primärschlüssel und Sekundärschlüssel genannt. Im obigen Beispiel könnte die MaNr als Verknüpfungsattribut dienen und MaBez als identifizierend beschreibendes. |
Mehrere Schlüssel |
Obiger Relation fehlt allerdings noch etwas wichtiges. KapNr und TrNr sind einfach nur Nummern, erst durch die Verknüpfung mit den aktiven Mitgliedern (MitglAktiv) sind diesen Nummern die weiteren Informationen zugeordnet. Deshalb werden KapNr und TrNr hier ebenfalls zu Fremdschlüsseln : |
Kapitän, Trainer |
Mannschaften (#MaNr, MaBez, Liga, KapNr, TrNr, AbtNr) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
Folgende Verknüpfungen liegen bzgl. der Mannschaften damit vor : |
|
- Mannschaften.KapNr mit MitglAktiv.MiNr
- Mannschaften.TrNr mit MitglAktiv.MiNr
- Mannschaften.AbtNr mit Abteilungen.AbtNr
|
|
Bleiben noch die Spieler. Natürlich soll festgehalten werden, welche Spieler in welcher Mannschaft spielen. Wir können sicherlich davon ausgehen, dass Spieler datenbanktechnisch aktive Mitglieder sind. Würde ein aktives Mitglied nur in einer Mannschaft spielen, könnten wir die Mannschaft in MitglAktiv vermerken. Auf Nachfrage erfahren wir aber, dass ein aktives Mitglied durchaus in mehreren Mannschaften spielen kann. Das verändert das Modellfragment. |
Spieler |
Jetzt liegt eine n:m-Beziehung zwischen den beiden Relationen Mannschaften und MitglAktiv vor. Dies erfordert eine Verbindungsrelation, die AM-MA (aktive Mitglieder – Mannschaften) genannt werden soll: |
Verbindungsrelation |
AM-MA (#(MaNr, MiNr)) |
|
Die Kardinalität ist n:m, die Min-/Max-Angaben sind – von den aktiven Mitgliedern zu den Mannschaften 0,n : 0,m. |
|
Wir gehen also davon aus, dass es auch aktive Mitglieder gibt, die nicht in einer Mannschaft sind und dass wir eine Mannschaft erst in der Datenbank aufnehmen, wenn wir zumindest ein Mitglied (z.B. die Kapitänin) angeben können. |
|
2.3.3 Lösung |
|
Insgesamt liegen für dieses Fragment zum Datenmodell Sportverein damit folgende Relationen vor. |
|
Textliche Notation |
|
Abteilungen (#AbtNr, #AbtBez, AbtLeiter) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
Mannschaften (#MaNr, #MaBez, Liga, KapNr, TrNr, AbtNr) //Mehrere Schlüssel |
|
AM-MA (#(MaNr, MiNr)) |
|
|
|
Grafische Fassung |
|
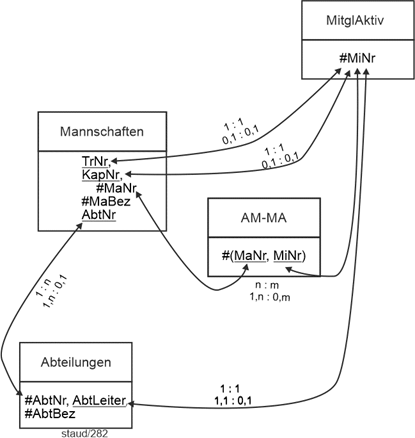
|
|
Abbildung 2.3-1: Anwendungsbereich Sportverein – Fragment Mannschaften/Abteilungen |
|
2.4 Basisübung 4 |
|
Zwei Modellierungsaspekte werden hier betrachtet: |
|
- Die Modellierung von Vorgängen, von Ereignissen mit zeitlicher Dimension.
- Wiederum gilt, dass die neuen Anforderungen in ein bestehendes Datenmodell eingearbeitet werden sollen.
|
|
2.4.1 Anforderungsbeschreibung |
|
Aus den obigen Aufgaben liegt ein Datenmodell zu einem Sportverein vor, das ergänzt werden soll: |
|
Abteilungen (#AbtNr, #AbtBez, AbtLeiter) |
|
AM-MA (#(MaNr, MiNr)) |
|
Mannschaften (#MaNr, #MaBez, Liga, KapNr, TrNr, AbtNr) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
Mitglieder (#MiNr, Name, Vorname, GebTag, Alter, PLZ, Ort, Straße, AktPass) |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
MitglPassiv (#(MiNr, BezTät)) |
|
MitglVerstorben (#MiNr, Todestag) |
|
Telefone (#(MiNr, Tel)) |
|
Es wurde beschlossen, auch die Begegnungen, an denen Mannschaften des Vereins teilnehmen, in der Datenbank zu erfassen. Hier die Anforderungen: |
Begegnungen |
Die Begegnungen von Mannschaften des Vereins sollen mit Datum (Tag), Spielbeginn (Beginn), gegnerischer Mannschaft (Gegner) und Ergebnis festgehalten werden. Falls im Rahmen eines Turniers zwei Mannschaften des Vereins gegeneinander spielen, wird nur ein Eintrag vorgenommen und eine der beiden Mannschaften als „gegnerische“ Mannschaft eingetragen. Für diese Datenbank wird angenommen, dass eine Mannschaft mehrere Spiele an einem Tag haben kann (Turnier!). |
|
2.4.2 Lösungsschritte |
|
Die Anforderungen machen deutlich, dass die Begegnungen nicht in einer der schon bestehenden Relationen erfasst werden können. Sie werden identifiziert durch die Attribute (MaNr, Gegner, Tag, Beginn). Ein solcher Schlüssel mit zugehöriger Relation liegt bisher nicht vor, also ist eine weitere Relation nötig, die Begegnungen genannt werden soll: |
|
Begegnungen (#(MaNr, Gegner, Tag, Beginn)). |
|
Beginn ist im Schlüssel für den Fall dabei, dass tatsächlich zwei Manschaften an einem Tag zwei mal gegeneinander spielen, z.B. bei einem Vereinsturnier. |
|
Es geht nur um Begegnungen des Vereins, nicht z.B. um die einer ganzen Liga zwischen allen Mannschaften. Deshalb ist die in MaNr angesprochene Mannschaft immer die des Vereins. |
|
Dies erlaubt und verlangt die Verknüpfung von Begegnungen mit dem vorliegenden Datenmodell über die Relation Mannschaften. Begegnungen.MaNr wird zum Fremdschlüssel und dient damit der Verknüpfung mit Mannschaften.MaNr. |
|
Begegnungen (#(MaNr, Gegner, Tag, Beginn)). |
|
Mannschaften (#MaNr, #MaBez, Liga, KapNr, TrNr, AbtNr) |
|
Nun fehlt nur noch, das Ergebnis mit in die Begegnungen aufzunehmen : |
|
Begegnungen (#(MaNr, Gegner, Tag, Beginn), Ergebnis). |
|
So weit so gut. Bei der Kontrolle des Ergebnisses sollte man allerdings bemerken, dass der Schlüssel überausgestattet ist. Dies kommt von dem erfassten Zeitpunkt der Begegnung. Zeitpunkte sind alleine schon sehr identifizierend. Liegen sie vor, gilt es nur noch zu bedenken, welches zusätzliche Attribut zum Schlüsselcharakter führt. Hier ist es so, dass eine Mannschaft zu einem Zeitpunkt nur ein Spiel gestalten kann. Also genügt als Schlüssel #(MaNr, Tag, Beginn) und der Gegner wird zum deskriptiven Attribut ohne Schlüsselcharakter : |
Zeitachse, Zeitpunkte |
Begegnungen (#(MaNr, Tag, Beginn), Gegner, Ergebnis). //final |
|
2.4.3 Lösung |
|
Textliche Fassung |
|
Begegnungen (#(MaNr, Tag, Beginn), Gegner, Ergebnis). |
|
Mannschaften (#MaNr, #MaBez, Liga, KapNr, TrNr, AbtNr) |
|
Die Beziehung Begegnungen zu Mannschaften stellt eine Komposition dar. Wenn eine Mannschaft aus der Datenbank gelöscht wird, müssen (datenbanktechnisch) auch ihre Begegnungen verschwinden, da unvollständige Schlüssel nicht zulässig sind. |
Muster Komposition |
Grafische Fassung |
|
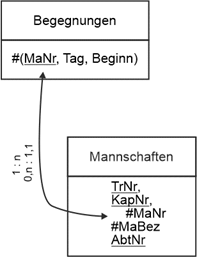
|
|
Abbildung 2.4-1: Anwendungsbereich Sportverein – Fragment Mannschaften/Begegnungen |
|
Alternative |
|
Bei solchen zusammengesetzten Schlüsseln, vor allem, wenn sie noch umfangreicher sind, wird oft ein künstlich generierter Schlüssel gewählt, der das jeweilige Geschehen eindeutig beschreibt. Hier wäre z.B. eine Zeichenkette, bestehend aus Datum, Beginn, Mannschaftsnummer, Kurzbezeichnung der gegnerischen Mannschaft, denkbar. Also z.B. |
Pragmatik |
20230505M001BayMü |
|
… für eine Begegnung am 5.5.2023 zwischen unserer Mannschaft M001 und Bayern München. |
|
Für die Relation ergäbe sich dann: |
|
Begegnungen (#BegebungID, MaNr, Tag, Beginn, Gegner, Ergebnis) |
|
2.5 Sportverein (insgesamt) |
|
Einzelne Fragmente dieser Aufgabe dienten oben in den Basisübungen 1 – 4 zur Wiederholung elementarer Modellierungstechniken. Hier nun die integrierte Fassung. |
|
2.5.1 Anforderungsbeschreibung |
|
Ein Sportverein beschließt, seine Aktivitäten (Mitgliederverwaltung, Sportveranstaltungen, usw.) in Zukunft computergestützt abzuwickeln. Dazu soll eine Datenbank aufgebaut werden, für die folgende Festlegungen getroffen werden: |
|
- Die Mitglieder des Vereins werden durch Name, Vorname (VName), Telefon (Tel), Geburtstag (GebTag), eine Mitgliedsnummer (MiNr) und die Hauptadresse (PLZ, Ort, Straße) festgehalten. Erfasst wird außerdem der Tag des Eintritts (Eintritt) in den Verein. Bei ausgetretenen Mitgliedern ebenfalls der des Austritts (Austritt). Es kommt auch vor, dass ein Mitglied austritt und später wieder eintritt. Auch dies soll in vollem Umfang dokumentiert werden, d.h. vorherige Mitgliedschaften werden nicht gelöscht. Es entsteht so eine Dokumentation aller Ein- und Austritte eines Vereinsmitglieds. Bei verstorbenen Mitgliedern wird der Todestag (Todestag) vermerkt.
- Für die Mitglieder wird erfasst, ob sie passiv oder aktiv sind. Für jedes aktive Mitglied wird dann noch festgehalten, welche Sportart es in welcher Leistungsstufe (LStufe) betreibt. Dies können mehrere sein. Für die passiven Mitglieder wird erfasst, für welche ehrenamtliche Tätigkeit sie zur Verfügung stehen (BezTät). Auch dies können mehrere sein.
- Der Sportverein ist in Abteilungen (AbtNr, AbtBez) gegliedert (Handball, Fußball, Volleyball, usw.).
- Jede Abteilung hat einen Leiter (AbtLeiter). Dieser zählt als aktives Mitglied.
- Eine Abteilung kann mehrere Mannschaften haben. Natürlich gehört eine Mannschaft zu genau einer Abteilung.
- Von jeder Mannschaft (MaNr, MaBez) werden mit Hilfe der Mitgliedsnummer die Spieler und der Kapitän (KapNr) festgehalten sowie die Liga, in der sie spielt (Bundesliga, usw.).
- Jede Mannschaft hat einen (einzigen) Trainer (TrNr). Auch dieser wird festgehalten. Er zählt als aktives Mitglied.
- Die Begegnungen von Mannschaften des Vereins sollen mit Datum (Tag), Spielbeginn (Beginn), gegnerischer Mannschaft (Gegner) und Ergebnis festgehalten werden. Falls im Rahmen eines Turniers zwei Mannschaften des Vereins gegeneinander spielen, wird nur ein Eintrag vorgenommen und eine der beiden Mannschaften als "gegnerische" Mannschaft eingetragen. Für diese Datenbank wird angenommen, dass eine Mannschaft mehrere Spiele an einem Tag haben kann (Turnier!).
2.5.2 Lösungsschritte |
|
Wie sehen nun die konkreten Modellierungsschritte aus? Sinnvoll ist es, zuerst die Objekte und Objektklassen und die zugehörigen Relationen zu suchen. |
Erste Schritte |
Beginnen wir mit den Mitgliedern des Vereins. Diese erkennt man modellierungstechnisch daran, dass es sich erstens um Objekte im allgemeinen Sinn handelt und dass zweitens diese Objekte durch Attribute beschrieben werden. Zweiteres ist von zentraler Bedeutung, denn sonst kann es sich auch um ein Attribut handeln, das andere Objekte beschreibt. Es entsteht also eine Relation Mitglieder. Nehmen wir die in der Anforderung genannten deskriptiven Attribute und den Schlüssel erhalten wir folgende Relation: |
Mitglieder |
Mitglieder (#MiNr, Name, VName, Tel, GebTag, PLZ, Ort, Straße) |
|
Alle Mitglieder sind irgendwann in den Verein eingetreten. Insofern könnte man das Attribut Eintritt zur Relation mithinzunehmen. Da es aber Mitglieder gibt, die ausgetreten sind und solche, die vielleicht später wieder eintreten, stellen diese Mitglieder eine Spezialisierung dar. Die ganz korrekte Lösung wäre es, zwei Relationen anzulegen: |
Eintritt, Austritt, verstorbene Mitglieder |
MitglEintritt (#(MiNr, Datum)) |
|
MitglAustritt (#(MiNr, Datum)) |
|
Der Schlüssel ist zusammengesetzt, da dasselbe Mitglied ja jeweils mehrere Einträge haben kann. |
|
Vertretbar ist aber auch die hier gewählte pragmatische Lösung, die Ein- und Austritte zusammen zu verwalten, auch wenn dabei inhaltlich begründete Leereinträge entstehen, denn das Austrittsdatum wird erst beschrieben, wenn das Mitglied tatsächlich austritt: |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
Auch hier ist der Schlüssel wieder zusammengesetzt aus Mitgliedsnummer und Eintrittsdatum, da nur diese Attributkombination differenziert. In beiden Fällen ist es daher möglich, dass ein Mitglied mehrfach ein- und wieder austritt. |
|
Auch die verstorbenen Mitglieder müssen als Spezialisierung erfasst werden, da diese Eigenschaft und den Todestag die anderen Mitgleider nicht teilen: |
Verstorbene Mitglieder |
MitglVerstorben (#MiNr, Todestag) |
|
Dies macht nochmals deutlich, dass ein Attribut genügt, zu um einer spezialisierten Relation zu kommen. |
|
Bleibt noch die Modellierung der Eigenschaft, aktives oder passives Vereinsmitglied zu sein. Ginge es nur um diese Eigenschaft, würde einfach ein Attribut "aktiv/passiv" mit diesen zwei Eigenschaften an die Relation Mitglieder angefügt. Nun ist es hier aber so, dass für die aktiven und passiven Mitglieder jeweils unterschiedliche Attribute festgehalten werden sollen. Deshalb müssen diese Teilgruppen der Mitglieder getrennt als Spezialisierungen erfasst werden: |
Aktiv / Passiv - Muster Gen/Spez |
MitglAktiv (#MiNr, Sportart, LStufe) |
|
MitglPassiv (#(MiNr, BezTät)) |
|
Die passiven Mitglieder erhalten einen zusammengesetzten Schlüssel. Damit kann datenbanktechnisch ein Mitglied auch mehrere ehrenamtliche Tätigkeiten übernehmen. |
|
Oftmals wird in die "oberste" Relation ganz pragmatisch noch ein Attribut eingefügt, das angibt, zu welcher Spezialisierung das Objekt gehört. Hier könnte z.B. ein Attribut Status in Mitglieder angeben, ob es sich um ein aktives, passives oder verstorbenes Mitglied handelt. Dies erleichtert die Abfragen und Auswertungen sehr stark, denn dadurch kann ohne Abfragen der Spezialisierungen gleich die entsprechende Auswahl getroffen werden. |
Pragmatik |
Insgesamt erhalten wir damit für die Mitglieder folgende Relationen: |
|
Mitglieder (#MiNr, Name, VName, Tel, GebTag, PLZ, Ort, Straße, Status) |
|
MitglEinAus (#(MiNr, Eintritt), Austritt) |
|
MitglVerstorben (#MiNr, Todestag) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
MitglPassiv (#(MiNr, BezTät)) |
|
Hier die grafische Darstellung dieses Modellfragments: |
|
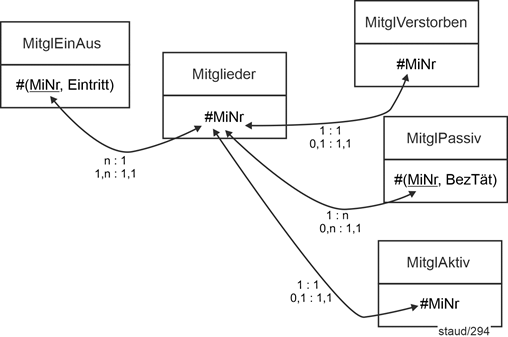
|
|
Abbildung 2.5-1: Mitglieder im Datenmodell Sportverein |
|
Hilfestellung zum Lesen der Wertigkeiten |
|
In der relationalen Verknüpfung zwischen Mitglieder und MitglAktiv kommt eine bestimmte MiNr aus Mitglieder maximal einmal vor, eine bestimmte MiNr aus MitglAktiv genau ein Mal. |
|
In semantischen und objektorientierten Modellen ist es möglich auszudrücken, dass alle Objekte der übergeordneten Einheit (Entitätstyp, Superklasse) an den Spezialisierungen teilhaben. Dies kann in relationalen Modellen nicht ausgedrückt werden. Falls es gewünscht wird, muss es auf andere Weise festgehalten und durch das Anwendungsprogramm sichergestellt werden. |
Totale Beteiligung |
Betrachten wir nun die Mannschaften. Sie tauchen mit folgenden Beschreibungen auf: |
Die Mannschaften |
- Jede Abteilung hat mehrere Mannschaften, insofern könnte "Mannschaft" ein Attribut von Abteilung sein.
- Von jeder Mannschaft werden die Bezeichnung (MaBez), die Spieler, der Kapitän, die Liga, der Trainer und ihre Begegnungen festgehalten.
|
|
Letzteres macht die Mannschaften zu Klassen und dann zu Relationen, da sie durch weitere Attribute beschrieben werden. Trainer und Kapitän sind aktive Mitglieder und werden somit durch einen Fremdschlüssel erfasst. Die Abteilungszugehörigkeit wird im nächsten Schritt geklärt. Damit ergibt sich folgender erster Entwurf: |
|
Mannschaften (#MaNr, #MaBez, Liga, TrNr, KapNr) |
|
Schlüssel, Sekundärschlüssel und Fremdschlüssel |
|
MaNr: Mannschaftsnummer |
|
MaBez: Mannschaftsbezeichnung |
|
TrNr: Trainernummer |
|
KapNr : Kapitänsnummer |
|
Die Zuordnung der Spieler schieben wir auf, da eine Mannschaft mehrere Spieler hat. Die Begegnungen werden ebenfalls später geklärt, da sie durch weitere Attribute zu einer eigenständigen Existenz kommen. |
|
Jetzt müssen noch die Abteilungen betrachtet werden. Für sie wurde oben festgehalten, dass der Verein in Abteilungen gegliedert ist (Handball und Fußball), dass jede Abteilung eine/n Leiter/in und mehrere Mannschaften hat. |
Abteilungen |
In Konfrontation mit den schon erstellten Modellfragmenten lässt sich damit festhalten, dass Abteilungen zu einer Relation mit den Attributen AbtBez und AbtLeiter wird. Die Tatsache, welche Mannschaft zu welcher Abteilung gehört, ist eine 1:n-Beziehung (z.B. als 1,1 : 1,n) und wird daher durch den Fremdschlüssel AbtNr in Mannschaften festgehalten. |
|
Abteilungen (#AbtNr, #AbtBez, AbtLeiter) |
|
Mannschaften (#MaNr, MaBez, Liga, TrNr, KapNr, AbtNr) |
|
Eine Mannschaft hat mehrere Spieler, ein Spieler kann in mehreren Mannschaften sein. Damit liegt eine n:m-Beziehung zwischen Aktiven Mitgliedern (AM) und Mannschaften (MA) vor: |
Spieler |
AM-MA (#(MaNr, MiNr)) |
|
Im beschreibenden Text wurde festgelegt, dass alle Begegnungen von Mannschaften des Vereins mit Tagesdatum, Gegner und Ergebnis festgehalten werden sollen. Da die Mannschaften in einer anderen Relation beschrieben sind, werden sie hier durch den Fremdschlüssel MaNr repräsentiert: |
Begegnungen |
MaNr, Tag, Gegner, Ergebnis |
|
Fehlt noch ein Schlüssel. Dieser könnte realisiert werden, indem bei jeder Begegnung der Beginn des Spiels miterfasst wird. Denn eine Mannschaft kann zwar u.U. an einem Tag mehrere Begegnungen haben, aber nicht mit demselben Startpunkt. Damit werden (MaNr, Tag, Beginn) zu einem Schlüssel und die Relation ergibt sich wie folgt: |
|
Begegnungen (#(MaNr, Tag, Beginn), Gegner, Ergebnis) |
|
Die Beziehung Begegnungen zu Mannschaften stellt eine Komposition dar. Wenn eine Mannschaft aus der Datenbank gelöscht wird, müssen (datenbanktechnisch) auch ihre Begegnungen verschwinden, da unvollständige Schlüssel nicht zulässig sind. |
Muster Komposition |
Zu beachten ist, dass es nur um die Spiele des betrachteten Vereins geht, nicht um alle Spiele einer Liga, was die Situation verändern würde. Oben wurde schon angemerkt, was geschieht, falls ausnahmsweise im Rahmen eines Turniers zwei Mannschaften des Vereins gegeneinander spielen. |
|
2.5.3 Lösung |
|
Insgesamt ergibt sich damit das folgende Datenmodell. |
|
Textliche Fassung |
|
Mitglieder (#MiNr, Name, VName, Tel, GebTag, PLZ, Ort, Straße, Status) |
|
Mitgliedschaften (#(MiNr, Eintritt), Austritt) |
|
MitglVerstorben (#MiNr, Todestag) |
|
MitglAktiv (#MiNr, Sportart, LStufe) |
|
MitglPassiv (#(MiNr, BezTät)) |
|
Begegnungen (#(MaNr, Tag, Beginn), Gegner, Ergebnis) |
|
AM-MA (#(MaNr, MiNr)) |
|
Abteilungen (#AbtNr, AbtBez, AbtLeiter) |
|
Mannschaften (#MaNr, MaBez, Liga, TrNr, KapNr, AbtNr) |
|
Anmerkung: |
|
Folgende Abweichungen gegenüber der Modellierung der Fragmente in den Basisübungen liegen vor: |
|
- Attribut Mitglieder.Status. Es erfasst auch die verstorbenen Mitglieder (Attributsausprägungen aktiv, passiv, verstorben). |
|
- Hier wurde nur ein einziger Telefonanschluss modelliert. Dadurch wird Tel ein ganz normales deskriptives Attribut. |
|
Grafische Fassung |
|
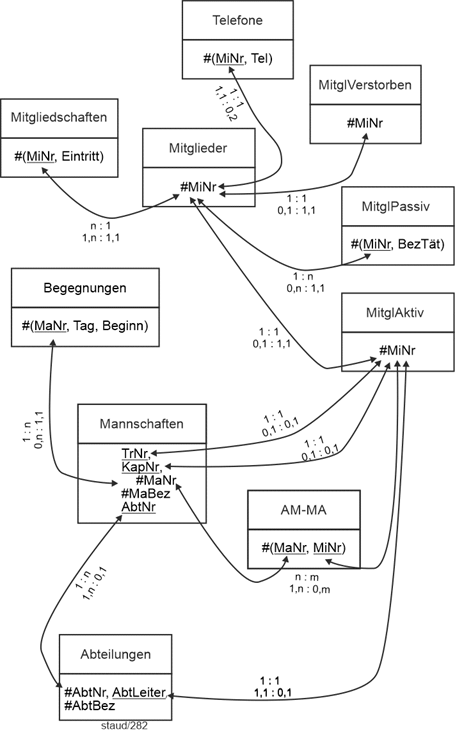
|
|
Abbildung 2.5-2: Gesamtmodell Sportverein |
|
AbtNr: Abteilungsnummer |
|
AbtLeiter: Abteilungsleiter |
|
MaNr: Mannschaftsnummer |
|
MiNr: Mitgliedsnummer |
|
TrNr: Trainernummer |
|
KapNr: Kapitänsnummer |
|
LStufe: Leistungsstufe |
|
BezTät: Bezeichnung der ehrenamtlichen Tätigkeit |
|
|
2.6 Obst |
|
2.6.1 Anforderungsbeschreibung |
|
Ein Einzelhändler möchte seine Obstlieferanten und Obstlieferungen in einer Datenbank verwalten. Für alle Lieferanten erfasst er die Zuverlässigkeit (ZV; Skala von 1 bis 6) und die Art der Abrechnung (AbrArt; sofort, Monatsende, Saisonende, ...). Bezüglich der Landwirte, die ihm Obst liefern, erfasst er Name, Vorname (VName), Typ (biologisch, konventionell, ...), Postleitzahl (PLZ), Ort, Straße, Telefon (nur eines; Tel), Mailadresse (E-Mail) und welche Obstsorten (z.B. Golden Delicious) (SortBez) sie ihm in den einzelnen Monaten typischerweise liefern können ("Lieferbarkeit"). Natürlich bezieht er dieselbe Obstsorte u.U. von unterschiedlichen Landwirten und von einem Landwirt mehrere Obstsorten, z.B. eine Sorte Äpfel, mehrere Sorten Birnen, usw., alles was in der Region wächst. |
|
Bezüglich der Obstgroßhändler erfasst er Firmenname (FName), Land (Deutschland, Österreich, Schweiz, Niederlande, ...) Postleitzahl (PLZ), Ort (Ort), Straße, Telefon (nur eines) (Tel), Fax (Fax), Mailadresse (E-Mail) und - genau wie bei den Landwirten - welche Obstsorten (SortBez) in welchem Zeitraum typischerweise lieferbar sind (z.B. Erdbeeren von Januar bis März, da aus Übersee). Alle Lieferanten (Landwirte oder Großhändler) erhalten eine Lieferantennummer (LiefNr). Aus pragmatischen Gründen erhält jede Obstsorte auch eine identifizierende Nummer (Sortennummer, SortNr). Für jede Obstsorte wird auch festgehalten, wie lagerfähig sie ist (LagFäh), d.h. wieviele Wochen man sie gekühlt aufheben kann. |
|
Weiter sollen konkrete Lieferungen (von Landwirten oder Großhändlern) erfasst werden mit Obstsorte, Menge (Menge), Liefertag (LTag), Lieferant (Landwirt oder Großhändler) und Kilopreis (KPreis). Ein Lieferant liefert höchstens einmal pro Tag, da aber u.U. mehrere Obstsorten. Aus statistischen Gründen wird auch festgehalten, wieviel (in kg) von jeder Obstsorte umgesetzt wurde (Umsatz). Diese Berechnung erfolgt in jedem Jahr neu ab Jahresanfang. |
|
2.6.2 Lösungsschritte |
|
Beim Lesen der Anforderungsbeschreibung sollte man erkennen, dass die Beschreibung der Lieferanten zu der Struktur führt, die man Generalisierung / Spezialisierung nennt. Da gibt es zum einen Landwirte, zum anderen Großhändler und beide haben teilweise identische Attribute. Da beide Gruppen identifiziert und beschrieben werden, ist für sie jeweils eine Relation anzulegen. Für die identischen Attribute ist ebenfalls eine eigene Relation anzulegen. Die erste Annäherung ergibt: |
Generalisierung / Spezialisierung |
- Attribute für alle Lieferanten (Generalisierung): LiefNr, ZV, AbrArt
- Attribute für Landwirte (Spezialisierung 1): Name, VNameTyp, PLZ, Ort, Straße, Tel, E-Mail, SortBez (mehrere)
- Attribute für Großhändler (Spezialisierung 2): FName, Land, PLZ, Ort, Straße, Telefon, Fax, E-Mail
|
|
Schauen wir obige drei Relationenkandidaten an, sehen wir, dass die beiden Spezialisierungen noch identische Attribute aufweisen. Dies muss geändert werden, schließlich sollen Generalisierung und Spezialisierungen bis auf verknüpfende Attribute nur verschiedene haben. Wir nehmen also im nächsten Schritt alle weiteren Attribute, die für alle Lieferanten vorliegen, in die entsprechende Relation: |
|
Lieferanten (#LiefNr, ZV, AbrArt, PLZ, Ort, Straße, E-Mail, Tel) |
|
Natürlich kommen wir gleich ins Grübeln, was die Adressen angeht. Da aber nicht verlangt ist, mehrere Adressen pro Lieferant zu erfassen, können wir es so belassen. |
|
Für die Landwirte bleiben dann noch folgende Attribute übrig: |
|
Landwirte (#LiefNr, Name, Vorname, Typ) |
|
Für die Großhändler: |
|
Großhändler (#LiefNr, FName, Land, Fax) |
|
Wie üblich bei einer Generalisierung / Spezialisierung erhalten alle drei Relationen denselben Schlüssel. Für Anmerkungen zur Verknüpfung vgl. unten. |
|
Pragmatik. Die relationale Theorie verlangt es nicht, aber aus pragmatischen Gründen nimmt man bei einer Gen/Spez oftmals ein Attribut in die Generalisierung, das für jeden Eintrag festhält, zu welcher Spezialisierung er gehört. Das macht SQL-Abfragen sehr viel einfacher, z.B. wenn auf die Spezialisierungen zugegriffen werden soll. Wir ergänzen hier also in Lieferanten ein Attribut Typ mit den zwei Ausprägungen Landwirt (LW) und Großhändler (GH). |
|
Lieferanten (#LiefNr, Typ, ZV, AbrArt, PLZ, Ort, Straße, E-Mail, Tel) |
|
Betrachten wir nun die Lieferbarkeit. Hier deutet die Anforderungsbeschreibung an, dass Landwirte und Großhändler gleich behandelt werden. Folgende Tabelle fasst die beschriebene Semantik zusammen. |
Lieferbarkeit und Obstsorten |
Beispiele für Lieferbarkeit |
|
| LiefNr |
SortBez |
Monat |
| 100 |
Äpfel xyz |
August |
| 100 |
Äpfel xyz |
September |
| 100 |
Birnen xyz |
Oktober |
| 101 |
Birnen xyz |
Oktober |
| ... |
... |
... |
| |
- Ein Lieferant kann mehrere Obstsorten liefern und dies jeweils in verschiedenen Monaten.
- Eine Obstsorte kann von verschiedenen Lieferanten geliefert werden und dies wiederum in verschiedenen Monaten.
|
|
Wir haben also eine Dreierbeziehung, die durch einen Schlüssel mit drei Attributen bewältigt wird: |
|
Lieferbarkeit (#(LiefNr, ObstNr, Monat)) |
|
Wer da Probleme hat, dem hilft die Überlegung, dass erst durch das Attribut Monat jedes Tupel eindeutig wird. Die Unterstreichungen kennzeichnen Fremdschlüssel und deuten Verknüpfungen an. Dazu unten mehr. |
|
Auch für die Obstsorten liegen identifizierende und beschreibende Attribute vor, so dass eine entsprechende Relation entsteht: |
|
Obstsorten (#ObstNr, SortBez, LagFäh) |
|
Die Beziehungen ergeben sich zum Teil methodisch, zum Teil semantisch. Methodisch sind es die zwischen der Generalisierung Lieferanten und den Spezialisierungen Landwirte und Großhändler. Dies wurde oben schon durch den Schlüssel LiefNr umgesetzt. Die Kardinalität einer Beziehung zwischen Generalisierung und Spezialisierung ist 1:1. Da aber in jeder Spezialisierung nur eine Teilmenge der Generalisierung vorliegt, sind die Min-/Max-Angaben (für Landwirte/Lieferanten bzw. Großhändler/Lieferanten) 1,1 : 0,1. |
Beziehungen klären |
Eine semantische Basis haben die „konkreten Lieferungen“ (KonkreteLief). Sie verknüpfen Lieferanten und Obstsorten. Wegen der angeführten Wertigkeiten können wir eine Relation mit einem zusammengesetzten Schlüssel anlegen: |
|
KonkreteLief (#(LiefNr, ObstNr)) |
|
Es fehlt aber noch der Liefertag (LTag). Da jeder Lieferant höchstens einmal pro Tag liefert, können wir LTag noch zum Schlüssel hinzunehmen: |
|
KonkreteLief (#(LiefNr, ObstNr, LTag)) |
|
Wenn wir die beschreibenden Attribute noch hinzufügen erhalten wir die folgende Relation: |
|
KonkreteLief (#(LiefNr, ObstNr, LTag), Menge, KPreis) |
|
Die beiden Fremdschlüssel zeigen die notwendigen relationalen Verknüpfungen zwischen Lieferanten und Obstsorten auf. Die Kardinalität ist n:m, die Min-/Max-Angaben sollen auf 0,n : 0,m festgelegt werden. D.h., wir wollen auch Lieferanten erfassen, von denen noch keine Lieferungen kamen und Obstsorten, die noch nicht geliefert wurden. |
|
Etwas Nachdenken verlangen die abschließenden Ausführungen zu den Jahresmengen. Es ist verlangt, in jedem Jahr für jede Obstsorte den Umsatz im Zeitverlauf hochzurechnen. Dies kann nicht in vollem Umfang durch die Datenmodellierung gelöst, sondern nur vorbereitet werden. Dazu dient die folgende Relation: |
|
Jahresumsätze (#(Jahr, ObstNr), Umsatz) |
|
Eine Verknüpfung kann mit Obstsorten angelegt werden. Die Kardinalität ist (von Obstsorten ausgehend) 1:n, da es nach mehreren Jahren mehrere Jahresumsätze je Obstsorte gibt. Die Min-/Max-Angaben sind, wenn wir annehmen, dass neue Obstsorten nicht gleich in die Messung geraten, 0,n : 1,1. |
|
Durch Datenbankprogrammierung (Trigger, usw.) muss sichergestellt werden, dass bei jedem Eintrag in KonkreteLief in der Relation Jahresumsätze ein Fortschreiben des entsprechenden Umsatzes erfolgt. Am Jahresende muss die Datenbankprogrammierung sicherstellen, dass neue Tupel für das neue Jahr angelegt werden. |
|
Die Relationen sind in der höchsten Normalform: Die BCNF ist erfüllt und es liegen keine Verstöße gegen die 4NF und 5NF vor. Das auftretende Muster (Gen/Spez) wurde eingearbeitet. Weitere liegen nicht vor. Die automatisierte Bestimmung der Jahresumsätze muss mittels Datenbankprorammierung erfolgen. |
Schlussbemerkung |
2.6.3 Lösung |
|
Textliche Fassung |
|
Großhändler (#LiefNr, FName, Land, Fax) |
|
Jahresumsätze (#(Jahr, ObstNr), Umsatz) |
|
KonkreteLief (#(LiefNr, ObstNr, LTag), Menge, KPreis) |
|
Landwirte (#LiefNr, Name, Vorname, Typ) |
|
Lieferanten (#LiefNr, ZV, AbrArt, PLZ, Ort, Straße, E-Mail, Tel) |
|
Lieferbarkeit (#(LiefNr, ObstNr, Monat)) |
|
Obstsorten (#ObstNr, SortBez, LagFäh) |
|
|
|
Grafische Fassung |
|
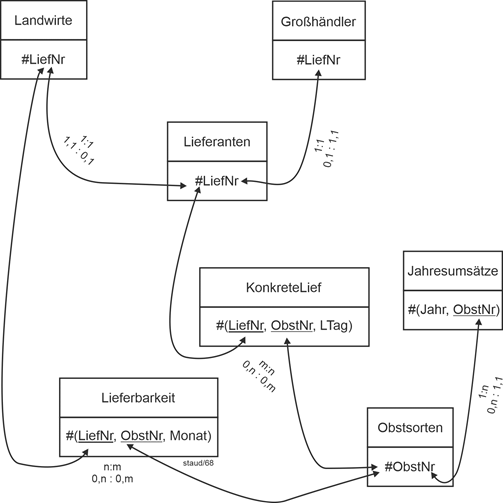
|
|
Abbildung 2.6-1: Relationales Datenmodell Obst |
|
2.7 Angestellte |
|
Diese Aufgabe gehört mit 18 Relationen und zahlreichen Modellmerkmalen (auch zu Zeitaspekten) zu den ausführlichen. |
|
2.7.1 Anforderungsbeschreibung |
|
In diesem Anwendungsbereich geht es um Angestellte eines Unternehmens, ihre Ausstattung mit PC, ihre Mitarbeit in Abteilungen und Projekten, usw. Ausschnitte aus diesem didaktisch motivierten Datenmodell dienen in den Theoriekapiteln von [Staud 2021] als Beispiele. Folgendes soll festgehalten werden: |
|
|
(1) Für die Angestellten die Personalnummer (PersNr), der Name (Name), Vorname (VName) und Geburtstag (GebTag). Außerdem werden die Adressen erfasst mit Strasse, PLZ, Ort und einer zweiten Adresszeile (AdrZ2). Jeder Angestellte kann mehrere Adressen haben und unter einer Adresse können mehrere Angestellte wohnen.
|
|
|
(2) Das Vorgesetztenverhältnis. Wer ist wem unter- bzw. überstellt?
|
|
|
(3) Für die Projekte die Bezeichnung (Bez), der Einrichtungstag (TagEinr), die Dauer (Dauer) und das Budget (Budget). Ein Projekt kann auf mehrere Standorte verteilt sein. Dies wird auch erfasst.
|
|
|
(4) Die Standorte werden mit einer identifizierenden Information (OrtId), ihrer Bezeichnung (Bez), ihrer Adresse und der Anzahl Mitarbeiter am Standort (AnzMitarb) erfasst.
|
|
|
(5) Ein Angestellter kann in mehreren Projekten mitarbeiten und ein Projekt hat typischerweise mehrere Mitarbeiter.
|
|
|
(6) Für die Abteilungen wird die Abteilungsbezeichnung (AbtBez), der Abteilungsleiter (AbtLeiter) und der Standort festgehalten. Eine Abteilung ist immer genau an einem Standort, an einem Standort können mehrere Abteilungen sein.
|
|
|
(7) In einer Abteilung sind mehrere Angestellte, ein Angestellter gehört aber zu einem Zeitpunkt genau zu einer Abteilung. Im Zeitverlauf können Angestellte auch die Abteilung wechseln, was mit BeginnZ(ugehörigkeit) und EndeZ ebenfalls erfasst wird.
|
|
|
(8) Festgehalten wird auch, welche Funktion ein Angestellter in einer Abteilung hat. Dies geschieht mit Hilfe der Funktionsbezeichnung (BezFu), dem Beginn (Beginn) und Ende (Ende) der Funktionsübernahme. Es ist durchaus möglich, dass ein Angestellter im Zeitablauf auch unterschiedliche Funktionen in einer Abteilung übernimmt. Zu einem Zeitpunkt aber immer nur eine.
|
|
|
(9) Für die von den Angestellten benutzten PC wird die Inventarnummer, (InvNr), das Kaufdatum (Kauf), die Bezeichnung (Bez) und der Typ (Standard, Entwickler-PC, Server, …) erfasst. Ein PC kann mehreren Angestellten zugeordnet sein, ein Angestellter nutzt zu einem Zeitpunkt maximal einen PC. Bei der Übernahme eines PC durch einen Angestellten wird die Art der Nutzung (Art; "Entwickler, Office-Nutzer, Superuser"), der Beginn (Beginn) und das Ende (Ende) festgehalten. Natürlich nutzt ein Angestellter im Zeitverlauf mehrere PC, diesbezüglich soll die gesamte Historie festgehalten werden.
|
|
|
(10) Für die Programmiersprachen, die von den Angestellten beherrscht werden, wird die Bezeichnung der Sprache (BezPS), die Bezeichnung des Compilers (BezComp) und der Preis (PreisLiz) für eine Lizenz festgehalten. Wegen der Bedeutung der Programmiererfahrung wird außerdem festgehalten, wieviel Jahre Programmierpraxis (ErfPS) jeder Angestellte in seinen Programmiersprachen hat. Es gibt auch Angestellte, die nicht programmieren und keine Programmiersprache beherrschen.
|
|
|
(11) Für die Entwickler unter den Angestellten wird die von ihnen genutzte Entwicklungsumgebung (EntwU) und ihre hauptsächlich genutzte Programmiersprache festgehalten (HauptPS). Für die Mitarbeiter des Gebäudeservices die Funktion (Funktion) und die Schicht (Schicht), in der sie arbeiten. Für das Top-Management der Bereich in dem sie tätig sind (Bereich) und das Entgeltmodell, nach dem sie ihr Gehalt bekommen (Entgelt).
|
|
2.7.2 Lösungsschritte |
|
Punkt 1 deutet eine Relation zu Angestellten an. Der Schlüssel und zahlreiche weitere Attribute sind bereits angeführt: |
Relationen festlegen |
Angestellte (#PersNr, Name, VName, GebTag) |
|
Mit ihnen kommen die Adressen und der Semantikaspekt, dass jeder Angestellte mehrere Adressen haben kann und unter einer Adresse mehrere Angestellte wohnen können. Hier legen wir schon mal die Adressrelation an, der weitergehende Semantikaspekt wird unten betrachtet. Wir ergänzen einen Schlüssel für die Adressen (AdrId). |
|
Adressen (#AdrId, PLZ, Ort, AdrZ2, Strasse) |
|
Der nächste Punkt gibt einen Hinweis auf das zu erfassende Vorgesetztenverhältnis. Dazu unten mehr. Dann die Projekte (3). Sie werden identifiziert und beschrieben, also können wir eine Relation anlegen : |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
Die Projektmitarbeit setzt Angestellte und Projekte in eine Beziehung. Sie wird deshalb unten modelliert. |
|
Auch die Standorte (Punnkt 4) sind identifiziert und beschrieben, wobei die Klärung der Adressangaben unten erfolgt. Damit ergibt sich erstmal: |
|
Standorte (#OrtId, Bez, AnzMitarb) |
|
Die in (6) angesprochenen Abteilungen sind ebenso sofort als Relationen erkennbar. Es werden eine Bezeichnung und weitere beschreibende Attribute genannt. Für den Standort ergänzen wir ein Attribut Ort: |
|
Abteilungen (#AbtBez, AbtLeiter, Ort) |
|
Das Verhältnis Abteilung/Standort klären wir unten. Auch die nächsten beiden Punkte klären Beziehungsfragen und werden deshalb unten betrachtet. |
|
Danach folgt in (9) die Beschreibung der PC. Beim Lesen dieses Punktes sollte man erkennen, dass hier Einzelgeräte erfasst werden. Diese werden wie folgt beschrieben: |
|
PC (#InvNr, Kauf, Typ, Bez) |
|
Die Zuordnung der PC ist wiederum eine Beziehungsfrage und wird unten umgesetzt. |
|
Der vorletzte Punkt deutet an, dass Software in diesem Unternehmen eine große Rolle spielt. Die Programmiersprachen werden identifiziert und beschrieben, finden also in eine Relation: |
|
PS (#BezPS, BezComp, PreisLiz) |
|
Die Sache mit der Programmiererfahrung gehört wiederum in den nächsten Punkt. |
|
Der letzte Punkt deutet eine Generalisierung / Spezialisierung an. Entwickler, Gebäudeservice und Manager haben als Spezialisierungen jeweils eigene Attribute, zusätzlich zu denen der Generalisierung (Angestellte). Damit ergeben sich folgende Relationen : |
Generalisierung / Spezialisierung |
Entwickler (#PersNr, EntwU, HauptPS) |
|
TopMan (#PersNr, Bereich, Entgelt) |
|
GebService (#PersNr, Funktion, Schicht) |
|
Der Schlüssel ist, wie bei einer Generalisierung / Spezialisierung üblich, derjenige der Generalisierung. |
|
Beziehungen klären |
|
Beginnen wir bei der Präzisierung der Beziehungen wieder mit dem ersten Punkt der Anforderungsbeschreibung. Hier geht es um die Beziehung zwischen Angestellten und Adressen: |
Angestellte / Adressen |
Adressen (#AdrId, PLZ, Ort, AdrZ2, Strasse) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
Die Semantik beschreibt eine n:m-Beziehung. Dies erfordert eine Verbindungsrelation AngAdr mit einem zusammengesetzten Schlüssel: |
|
AngAdr (#(PersNr, AdrNr)) |
|
Die Kardinalität ist n:m. Die Min-/Max-Angaben sind 1,n : 1,m, wenn man die Adressangabe zu einer Pflichtangabe macht (d.h., in der Datenbank gibt es keinen Angestellten ohne Adresse und keine Adresse ohne Angestellten). Denkbar wären aber auch 0,n : 0,m und andere Kombinationen (vgl. Abbildung). |
|
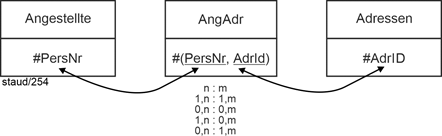
|
|
Abbildung 2.7-1: N:m-Beziehung mit AngAdr und alternativen Min-/Max-Angaben. |
|
Im zweiten Punkt ist gefordert, dass das Vorgesetztenverhältnis zwischen den Angestellten erfasst wird. Dies ist eine rekursive Beziehung (vgl. auch [Staud 2021, Abschnitt 14.3]), die in der relationalen Modellierung durch eine weitere Relation Vorgesetzte gelöst werden muss: |
Vorgesetzte |
Vorgesetzte (#(PersNrV, PersNrU)) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
Damit steht in jedem Tupel von Vorgesetzte an erster Stelle die Personalnummer des Vorgesetzten, an zweiter Stelle die einer untergebenen Person. Beide Attribute sind Fremdschlüssel bzgl. Angestellte.PersNr. Jedes Tupel hält somit ein Vorgesetztenverhältnis fest. In dieser Relation können auch Hierarchien abgebildet werden. Dies ist eine schlichte Lösung des Problems, mehr an Semantik muss in die Anwendungsprogrammierung. |
|
Erinnerung: Angestellte.PersNr bedeutet: Attribut PersNr der Relation Angestellte. |
|
Die nächste zu klärende Beziehung betrifft die zwischen Projekten und Standorten (Punkt 3). Da ein Projekt auf mehrere Standorte verteilt sein kann und da – wie wir auf Nachfrage erfuhren [Anmerkung] – an einem Standort mehrere Projekte angesiedelt sein können, liegt hier eine n:m-Beziehung zwischen Projekten und Standorten vor. Hier die Lösung, ergänzt um die beiden verknüpften Relationen: |
Projekte / Standorte |
ProjOrte (#(BezProj, OrtId)) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
Standorte (#OrtId, Bez, AnzMitarb) |
|
Die Min-/Max-Angaben ergeben sich zu 1,n : 1,m, wenn wir festlegen, dass jedes Projekt ab Einrichtung mindestens einen Standort haben muss und ein Standort erst in die Datenbank aufgenommen wird, wenn mindestens 1 Projekt dort angesiedelt ist. |
|
Auch die Projektmitarbeit (Punkt (5)) hat die Struktur einer n:m-Beziehung. Ein Angestellter kann in mehreren Projekten mitarbeiten, ein Projekt kann mehrere zugeordnete Angestellte haben. Mit den verknüpften Relationen ergibt sich: |
Projekt-mitarbeit |
ProjMitarb (#PersNr, BezProj)) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
Was die Min-/Max-Angaben angeht, können wir davon ausgehen, dass sicherlich nicht alle Angestellten in Projekten tätig sind. Außerdem sei es so, dass ein Projekt datenbanktechnisch schon eingerichtet sein kann, bevor ihm Personal zugewiesen wurde. Damit ergeben sich die Min-/Max-Angaben 0,n : 0,m. |
|
Als nächster Beziehungsaspekt werden in Punkt (6) die Abteilungsstandorte angeführt. So wie es gefordert ist, stellt es eine 1:n-Beziehung dar (Standorte/Abteilungen). Da eine Abteilung nicht ohne Standort existieren kann, wird das Attribut OrtId zu einem Fremdschlüssel in Abteilungen. Wir nehmen an, dass es Standorte auch geben kann, ohne dass dort eine Abteilung angesiedelt ist (weil dort z.B. nur Projekte sind). Dies erfordert die Min-/Max-Angaben 1,n : 0,n. Zusammen mit der beteiligten Relation ergibt sich damit: |
Abteilungen / Standorte |
Abteilungen (#AbtBez, AbtLeiter, OrtId) |
|
Standorte (#OrtId, Bez, AnzMitarb) |
|
Punkt (7) spricht die Abteilungszugehörigkeit an. Nach der Beschreibung ist dies eine 1:n-Beziehung, die durch einen Fremdschlüssel AbtBez in Angestellte modelliert werden könnte. Hier ist aber zusätzlich verlangt, dass die zeitliche Zugehörigkeit ebenfalls erfasst wird mit Anfang (BeginnZ) und Ende (EndeZ) der Zugehörigkeit. Damit ist ein Zeitaspekt zu modellieren: die Zeitabschnitte der Abteilungszugehörigkeit. Da es durchaus vorkommen kann, dass jemand eine Abteilung verlässt und später wieder in sie zurückkommt (vielleicht sogar mehrfach), liegt hier eine n:m-Beziehung mit zeitlicher Dimension zwischen Abteilungen und Angestellten vor. |
Abteilungs-zugehörigkeit |
Da ein Angestellter zu jedem Zeitpunkt einer Abteilung angehören sollte (extreme Sonderfälle sollen mal nicht betrachtet werden), und da eine Abteilung erst eingerichtet wird, wenn zumindest die Abteilungsleiterin feststeht (so soll es hier sein), sind die Min-/Max-Angaben für die Richtung Angestellte/Abteilungen 1,n : 1,m. |
|
Dafür richten wir eine Relation AngAbtZug (Angestellen/Abteilung/Zugehörigkeit) ein, in die neben PersNr und AbtBez auch BeginnZ und EndeZ rein müssen. |
|
Mit der Aufnahme von Beginn und Ende der Zugehörigkeit, können die unterschiedlichen Phasen erfasst werden. Z.B. kann eine Angestellte vom 1.1.2020 bis zum 20.6.2023 und vom 4.5.2021 bis zur Gegenwart in einer bestimmten Abteilung gewesen sein. Um Eindeutigkeit zu erreichen, muss ein Zeitpunkt in den Schlüssel. Wir nehmen hier BeginnZ. |
|
Die zeitliche Dimension führt im Fall von Zeiträumen dazu, dass gegen die „reine“ relationale Lehre verstoßen werden muss. Denn dabei entsteht ein Attribut (hier: EndeZ), das semantikbedingt leere Einträge hat (bis zum Ende des Zeitraums, hier: der Zugehörigkeit) und dies sollte in relationalen Datenbanken nicht sein. Eine eigene Relation für EndeZ wäre möglich, darauf wird aber aus pragmatischen Gründen i.d.R. verzichtet. |
Zeitliche Dimension |
Der Schlüssel enthält zum einen PersNr und AbtBez, muss zum anderen um BeginnZ erweitert werden. Insgesamt wird diese Beziehung dann durch folgende Relationen beschrieben: |
|
AngAbtZug (#(PersNr, AbtBez, BeginnZ), EndeZ) |
|
Abteilungen (#AbtBez, AbtLeiter, OrtId) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
In Punkt (8) wird gefordert, dass auch die Funktionen, die Angestellte in Abteilungen übernehmen, in der Datenbank erfasst werden. Basis ist wieder die 1:n-Beziehung zwischen Angestellten und Abteilungen. Hier muss sie ergänzt werden um die Attribute der Funktionsbeschreibung: BezFu, BeginnF, EndeF. Da auch hier ein wiederholtes Beenden und Wiederaufnehmen möglich ist und zu einem Zeitpunkt nur eine einzige Funktion übernommen wird, ist die folgende Relation AngAbtFu korrekt. |
|
Zur Wertigkeit liegen keine Angaben vor. Wir nehmen daher an, dass eine Angestellte in einer Abteilung in einem Zeitraum nur jeweils eine Funktion übernimmt und dass eine Abteilung keine, eine oder mehrere Funktionen zu vergeben hat. Damit ergibt sich die Kardinalität n:m und die Min-/Max-Angaben 0,1 : 0,m. |
|
AngAbtFu (#(PersNr, AbtBez, BeginnF), EndeF, BezFu)) |
|
Die Funktionsübernahme kann damit vollständig in die Relation AngAbtFu aufgenommen werden. Der Schlüssel muss BeginnF enthalten (möglich wäre auch EndeF), dadurch sind auch mehrere zeitlich verschobene Funktionsübernahmen möglich. |
|
Die Struktur wäre durch leichte semantische Änderungen eine andere, z.B. wenn mehr als eine Funktion in einem Zeitraum übernommen werden könnte. |
|
Punkt (9) klärt die Zuordnung von PC zu Angestellten. In der Beschreibung wird eine 1:n-Beziehung deutlich, was normalerweise einfach zu einem Fremdschlüssel führt. Hier ist aber wieder für diese PC-Nutzung Beginn, Ende und Art der Nutzung zu erfassen und dies so, dass auch mehrere Nutzungsphasen modelliert werden können. |
PC und Angestellte |
Wir müssen also die einfache Relation |
|
PC-Nutzung (#(PersNr, InvPC)) |
|
oder |
|
PC-Nutzung(#InvPC, PersNr) |
|
(wenn eine Person nur einen PC hat) ergänzen. Zum einen machen wir PersNr und Beginn gemeinsam zum Schlüssel. Damit erfasst diese Relation nicht mehr nur Personen, sondern Zeiträume. Hinzu muss auch Ende zur Beschreibung des Zeitraums und Art für die Nutzung sowie InvPC als Fremdschlüssel, damit festgehalten wird, um welchen PC es sich handelt. |
|
Die Min-/Max-Angaben ergeben sich (von PC zu Angestellte) zu 0,n : 0,1, wenn PC auch erfasst werden sollen, bevor sie zugewiesen sind und man die Möglichkeit bestehen lassen will, dass es Angestellte (in der Datenbank) gibt, die noch keinen PC zugewiesen bekommen haben. |
|
Zusammen mit den verknüpften Relationen ergibt sich dann: |
|
AngPC (#(PersNr, Beginn), InvNrPC, Art, Ende) |
|
PC (#InvNr, Kauf, Typ, Bez) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
Bei den Programmiersprachen zielt die weitere Beschreibung in Punkt 10 auf die Erfassung der Programmiererfahrung. Es soll also ganz grundsätzlich die Beziehung zwischen Angestellten und Programmiersprachen festgehalten werden („wer kann in Java programmieren?“) und die Anzahl der Erfahrungsjahre. |
|
Durch die Mehrzahl bei Programmiersprachen ist die die Kardinalität n:m. Die Min-/Max-Angaben sind 0,n : 0,m, da ja Angestellte dabei sind, die nicht programmieren und wir auch Programmiersprachen in der Datenbank erfassen wollen, die zwar angeschafft wurden, aber noch nicht eingesetzt werden. |
|
Dies erfordert wieder eine eigene Relation AngPS für diese Beziehung zwischen PS und Angestellte. |
|
AngPS (#(BezPS, PersNr)) |
|
PS (#BezPS, BezComp, PreisLiz) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
Sehr oft gibt es in Anforderungsbeschreibungen nur indirekte Hinweise auf Beziehungen. Ein Beispiel ist hier die Beziehung zwischen Abteilungen und Abteilungsleitern. Nehmen wir folgendes an: |
Vergessene Anforderungen |
- Eine Angestellte kann keine, eine oder in Ausnahmefällen auch mal mehr Abteilungen leiten.
- Eine Abteilung wird immer genau von einem Angestellten geleitet und auch erst eingerichtet, wenn ein solcher ernannt ist.
|
|
Damit ist die Kardinalität (Angestellte/Abteilungen) 0:n und Abteilung.AbtLeiter wird zum Fremdschlüssel. Die Min-/Max-Angaben sind 0,m : 1,1. |
|
Abteilungen (#AbtBez, AbtLeiter, OrtId) |
|
Restliche Prüfung |
|
Dadurch, dass bei der Bildung der Relationen auf die Einhaltung der Struktur „ein Schlüssel und nur davon abhängige Attribute“ geachtet wurde, war die höchste Normalform gesichert. Das führte auch zu den Lösungen rund um die Muster, z.B. indem Spezialisierungen in eigene Relationen mit dem Schlüssel der Generalisierung kommen. Auch Verstöße gegen die 4NF und 5NF liegen hier nicht vor. |
|
Gegen die Grundlagen der relationalen Theorie verstoßen die Attribute, die erstmal keine Werte aufweisen können („Ende Zeitraum“), weil ihre Werte erst später anfallen. Streng nach der reinen Lehre wären hier eigene Relationen nötig. |
|
2.7.3 Lösung |
|
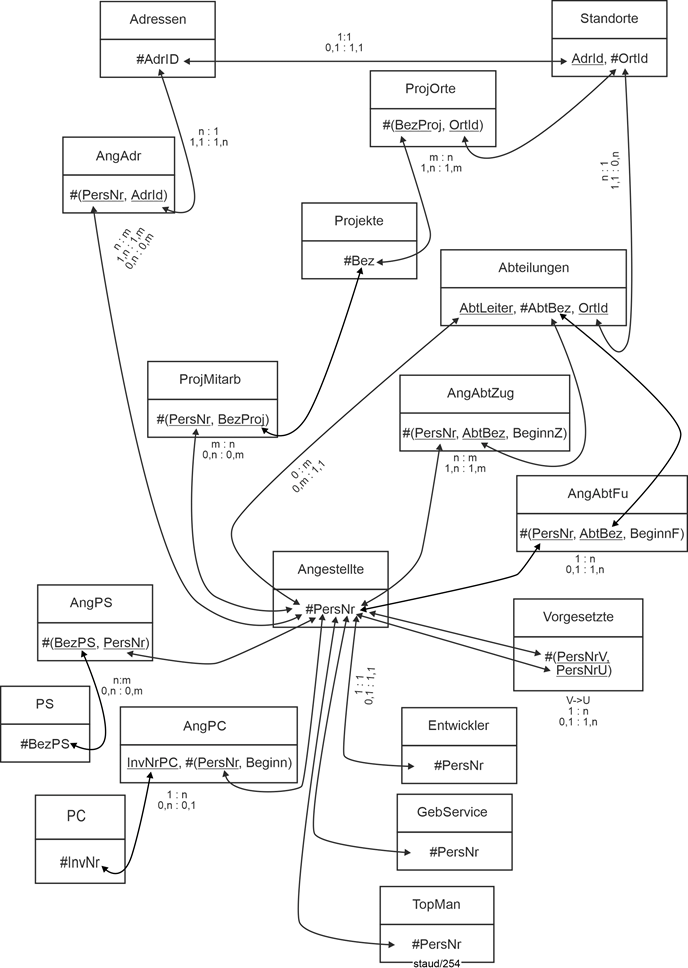
Insgesamt gehören zum Datenmodell nun folgende Relationen. |
|
Textliche Fassung |
|
Abteilungen (#AbtBez, AbtLeiter, OrtId) |
|
Adressen (#AdrId, PLZ, Ort, AdrZ2, Strasse) |
|
AngAbtFu (#(PersNr, AbtBez, BeginnF), EndeF, BezFu)) |
|
AngAbtZug (#(PersNr, AbtBez, BeginnZ), EndeZ) |
|
AngAdr (#(PersNr, AdrNr)) |
|
Angestellte (#PersNr, Name, VName, GebTag) |
|
AngPC (#(PersNr, Beginn), InvNrPC, Art, Ende)) |
|
AngPS (#(PersNr, BezPS), ErfPS) |
|
Entwickler (#PersNr, EntwU, HauptPS) |
|
GebService (#PersNr, Funktion, Schicht) |
|
PC (#InvNr, Kauf, Typ, Bez) |
|
Projekte (#Bez, TagEinr, Dauer, Budget) |
|
ProjMitarb (#PersNr, BezProj)) |
|
ProjOrte (#(BezProj, OrtId)) |
|
PS (#BezPS, BezComp, PreisLiz) |
|
Standorte (#OrtId, Bez, AnzMitarb, AdrId) |
|
TopMan (#PersNr, Bereich, Entgelt) |
|
Vorgesetzte (#(PersNrV, PersNrU)) |
|
|
|
Grafische Fassung |
|
|
|
Abbildung 2.7-2: Relationales Datenmodell zum Anwendungsbereich Angestellte |
|
2.8 Sprachenverlag |
|
Diese Aufgabe gehört mit 15 Relationen, zahlreichen Modellmerkmalen und Mustern zu den ausführlichen. |
|
2.8.1 Anforderungsbeschreibung |
|
Es geht um die Produkte eines Verlages, der Wörterbücher (z.B. von Deutsch nach Englisch), digital oder auch gedruckt, herstellt und verkauft und der seit einiger Zeit auch Übersetzungsprogramme anbietet. Seine Produkte sollen in einer Datenbank verwaltet werden. Zu erfassen sind die nachfolgend angeführten Sachverhalte: |
|
|
(1) Alle Produkte, d.h. alle Wörterbücher und Volltextübersetzer (Programm zur automatischen Übersetzung von Text) mit ihrer Produktnummer (ProdNr) und Bezeichnung (Bez), mit ihrem Listenpreis (LPreis) und den Sprachen, die abgedeckt sind (z.B. deutsch nach englisch und englisch nach deutsch, deutsch nach französisch und französisch nach deutsch).
|
|
|
(2) Für jedes gedruckte Wörterbuch wird auch festgehalten, wieviele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, "Anwender", "Profi-Anwender", Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDat), wieviele Seiten es hat (AnzSeit).
|
|
|
(3) Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDat), welche Speichertechnik (SpeichTech) bei ihm verwendet wurde, wieviele Einträge es umfasst (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, "Anwender", "Profi-Anwender", Übersetzer) (Zielgruppe).
|
|
|
(4) Die digitalen Produkte des Verlags beruhen jeweils auf einem Übersetzungsprogramm (BezProg). Es kann sein, dass eines mit verschiedenen Programmen angeboten wird (z.B. zielgruppenspezifisch). Natürlich dient ein Programm u.U. mehreren digitalen Produkten. Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.; mehrere) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK: Integrierbarkeit).
|
|
|
(5) Für jeden Volltextübersetzer wird auch festgehalten, welche Sprachen abgedeckt sind, wieviele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird außerdem, ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf.
|
|
|
(6) Für alle Programme werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die der Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm in Kooperation von mehreren Softwarehäusern erstellt wird. Natürlich bietet ein bestimmtes Softwarehaus u.U. mehrere Programme an, z.B. für verschiedene Sprachen. Es wird bzgl. eines jeden Programms der Beginn und das Ende der Zusammenarbeit vermerkt.
|
|
|
(7) Für alle digitalen Produkte werden außerdem die Systemvoraussetzungen festgehalten, abhängig vom eingesetzten Programm. Welche minimale Hardwareanforderung gegeben ist (anhand des Prozessors, Proz), wieviel Arbeitsspeicher sie benötigen (ArbSp), wieviel freier Plattenspeicher (PlattSp) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann (Windows Vista, 7, 8; LINUX). Dies sind in der Regel mehrere.
|
|
|
(8) Erfasst werden auch die konkreten Geräte, auf denen die digitalen Produkte lauffähig sind mit ihrer Bezeichnung (Bez) und dem Gerätetyp (Typ; Smartphone, Pad, Tablet, Laptop, usw.). Auf einem Gerät sind natürlich mehrere digitale Produkte lauffähig, dagegen werden die digitalen Produkte am Ende ihrer Entwicklung auf genau ein Gerät zugeschnitten. Besteht das jeweilige Gerät nicht mehr, wird auch das zugehörige digitale Produkt überflüssig.
|
|
|
(9) Die Entwicklung der Programme findet so statt, dass jedes Programm mit unterschiedlichen grafischen Bedienoberflächen (GUI; graphical user interface) kombiniert werden kann. Für die GUIs wird ein Schlüssel (GUIId), der Typ (Fenster, Kacheln, ...) und die Programmiersprache (PS), mit der sie entwickelt wurde, festgehalten. Ein konkretes vom jeweiligen Softwarehaus angebotenes Programm enthält dann genau eine GUI, d.h. die Programme sind nach ihren GUIs differenziert.
|
|
2.8.2 Lösungsschritte |
|
Hier nun die schrittweise Umsetzung des Textes in ein relationales Datenmodell. Sie erfolgt, indem die Anforderungen nacheinander Absatz für Absatz bearbeitet werden. |
|
Anforderung Teil 1 |
|
Alle Produkte, d.h. alle Wörterbücher und Volltextübersetzer (Programm zur automatischen Übersetzung von Text) mit ihrer Produktnummer (ProdNr) und Bezeichnung (Bez), mit ihrem Listenpreis (LPreis) und den Sprachen, die abgedeckt sind (z.B. deutsch nach englisch und englisch nach deutsch, deutsch nach französisch und französisch nach deutsch). |
|
Dem Text kann entnommen werden, dass es Produkte gibt und dass diese (erstmal) aus Wörterbüchern und Volltextübersetzern bestehen. Nennen wir sie auch Produkte und geben ihnen den Schlüssel ProdNr. Außerdem wird auf die abgedeckten Sprachen hingewiesen. Da dies immer zwei sind, legen wir zwei Attribute Sprache1 und Sprache2 an. Z.B. also mit den Einträgen Italienisch und Deutsch. |
|
Produkte (#ProdNr, Bez, LPreis, Sprache1, Sprache2) |
|
Anforderung Teil 2 |
|
Für jedes gedruckte Wörterbuch wird auch festgehalten, wieviele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, "Anwender", "Profi-Anwender", Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDat), wieviele Seiten es hat (AnzSeit). |
|
Das Wort "auch" macht deutlich, dass es sich um eine Variante handelt, die evtl. zusätzliche Attribute hat. Dies ist hier auch der Fall, so dass eine Spezialisierung für gedruckte Wörterbücher eingerichtet werden muss. Sie wird WBGedr genannt und hat (erstmal) die folgenden Attribute. |
|
WBGedr (#ProdNr, Einträge, Zielgruppe, ErschDat, AnzSeiten) |
|
Anforderung 3 |
|
Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDat), welche Speichertechnik (SpeichTech) bei ihm verwendet wurde, wieviele Einträge es umfasst (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, "Anwender", "Profi-Anwender", Übersetzer) (Zielgruppe). |
Generalisierung / Spezialisierung |
Wieder taucht in der Anforderungsformulierung das Wort "auch" auf. Die neue Produktvariante hat dann auch eine Spezialisierung: Digitale Wörterbücher. Diese Relation wird WBDig genannt: |
|
WBDig (#ProdNr, Einträge, Zielgruppe, ErschDat, SpeichTech) |
|
Da in WBDig zum Teil dieselben Attribute wie in WBGedr vorliegen, kann eine Generalisierung dieser beiden Relationen mit Einträge, ErschDatum und Zielgruppe gebildet werden. Dieses Muster Gen/Spez muss man nun erkennen, z.B. anhand der Semantik ("Ähnlichkeit") oder der identischen Attribute. Die Bereinigung ergibt eine Relation für Wörterbücher und je eine "abgeschlankte" für die digitalen und gedruckten Wörterbücher. |
|
Damit entstehen folgende neue bzw. veränderte Relationen: |
|
WB (#ProdNr, Einträge, Zielgruppe, ErschDat) |
|
WBDig (#ProdNr, SpeichTech) |
|
WBGedr (#ProdNr, AnzSeiten) |
|
WB ist Spezialisierung von Produkte, WBDig und WBGedr sind Spezialisierungen von WB. Von der Generalisierung ausgehend ist die Kardinalität 1:1 und die Min-/Max-Angaben sind 0,1 : 1,1. |
|
Will man eine nicht simple Gen/Spez-Struktur durchdringen, lohnt sich die Anlage einer Tabelle mit den Attributen der beteiligten Relationen, wie es die folgenden Abbildungen zeigen. In der Kopfzeile sind die einzelnen Produkte angesiedelt, darunter zeilenweise die Attribute. Die obersten Zeilen geben die Attribute an, die alle Produkte haben, darunter dann die für die einzelnen Spezialisierungen. |
|
Gen/Spez-Tabelle 1: Produkte und ihre Spezialisierungen - Version 1-A |
|
| Produkte |
WB |
WBGedr |
WBDig |
| ProdNr |
ProdNr |
ProdNr |
ProdNr |
| Bez |
Bez |
Bez |
Bez |
| LPreis |
LPreis |
LPreis |
LPreis |
| Sprache1 |
Sprache1 |
Sprache1 |
Sprache1 |
| Sprache2 |
Sprache2 |
Sprache2 |
Sprache2 |
| |
Einträge |
Einträge |
Einträge |
| |
Zielgruppe |
Zielgruppe |
Zielgruppe |
| |
ErschDat |
ErschDat |
ErschDat |
| |
|
AnzSeiten |
|
| |
|
|
SpeichTech |
| |
Schon diese Tabelle zeigt die Gen/Spez-Struktur auf. Noch übersichtlicher wird es, wenn man in jeder Spalte die Attribute weg lässt, die in der übergeordneten Generalisierung enthalten sind: |
|
Gen/Spez-Tabelle 1: Produkte und ihre Spezialisierungen - Version 1-B |
|
| Produkte |
WB |
WBGedr |
WBDig |
| ProdNr |
|
|
|
| Bez |
|
|
|
| LPreis |
|
|
|
| Sprache1 |
|
|
|
| Sprache2 |
|
|
|
| |
Einträge |
|
|
| |
Zielgruppe |
|
|
| |
ErschDat |
|
|
| |
|
AnzSeiten |
|
| |
|
|
SpeichTech |
| |
Hier ist jetzt der Spezialisierungszusammenhang klar erkennbar. WBDig „erbt“, wie es in der objektorientierten Programmierung genannt wird, die Attribute von WB und von Produkte. |
|
Anforderung Teil 4 |
|
Die digitalen Produkte des Verlags beruhen jeweils auf einem Übersetzungsprogramm (BezProg). Es kann sein, dass eines mit verschiedenen Programmen angeboten wird (z.B. zielgruppenspezifisch). Natürlich dient ein Programm u.U. mehreren digitalen Produkten. Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.; mehrere) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IBK: Integrierbarkeit). |
Digitale Produkte |
Anforderung 4 beschreibt die digitalen Produkte näher. Der erste Teil legt außerdem auch eine n:m-Beziehung zwischen Produkten und Programmen fest, so dass sich die Relation ProdDig ergibt. Die Programme werden durch die beiden Attribute DokArt und IBK datenbanktechnisch existent, wegen der n:m-Beziehung zwischen Programmen und Dokumentart sogar in zwei Relationen. |
|
Damit kommen folgende Relationen dazu: |
|
Programme (#BezProg, IBK) |
|
ProgDokArt (#(BezProg, DokArt)) |
|
ProdDig (#(ProdNr, BezProg)) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: |
|
- Von Produkte zu ProdDig: 1:n bzw. 0,n : 1,1
- Von Programme zu ProdDig: 1:n bzw. 0,n : 1,1, da wir davon ausgehen, dass es auch (datenbanktechnisch) Programme geben kann, die noch nicht in einem digitalen Produkt verarbeitet sind.
- Von Programme zu ProgDokArt: 1:n bzw. 0,1 : 1,n.
|
|
Anforderung Teil 5 |
|
Für jeden Volltextübersetzer wird auch festgehalten, welche Sprachen abgedeckt sind, wieviele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde (ErschDatum). Festgehalten wird außerdem, ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf. |
|
2.8.3 Lösung durch Umbenennung |
|
Die Beschreibung der Produkte geht damit weiter und die Volltextübersetzer (VTÜ) werden als Relation eingeführt. Die hier genannten Attribute der Volltextübersetzer sind aber bis auf eines in WB enthalten. Deshalb ändern wir den Namen von WB in WB+VTÜ (Wörterbücher und Volltextübersetzer). Dies ist eine pragmatische aber angemessene Lösung, denn normalerweise gibt es keine zwei Relationen mit identischem Schlüssel. Für die Volltextübersetzer mit Aktualisierungsmöglichkeit wird eine neue Relation VTÜAkt angelegt: |
|
WB+VTÜ (#ProdNr, Einträge, Zielgruppe, ErschDat) |
|
VTÜAkt (#ProdNr, AktJahre) |
|
Auch die Gen/Spez-Tabelle ändert sich damit (die bei den anderen Produkten vorkommenden Attribute wurden gleich weggelassen): |
|
Gen/Spez-Tabelle 2: Produkte und ihre Spezialisierungen |
|
| Produkte |
WB+VTÜ |
WBGedr |
WBDig |
VTÜAkt |
| ProdNr |
|
|
|
|
| Bez |
|
|
|
|
| LPreis |
|
|
|
|
| Sprache1 |
|
|
|
|
| Sprache2 |
|
|
|
|
| |
Einträge |
|
|
|
| |
Zielgruppe |
|
|
|
| |
ErschDat |
|
|
|
| |
|
AnzSeiten |
|
|
| |
|
|
SpeichTech |
|
| |
|
|
|
AktJahre |
| |
Um nicht den Überblick zu verlieren und um die Gen/Spez-Struktur ganz deutlich zu machen, hier die an diesem Fragment beteiligten Relationen, textlich und grafisch. |
|
Produkte (#ProdNr, Bez, Lpreis, Sprache1, Sprache2) |
|
VTÜAkt (#ProdNr, AktJahre) |
|
WB+VTÜ (#ProdNr, Einträge, Zielgruppe, ErschDat) |
|
WBDig (#ProdNr, SpeichTech) |
|
WBGedr (#ProdNr, AnzSeiten) |
|
Die Kardinalitäten und Min-/Max-Angaben sind damit jetzt wie folgt: |
|
- Von WB+VTÜ zu WBGedr: 1:1 bzw. 0,1 : 1,1
- Von WB+VTÜ zu WBDig: 1,1 bzw. 0,1 : 1,1
- Von WB+VTÜ zu VTÜAkt: 1,1 bzw. 0,1 : 1,1
- Von Produkte zu WB+VTÜ: 1,1 bzw. 0,1 : 1,1. Wir lassen also datenbanktechnisch Produkte zu, die weder Wörterbücher (WB) noch Volltextübersetzer (VTÜ) sind.
|
|
|
|
Abbildung 2.8-1: Generalisierung / Spezialisierung rund um Produkte |
|
Anforderung Teil 6 |
|
Für alle Programme werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm in Kooperation von mehreren Softwarehäusern erstellt wird. Natürlich bietet ein bestimmtes Softwarehaus u.U. mehrere Programme an, z.B. für verschiedene Sprachen. Es wird bzgl. eines jeden Programms der Beginn und das Ende der Zusammenarbeit vermerkt. |
|
Hier werden nun die Softwarehäuser zu Datenbankobjekten. Da für sie gleich auch noch Attribute vorliegen, kann eine Relation angelegt werden. Außerdem auch für die Beziehung zwischen den Softwarehäusern und den Programmen. Diese ist vom Typ n:m und hat eine Zeitkomponente (Zeitabschnitte). Es genügt, den Beginn der Zusammenarbeit in den Schlüssel aufzunehmen, damit können mehrere solche Phasen unterschieden werden. Daraus folgen weitere Relationen: |
Zeitaspekt in Beziehung |
SWHäuser (#SWHNr, PLZ, Ort, Straße, eMail) |
|
SWHProg (#(SWHNr, BezProg, Beginn), Ende) |
|
Programme (#BezProg, IBK) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Programme über SWHProg zu SWHäuser: n:m bzw. 1,n : 1,m |
|
Anforderung Teil 7 |
|
Für alle digitalen Produkte werden außerdem die Systemvoraussetzungen festgehalten, abhängig vom eingesetzten Programm. Welche minimale Hardwareanforderung gegeben ist (anhand des Prozessors, Proz), wieviel Arbeitsspeicher sie benötigen (ArbSp), wieviel freier Plattenspeicher (PlattSp) nötig ist (in MB) und welche Betriebssystemversion (BS) genutzt werden kann (Windows 7, 8, 10, 11; LINUX). Dies sind in der Regel mehrere. |
|
Zuerst scheint der Text eine Erweiterung der Beschreibung der digitalen Produkte zu enthalten. Die Formulierung "abhängig vom eingesetzten Programm" zeigt aber, dass Objekte gemeint sind, die durch die Kombination aus Produkt und Programm identifiziert sind. Deshalb wird die Relation ProdDig hier um die drei Attribute Proz, ArbSp und PlattSp ergänzt. |
|
Bleiben noch die Betriebssysteme. Da u.U. mehrere Betriebssysteme für ein digitales Produkt tauglich sind, muss eine Relation erstellt werden, die das Attribut BS mit im Schlüssel hat: ProdDigBS. Dadurch kommt es zu einer eher seltenen Konstellation: einem Fremdschlüssel, der aus zwei Attributen besteht. ProdDig hat den Schlüssel #(ProdNr, BezProg), ProdDigBS den Fremdschlüssel (ProdNr, BezProg). Zusammen mit Programme liegen dann folgende geänderten und neuen Relationen vor: |
|
ProdDig (#(ProdNr, BezProg), Proz, ArbSp, PlattSp) |
|
ProdDigBS (#((ProdNr, BezProg), BS) //innere Klammer nur wegen derAnschaulichkeit |
|
Programme (#BezProg, IBK) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von ProdDig zu ProdDigBS: 1:n bzw. 1,n : 1,m |
|
Anforderung Teil 8 |
|
Erfasst werden auch die konkreten Geräte, auf denen die digitalen Produkte lauffähig sind mit ihrer Bezeichnung (Bez) und dem Gerätetyp (Typ; Smartphone, Pad, Tablett, Laptop, usw.). Auf einem Gerät sind natürlich mehrere digitale Produkte lauffähig, dagegen werden die digitalen Produkte am Ende ihrer Entwicklung auf genau ein Gerät zugeschnitten. Besteht das jeweilige Gerät nicht mehr, wird auch das zugehörige digitale Produkt überflüssig. |
|
Damit ergibt sich eine Relation zu Geräten. Außerdem kann die Gerätebezeichnung als Teilschlüssel in den Schlüssel von ProdDig aufgenommen werden, denn ein Gerät ist auf mehreren digitalen Produkten lauffähig. Dies führt zu neuen bzw. veränderten Relationen: |
|
Geräte (#Bez, Typ) |
|
ProdDig (#(ProdNr, BezProg, BezGerät), Proz, ArbSp, PlattSp) |
|
Ist das wirklich korrekt? Bei näherem Hinsehen entsteht ein leichtes Unbehagen. Wird nicht Proz, ArbSp und PlattSp alleine durch ProdNr und BezProg bestimmt? Was tut dann, diesbezüglich, BezGerät im Schlüssel. Würden die drei beschreibenden Geräte auch durch das jeweilige Gerät mit bestimmt, wäre das in Ordnung. Nach der Beschreibung ist dies aber nicht anzunehmen. Der Bedarf an Hardwarekapazitäten wird wohl geräteunabhängig bestimmt. Um ein solches Unbehagen zu beseitigen, ist ein FA-Diagramm gut geeignet: |
Unbehagen |
|
|
Abbildung 2.8-2: FA-Diagramm der Relation ProdDig_1NF |
|
Das macht die Problematik klar. Die Relation ist nicht mal in 2NF. Deshalb muss normalisiert werden. Es entstehen die folgenden Relationen (als FA-Diagramme). |
|
|
|
Abbildung 2.8-3: FA-Diagramm der Relationen ProdProgGer_5NF und ProdDig_5NF |
|
Damit ergibt sich eine veränderte Relation ProdDig (die der "vorletzten" Fassung entspricht) und eine neue Relation zu der Beziehung von Produkten, Programmen und Geräten. Sie hält fest, in welcher konkreten Konstellation die drei Komponenten zusammengefügt werden können: |
|
ProdDig (#(ProdNr, BezProg), Proz, ArbSp, PlattSp) |
|
ProdProgGer (#(ProdNr, BezProg, BezGerät)) |
|
Es soll an dieser Stelle nicht verschwiegen werden, dass ProdProgGer in der Praxis ein Kandidat für die Einführung eines Schlüssels wäre, der in seiner Zusammensetzung die jeweils konkrete Konstellation ausdrückt, z.B. PPGId (ProduktProgrammGerätId). Dann würden die drei Attribute a) zu einem Sekundärschlüssel und b) zu beschreibenden Attributen: |
Konstruierter Schlüssel. |
ProdProgGer-Alternative (#PPGId, (ProdNr, BezProg, BezGerät)) |
|
Wir belassen es hier aber bei der obigen Lösung, so dass sich folgende Relationen ergeben: |
|
Geräte (#Bez, Typ) |
|
ProdDig (#(ProdNr, BezProg), Proz, ArbSp, PlattSp) |
|
ProdProgGer (#(ProdNr, BezProg, BezGerät)) |
|
Betrachten wir noch die Kardinalitäten und Min-/Max-Angaben: |
|
|
- Für Produkte – ProdProgGer – Geräte ergibt sich die Kardinalität n:m und die Min-/Max-Angaben 1,n : 1,n, wenn wir festlegen, dass nur Produkte bzw. Geräte datenbankmäßig erfasst werden, die auch zum Einsatz kommen.
|
|
Anforderung Teil 9 |
|
Die Entwicklung der Programme findet so statt, dass jedes Programm mit unterschiedlichen grafischen Bedienoberflächen (GUI; graphical user interface) kombiniert werden kann. Für die GUIs wird ein Schlüssel (GUIId), der Typ (Fenster, Kacheln, ...) und die Programmiersprache (PS), mit der sie entwickelt wurde, festgehalten. Ein konkretes vom jeweiligen Softwarehaus angebotenes Programm enthält dann genau eine GUI, d.h. die Programme sind nach ihren grafischen Bedienoberflächen differenziert. |
|
Nun wird die Einbindung der grafischen Bedienoberflächen (Graphical User Interface, GUI) in das Datenmodell geklärt. Sie werden durch Identifikation und Beschreibung datenbanktechnisch existent in der Relation GUI. Dem Text kann außerdem entnommen werden, dass ein bestimmtes Programm genau eine ganz bestimmte GUI hat, so dass hier eine 1:n-Beziehung vorliegt. Entsprechend wird der Schlüssel von GUI in Programme als Fremdschlüssel eingefügt: |
|
GUI (#GUIId, Typ, PS) |
|
Programme (#BezProg, IBK, GUIId) |
|
2.8.4 Lösungen |
|
Textliche Fassung |
|
Geräte (#Bez, Typ) |
|
GUI (#GUIId, Typ, PS) |
|
Programme (#BezProg, IBK, GUIId) |
|
ProdDig (#(ProdNr, BezProg), Proz, ArbSp, PlattSp) |
|
ProdDigBS (#((ProdNr, BezProg), BS) |
|
ProdProgGer (#(ProdNr, BezProg, BezGerät)) |
|
Produkte (#ProdNr, Bez, LPreis, Sprache1, Sprache2) |
|
ProgDokArt (#(BezProg, DokArt)) |
|
SWHäuser (#SWHNr, PLZ, Ort, Straße, eMail) |
|
SWHProg (#(SWHNr, BezProg, Beginn), Ende) |
|
VTÜAkt (#ProdNr, AktJahre) |
|
WB+VTÜ (#ProdNr, Einträge, Zielgruppe, ErschDat) |
|
WBDig (#ProdNr, SpeichTech) |
|
WBGedr (#ProdNr, AnzSeiten) |
|
|
|
Grafische Fassung |
|
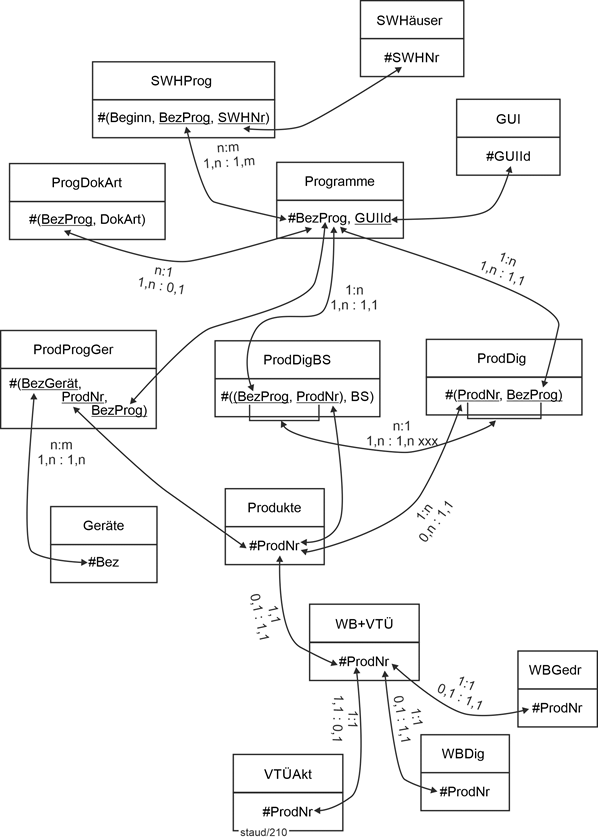
|
|
Abbildung 2.8-4: Relationales Datenmodell Sprachenverlag |
|
Abkürzungen für Attribute: |
|
AktJahr: Zahl der Jahre, in denen das Programm aktualisiert wird |
|
ArbSp: Arbeitsspeicher |
|
BS: Bezeichnung Betriebssystemversion |
|
ErschDatum: Erscheinungsdatum |
|
Geräte.Bez: Bezeichnung des Geräts |
|
Geräte.Typ: Gerätetyp |
|
GUI.Typ: Typ der grafischen Bedienoberfläche |
|
GUIId: Schlüssel für die grafische Bedienoberfläche |
|
LPreis: Listenpreis |
|
PlattSp: Speichergröße der Festplatte |
|
ProdDig.BezProg: Bezeichnung des Übersetzungsprogramms |
|
ProdNr : Produktnummer |
|
Produkte.Bez: Bezeichnung Produkt |
|
Proz: Bezeichnung des Prozessors bei digitalen Produkten |
|
PS: Programmiersprache, mit der die GUI entwickelt wurde |
|
SWHProg.Beginn: Beginn der Zusammenarbeit |
|
SWHProg.Ende: Ende der Zusammenarbeit |
|
WBVTÜ. Einträge: Zahl der Einträge in gedruckten Wörterbüchern und Volltextübersetzern |
|
Zielgruppe: anvisierte Kundengruppe |
|
|
|
Abkürzungen für Relationen: |
|
Geräte: Geräte, auf denen das digitale Produkt einsetzbar ist |
|
GUI: grafische Bedienoberfläche |
|
ProdDig: digitale Produkte |
|
ProdDigBS: digitale Produkte in Kombination mit Betriebssystemen |
|
ProdProgGer: Kombination Produkte – Programme – Geräte |
|
Produkte: die vom Sprachenverlag hergestellten Produkte |
|
ProgDokArt: Dokumentarten, die von den Programmen ausgewertet werden können |
|
Programme: die eingesetzten Programme |
|
SWHäuser: Softwarehäuser, die mit dem Sprachenverlag zusammenarbeiten |
|
SWHProg: Kombination Softwarehäuser und Programme |
|
VTÜAkt: Angabe zur Aktualisierung bei Volltextübersetzern |
|
WB+VTÜ: Attribute zu Volltextübersetzern und Wörterbüchern |
|
WBDig: digitale Wörterbücher |
|
WBGedr: Gedruckte Wörterbücher |
|
2.9 Lehre 1 |
|
Aufgabenstellung: Prof. Dr. Josef L. Staud |
|
Lösung: stud. oec. inf. Karolin Staud |
|
2.9.1 Anforderungsbeschreibung |
|
Für den Lehrbetrieb einer Hochschule soll eine Datenbank erstellt werden. Dazu wird ein relationales Datenmodell erstellt, für das die folgenden Anforderungen festgelegt wurden. Zu erfassen sind: |
|
|
(1) Lehrveranstaltungen: Jede Veranstaltung mit einer identifizierenden Nummer (LVNr), Bezeichnung (BezLV), der Zahl der Semesterwochenstunden (SWS) und in welchem Semster sie nach der SPO angeboten werden müssen (SemPlan).
|
|
|
(2) Studierende mit Matrikelnummer (MatrNr), Namen, Vornamen (VName) und einem E-Mail-Postfach (E-Mail).
|
|
|
(3) Der Besuch von Lehrveranstaltungen durch Studierende. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss.
|
|
|
(4) Dozenten: Jeder Dozent, der Lehrveranstaltungen gibt, mit Namen und Vornamen.
|
|
|
(5) Die Lehrtätigkeit der Dozenten. Festgehalten wird, welcher Dozent eine bestimmte Veranstaltung in welchem Semester gehalten hat. An dieser (kleinen) Hochschule wird jede Veranstaltung pro Semester nur einmal gehalten. Allerdings kommt es vor, dass mehrere Dozenten in einem Semester zusammen eine Lehrveranstaltung durchführen.
|
|
2.9.2 Lösungsschritte |
|
Anforderung 1 |
|
Unschwer kann die erste Relation erkannt werden: Lehrveranstaltungen (LV). Sie werden identifiziert (LVNr) und beschrieben, sind also datenbanktechnisch relevant: |
|
LV (#LVNr, #BezLV, SWS, SemPlan) |
|
Da die Bezeichnung der Lehrveranstaltung auch eindeutig sein dürfte, wird BezLV zu einem Sekundärschlüssel. |
|
Anforderung 2 |
|
Hier werden die Studierenden angesprochen. Da ein Schlüssel vorliegt (MatrNr) und beschreibende Attribute, entsteht eine Relation: |
|
Studierende (#MatrNr, Name, VName, E-Mail) |
|
Anforderung 3 |
|
Für den Besuch von Lehrveranstaltungen (LVBesuch) müssen obige Relationen verknüpft werden. Geht man davon aus, dass Vorlesungen semesterweise besucht werden, ist die erste Lösung g wie folgt: |
|
LVBesuch (#(MatrNr, LVNr), Semester) |
|
Durch den Hinweis, dass Lehrveranstaltungen durchaus auch mehrfach besucht werden (müssen), ergibt sich aber eine Änderung. Das Attribut Semester muss in den Schlüssel, sonst wäre der Schlüssel im Fall von Wiederholungsn nicht eindeutig: |
|
LVBesuch (#(MatrNr, LVNr, Semester)) |
|
Anforderung 4 |
|
Die hier angesprochenen Dozenten können, wenn man einen Schlüssel ergänzt (DozNr), ebenfalls als Relation angelegt werden: |
|
Dozenten (#DozNr, Name, VName) |
|
Anforderung 5 |
|
Der abschließende Punkt betrifft die Lehrtätigkeit (Lehre). Gehen wir von der realistischen Annahme aus, dass ein Dozent keine (Freisemester), eine oder (meist) mehrere Lehrveranstaltungen gibt, ergibt sich folgende Lösung: |
|
Lehre ((DozNr, LVNr, Sem), …//Sem = Semester |
|
Wäre verlangt, dass eine bestimmte Lehrveranstaltung pro Semester vom selben Dozenten mehrfach gehalten werden kann, müsste die Relation verändert werden. |
|
Nun ist noch gefordert, dass auch der Fall erfasst wird, dass mehrere Dozenten zusammen eine Lehrveranstaltung durchführen. Dies ist mit obiger Relation möglich. Dann gibt es z.B. folgende Tupel: |
|
|
1007, DBS1, SS2023
|
|
|
1008, DBS1, SS2023
|
|
Die Lösung ist aber nur richtig, weil in der Anforderungsbeschreibung ausgeführt ist, dass in jedem Semester jede Vorlesung nur einmal gehalten wird. Das drücken auch die Min-/Max-Angaben aus: |
|
Min-/Max-Angaben für Dozenten – Lehre – LV: 0,n : 1,1 |
|
2.9.3 Lösung |
|
Textliche Fassung |
|
LV (#LVNr, #BezLV, SWS, SemPlan) |
|
Studierende (#MatrNr, Name, VName, E-Mail) |
|
LVBesuch (#(MatrNr, LVNr, Semester)) |
|
Dozenten (#DozNr, Name, VName) |
|
Lehre ((DozNr, LVNr, Sem)) |
|
|
|
Grafische Fassung |
|
|
|
Abbildung 2.9-1: Relationales Datenmodell Lehre 1 |
|
2.10 Lehre 2 |
|
Aufgabenstellung: Prof. Dr. Josef L. Staud |
|
Lösung: stud. oec. inf. Karolin Staud |
|
2.10.1 Anforderungsbeschreibung |
|
Diese Aufgabe baut auf obiger auf. Die zusätzlichen Anforderungen sind mit „ZUSÄTZLICH:“ markiert. Entwerder also die obige Lösung übernehmen und als Ausgangsbasis nehmen oder einfach als Ganzes lösen. Erfasst weden sollen: |
|
|
(1) Lehrveranstaltungen: Jede Veranstaltung mit einer identifizierenden Nummer (LVNr), Bezeichnung (BezLV), der Zahl der Semesterwochenstunden (SWS) und in welchem Semster sie nach der SPO angeboten werden müssen (SemPlan).
|
|
|
(2) Studierende mit Matrikelnummer (MatrNr), Namen, Vornamen (VName) und einem E-Mail-Postfach (E-Mail). ZUSÄTZLICH: Von jedem Studierenden wird die Hauptadresse, die der Kommunikation mit der Hochschule dient, mit PLZ, Ort, Straße erfasst.
|
|
|
(3) Der Besuch von Lehrveranstaltungen durch Studierende. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss.
|
|
|
(4) Dozenten: Jeder Dozent, der Lehrveranstaltungen gibt, mit Namen und Vornamen. ZUSÄTZLICH: Für interne Dozenten wird noch festgehalten, in welchem Raum der Hochschule sie ihr Büro haben und wann ihre Sprechstunde ist. Für externe Dozenten wird festgehalten von welcher Organisation sie kommen (einem Unternehmen, einer anderen Hochschule, usw.).
|
|
|
(5) Die Lehrtätigkeit der Dozenten (Lehre). Festgehalten wird, welcher Dozent eine bestimmte Veranstaltung in welchem Semester gehalten hat. An dieser (kleinen) Hochschule wird jede Veranstaltung pro Semester nur einmal gehalten. Allerdings kommt es vor, dass mehrere Dozenten in einem Semester zusammen eine Lehrveranstaltung durchführen.
|
|
|
(6) ZUSÄTZLICH: Jede einzelne Veranstaltungsstunde (VTermine) mit Tag, Beginn, Ende und Raum. Als Schlüssel für die Termine dient eine Konstruktion aus Tag und Anfangszeit, also z.B. 20230602_0830 für eine Lehrveranstaltung, die am 2.6.2023 um 8.30 Uhr begann.
|
|
|
(7) ZUSÄTZLICH: Der Besuch der Veranstaltungstermine durch die Studierenden. An dieser Hochschule ist es üblich, die Anwesenheit zu kontrollieren. Deshalb wird für jeden Veranstaltungstermin einer Lehrveranstaltung festgehalten, welche Studierenden anwesend waren.
|
|
2.10.2 Lösungsschritte |
|
Anforderung 1 |
|
Unschwer kann die erste Relation erkannt werden: Lehrveranstaltungen (LV). Sie werden identifiziert (LVNr) und beschrieben, sind also datenbanktechnisch relevant: |
|
LV (#LVNr, #BezLV, SWS, SemPlan) |
|
Da die Bezeichnung der Lehrveranstaltung auch eindeutig sein dürfte, wird BezLV zu einem Sekundärschlüssel. |
|
Anforderung 2 |
|
Hier werden die Studierenden angesprochen. Da ein Schlüssel vorliegt (MatrNr) und beschreibende Attribute, entsteht eine Relation mit Name, VName und Email. Da von den Studierenden nur eine einzige Adresse erfasst wird, können die Adressinformkationen auch in diese Relation eingefügt werden. Somit entsteht: |
|
Studierende (#MatrNr, Name, VName, E-Mail, PLZ, Ort, Straße) |
|
Anforderung 3 |
|
Für den Besuch von Lehrveranstaltungen müssen obige Relationen verknüpft werden. Geht man davon aus, dass Vorlesungen semesterweise besucht werden, ist die Lösung wie folgt: |
|
LVBesuch (#(MatrNr, LVNr), Semester) |
|
Durch den Hinweis, dass Lehrveranstaltungen durchaus auch mehrfach besucht werden (müssen), ergibt sich aber eine Änderung. Das Attribut Semester muss in den Schlüssel, sonst wäre der Schlüssel nicht eindeutig: |
|
LVBesuch (#(MatrNr, LVNr, Semester)) |
|
Anforderung 4 |
|
Die hier angesprochenen Dozenten können, wenn man einen Schlüssel ergänzt (DozNr), ebenfalls als Relation angelegt werden: |
|
Dozenten (#DozNr, Name, VName) //vorläufig |
|
Nun werden aber für interne und externe Dozenten jeweils spezifische Attribute genannt. Das führt zu Spezialisierungen von Dozenten. Wird Dozenten in DozAllg (Dozenten allgemein) umbenannt und für die Spezialisierungen DozIntern und DozExtern eingeführt, entstehen folgende Relationen: |
|
DozAllg (#DozNr, Name, Vorname, Typ) |
|
DozIntern (#DozNr, EMail, BüroNr, SprStunde) |
|
DozExtern (#DozNr, Org) |
|
Das Attribut DozAllg.Typ wurde aus pragmatischen Gründen hinzugenommen. Es gibt an, ob der Dozent ein interner oder ein externer ist und erleichtert damit die Abfragen. |
|
Anforderung 5 |
|
Dieser Punkt betrifft die Lehrtätigkeit (Lehre). Dafür werden Dozenten und Lehrveranstaltungen verknüpft. Gehen wir von der realistischen Annahme aus, dass ein Dozent keine (Freisemester), eine oder (meist) mehrere Lehrveranstaltungen gibt, ist die Lösung wie folgt: |
|
Lehre ((DozNr, LVNr, Sem), …//Sem = Semester |
|
Die Min-/Max-Angaben für Dozenten – Lehre – LV sind 0,n : 1,1. |
|
Anforderung 6 – Termine! |
|
Neben den Lehrveranstaltungen ist auch die Erfassung der einzelnen Termine der Lehrveranstaltung gefordert. Entsprechend den Anforderungen wird für die Termine ein konstruierter Schlüssel TerminNr angelegt. Als beschreibende Attribute kommen Tag, Beginn, Ende und Raum hinzu: |
|
LVTermine (#TerminNr, Tag, Beginn, Ende, Raum, …//vorläufig |
|
Etwas wichtiges fehlt da noch, die Lehrveranstaltung um die es geht. Diese kann mit Hilfe der LVNr hinzugefügt werden. Dies sollte im Schlüssel geschehen, da es mit Sicherheit Lehrveranstaltungen gibt, die zum selben Zeitpunkt stattfinden. Die LVNr ist dann auch Fremdschlüssel. Damit ergibt sich: |
|
LVTermine (#TerminNr, LVNr), Tag, Beginn, Ende, Raum) //final |
|
Der konstruierte Schlüssel könnte aus der LVNr und zeitlichen Angaben bestehen. Also z.B. 1220_20230602_0830 für einen Lehrveranstaltungstermin mit der Nummer 1220, die am 2.6.2023 um 8.30 Uhr beginnt. Will man keinen konstruierten Schlüssel, könnte man den zeitlichen Aspekt mittels Tag und Beginn erfassen, insgesamt also zum Schlüssel #(LVNr, Tag, Beginn) finden. |
|
Anforderung 7 |
|
Hier soll auch noch der Besuch der Termine durch die Studierenden festgehalten werden („Anwesenheitsliste“). Dafür muss eine Relation „Lehrveranstaltungsbesuchtermine“ (LVBesTermine) angelegt werden. Als Attribute werden die TerminNr und die MatrNr. Benötigt. Es handelt sich um eine n:m-Beziehung, so dass folgende Relation entsteht: |
|
LVBesTermine (#(TerminNr, MatrNr)) |
|
Als Min-/Max-Angabe soll für „Studierende – LVBesTermine – LVTermine“ 0,n : 3,n angenommen werden mit der Erkenntnis/Semantik: Es gibt Studierende, die gar keinen Termin wahrnehmen, ein Termin findet nur statt, wenn mindestens drei Studierende anwesend sind (zum Beispiel). |
|
2.10.3 Lösung |
|
Textliche Fassung |
|
DozAllg (#DozNr, Name, Vorname, Typ) |
|
DozExtern (#DozNr, Org) |
|
DozIntern (#DozNr, EMail, BüroNr, SprStunde) |
|
Lehre ((DozNr, LVNr, Sem) |
|
LV (#LVNr, #BezLV, SWS, SemPlan) |
|
LVBesTermine (#(TerminNr, MatrNr)) |
|
LVBesuch (#(MatrNr, LVNr, Semester)) |
|
LVTermine (#TerminNr, LVNr), Tag, Beginn, Ende, Raum) |
|
Studierende (#MatrNr, Name, VName, E-Mail, PLZ, Ort, Straße) |
|
|
|
Grafische Fassung |
|
|
|
Abbildung 2.10-1: Relationales Datenmodell Lehre 2 |
|
2.11 Lehre 3 |
|
Dies ist die umfangreichste Aufgabe zum Vorlesungsbetrieb an Hochschulen. Hier wird in den Lösungsschritten, stärker als oben, die schrittweise Entwicklung des Datenmodells anhand von Modellfragmenten dargestellt. Außerdem wird das Muster Generalisierung / Spezialisierung intensiv thematisiert. |
|
2.11.1 Anforderungsbeschreibung |
|
Hier wird der Anwendungsbereich Vorlesungsbetrieb einer Hochschule (HS) betrachtet. Folgendes soll erfasst werden: |
|
|
(1) Für die Lehrveranstaltungen eine Veranstaltungsnummer (LVNr), ihre Bezeichnung (BezLV), der Typ des zugehörigen Studienganges (Master, Bachelor, Diplom) (TypSG), die Bezeichnung des Studienganges (WI, AI, ...), der die Lehrveranstaltung durchführt (BezSG), die Credit Points (cp) und die Anzahl Semesterwochenstunden (SWS). Außerdem, in welchem Studiensemester die Lehrveranstaltung abzuhalten ist (SemPlan). Für jeden konkreten Termin der Lehrveranstaltungen wird festgehalten an welchem Tag er statt fand (Tag), wann er begann (Beginn) und wann er endete (Ende). Also z.B. Mittwochs, 8.00 - 9.30 Uhr. Die Räume werden ebenfalls erfasst, mit einer Typisierung (ArtRaum; DV-Raum, Vorlesungsraum, Labor, ...), der Größe (Groesse), der Ausstattung mit Beamern und Intranet (BeamerJN, IntranetJN) und dem Gebäude, in dem sie sich befinden (GebBez). Dabei geht man davon aus, dass in einem Semester eine Lehrveranstaltung immer in demselben Raum stattfindet. In verschiedenen Semestern kann die Lehrveranstaltung aber natürlich in jeweils anderen Räumen sein.
|
|
|
(2) Die Studierenden werden durch ihre Matrikelnummer (MatrNr), den Namen, Vornamen (VName) und ein E-Mail-Postfach (E-Mail) erfasst. Für sie wird außerdem festgehalten, in welchem Semester sie welche Lehrveranstaltung besucht haben. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss. Sozusagen in den "Stammdaten" der Studierenden ist außerdem vermerkt, wann das Studium begann (BegStudium), wann es endet(e) (EndeStudium), in welchem Studiengang (SG) sie eingeschrieben sind und in welchem Fachsemester sie sich befinden (FachSem). Für die Studierenden werden beliebig viele Adressen (PLZ, Ort, Strasse) zugelassen. Eine davon muss als die gekennzeichnet sein, zu der die Mitteilungen der Hochschule gesandt werden.
|
|
|
(3) Die Dozenten werden durch eine Dozentennummer (DozNr), den Namen, Vornamen (VName), die Anrede sowie ein E-Mail-Postfach erfasst. Für die Dozenten der Hochschule sollen zusätzlich auch die Nummer ihres Büros (BüroNr), ihre interne Telefonnummer (IntTel), ihre Sprechstunde (SprSt), ihre Fakultät und die Angabe des Gebäudes, in dem sich das Büro befindet (GebBez), angegeben werden. Für diese Gebäude wird noch festgehalten, in welchem Ort sie sich befinden (Ort), welche Straßenadresse sie haben (Straße, z.B. Hauptstr. 8) und welcher DV-Betreuer für das Gebäude zuständig ist (Straße, DVBetr). Es gibt an dieser Hochschule auch externe Dozenten. Für diese wird die Adresse erfasst (nur eine), welchen akademischen Abschluss sie haben (AkAb) und in welcher Organisation (Unternehmen, andere Hochschule, ...) welcher Branche sie arbeiten. Deren Adresse wird, für die Zusendung von Lehraufträgen usw., ebenfalls erfasst.
|
|
|
(4) Zum Lehrbetrieb soll in der Datenbank festgehalten werden, welcher Dozent welche Lehrveranstaltung gehalten hat. Üblicherweise hält ein Dozent mehrere Lehrveranstaltungen in einem Semester und dieselbe Lehrveranstaltung kann in verschiedenen Semestern von unterschiedlichen Dozenten gehalten werden. Kein Dozent hält in einem Semester eine Lehrveranstaltung mehrfach. Auch der Besuch von Lehrveranstaltungen durch Studierende wird mit Angabe des Semesters erfasst. Es soll möglich sein, dass ein Studierender mehrfach für eine Lehrveranstaltung eingeschrieben ist (Wiederholungen).
|
|
|
(5) Alle Prüfungen beziehen sich immer auf genau eine Lehrveranstaltung. Jeder wird eine Prüfungsnummer (PrüfNr) und eine Bezeichnung (Bez) zugewiesen. Bei allen Prüfungen wird der Prüfungstag festgehalten (Datum). Bei Klausuren (KL) und mündlichen Prüfungen (MP) auch die Länge. Bei mündlichen Prüfungen zusätzlich der Prüfer (dies ist immer nur genau einer; PrüfPersNr). Dieser kann interner oder auch externer Dozent sein. Praktische Arbeiten (PA) sind Leistungen wie Erstellung eines Datenmodells, Modellierung eines Prozesses, usw. Laborarbeiten (LA) sind solche, für die ein Labor und die Unterstützung des zuständigen Laborbetreuers benötigt wird. Beide finden in einem bestimmten Zeitraum statt, der ebenfalls in der Datenbank erfasst werden soll (Start, Ende). Bei Laborarbeiten sind zusätzlich die Laborbezeichnung (LabBez; EBUS-Labor, Mikrocomputerlabor, ERP-Labor, ...) und der Laborbetreuer mit Namen und Vornamen zu erfassen (LabBetrN, LabBetrVN).
|
|
|
(6) Der Besuch einer Prüfung bezieht sich immer auf eine Lehrveranstaltung. Festgehalten wird zu jeder Prüfung das Semester, in dem sie stattfindet (Sem), das genaue Datum, um welchen Versuch es sich handelt (1. Versuch, 2. Versuch, ...) und welche Note erzielt wurde.
|
|
2.11.2 Lösungsschritte |
|
Anforderung Teil 1 |
|
Für die Lehrveranstaltungen eine Veranstaltungsnummer (LVNr), ihre Bezeichnung (BezLV), der Typ des zugehörigen Studienganges (Master, Bachelor, Diplom) (TypSG), die Bezeichnung des Studienganges (WI, AI, ...), der die Lehrveranstaltung durchführt (BezSG), die Credit Points (cp) und die Anzahl Semesterwochenstunden (SWS). Außerdem, in welchem Studiensemester die Lehrveranstaltung abzuhalten ist (SemPlan). Für jeden konkreten Termin der Lehrveranstaltungen wird festgehalten an welchem Tag er war (Tag), wann er begann (Beginn) und wann er endete (Ende). Also z.B. Mittwochs, 8.00 - 9.30 Uhr. Die Räume werden ebenfalls erfasst, mit einer Typisierung (ArtRaum; DV-Raum, Vorlesungsraum, Labor, ...), der Größe (Groesse), der Ausstattung mit Beamern und Intranet (BeamerJN, IntranetJN) und dem Gebäude, in dem sie sich befinden (GebBez). Dabei geht man davon aus, dass in einem Semester eine Lehrveranstaltung immer in demselben Raum stattfindet. In verschiedenen Semestern kann die Lehrveranstaltung aber natürlich in jeweils anderen Räumen sein. |
|
Auf Grund der Beschreibung kann angenommen werden, dass es nicht um fixe Wochenpläne geht, sondern um flexible, also um Einzeltermine. Dass trotzdem die meisten dann in jeder Woche zum selben Zeitpunkt stattfinden, soll nicht stören. |
|
Die Lehrveranstaltungen (LV) selbst sind sofort als Relationen erkennbar, da sie identifiziert und durch zahlreiche Attribute beschrieben werden (mit BezLV, TypSG, BezSG, SemPlan, cp, SWS). Der Schlüssel ist LVNr. Für die Termine der Lehrveranstaltungen ergibt sich ein Schlüssel, wie er oft bei zeitlich fixierten Vorgängen auftritt. Der eigentliche Gegenstand, hier die Veranstaltungstermine, muss mit einem "Zeitstempel" versehen werden. Dabei genügen hier Tag und Beginn, da damit der Schlüssel eindeutig wird (LVTermine mit #(LVNr, Tag, Beginn), Ende). |
|
Auch die Räume sind oben angesprochen. Ihre Modellierung bereitet keine Probleme: (#RaumNr, ArtRaum, Groesse, BeamerJN, IntranetJN, GebBez). Bei den Gebäuden muss geprüft werden, ob sie später noch beschrieben werden. Da dies hier der Fall ist, wurde die Gebäudebezeichnung als Fremdschlüssel aufgenommen. |
|
Die Ausführungen in der Anforderung zu den Räumen für die Lehrveranstaltungen sind etwas unklar und müssen präzisiert werden. Nimmt man die Räume zu den Terminen hinzu entsteht Redundanz, denn es ist ja in einem Semester immer derselbe Raum, in dem die Lehrveranstaltung stattfindet. Deshalb muss eine eigene Relation eingerichtet werden, die an einer einzigen Stelle für eine Lehrveranstaltung und ein ganzes Semester den Raum mittels RaumNr festhält: LVRäume mit (#(LVNr, Sem), RaumNr). Das Attribut RaumNr stellt als Fremdschlüssel die Verknüpfung mit Räume her. |
|
Damit ergeben sich folgende Relationen: |
|
LV (#LVNr, BezLV, TypSG, BezSG, SemPlan, cp, SWS) |
|
LVRäume (#(LVNr, Sem), RaumNr) |
|
LVTermine (#(LVNr, Tag, Beginn), Ende) |
|
Räume (#RaumNr, ArtRaum, Groesse, BeamerJN, IntranetJN, GebBez) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt (hier mal ausnahmsweise zusätzlich auch mit Einzelangaben zur n:m-Verknüpfung): |
|
- Von LV über LVRäume zu Räume: n:m bzw. 1,n : 0,n. Weil eine Lehrveranstaltung in mehreren Semestern in verschiedenen Räumen abgehalten werden kann und wenn wir annehmen, dass es auch Räume für Lehrveranstaltungen gibt, die noch nicht eingesetzt wurden.
- Von LV zu LVRäume: 1:m bzw. 1,n : 1,1 (Teil von oben).
- Von Räume zu LVRäume: 1:n bzw. 0,n : 1,1 (Teil von oben).
- Von LV zu LVTermine: 1:n bzw. 1,n : 1,1.
|
|
Die folgende Abbildung zeigt diesen Modellausschnitt in grafischer Form. |
|
|
|
Abbildung 2.11-1: Relationales Datenmodell HS – Ausschnitt Lehrveranstaltungen |
|
Nicht verwirren lassen: Die Beziehung LV – Räume ist hier nicht nur jeweils für ein Semester, sondern über die Semester hinweg erfasst. Deshalb n:m und nicht 1:n. |
|
Anforderung Teil 2 |
|
Die Studierenden werden durch ihre Matrikelnummer (MatrNr), den Namen, Vornamen (VName) und ein E-Mail-Postfach (E-Mail) erfasst. Für sie wird außerdem festgehalten, in welchem Semester sie welche Lehrveranstaltung besucht haben. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss. Sozusagen in den "Stammdaten" der Studierenden ist außerdem vermerkt, wann das Studium begann (BegStudium), wann es endet(e) (EndeStudium), in welchem Studiengang (SG) sie eingeschrieben sind und in welchem Fachsemester sie sich befinden (FachSem). Für die Studierenden werden beliebig viele Adressen (PLZ, Ort, Strasse) zugelassen. Eine davon muss als die gekennzeichnet sein, zu der die Mitteilungen der Hochschule gesandt werden. |
|
Hieraus ergeben sich mehrere Relationen. Die erste zu den Studierenden. Sie werden durch die Matrikelnummer identifiziert und durch die angegebenen weiteren Attribute beschrieben. Die Aufnahme von EndeStudium verstößt ja eigentlich gegen eine derGrundregeln relationaler Datenmodellierung (weil diese Angabe ja erst mal nicht zur Verfügung steht), wird aber aus pragmatischen Gründen akzeptiert: (#MatrNr, Name, VName, E-Mail, BegStudium, EndeStudium, SG, FachSem). |
|
Die zweite erfasst den Besuch von Lehrveranstaltungen. Es ist eine n:m-Verknüpfung, so dass eine Verbindungsrelation entsteht (LVBesuch), allerdings mit einem zusätzlichen Zeitstempel, der Semesterangabe (Sem). |
|
Abschließend werden oben die Adressangaben der Studierenden angesprochen. Der Text lässt auf eine 1:n-Beziehung zwischen Studierenden und Adressen schließen. Da aber unter einer Adresse auch mehrere Studierende wohnen können (Wohnheim, Wohngemeinschaft), gilt auch umgekehrt eine 1:n-Beziehung. Insgesamt ensteht also also eine n:m-Beziehung. Diese führt zur Relation StudAdr. Mit dem Attribut Art kann festgehalten werden, ob es sich um die Adresse für die Mitteilungen an die Studierenden handelt. |
|
Die neuen Relationen: |
|
Studierende (#MatrNr, Name, VName, E-Mail, BegStudium, EndeStudium, SG, FachSem) |
|
LVBesuch (#(MatrNr, LVNr, Sem)) |
|
Adressen (#AdrNr, Ort, PLZ, Strasse) |
|
StudAdr (#(MatrNr, AdrNr), Art) |
|
Nehmen wir LV dazu, sind die Kardinalitäten und Min-/Max-Angaben wie folgt: |
|
- Von Studierende über LVBesuch zu LV: n:m bzw. 0,n : 3,n. Wenn man annimmt, dass ein Studierender auch mal keine Lehrveranstaltung besucht und dass eine Lehrveranstaltung nur durchgeführt wird, wenn mindestens drei Studierende anwesend sind.
- Von Studierende über StudAdr zu Adressen: n:m bzw. 1,n : 1,m.
|
|
Die folgende Abbildung zeigt diesen Ausschnitt des Datenmodells: |
|
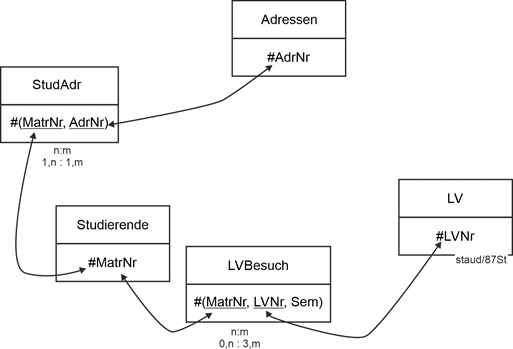
|
|
Abbildung 2.11-2: Relationales Datenmodell HS – Auschnitt Studierende und Lehrveranstaltungen |
|
Anforderung Teil 3 |
|
Die Dozenten werden durch eine Dozentennummer (DozNr), den Namen, Vornamen (VName), die Anrede sowie ein E-Mail-Postfach erfasst. Für die Dozenten der Hochschule sollen zusätzlich auch die Nummer ihres Büros (BüroNr), ihre interne Telefonnummer (IntTel), ihre Sprechstunde (SprSt), ihre Fakultät und die Angabe des Gebäudes, in dem sich das Büro befindet (BezGeb), angegeben werden. Für diese Gebäude wird noch festgehalten, in welchem Ort sie sich befinden (Ort), welche Straßenadresse sie haben (Straße, z.B. Hauptstr. 8) und welcher DV-Betreuer für das Gebäude zuständig ist (Straße, DVBetr). Es gibt an dieser Hochschule auch externe Dozenten. Für diese wird die Adresse erfasst (nur eine), welchen akademischen Abschluss sie haben (AkAb) und in welcher Organisation (Unternehmen, andere Hochschule, ...) welcher Branche sie arbeiten. Deren Adresse wird, für die Zusendung von Lehraufträgen usw., ebenfalls erfasst. |
|
Dozenten mit Generalisierung / Spezialisierung. Die Lehrkräfte der Hochschule erscheinen hier als externe und interne Dozenten. Da es Attribute für alle Dozenten gibt und spezifische für die beiden Untergruppen liegt eine Generalisierung / Spezialisierung vor. Die gemeinsamen Attribute sind Name, VName, Anrede und E-Mail, sie kommen in die Generalisierung (DozAllgemein). |
|
Den externen Dozenten (DozExt) wird nach Übernahme eines Lehrauftrags eine Dozentennummer (DozNR) zugewiesen. Diese entspricht modelltechnisch der Personalnummer (DozExtern) der internen Dozenten (DozHS). Für die externen Dozenten wird neben dem akademischen Abschluss (AkAb) eine einzige Adresse erfasst, somit genügt für das Festhalten der Adresse ein Fremdschlüssel in der Relation (AdrNr). Für die Organisationszugehörigkeit wird ebenfalls ein Fremdschlüssel (OrgNr) angelegt (zur Organisation vgl. unten). Bei den Dozenten der Hochschule wird angenommen, dass sie nur ein einziges Büro haben. Dessen Gebäude kann als Fremdschlüssel in DozHS erfasst werden. |
|
Alle drei Relationen zu Dozenten erhalten denselben Schlüssel. Dies ist bei einer Generalisierung / Spezialisierung immer der Fall und wirkt auf den ersten Blick befremdlich, da im allgemeinen in der relationalen Modellierung gilt: Es gibt keine Relationen mit demselben Schlüssel. Dies ist eine der Ausnahmen. |
|
Auch die Gebäude können mit einem Schlüssel (#BezGeb), dem Ort und der Straße sowie dem zuständigen DV-Betreuer (DVBetr) erfasst werden. |
|
Bleiben noch die Organisationen. Sie haben eine Bezeichnung und eine Adresse, Außerdem wird ihre Branche festgehalten und ein Schlüssel (OrgNr) vergeben. Damit kann eine Relation Organisationen angelegt werden. Mit dem Fremdschlüssel AdrNr wird diese Relation mit der zu den Adressen verknüpft. |
|
Die neuen Relationen und ihr Umfeld: |
|
DozAllg (#DozNr, Name, VName, Anrede, E-Mail) |
|
DozExt (#DozNr, AkAb, OrgNr, AdrNr) |
|
DozHS (#DozNr, Fakultät, BüroNr, BezGeb, IntTel, SprSt, E-Mail) |
|
Gebäude (#BezGeb, Ort, Straße, DVBetr) |
|
Räume (#RaumNr, ArtRaum, Groesse, BeamerJN, IntranetJN, GebBez) |
|
Organisationen (#OrgNr, Bez, AdrNr, Branche) |
|
Adressen (#AdrNr, Ort, PLZ, Strasse) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: |
|
- Von DozAllg zu DozExt: 1:1 bzw. 0,1 : 1,1. Genauso für DozAllg zu DozHS.
- Von Gebäude zu DozHS: 1:n, bzw. 0,n : 1,1.
- Von Organisationen zu DozExt: 1:n bzw. 1,n : 0,1. Wenn man festlegt, dass eine Organisation nur erfasst wird, wenn sie mindestens einen Dozenten „schickt“ und nicht jeder externe Dozent von einer Organiation kommt („Privatier“).
- Von Adressen zu Organisationen: 1:1 bzw. 0,1 : 1,1 1:1 bzw. 0,1 : 1,1.
- Von Gebäude zu Räume: 1:n bzw. 1,n : 1,1
|
|
Hier die grafische Fassung dieses Modellausschnitts: |
|
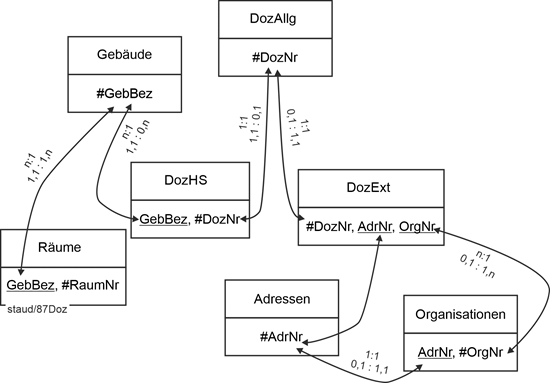
|
|
Abbildung 2.11-3: Relationales Datenmodell HS – Auschnitt Dozenten |
|
Anforderung Teil 4 |
|
Zum Lehrbetrieb soll in der Datenbank festgehalten werden, welcher Dozent welche Lehrveranstaltung gehalten hat. Üblicherweise hält ein Dozent mehrere Lehrveranstaltungen in einem Semester und dieselbe Lehrveranstaltung kann in verschiedenen Semestern von unterschiedlichen Dozenten gehalten werden. Kein Dozent hält in einem Semester eine Lehrveranstaltung mehrfach. Auch der Besuch von Lehrveranstaltungen durch Studierende wird mit Angabe des Semesters erfasst. Es soll möglich sein, dass ein Studierender mehrfach für eine Lehrveranstaltung eingeschrieben ist (Wiederholungen). |
|
Der Lehrbetrieb wird einfach durch eine Verbindungsrelation mit Angabe des Semesters erfasst. Mit dieser Lösung kann ein Dozent mehrere Lehrveranstaltungen pro Semester halten (was ja meist der Fall ist) und dieselbe Lehrveranstaltung kann in einem Semester von mehreren Dozenten gehalten werden, was allerdings normalerweise nicht der Fall ist. Genau gleich ist die Lösung für den Besuch von Lehrveranstaltungen. Durch das Schlüsselattribut Semester sind auch Wiederholungen erfassbar. |
|
Damit ergeben sich folgende neuen Relationen mit "Zeitstempel": |
|
Lehrbetrieb (#(DozNr, VeranstNr, Sem)) |
|
LVBesuch (#(MatrNr, LVNr, Sem)) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: |
|
- Von LV über Lehrbetrieb zu DozAllg: n:m bzw. 1,n : 0,n. Da ein neuer Dozent auch erfasst werden soll, bevor er oder sie die erste Lehrveranstaltung hält.
- Von LV über LVBesuch zu Studierende: n:m, bzw. 3,n : 0,n. Da eine Lehrveranstaltung mindestens drei Teilnehmer braucht und Studierende zu Beginn des Studiums noch keine LV besucht haben.
|
|
Für die grafische Gestaltung vgl. das Gesamtmodell. |
|
Anforderung Teil 5 |
|
Alle Prüfungen beziehen sich immer auf genau eine Lehrveranstaltung. Jeder wird eine Prüfungsnummer (PrüfNr) und eine Bezeichnung (Bez) zugewiesen. Bei allen Prüfungen wird der Prüfungstag festgehalten (Datum). Bei Klausuren (KL) und mündlichen Prüfungen (MP) auch die Länge. Bei mündlichen Prüfungen zusätzlich der Prüfer (dies ist immer nur genau einer; PrüfPersNr). Dieser kann interner oder auch externer Dozent sein. Praktische Arbeiten (PA) sind Leistungen wie Erstellung eines Datenmodells, Modellierung eines Prozesses, usw. Laborarbeiten (LA) sind solche, für die ein Labor und die Unterstützung des zuständigen Laborbetreuers benötigt wird. Beide finden in einem bestimmten Zeitraum statt, der ebenfalls in der Datenbank erfasst werden soll (Start, Ende). Bei Laborarbeiten sind zusätzlich die Laborbezeichnung (LabBez; EBUS-Labor, Mikrocomputerlabor, ERP-Labor, ...) und der Laborbetreuer mit Namen und Vornamen zu erfassen (LabBetrN, LabBetrVN). |
|
. Auch bei den Prüfungen zeichnet sich eine Generalisierung / Spezialisierung ab. Alle erhalten eine Prüfungsnummer (PrüfNr), eine Bezeichnung (Bez), ein Prüfungsdatum (Datum) und den Verweis auf die Lehrveranstaltung , auf die sie sich beziehen. Da sich jede Prüfung auf genau eine Lehrveranstaltung bezieht, ist diese Lösung mit einem Fremdschlüssel korrekt. Für die Klärung der Gen/Spez-Hierarchie wird eine Tabelle erstellt, genau nach den oben formulierten Anforderungen. |
Mehrstufige Gen/Spez zu Prüfungen |
Prüfungsunterschiede |
|
| Klausuren (KL) |
Mündliche Prüfungen (MP) |
Praktische Arbeit (PA) |
Laborarbeit (LA) |
| PrüfNr |
PrüfNr |
PrüfNr |
PrüfNr |
| Bez |
Bez |
Bez |
Bez |
| Datum |
Datum |
Datum |
Datum |
| Versuch |
Versuch |
Versuch |
Versuch |
| Länge |
Länge |
|
|
| |
|
Start |
Start |
| |
|
Ende |
Ende |
| |
PrüfPersNr |
|
|
| |
|
|
LabBez |
| |
|
|
LabBetrN |
| |
|
|
LabBetrVN |
| |
Damit sind die Spezialisierungen klar. PrüfAllg ist die "oberste" Generalisierung und enthält die Attribute, die alle Relationen aufweisen. Dazu gehört auch ein Fremdschlüssel für die zugehörige Lehrveranstaltung (LVNr). Die ersten Spezialisierungen sind PrüfPALA für die gemeinsamen Attribute von PA und LA (Start und Ende) sowie PrüfKLMP für das gemeinsame Attribut von KL und MP (Länge). Es folgen die Spezialisierungen PrüfLA von PrüfPALA und PrüfMP von PrüfKL+MP. PrüfLA erhält die Attribute zur Laborbetreuung (LabBez, LabBetrN, LabBetrVN), PrüfMP die zur prüfenden Person (PrüfPersNr), die auch Fremdschlüssel ist. |
|
Die Relationen PrüfPALA und PrüfKLMP sind "nach oben" Spezialisierungen und "nach unten" Generalisierungen. Die Abbildung mit dem Datenmodell unten verdeutlicht dieses Strukturmerkmal. In dieser Abbildung sind die relationalen Verknüpfungen entlang dieser Spezialisierungshierachie eingezeichnet. Natürlich können aber in relationalen Datenbanken mit SQL alle Relationen einer Gen/Spez über ihre (gleichen) Schlüssel verknüpft werden. |
|
Die neuen Relationen: |
|
PrüfAllg (#PrüfNr, Bez, Datum, Versuch, ArtPrüf, LVNr) |
|
PrüfPALA (#PrüfNr, Start, Ende) |
|
PrüfKLMP (#PrüfNr, Länge) |
|
PrüfLA (#PrüfNr, LabBez, LabBetrN, LabBetrVN) |
|
PrüfMP (#PrüfNr, PrüfPersNr) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: |
|
- Von PrüfAllg zu PrüfPALA: 1,1 bzw 0,1 : 1,1. Genauso sind die übrigen Gen/Spez-Wertigkeiten .
- Von DozAllg zu PrüfMP: 1:n bzw. 0,n : 1,1. Da es sicher Dozenten gibt, die nicht an einer mündlichen Prüfung teilgenommen haben und da jede mündliche Prüfung genau einen Prüfer hat.
|
|
Anforderung Teil 6 |
|
Der Besuch einer Prüfung bezieht sich immer auf eine Lehrveranstaltung. Festgehalten wird zu jeder Prüfung das Semester, in dem sie stattfindet (Sem), das genaue Datum, um welchen Versuch es sich handelt (1. Versuch, 2. Versuch, ...) und welche Note erzielt wurde. |
|
Der letzte Teil der Anforderungen klärt die Erfassung des Prüfungsbesuchs. Dies ist wieder eine n:m-Beziehung (zwischen Studierenden und Prüfungen). Als Schlüssel dient neben der Matrikel- und Prüfungsnummer auch die Semesterangabe. Die anderen drei beschreibenden Attribute werden als Nichtschlüsselattribute eingefügt. |
|
Damit ergibt sich folgende Relation: |
|
PrüfBesuch (#(MatrNr, PrüfNr, Sem), Datum, Versuch, Note) |
|
Die Kardinalität und die Min-/Max-Angaben sind wie folgt: |
|
- Von Studierende über PrüfBesuch zu PrüfAllg: n:m bzw. 0,n : 1,m. Da ein Studierender zu Beginn des Studiums noch keine Prüfung besucht hat und da man davon ausgehen kann, dass eine Prüfung nur stattfindet, wenn mindestens ein Prüfling kommt.
|
|
Damit sind die einzelnen Anforderungen modelliert und können nun zusammengefügt werden. |
|
2.11.3 Lösung |
|
Textliche Fassung |
|
Adressen (#AdrNr, Ort, PLZ, Strasse) |
|
DozAllg (#DozNr, Name, VName, Anrede, E-Mail) |
|
DozExt (#DozNr, AkAb, OrgNr, AdrNr) |
|
DozHS (#DozNr, Fakultät, BüroNr, BezGeb, IntTel, SprSt, E-Mail) |
|
Gebäude (#BezGeb, Ort, Straße, DVBetr) |
|
Lehrbetrieb (#(DozNr, VeranstNr, Sem)) |
|
LV (#LVNr, BezLV, TypSG, BezSG, SemPlan, cp, SWS) |
|
LVBesuch (#(MatrNr, LVNr, Sem)) |
|
LVRäume (#(LVNr, Sem), RaumNr) |
|
LVTermine (#(LVNr, Tag, Beginn), Ende) //für jeden Termin |
|
Organisationen (#OrgNr, Bez, AdrNr, Branche) |
|
PrüfAllg (#PrüfNr, Bez, ArtPrüf, LVNr) |
|
PrüfBesuch (#(MatrNr, PrüfNr, Sem), Datum, Versuch, Note) |
|
PrüfKLMP (#PrüfNr, Länge) |
|
PrüfLA (#PrüfNr, LabBez, LabBetrN, LabBetrVN) |
|
PrüfMP (#PrüfNr, PrüfPersNr) |
|
PrüfPALA (#PrüfNr, Start, Ende) |
|
Räume (#RaumNr, ArtRaum, Groesse, BeamerJN, IntranetJN, GebBez) |
|
StudAdr (#(MatrNr, AdrNr), Art) |
|
Studierende (#MatrNr, Name, VName, E-Mail, BegStudium, EndeStudium, SG, FachSem) |
|
|
|
Grafische Fassung |
|
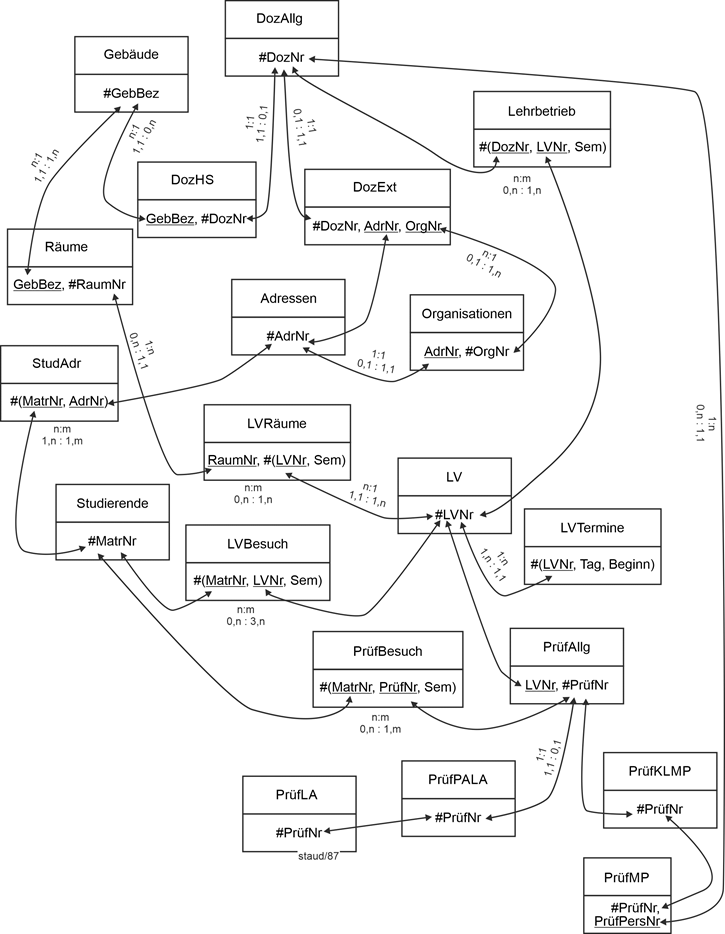
|
|
Abbildung 2.11-4: Relationales Datenmodell Vorlesungsbetrieb |
|
2.12 Fachliteratur |
|
Angesichts von 20 Relationen und zahlreichen methodischen und semantischen Strukturmerkmalen gehört diese Aufgabe zu den umfangreichen und komplexen. |
|
2.12.1 Anforderungsbeschreibung |
|
Im Anwendungsbereich Fachliteratur sollen alle wichtigen Typen von Fachliteratur erfasst werden. Zweck der Datenbank ist es, die Literatur zu erfassen, die Suche nach Fachliteratur zu ermöglichen und von Zeit zu Zeit eine Literaturliste wie die nachfolgende zu erstellen (z.B. für eine Bachelor- oder Masterarbeit). |
|
Die wichtigsten Arten von Fachliteratur sind: |
|
- Monographien (Mono). Dies sind Bücher, die ein zusammenhängendes Werk darstellen und die von einem Autor oder mehreren verfasst sind.
- Sammelbände (SB). Auch diese sind Bücher. Allerdings hat hier jedes Kapitel einen eigenen Autor oder mehrere. Die Autoren des Sammelbandes insgesamt werden Herausgeber genannt.
- Die Beiträge in einem Sammelband (SBB). Dies sind die einzelnen Kapitel in Sammelbänden. Da diese ja spezielle Themen betreffen und eigene Autoren haben, werden sie als eigenständige Werke in der Datenbank erfasst. Zum Beispiel, um sie bei einer inhaltlichen Suche zu finden.
- Artikel in Fachzeitschriften (Zeitschriftenartikel, ZSA). Dies sind Werke, die in einer Zeitschrift erschienen sind.
- Internetquellen (IQU). Dies sind Werke von Internetseiten, z.B. Forschungsberichte, Firmenmitteilungen, usw.
|
|
Ergänzend werden Zeitschriften (ZS) erfasst, als Trägermedium der Zeitschriftenartikel (ZSA). |
|
Diese Unterscheidung von Literaturarten ist wichtig, weil sie unterschiedlich beschrieben werden. Zum Beispiel in einer Literaturliste, wie sie bei einer akademischen Abschlussarbeit meist anfällt: |
Bibliographische Angaben |
Beispiele für Monographien (Mono) |
|
Scheer, August-Wilhelm: Wirtschaftsinformatik. Referenzmodell für industrielle Geschäftsprozesse (5. Auflage), Berlin et al. 1994 (Springer-Verlag) |
|
Österle, H.; Brenner, W.; Hilbers, K. et al.: Unternehmensführung und Informationssystem, Stuttgart 1992 (XYZ-Verlag) |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 |
|
Also: Name; Vorname; Titel; Ort (des Verlags); Erscheinungsjahr; Verlag, bei dem das Buch erschienen ist. Die Gestaltung mit Punkten, Strichpunkten, Kommata und die Einordnung der Verlagsangabe ist nur eine Empfehlung. Bei KI-Programmen als Autoren steht Name für die Bezeichnung der Software. |
|
Beispiel für Sammelbände (SB) |
|
Reussner, Ralf; Hasselbring, Wilhelm (Hrsg.), Handbuch der Software-Architektur (2. Auflage). Heidelberg 2009 (dpunkt) |
|
Becker, Jörg; Kugeler, Martin; Rosemann, Michael (Hrsg.): Prozessmanagement. Ein Leitfaden zur Prozessorientierten Organisationsgestaltung (5. Auflage). Berlin u.a. 2005 (Springer) |
|
Also: Namen und Vornamen; Hinweis auf die Herausgeberschaft; Titel; Untertitel, falls vorhanden; Hinweis auf Auflage, falls nicht die erste; Verlagsort(e); Erscheinungsjahr; Angabe Verlag, falls möglich. |
|
Beispiele für Beiträge in einem Sammelband (SBB) |
|
Hansmann, Holger; Laske, Michael; Luxem, Redmer: Einführung der Prozesse - Prozess-Roll-out. In: [Becker, Kugeler, Rosemann (Hrsg.) 2005], S. 269 - 298. |
|
Baier, Achim; Becker, Steffen; Jung, Martin u.a.: Modellgetriebene Software-Entwicklung . In: [Reussner, Hasselbring (Hrsg.) 2009], S. 93 - 122 |
|
Also: Namen und Vornamen, bei mehr als drei Autoren der Zusatz "u.a." (und andere) oder "et al"; Titel; das Wort "In", das verdeutlicht, dass jetzt das übergeordnete Werk (der SB) folgt; bibliographische Angaben des Sammelbandes, in dem der SBB enthalten ist; Seitenangaben: erste und letzte Seite des SBB. |
|
Falls in einer Literaturliste ein Beitrag aus einem Sammelband angeführt wird, muss auch der Sammelband enthalten sein. |
|
Beispiele für einen Artikel in einer Zeitschrift (ZSA) |
|
Wirth, N.: Gedanken zur Software-Explosion. In: Informatik Spektrum, Februar 1994, S. 5 - 10. |
|
Czarski, Carsten: Richtig gefragt. Konstrukte für komplexe Datenbank-Queries. In: iX, Januar 2013, S. 154 - 157. |
|
Schulz, Hajo: Objektorientiert programmieren mit Smalltalk. In: c’t kompakt Programmieren, Heft 03/2012, S. 146 - 152 |
|
Also: Namen und Vornamen; Titel, evtl. Untertitel; Bezeichnung der Zeitschrift, Angaben zum konkreten Heft der Zeitschrift; erste und letzte Seite des Artikels. |
|
2.12.2 Lösungsschritte |
|
Grundstruktur: Werke, Autoren, Autorenschaft |
|
Bevor wir in die eigentliche Modellierung einsteigen, hier einige Ausführungen zur Modellierung dieses Anwendungsbereichs. Zu jeder Fachliteratur, egal ob sie als Buch, Zeitschriftenaufsatz oder sonstwie erscheint, gehört ein Text, dieser wird Werk genannt. Er soll hier durch eine WerkNr identifiziert werden: |
Im Mittelpunkt: das Werk … |
Werke (#WerkNr, ...) |
|
Ein Werk stammt meist von einer oder mehreren natürlichen Personen. Oftmals werden auch Organisationen (Forschungseinrichtungen, Behörden, ...) als Autoren genannt. Inzwischen kann auch ein KI-Programm Texte erstellen und sollte dann als Autor genannt werden. Diese Autoren werden ebenfalls erfasst und durch eine Autorennummer identifiziert (AutorNr). Da es drei Gruppen von Autoren mit teilweise abweichenden Attributen gibt, müssen dafür drei verschiedene Relationen angelegt werden, Organisationen als Autoren (AutOrg), Personen als Autoren (AutPers) und KI-Programme als Autoren: |
… und seine Autoren |
AutPers (#AutorNr, Name, VName, …) |
|
In dieser ersten Fassung der Relation wurden, abgeleitet aus den obigen Beispielen, die Attribute Name und Vorname (VName) eingefügt. |
|
AutOrg(#AutorNr, BezOrg, BezOrg2, …) |
|
Hier wurde die Bezeichnung der Organisation (BezOrg) und die zweite Zeile der Organiationsbezeichnung (BezOrg2) angelegt. |
|
AutKI(#AutorNr, BezKI, Besitzer, …) |
|
Für die KI-Programme werden in der ersten Fassung ihre Bezeichnung (BezKI), z.B. Chatxyz, und der Besitzer (z.B. Google) erfasst. |
|
Hier bietet sich eine Generalisierung / Spezialisierung an. Die Generalisierung wird Autoren genannt. Sie erhält neben der AutorNr ein Attribut Typ mit den Ausprägungen Mensch, Organisation und KI sowie ein Attribut Id1 für Name (bei Menschen), BezOrg (bei Organisationen) bzw. BezKI (bei KI-Programmen): |
Generalisierung / Spezialisierung |
Autoren (#AutorNr, Id1, Typ, …) |
|
Diese Generalisierung hat zwar erst mal wenig Attribute, erleichtert aber Abfrage und Verknüpfung. Vielleicht kommen ja noch Attribute dazu. |
|
Hier gilt ganz grundsätzlich: |
Autorenschaft |
Ein Autor kann mehrere Werke veröffentlichen, ein Werk kann mehrere Autoren haben. |
|
Werke und Autoren sind durch die Autorenschaft verbunden: Diese hält fest, wer welches Werk verfasst hat. Da es sich um eine n:m-Verknüpfung handelt, ergibt sich eine Verbindungsrelation. |
|
Nehmen wir noch dazu, dass bei Werken mit mehreren Autoren die Reihenfolge der Autorennennungen wichtig ist, ergibt sich für die Relation Autorenschaft ein beschreibendes Attribut Rang (an welcher Stelle der Autorenliste kommt er oder sie). Insgesamt liegen dann in textlicher Form folgende Relationenfragmente vor: |
|
AutKI(#AutorNr, BezKI, Besitzer, …) |
|
Autoren (#AutorNr, Id1, Typ, …) |
|
Autorenschaft (#(AutorNr, WerkNr), Rang) |
|
AutOrg(#AutorNr, BezOrg, BezOrg2, …) |
|
AutPers (#AutorNr, Name, VName, …) |
|
Werke (#WerkNr, ...) |
|
Das folgende Modellfragment gibt diesen "Kern" des Datenmodells an. |
|
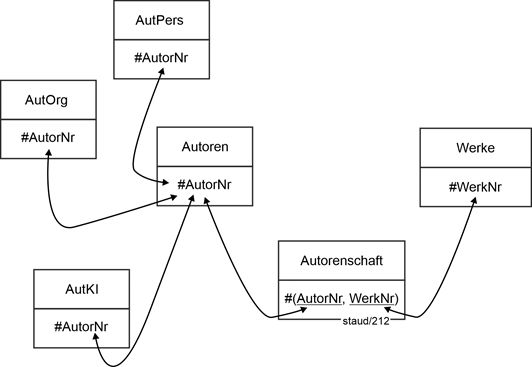
|
|
Abbildung 2.12-1: Autorenschaft im Anwendungsbereich Fachliteratur |
|
Modellierung der Literaturtypen |
|
Die obige Liste von Werken machte den weitergehenden Aufbau der verschiedenen Literaturarten deutlich. In der folgenden Tabelle sind diese Informationen zusammengefasst. Es handelt sich hier um eine Generalisierung / Spezialisierung (vgl. Abschnitt 2.4.2 sowie [Staud 2021, Abschnitt 14.1]). |
Typen bewältigen durch Gen/Spez. |
Werke und ihre Attribute aus der Gen/Spez-Hierarchie |
|
| |
|
Mono |
SB |
SBB |
ZSA |
IQU |
| A |
Autoren: Personen oder Organisationen, u.U. mehrere |
Ja |
Ja |
Ja |
Ja |
ja |
| B |
Titel ggf. Untertitel: UTitel |
Ja |
Ja |
Ja |
Ja |
ja |
| C |
ISBN-Nummer: ISBN |
Ja |
Ja |
- |
- |
- |
| D |
Auflage |
Ja |
Ja |
- |
- |
- |
| E |
Erscheinungsjahr: Jahr |
Ja |
Ja |
- |
- |
- |
| F |
Verlagsort/e, u.U. mehrere: Ort |
Ja |
Ja |
- |
- |
- |
| G |
Verlagsbezeichnung: BezVerlag U.U. mehrere |
Ja |
Ja |
- |
- |
- |
| H |
Von (erste Seite des SBBs bzw. ZSAs) |
- |
- |
Ja |
Ja |
- |
| I |
Bis (letzte Seite des SBBs bzw. ZSAs) |
- |
- |
Ja |
Ja |
- |
| J |
Quelle (SB + Kapitel, in dem der SBB enthalten ist): WerkNr, KapitelNr |
- |
- |
Ja |
- |
- |
| K |
Quelle (Name und Heft der Zeitschrift, in dem der ZSA enthalten ist): ZSBez, HeftNr |
- |
- |
- |
Ja |
- |
| L |
URL |
- |
- |
- |
- |
ja |
| M |
Tag des Abrufs: AbrTag |
- |
- |
- |
- |
ja |
| N |
Anzahl der Kapitel in Sammelbänden: AnzKap |
- |
Ja |
- |
- |
- |
| |
Zeile A ... |
|
sagt, dass alle Werke Autoren haben, die entweder Personen oder Organisationen sind. Dies wurde schon angelegt. |
|
Zeile B ... |
|
gibt den Hinweis auf ein Attribut, das alle verschiedenen Werke haben, den Titel. Außerdem auf eine Spezialisierung von Werke, nämlich Werke mit Untertiteln: |
|
Werke (#WerkNr, Titel, …) |
|
WerkeUT (#WerkNr, UT) |
|
Zeilen C bis G ... |
|
zeigen, dass MONographien (Mono) und SammelBände (SB) die 5 Attribute ISBN, Auflage, Jahr, Ort und BezVerlag gemeinsam haben, womit eine weitere Spezialisierung von Werke entsteht. In die Spezialisierung kommen aber nur drei Attribute, da die Verlagsangaben mehrfach vorkommen können, wenn ein einzelnes Werk von mehreren Verlagen herausgegeben wird. Dazu unten mehr. |
|
Mono+SB (#WerkNr, ISBN, Auflage, Jahr) |
|
Zeilen F und G: vgl. unten |
|
Zeilen H und I ... |
|
geben Attribute an, die nur SBB und ZSA besitzen. Für sie entsteht also eine Spezialisierung: |
|
SBB+ZSA (#WerkNr, Von, Bis) |
|
Zeile J ... |
|
zeigt, dass Sammelbandbeiträge (SBB) eine weitere spezifische Information haben, die Angabe, von welchem Sammelband sie stammen (Quelle). Sie besteht aus zwei Attributen: Werknummer des Sammelbandes (WerkNrSB) und die KapitelNr im Sammelband. Somit entsteht die folgende Relation: |
|
SBB (#WerkNr, WerkNrSB, KapitelNr) |
|
Komposition zwischen SBB und SB als 1:n-Beziehung |
|
Damit liegt eine Komposition zwischen Sammelbandbeiträgen und Sammelbänden vor. Falls ein Sammelband aus dem Buchbestand und damit aus der Datenbank entfernt wird, müssen auch die Sammelbandbeiträge dieses Sammelbands entfernt werden. Die Gestaltung des Schlüssels ergibt sich daraus, dass jeder SBB eine eindeutige Werknummer erhält und auch nur in genau einem SB enthalten ist. So sollte es zumindest sein. Es kommt aber natürlich vor, dass ein Autor sein Werk in mehreren Sammelbänden unterbringt. |
Muster Komposition |
Zeile K ... |
|
zeigt, dass die Zeitschriftenaufsätze ebenfalls eine spezifische Information haben, die Quellenangabe. Sie besteht (im einfachsten Fall) aus zwei Attributen, Zeitschriftenbezeichnung (ZSBez) und Heftnummer (HeftNr): |
|
ZSA (#WerkNr, ZSBez, HeftNr) |
|
Zeilen L, M und N ... |
|
führen zu weiteren Spezialisierungen von Werke, zu Internetquellen (IQU) und zu Sammelbänden (SB). Für die Internetquellen wird die URL und der Tag des Abrufs (AbrTag) angegeben, für die Sammelbände die Anzahl der Kapitel, die sie enthalten (AnzKap): |
|
IQU (#WerkNr, URL, AbrTag) |
|
SB (#WerkNr, AnzKap) |
|
Insgesamt ergibt sich damit folgendes Datenmodell: |
|
IQU (#WerkNr, URL, AbrTag) |
|
ZSA (#WerkNr, ZSBez, HeftNr) |
|
AutOrg(#AutorNr, BezOrg2, BezOrg3) |
|
Autoren (#AutorNr, Id1) |
|
Autorenschaft (#(AutorNr, WerkNr), Rang) |
|
AutPers (#AutorNr, VName, Anrede) |
|
Mono+SB (#WerkNr, ISBN, Auflage, Jahr) |
|
SB (#WerkNr, AnzKap) |
|
SBB (#WerkNr, WerkNrSB, KapitelNr) |
|
SBB+ZSA (#WerkNr, Von, Bis) |
|
Werke (#WerkNr, Titel) |
|
WerkeUT (#WerkNr, UT) |
|
Wertigkeiten |
|
Die folgende Abbildung mit dem Ausschnitt zur Gen/Spez der Werke und zur Komposition zwischen SBB und SB verdeutlicht dieses Strukturmerkmal. Die Beziehungswertigkeiten zeigen zum einen die zwischen jeder Spezialisierung und ihrer Generalisierung (Kardinalität 1:1, Min-/Max-Angaben 0,1 : 1,1), zum anderen die bei einer Komposition, hier zwischen SB und SBB. Die Null bei der Wertigkeit bedeutet, dass es auch Sammelbände gibt, von denen keine Sammelbandbeiträge erfasst sind. Der Fremdschlüssel Fach in Werke wird unten erläutert. |
|
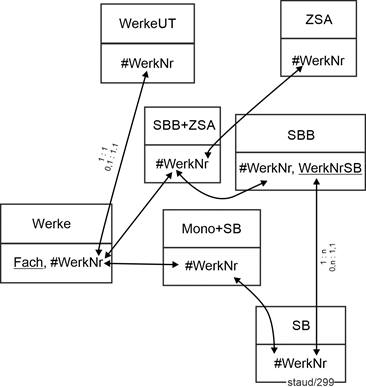
|
|
Abbildung 2.12-2: Gen/Spez zu Literaturarten und Muster Komposition im Anwendungsbereich Fachliteratur |
|
Noch mehr Anforderungen |
|
Erfasst werden soll außerdem, welches Werk von welchem Verlag verfasst wurde. Es kommt auch vor, dass mehrere Verlage zusammen ein Buch publizieren. Bei den Verlagen wird der Ansprechpartner (AnsprV), die allgemeine Telefonnummer (Tel) und die des Ansprechpartners (TelAP) erfasst, für die Adressen der Verlage und die Adressen der Autoren PLZ, Ort und Straße. Von einem Verlag wird nur die Hauptadresse erfasst, von einem Autor mehrere. Es gibt auch Adressen, unter denen mehrere Autoren wohnen. Daraus ergeben sich die folgenden Relationen. Die Veröffentlichungstätigkeit wird als n:m-Verbindung zwischen Verlagen und Werken angesetzt. Die Adressen der Verlage werden durch einen Fremdschlüssel in Verlage integriert. Für die Adressen der Autoren gibt es eine Verbindungsrelation. |
Verlage und Publikationen |
Neue und veränderte Relationen |
|
Verlage (#VerlNr, #BezVerlag,Tel, AnsprV, TelAP, AdrNr) |
|
Publikationen (#(VerlNr, WerkNr)) |
|
Adressen (#AdrNr, PLZ, Ort, Straße) |
|
AutOrg(#AutorNr, BezInst2, BezInst3, AdrNr) |
|
AutPersAdr (#(AutorNr, AdrNr)) |
|
Für die Literatursuche sollen die Werke auch inhaltlich erschlossen werden. Dazu werden für jedes Werk ein Schlagwort (BezSchl) oder mehrere erhoben, z.B. Softwareentwicklung, Datenbankdesign, HTML 5, NoSQL. Jedes Schlagwort wird kurz beschrieben (Beschr), um die exakte Bedeutung zu klären. Dies führt zu folgenden neuen Relationen. |
Inhaltliche Erschließung |
WSchl (#(WerkNr, BezSchl)) |
|
Schlagw (#BezSchl, Beschr) |
|
"Wieviele Werke liegen zu jedem Fachgebiet vor" |
|
Ebenfalls erfasst werden soll ein Fachgebiet pro Werk. D.h. jedes Werk erhält eine Fachgebietszuordnung (Medizin, Technik, Informatik, ...). Diese werden regelmäßig ausgezählt, die Ergebnisse werden auch in der Datenbank verwaltet. |
|
AnzFG (#Fachgebiet, Anzahl) |
|
2.12.3 Lösung |
|
Textliche Fassung |
|
Insgesamt ergeben sich damit folgende Relationen: |
|
Adressen (#AdrNr, PLZ, Ort, Straße) |
|
AnzFG (#Fachgebiet, Anzahl) //Anzahl Werke in den Fachgebieten |
|
Autoren (#AutorNr, Id1, Typ) //Name bzw. Organisationsbezeichnung |
|
Autorenschaft (#(AutorNr, WerkNr), Rang) |
|
AutOrg(#AutorNr, BezInst2, BezInst3, AdrNr) //Organisationen als Autoren |
|
AutPers (#AutorNr, VName, Anrede) //Personen als Autoren |
|
AutPersAdr (#(AutorNr, AdrNr)) //n:m, Autorenadressen |
|
IQU (#WerkNr, URL, AbrTag) //Internetquellen |
|
Mono+SB (#WerkNr, ISBN, Auflage, Jahr) //Monographien und Sammelbände |
|
Publikationen (#(VerlNr, WerkNr)) //Verlage und Veröffentlichungen |
|
SB (#WerkNr, AnzKap) //Sammelbände |
|
SBB (#WerkNr, WerkNrSB, KapitelNr) //Beiträge in Sammelbänden |
|
SBB+ZSA (#WerkNr, Von, Bis) //Seitenzahlen |
|
Schlagw (#BezSchl, Beschr) //Schlagworte |
|
Verlage (#VerlNr, #BezVerlag,Tel, AnsprV, TelAP, AdrNr) //Verlage |
|
Werke (#WerkNr, Titel, Fach) //Textliche Werke (Fachliteratur) |
|
WerkeUT (#WerkNr, UT) //Werke mit Untertiteln |
|
WSchl (#(WerkNr, BezSchl)) //Verschlagwortung |
|
ZSA (#WerkNr, ZSBez, HeftNr) //Zeitschriftenaufsätze |
|
|
|
Grafische Fassung |
|
Die folgende Abbildung zeigt die grafische Darstellung des Datenmodells. Einige beispielhafte Wertigkeiten wurden auch eingefügt. Ein Beispiel für die Wertigkeiten einer n:m-Verknüpfung ist bei Autorenschaft angegeben. Die Min-/Max-Angaben signalisieren, dass nur Autoren aufgenommen werden, die auch mindestens 1 Werk in der Datenbank aufweisen und dass Werke nicht ohne zugehörigen Autor erfasst werden. |
|
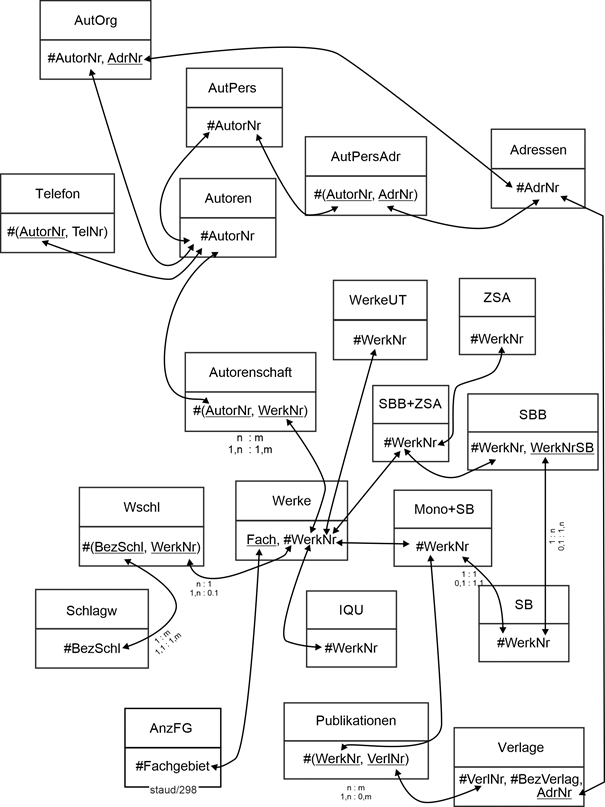
|
|
Abbildung 2.12-3: Relationales Datenmodell zum Anwendungsbereich Fachliteratur |
|
Abkürzungen in den Datenmodellen zur Fachliteratur: |
|
ZS: Zeitschriften |
|
ZSA: Zeitschriftenartikel |
|
SB: Sammelbände |
|
SBB: Beiträg in einem Kapitel eines Sammelbandes |
|
Mono: Monographien |
|
IQU: Internetquellen |
|
2.13 Rechnungsstellung Stufe 1 |
|
2.13.1 Anforderungsbeschreibung |
|
Mit dieser Aufgabe soll ein relationales Datenmodells für den Zweck der Rechnungsstellung erstellt werden. Ausgangspunkt ist dabei die in der folgenden Abbildung angegebene anonymisierte Rechnung, also ein Geschäftsobjekt (business object), was in der Datenmodellierung durchaus oft der Fall ist. |
Rechnungen |
Um die Rechnung aus dem Datenbestand reproduzieren zu können, soll folgendes festgehalten werden: |
|
- Die Kunden werden mit Namen (Name), Vornamen (VName) und Anrede erfasst. Außerdem wird ein identifizierendes Attribut (KuNr) angelegt.
- Ein Kunde wird zuerst mit nur einer Adresse erfasst. Später dann mit beliebig vielen.
- Ein Kunde kann mehrere Telefonanschlüsse haben.
- In der Datenbank wird auch festgehalten, wer die Kundschaft bedient hat (Verkäufer). Dies wird auf der Rechnung ausgegeben.
- Die Information TOUR. Sie bezeichnet das Auslieferungsteam (Tour).
- Die Information KVDAT. Sie gibt den Tag an, an dem die Kundschaft im Möbelhaus war und die Ware bestellt hat (Kvdat).
- Das Datum der Lieferung (DatumLief).
- Der Betrag der Mehrwertsteuer (MWStBetrag).
- Es gilt: Eine Rechnung bezieht sich auf genau einen Auftrag
- Die angegebene Telefonnummer ist die der Rechnungsanschrift
|
|
Die Abkürzungen bei Position 1 bedeuten: |
|
|
889999: Artikelnummer (ArtNr)
|
|
|
B/00/EG: Standort der Ware im Lager (Standort)
|
|
|
COUCHTISCH 1906 EICHE NATUR - MIT LIFT 125x71 cm: Artikelbezeichnung (ArtBez)
|
|
Ansonsten gilt die übliche kaufmännischen Semantik von Rechnungen. |
|

|
|
Abbildung 2.13-1: Geschäftsobjekt Rechnung (Typ Möbelhaus) |
|
2.13.2 Lösungsschritte |
|
Relationale Datenmodellierung kann auch so gelöst werden, dass zuerst die Attribute mit ihren Determinanten und funktionalen Abhängigkeiten bestimmt werden: |
|
- Name: des Kunden
- VNname
- PLZ: der Rechnungsanschrift
- Ort
- Straße
- Tel: Telefonnummer
- KuNr: Kundennummer. Diese ergänzen wir gleich, da die Erfassung der Kunden ohne eine Kundennummer nicht sinnvoll ist.
- ReNr: Rechnungsnummer
- ReDatum: Rechnungsdatum
- Verkäufer: die Angabe des Verkäufers erfolgt auf der Rechnung
- KVDAT: Hierbei handelt es sich um das Kaufvertragsdatum.
- Tour: Bezeichnung des Teams, das mit seinem Fahrzeug die Möbel ausliefert. Eine tiefere Semantik liegt nicht vor.
- PosNr: Rechnungspositionsnummer
- ArtNr: wird bei den Rechnungspositionen angegeben.
- Anzahl der Artikel pro Position
- Standort: Standort der Ware im Lager. Wird bei den Rechnungspositionen angegeben.
- ArtBez: Artikelbezeichnung
- DatumLief: Datum der Lieferung
- MWStB: Betrag der Mehrwertsteuer
- ZV: Zahlungsvereinbarung
- LiPreis: Listenpreis. Der Preis für die gesamte Position wird berechnet aus Anzahl und Preis.
|
|
Für einige Artikel liegt noch eine Beschreibung vor (Beschr), die aber nicht auf der Rechnung ausgegeben wird. In der Datenbank soll sie trotzdem erfasst werden. |
|
Datenbankdesigner haben es nicht gerne, Informationen im Anwendungsprogramm zu hinterlegen oder in separaten (neben der Datenbank befindlichen) Tabellen und dies obwohl der neueste Datenbank-Ansatz (NoSQL) sehr viel Semantik im Programm umsetzt. Und doch kann es manchmal sinnvoll sein. Hier soll dies beispielhaft mit dem Mehrwertsteuersatz geschehen. Er wird im Programm hinterlegt, der Mehrwertsteuerbetrag (MWStB) wird dann daraus und aus der Rechnungssumme berechnet. |
Informationen im Programm |
Universalrelation |
|
Das folgende muss man nicht machen, es hilft aber in komplexen Situationen gerade zu Beginn der Modellierung. Wir betrachten alle Attribute und bestimmen alle funktionalen Abhängigkeiten, z.B. durch FA-Diagramme. |
|
Nach einigen langen Besprechungen ergab sich über die gesamte Universalrelation das folgende FA-Diagramm. |
|
|
|
Abbildung 2.13-2: FA-Diagramm zur Universalrelation Rechnungen |
|
Grundlage der Betrachtung der funktionalen Abhängigkeiten im FA-Diagramm ist die Kenntnis der Semantik des Anwendungsbereichs. Neben den funktionalen Abhängigkeiten sind auch gleich die Determinaten zu bestimmen. Hier sind dies, wie die Abbildung anschaulich zeigt, KuNr, (ReNr, PosNr), ReNr, ArtNr. Dies sind Kandidaten für die Schlüssel der zu findenden Relationen. |
|
Welche Relationen können wir daraus ableiten? Sie sind in obiger Abbildung leicht zu erkennen. Alle Determinanten mit ihren funktional abhängigen Attributen werden normalerweise zu Relationen. Die Determinanten werden dann zu Schlüsseln. |
|
Problemlos zu erkennen sind die Kunden: Identifiziert werden sie durch die KuNr. Voll funktional abhängig von dieser sind die folgenden Attribute: |
Kunden |
- KuNr => Name
- KuNr => VName
- KuNr => PLZ
- KuNr => Ort
- KuNr => Straße
|
|
Für die Adressangaben gilt dies nur, weil wir uns in Stufe 1 mit der Rechnungsanschrift begnügen. Damit ergibt sich die erste Relation: |
|
|
|
Abbildung 2.13-3: FA-Diagramm von Kunden |
|
Kunden (#KuNr, Name, VName, PLZ, Ort, Straße) |
|
Die Telefonanschlüsse wurden oben weggelassen, da ja jeder Kunde mehrere haben kann. Dies ist dann keine funktionale Abhängigkeit. Hier können wir sie wieder dazutun, in einer eigenen Relation: |
|
KuTel(#(KuNr, Tel)) |
|
KuNr ist Fremdschlüssel und dient der Verknüpfung mit Kunden. |
|
Oben fällt der Attributsblock auf, der von ReNr funktional abhängig ist. Dies sind Attribute, mit denen die Rechnung beschrieben wird. In Abgrenzung zu den Rechnungspositionen soll er Rechnungsköpfe (ReKöpfe) genannt werden. |
Rechnungsköpfe |
Die kaufmännische Semantik und die relationale Theorie sagen uns, dass es eine Unterscheidung geben muss zwischen Rechnungskopf (identifiziert durch die Rechnungsnummer (ReNr)) und den Rechnungspositionen, denn es gibt pro Rechnung mehrere Positionen. Letztere werden durch (ReNr, PosNr) identifiziert. |
|
Folgende funktionalen Abhängigkeiten bestehen von der Determinante ReNr, die – spätestens nach der Normalisierung – zum Schlüssel wird. |
|
- ReNr => ReDatum: Es gibt genau ein Rechnungsdatum pro Rechnung bzw. von der Rechnungsnummer kann auf das Rechnungsdatum geschlossen werden.
- ReNr => Verkäufer: Da immer nur einer für einen Kaufvertrag zuständig ist und nur einer auf der Rechnung erscheint.
- ReNr => Tour: Es gibt ein Auslieferungsteam je Rechnung.
- ReNr => KVDAT: Es gibt hier genau ein Kaufvertragsdatum je Rechnung.
- ReNr => MWStB: Es gibt nur einen Mehrwertsteuerbetrag je Rechnung.
- ReNr => DatumLief: Für jede Rechnung gibt es genau ein Lieferdatum.
- ReNr => ZV: Die Zahlungsvereinbarung ist je Rechnung eindeutig. Trotz Nachfragen konnte auch keine weitere Semantik (z.B. Abhängigkeit vom gekauften Produkt) festgestellt werden.
|
|
Damit ergibt sich folgende Relation zu den Rechnungsköpfen: |
|
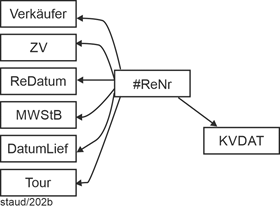
|
|
Abbildung 2.13-4: FA-Diagramm von Rechnungsköpfen (ReKöpfe) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB) |
|
Auch diese ist in 5NF. |
|
Die letzten leicht erkennbaren Objekte sind die Artikel. Sie werden identifiziert (ArtNr), haben eine Bezeichnung (ArtBez) und werden beschrieben. ArtNr wird also von der Determinante zum Schlüssel mit folgenden funktional abhängigen Attributen: |
Artikel |
- ArtNr => ArtBez
- ArtNr => ArtBeschr
- ArtNr => LiPreis: Da es sich um den Einzelpreis der Artikel handelt.
- ArtNr => Standort: Standort der Ware im Lager. Für einen Artikel immer derselbe.
|
|
Dies führt zu folgender Relation: |
|
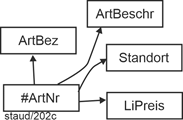
|
|
Abbildung 2.13-5: FA-Diagramm von Artikel |
|
Artikel (#ArtNr, ArtBez, ArtBeschr, LiPreis, Standort) |
|
Beim Überprüfen der Semantik überkommen uns Zweifel. Die Artikelbeschreibung liegt derzeit nur für 10% der Artikel vor. Soll das Attribut dann hier bleiben? In der späteren Datenbank wird dann für jeden Artikel der Speicherplatz für die Beschreibung verbraucht, auch wenn keine vorliegt. Da unser Datenbankmanagementsystem an dieser Stelle keine dynamische Speicherverwaltung anbietet, beschließen wir, die Artikelbeschreibung in eine eigene Relation auszulagern. |
Pragmatik |
Damit erhalten wir eine Generalisierung / Spezialisierung. In der relationalen Modellierung wird dafür für die Spezialisierung eine eigene Relation angelegt mit dem entsprechenden Attribut und mit dem Schlüssel der Generalisierung: |
Muster Generalisierung / Spezialisierung |
ArtBeschr(#ArtNr, ArtBeschr) //Artikelbeschreibung |
|
Auch hier gibt es keinen Verstoß gegen die 5NF. |
|
Bleiben noch die übrigen Attribute. Sie bewegen sich alle um die Rechnungspositionen herum. Rechnungspositionen werden durch eine Attributskombination identifiziert: (ReNr, PosNr). Folgende funktionalen Abhängigkeiten bestehen: |
|
- (ReNr, PosNr) => ArtNr: Da es pro Rechnungsposition nur einen Artikel gibt.
- (ReNr, PosNr) => Anzahl: Anzahl der Artikel je Position.
|
|
Damit ergibt sich folgende Relation zu Rechnungspositionen, ebenfalls in 5NF: |
|
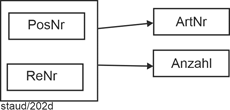
|
|
Abbildung 2.13-6: FA-Diagramm zu Rechnungspositionen (RePos) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl). |
|
Oftmals wird in Übungen obige Relation über den Zusammenhang von Rechnung und Artikeln erkannt. Da es typischerweise pro Rechnung mehrere Artikel gibt und die Artikel auch auf mehreren Rechnungen auftauchen (ein bestimmtes Sofa, das hundert mal verkauft wurde) wird dabei dann zuerst eine Verbindungsrelation mit dem Schlüssel (ReNr, ArtNr) eingerichtet. Dann wird die PosNr zu einem beschreibenden Attribut der Relation. Insgesamt also: |
Alternativer Weg |
RePos (#(ReNr, ArtNr), PosNr, Anzahl) //Alternative |
|
Relationale Verknüpfungen |
|
In dem Lösungsweg sind nun sechs Relationen entstanden, die wesentliche Merkmale der Rechnung beschreiben. Zu prüfen sind aber noch die die relationalen Verknüpfungen und damit die Schlüssel/Fremdschlüssel – Beziehungen. |
|
- Zwischen Kunden und ReKöpfe: Hier liegt sicherlich eine Beziehung vor. Ein Kunde hat u.U. viele Rechnungen mit dem Unternehmen, aber eine Rechnung bezieht sich immer nur auf einen Kunden. Diese 1:n - Beziehung kann verankert werden, indem in ReKöpfe die Kundennummer als Fremdschlüssel festgehalten wird.
|
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB, KuNr) |
|
Damit ist auch festgelegt, dass es keinen Rechnungskopf ohne Kundennummer gibt (denn ein Fremdschlüssel darf nie leer bleiben). Wenn wir annehmen, dass in der Datenbank nur Kunden erfasst sind, die schon gekauft haben, gelten die Min-/Max-Angaben von Kunden zu ReKöpfe 1,n : 1,1. |
|
- Zwischen Kunden und Artikel: Hier gibt es auf der Ebene der Relationen keine direkte Beziehung. Die Beziehung manifestiert sich durch die Rechnung und ihre Positionen. Wenn man sie trotzdem einrichtet, um z.B. im Rahmen des Kundenbeziehungsmanagements (Customer Relationship Management; CRM) schnellen Zugriff auf die vom Kunden schon getätigten Käufe zu haben, ist das möglich. Dafür müsste eine Verbindungsrelation eingerichtet werden.
- Zwischen Kunden und RePos (Rechnungspositionen): Auch hier gibt es auf der Ebene der Relationen keine Beziehung. Die Verknüpfung erfolgt über die Rechnung.
- Zwischen ReKöpfe und Artikel: Dieser Zusammenhang wird über die RePos hergestellt.
- Zwischen ReKöpfe und RePos: Diese Beziehung ist natürlich fundamental. Es ist eine 1:n - Beziehung, denn eine Rechnung kann mehrere Positionen haben, eine Rechnungsposition gehört aber immer zu einer bestimmten Rechnung. Damit handelt es sich bei diesem Muster um eine Komposition. Diese Beziehung wurde aber schon bei der Festlegung des Schlüssels von RePos festgelegt. Es muss lediglich noch die ReNr als Fremdschlüssel gekennzeichnet werden:
|
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Komposition bedeutet ja Existenzabhängigkeit, die hier ganz klar zu erkennen ist. Da ein zusammengesetzter Schlüssel, wie hier (ReNr, PosNr), immer vollständig sein muss, kann es keine Rechnungsposition ohne zugehörigen Rechnungskopf geben. Und: Wird ein Rechnungskopf gelöscht, müssen auch die verbundenen Rechnungspositionen gelöscht werden. Die Min-/Max-Angaben sind 1,1 : 1,n, von RePos ausgehend. |
|
- Zwischen Artikel und Rechnungspositionen (RePos): Auch hier liegt eine 1:n - Beziehung vor. Ein Artikel kommt hoffentlich auf vielen Rechnungspositionen vor und eine Rechnungsposition erfasst genau einen Artikel. Die Min-/Max-Angabe von 1,1 auf der Seite der Rechnungspositionen ist hier besonders sinnvoll, denn es hat keinen Sinn, Rechnungspositionen ohne Artikel zu erfassen. Damit kann die Verknüpfung durch Übernahme der ArtNr in die Relation RePos eingerichtet werden. Da dies oben schon geschehen ist (falls nicht, würde das Defizit spätestens hier erkannt), muss lediglich noch die Kennzeichnung von ArtNr als Fremdschlüssel erfolgen:
|
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Die funktionalen Abhängigkeiten sind in allen Relationen bereits geklärt, da ja die Attribute so zu Relationen gruppiert wurden, dass jeweils ein Schlüssel und die von ihm voll funktional abhängigen Attribute zusammen kamen. Da keine überlappenden Schlüssel auftreten, ist die BCNF auch gesichert. Da darüber hinaus die in der vierten und fünften Normalform angesprochenen Probleme nicht auftreten, befinden sich alle Relationen in 5NF. |
Idealstruktur - redundanzfrei |
Die folgende Abbildung zeigt die grafische Darstellung des Datenmodells. |
|
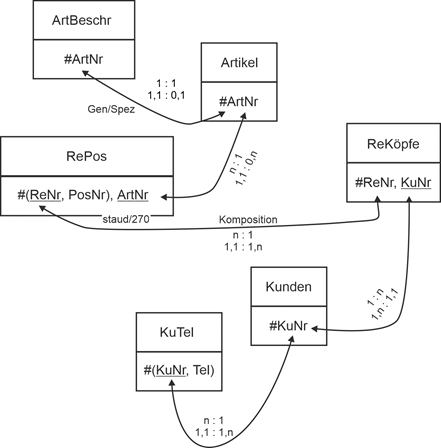
|
|
Abbildung 2.13-7: Relationales Datenmodell Rechnungsstellung Stufe 1 |
|
Hier noch die textlichen Notationen - im Zusammenhang: |
|
2.13.3 Lösung Stufe 1 |
|
ArtBeschr(#ArtNr, Beschr) |
|
Artikel (#ArtNr, ArtBez, Standort, LiPreis) |
|
Kunden (#KuNr, Anrede, Name, VName, PLZ, Ort, Straße) |
|
KuTel(#(KuNr, Tel)) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB, KuNr) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
2.14 Rechnungsstellung Stufe 2 |
|
2.14.1 Anforderungsbeschreibung |
|
Hier soll das Überarbeiten eines Datenmodells thematisiert werden. Dies ist eine Standardaufgabe, denn ein Anwendungsbereich verändert sich ständig und wenn dies geschieht, muss das Datenmodell und dann die Datenbank angepasst werden. |
Überarbeiten |
Das folgende Datenmodell aus obiger Aufgabe ist der Ausgangspunkt. Wie zu Beginn von Aufgabe 3.11 erläutert, beschreibt es einen Anwendungsbereich zur Rechnungsstellung: |
|
ArtBeschr(#ArtNr, Beschr) |
|
Artikel (#ArtNr, ArtBez, Standort, LiPreis) |
|
Kunden (#KuNr, Anrede, Name, VName, PLZ, Ort, Straße) |
|
KuTel(#(KuNr, Tel)) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB, KuNr) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
In Stufe 2 wird nun zwischen Liefer- und Rechnungsadresse unterschieden und es soll gelten: Ein Kunde kann beliebig viele Adressen haben, jede kann bei einer Rechnung Liefer- oder Rechnungsadresse sein. |
Liefer- und Rechnungsadresse |
2.14.2 Lösungsschritte |
|
Da es nun mehrere Adressen je Kunde geben kann ist eine Folge dieser neuen Anforderungen, dass die alte Relation Kunden verkürzt wird, da die Adressattribute in eine eigene Relation Adressen gehen. Übrig bleiben KuNr, Name, VName, so dass daraus die neue Kundenrelation entsteht: |
|
Kunden (#KuNr, Name, Vorname) |
|
Die neue Relation Adressen erhält zusätzlich einen Schlüssel Adressnummer (AdrNr), denn einen Schlüssel braucht jede Relation: |
|
Adressen (#AdrNr, PLZ, Ort, Straße, Telefon) |
|
Nun fehlt noch die Verknüpfung zwischen den Kunden und Adressen. Deren Wertigkeit ist n:m, denn ein Kunde kann ja mehrere Adressen haen und unter einer Adresse wohnen u.U. mehrere Kunden (Mehrfamilienhäuser). Es wird also eine Verbindungsrelation Kunden/Adressen benötigt. Sie wird KuAdr genannt: |
|
KuAdr (#(KuNr, AdrNr)) |
|
Beide Attribute wurden gleich als Fremdschlüssel gekennzeichnet. Damit ist im Datenmodell die Beziehung zwischen Kunden und Adressen festgehalten. Die Min-/Max-Angaben sind 1,n : 1,m, da nur Kunden mit Adressen und nur Adresen mit Kunden erfasst werden wollen. |
|
Bleibt noch zu klären, wie festgehalten wird, welche bei einer bestimmten Lieferung die Liefer- und welche die Rechnungsadresse ist. Bisher war diesbezüglich ja einfach die KNr als Fremdschlüssel in ReKöpfe hinterlegt. |
|
Eine sinnvolle Lösung ist, für jede Lieferung die drei Relationen Kunden, Adressen und Rechnungsköpfe zu verknüpfen und bei jeder Verknüpfung festzuhalten, ob es sich um die Liefer- oder die Rechnungsadresse handelt (hier mit dem Attribut Typ). Dann kann es pro Lieferung eine oder zwei solche Verknüpfungen geben, je nachdem, wieviele Adressen der Kunde angegeben hat. Die Relation hat damit drei Fremdschlüssel: |
|
Lieferungen (#(KuNr, AdrNr, ReNr), Typ) |
|
Das Attribut Typ hat die Ausprägungen L(ieferadresse) und R(echnungsadresse). R gibt es immer, L nur, falls es eine extra Lieferanschrift gibt. Ansonsten ist die Rechnungsanschrift gleich der Lieferanschrift. Diese Semantik muss über die Datenbankprogrammierung sichergestellt werden. Die folgende Tabelle zeigt zur Verdeutlichung einige Beispielsdaten: |
|
Lieferungen |
|
| ReNr |
KuNr |
AdrNr |
Typ |
| 1001 |
007 |
2 |
L |
| 1001 |
007 |
5 |
R |
| 2002 |
007 |
1 |
R |
| 2020 |
010 |
1 |
R |
| ... |
... |
... |
... |
| |
Zur Veranschaulichung wurde in den Daten auch der Fall mit eingefügt, dass unter einer Adresse mehrere Kunden wohnen (Rechnungsnummern 2002 und 2020). |
|
Die Relation KuAdr wird jetzt eigentlich nicht mehr benötigt. Die Beziehung zwischen Kunden und Adressen könnte auch aus Lieferungen gewonnen werden. Da es aber oftmals sinnvoll ist, die Adressen von Kunden auch ohne die Rechnungen/Lieferungen ansprechen zu können, z.B. bei Marketingmaßnahmen oder ganz allgemein im Customer Relationship Management (CRM), soll sie drin bleiben. |
Pragmatik |
Die Wertigkeiten bei der dreistelligen Beziehung Lieferungen ergeben sich – von Lieferungen ausgehend – zu Kunden, Adressen und ReKöpfe wie folgt: Kardinalität 1,1, Min-/Max-Angabe 1,1 : 0,n (falls ein Kunde vor seiner ersten Lieferung erfasst werden kann). |
|
2.14.3 Lösung |
|
Textliche Fassung |
|
Adressen (#AdrNr, PLZ, Ort, Straße, Telefon) |
|
ArtBeschr(#ArtNr, ArtBeschr) |
|
Artikel (#ArtNr, ArtBez, Standort, LiPreis) |
|
KuAdr (#(KuNr, AdrNr)) |
|
Lieferungen (#(KuNr, AdrNr, ReNr), Typ) |
|
Kunden (#KuNr, Anrede, Name, Vorname) |
|
KuTel(#(KuNr, Tel)) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Grafische Fassung |
|
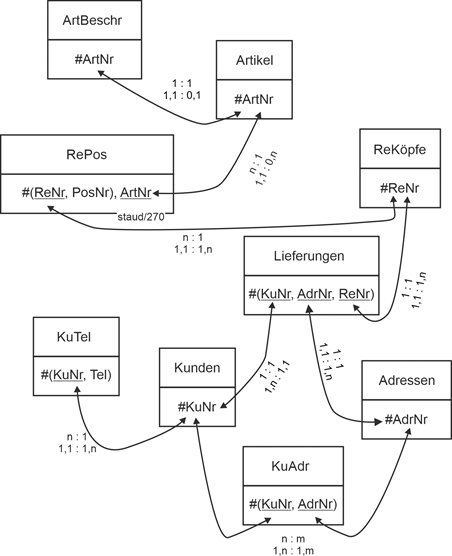
|
|
Abbildung 2.14-1: Datenmodell Rechnungsstellung Stufe 2 |
|
2.15 Rechnungsstellung Stufe 3 |
|
Vgl. zur zeitlichen Dimension auch [Staud 2021, Kapitel 15]. |
|
2.15.1 Anforderungsbeschreibung |
|
Hier geht es um die Änderung eines Datenmodells. Ausgangspunkt ist das Datenmodell Rechnungsstellung aus obiger Aufgabe: |
|
Adressen (#AdrNr, PLZ, Ort, Straße, Telefon) |
|
ArtBeschr(#ArtNr, ArtBeschr) |
|
Artikel (#ArtNr, ArtBez, Standort, LiPreis) |
|
KuAdr (#(KuNr, AdrNr)) |
|
Lieferungen (#(KuNr, AdrNr, ReNr), Typ) |
|
Kunden (#KuNr, Anrede, Name, Vorname) |
|
KuTel(#(KuNr, Tel)) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Nun soll eine zeitliche Dimension hinzugefügt werden und zwar mit dem Ziel, die Rechnungen der vergangenen Jahre aus der Datenbank heraus reproduzierbar zu halten, auch wenn sich die Stammdaten verändern. Bei einer Rechnungsstellung entstehen ja Daten zum kaufmännischen Vorgang, die auch nicht mehr verändert werden. Z.B. Rechnungsnummer, Rechnungsdatum, Artikelbeschreibung, Positionssummen, Gesamtsumme. Andere Daten werden mit Hilfe der durch das Datenmodell vorgegebenen Struktur im Moment der Rechnungsstellung aus den Datenbeständen geholt: zum Kunden, zu den Artikeln. Genau diese Daten können sich aber nach dem Zeitpunkt der Rechnungsstellung sehr schnell ändern: |
Zeitliche Dimension |
- Der Kunde zieht um, seine Telefonnummer ändert sich, er ändert seinen Namen.
- Die Artikelpreise ändern sich, Artikel verschwinden aus dem Sortiment, ihre Bezeichnung oder auch Beschreibung ändert sich.
|
|
Und so weiter. |
|
2.15.2 Lösungsschritte |
|
Die Lösung besteht darin, die "vergänglichen" Attribute bzw. deren Ausprägungen zum Zeitpunkt der Rechnungsstellung (RZ; Rechnungsstellungszeitpunkt) festzuhalten. Dazu werden diese Attribute an geeigneter Stelle im Datenmodell angelegt und dann in der Datenbank gespeichert. |
|
Die erste Überlegung bei einer solchen Anpassung des Datenmodells ist also, welche Attribute sich im Zeitverlauf ändern können. Von diesen müssen die Attributsausprägungen gerettet werden. In obigem Datenmodell sind dies bezüglich der Kunden: Name, Vorname, PLZ, Ort, Straße. Dies geschieht, indem sie mit dem Zusatz "RZ" zusätzlich aufgenommen werden: |
Zu „rettende“ Kundendaten |
- Name-RZ
- Vorname-RZ
- PLZ-RZ
- Ort-RZ
- Straße-RZ
|
|
Hier stehen dann jeweils die Attributsausprägungen des Rechnungsstellungszeitpunkts drin. |
|
In welcher Relation soll man sie unterbringen? Hier hilft die Überlegung, von welcher Determinante diese Attribute funktional abhängig sind. Natürlich von der Rechnungsnummer, also gehören sie in die Relation ReKöpfe. Da sich der Mehrwertsteuersatz ja auch regelmäßig ändert und auf der Rechnung ausgewiesen ist, muss auch er "konserviert" werden. Auch er ist von der Rechnungsnummer funktional abhängig. Somit ergibt sich: |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB, Name-RZ, VName-RZ, PLZ-RZ, Ort-RZ, Straße-RZ, Tel-RZ, MWStS-RZ) |
|
Folgende "vergänglichen" Attribute bezüglich der Artikel sollten, da sie auf der Rechnung erscheinen, verdoppelt werden: Artikelnummer (ArtNr), Artikelbezeichnung (ArtBez), Listenpreis (LiPreis). Wieder hängen wir das Kürzel RZ an. Der Platz für diese Attributdoppelung ist, auch hier hilft wieder die Überlegung zu den funktionalen Abhängigkeiten und zur Determinante, die Relation Rechnungspositionen: |
Zu "rettende" Artikeldaten |
RePos (#(ReNr, PosNr), ArtNr, Anzahl, ArtNr-RZ, ArtBez-RZ, LiPreis-RZ) |
|
Fassen wir das Vorgehen zusammen. Folgende Schritte sind zu leisten: |
|
- Klären, welche Attribute wegen der notwendigen Reproduzierbarkeit dupliziert werden müssen.
- Feststellen, wo diese Attribute platziert werden können durch Klärung der Frage, wovon sie funktional abhängig sind.
|
|
Damit ergibt sich das folgende Datenmodell. |
|
2.15.3 Lösung |
|
Textliche Fassung |
|
Adressen (#AdrNr, PLZ, Ort, Straße) |
|
ArtBeschr(#ArtNr, ArtBeschr) |
|
Artikel (#ArtNr, ArtBez, Standort, LiPreis) |
|
KuAdr (#(KuNr, AdrNr)) |
|
Lieferungen (#(KuNr, AdrNr, ReNr), Typ) |
|
Kunden (#KuNr, Anrede, Name, Vorname) |
|
KuTel(#(KuNr, Tel)) |
|
ReKöpfe (#ReNr, ReDatum, KVDAT, Tour, Verkäufer, DatumLief, ZV, MWStB, Name-RZ, VName-RZ, PLZ-RZ, Ort-RZ, Straße-RZ, Tel-RZ) |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl, ArtNr-RZ, ArtBez-RZ, LiPreis-RZ) |
|
RZ : Zeitpunkt der Rechnungsstellung |
|
Grafische Fassung |
Grafisches Datenmodell |
Das grafische relationale Datenmodell bleibt gleich, da die duplizierten Attribute weder Schlüssel noch Fremdschlüssel sind. Mit dieser Methode des Einbindens der zeitlichen Dimension sind die "geretteten" Daten in die operative Datenbank integriert. |
|
Das Befüllen der zeitlich fixierten Attribute erfolgt in der Datenbankprogrammierung. Bei jeder Transaktion (Rechnungserstellung) werden die zeitabhängigen Attribute mit der jeweils aktuellen Attributsausprägung beschrieben. |
Datenbank-programmierung |
2.16 PC-Beschaffung |
|
Vgl. Abschnitt 5.1 für die ER-Modellierung desselben Anwendungsbereichs, allerdings mit etwas anderen Anforderungen. |
|
Mit diesem Beispiel soll vertieft auf das Muster Einzel/Typ hingewiesen werden. Z.B., was die relationalen Verknüpfungen angeht. Eine Verknüpfung auf Typ-Ebene erfasst andere Informationen als auf Einzel-Ebene. |
Einzelgerät vs. Typ |
2.16.1 Anforderungsbeschreibung |
|
In einem Unternehmen soll der Vorgang der PC-Beschaffung durch eine Datenbank festgehalten werden. Folgende Festlegungen ergaben sich in den Interviews, die im Vorfeld mit den Betroffenen geführt wurden: |
|
|
(1) Jeder PC erhält eine Inventarnummer (InvPC), ebenso die Bildschirme (InvBS). Jedem PC ist ein Bildschirm zugeordnet. Einige Nutzer benötigen für ihre Aufgaben zwei Bildschirme an ihrem PC.
|
|
|
(2) Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein optisches Laufwerk (DVD, CD-ROM, usw.) vorhanden ist und welche Bezeichnung und Geschwindigkeit (BezLW bzw. Geschw) es hat. Es können durchaus mehrere optische Laufwerk eines Typs in einen PC eingebaut sein (z.B. zu Archivierungszwecken), so dass auch die Anzahl festgehalten wird. Natürlich gibt es einen Laufwerkstyp durchaus in verschiedenen Rechnern.
|
|
|
(3) Für alle PC wird festgehalten, ob Programmiersprachen (PS) installiert sind und falls ja, welche. Für die PC der Entwickler wird die hauptsächlich verwendete Entwicklungsumgebung (EntwUmg) festgehalten.
|
|
|
(4) In diesem Unternehmen wird vor der Übergabe des PC an den Nutzer durch die IT geprüft, ob das Gehäuse, die jeweilige Hauptplatine und die Grafikkarte für die Anforderungen des Nutzers geeignet sind. Falls nicht, werden sie ausgetauscht. Deshalb werden diese drei Komponenten in der Datenbank ausgewiesen. Alle mit ihrer Bezeichnung (BezGH, BezHP, BezGK), die Gehäuse noch mit Größenangaben (Größe), die Hauptplatinen mit der Anzahl der Prozessoren (AnzProz) und die Grafikkarten mit ihrer maximalen Auflösung (Auflösung). Natürlich kommt es vor, dass idetnische Komponenten in mehreren PC eingebaut werden.
|
|
|
(5) Für jede Festplatte wird die Bezeichnung (BezPl), die Speicherkapazität (Größe) sowie die Zugriffsgeschwindigkeit (Zugriff) erfasst. Jede Festplatte erhält von der IT-Abteilung eine eindeutige Seriennummer (SerNrF), angelehnt an die des Festplattenherstellers und wird ausführlich getestet. Das Ergebnis, ein Qualitätskoeffizient (Qual), wird auch festgehalten. Es kommt durchaus vor, dass ein PC mehrere Festplatten hat, aber nicht umgekehrt.
|
|
|
(6) Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die im PC enthaltenen sonstigen Komponenten (W-LAN-Komponente, Kamera, usw.) festgehalten. Natürlich kommt eine bestimmte Komponente in mehreren PC vor. Außerdem hat ein PC typischerweise mehrere solcher "sonstigen Komponenten".
|
|
|
(7) Für jeden ins Unternehmen gegebenen PC wird weiterhin festgehalten, wer ihn nutzt, erfasst über die Personalnummer (PersNr), Name, Vorname (VName) sowie Telefonnummer (Tel) und wann er dort eingerichtet wurde (DatEinr). Ein bestimmter PC wird immer von genau einem Angestellten genutzt, ein Angestellter kann bis zu zwei PC zugeordnet bekommen.
|
|
|
(8) Für Bildschirme wird neben der Bezeichnung (BezBS) noch festgehalten, von welcher Art (Art) sie sind, welchen Durchmesser sie haben (Zoll) und wann sie übergeben wurden (DatÜb).
|
|
2.16.2 Lösungsschritte |
|
Zur Erstellung des Datenmodells werden - Schritt um Schritt - nochmals die Anforderungen betrachtet, jeweils etwas eingerückt. |
|
Jeder PC erhält eine Inventarnummer (InvPC), ebenso die Bildschirme (InvBS). Jedem PC ist ein Bildschirm zugeordnet. Einige Nutzer benötigen für ihre Aufgaben zwei Bildschirme an ihrem PC. |
|
Für jeden PC wird folgendes festgehalten: der Prozessortyp (Proz), die Größe des Arbeitsspeichers (ArbSp), ob ein optisches Laufwerk (DVD, CD-ROM, usw.) vorhanden ist und welche Bezeichnung und Geschwindigkeit (BezLW bzw. Geschw) es hat. Es können durchaus mehrere optische Laufwerk eines Typs in einen PC eingebaut sein (z.B. zu Archivierungszwecken), so dass auch die Anzahl festgehalten wird. Natürlich gibt es einen Laufwerkstyp durchaus in verschiedenen Rechnern. |
|
Für alle PC wird festgehalten, ob Programmiersprachen (PS) installiert sind und falls ja, welche. Für die PC der Entwickler wird die hauptsächlich verwendete Entwicklungsumgebung (EntwUmg) vermerkt. |
|
Da PC nicht nur identifiziert, sondern auch beschrieben werden, stellen sie eine Relation dar. Mit den Attributen, die im Text genannt werden und die "keine Probleme" machen ergibt sich der nachfolgende Erstentwurf. |
Relation PC. |
Die Bildschirme tauchen in diesem Textabschnitt nur mit einem einzigen identifizierenden Attribut auf. Ein Blick weiter nach unten in obigen Anforderungen zeigt aber, dass sie weiter beschrieben werden. Also können wir auch dafür eine Relation anlegen. Außerdem ist angegeben, dass jedem PC ein oder zwei Bildschirme zugeordnet sind. Das macht eine Verbindungsrelation zwischen PC und Bildschirmen nötig (PC_BS-Einzeln). |
BS |
PC (#InvPC, Proz, ArbSp, ...) |
|
PC_BS-Einzeln(#(InvPC, InvBS)) |
|
BS-Einzeln (#InvBS, ...) |
|
Optische Laufwerke |
|
Die optischen Laufwerke werden selbst existent, weil sie identifiziert und beschrieben werden. Zu beachten ist, dass sie auf Typebene erfasst sind, was auch im Schlüssel ("Bezeichnung") zu erkennen ist. Mit der Festlegung, dass ein PC auch mehrere optische Laufwerke enthalten kann, ergibt sich damit: |
Muster Einzel/Typ |
OptLw (#BezLW, Geschw) |
|
OptLw_PC (#(BezLW, InvPC), Anzahl) |
|
Hier gibt es oft Verständnisprobleme: In einem PC können durchaus Laufwerke verschiedener Typen (z.B. eines von Seagate, zwei von IBM) eingebaut sein. Deshalb die Relation OptLw_PC. |
|
Man beachte die eingeschränkte Aussagekraft einer solchen Modellierung. Festgehalten wird nicht, welche konkreten Laufwerke in den PC eingebaut sind, sondern nur, wieviele verschiedene Laufwerkstypen. Schon bei der Angabe eines einzigen Typs können dies beliebig viele konkrete Laufwerke sein. |
|
Programmiersprachen |
|
Die Installation der Programmiersprachen wird durch eine eigene Relation PSInstall festgehalten. Der Schlüssel ergibt sich daraus, dass auf einem PC u.U. mehrere Programmiersprachen eingerichtet sind und eine Programmiersprache auf mehreren PC installiert ist. |
|
PS-Install (#(InvPC, ProgSpr)) |
|
Die Hinweise auf die PC der Entwickler führen zu einer Spezialisierung. Es entsteht eine eigene Relation mit dem zusätzlichen Attribut. |
Muster Gen/Spez |
EntwPC (#InvPC, EntwUmg) |
|
Die Verknüpfung der installierten Programmiersprachen mit den PC erfolgt dann über EntwPC. Vgl. die Abbildung unten. |
|
Bildschirme |
|
Bei den Bildschirmen klärt sich die Modellierungssituation im letzten Teil der Anforderungsliste: |
|
Für Bildschirme wird neben der Bezeichnung (BezBS) noch festgehalten, von welcher Art (Art) sie sind, welchen Durchmesser sie haben (Zoll) und wann sie übergeben wurden (DatÜb). |
|
Damit ergibt sich, dass zu Beginn zu Recht die Einzelinformation zu Bildschirmen angelegt wurde (lag ja auch nahe, angesichts des Schlüssels InvBS). Insgesamt ergeben die Attribute aber auch noch eine Relation mit Typinformation zu den Bildschirmen: |
Muster Einzel/Typ |
BS-Einzeln (#InvBS, BezBS, DatÜb) |
|
BS-Typen (#BezBS, Art, Zoll) |
|
Der Fremdschlüssel ist nötig, damit die Einzelinformationen mit den Typinformationen verknüpft werden können. Der Fremdschlüssel hält fest, zu welchem Bildschirmtyp ein bestimmter Bildschirm gehört. |
|
Komponentenpräzisierung. |
|
Der nächste Abschnitt der Spezifikation legt fest, welche Komponenten auf welche Weise erfasst werden. |
|
In diesem Unternehmen wird vor der Übergabe des PC an den Nutzer durch die IT geprüft, ob das Gehäuse, die jeweilige Hauptplatine und die Grafikkarte für die Anforderungen des Nutzers geeignet sind. Falls nicht, werden sie ausgetauscht. Deshalb werden diese drei Komponenten in der Datenbank ausgewiesen. Alle mit ihrer Bezeichnung (BezGH, BezHP, BezGK), die Gehäuse noch mit Größenangaben (Größe), die Hauptplatinen mit der Anzahl der Prozessoren (AnzProz) und die Grafikkarten mit ihrer maximalen Auflösung (Auflösung). Natürlich kommt es vor, dass identische Komponenten in mehreren PC eingebaut werden. |
|
Da alle drei Komponenten mit ihren Bezeichnungen erfasst werden, liegt Typinformation vor. Es handelt sich um eine 1:n-Beziehung zwischen den PC und Komponenten, woraus sich die Schlüssel ergeben. |
1:n-Beziehung und Muster Einzel/Typ. |
Gehäuse (#(BezGH, InvPC), Größe) |
|
Grafikkarten (#(BezGK, InvPC), Auflösung) |
|
Hauptplatinen (#(BezHP, InvPC), AnzProz) |
|
Festplatten |
|
Auch die Festplatten werden so beschrieben, dass sie eigene Relationen bilden und dass Einzel- und Typinformation vorhanden ist. |
|
Für jede Festplatte wird die Bezeichnung (BezPl), die Speicherkapazität (Größe) sowie die Zugriffsgeschwindigkeit (Zugriff) erfasst. Jede Festplatte erhält von der IT-Abteilung eine eindeutige Seriennummer (SerNrF), angelehnt an die des Festplattenherstellers und wird ausführlich getestet. Das Ergebnis, ein Qualitätskoeffizient (Qual), wird auch festgehalten. Es kommt durchaus vor, dass ein PC mehrere Festplatten hat, aber nicht umgekehrt. |
|
Es ergeben sich die entsprechenden Relationen. Hier soll zusätzlich der Frage nachgegangen werden, wie in einem solchen Fall - wenn also Einzel- und Typinformation vorliegt - die Verknüpfung mit dem restlichen Modell (hier PC) vorgenommen wird. Grundsätzlich ist beides möglich, allerdings ist die Verknüpfung mit Typinformation ungenau. Dabei würde nur erfasst, welcher Plattentyp in einem PC installiert ist. Wird dagegen mit Hilfe der Einzelinformation verknüpft, kann genau festgehalten werden, welche und wieviele Festplatten im PC sind. Deshalb wird hier dieseVorgehensweise gewählt. Da eine einzelne Festplatte nur in einem einzigen PC sein kann, handelt es sich um eine 1:n-Beziehung, die durch den Fremdschlüssel InvPC in FP-Einzeln ausgedrückt wird. |
Verknüpfung? |
FP-Einzeln (#SerNrF, Qual, BezPL, InvPC) |
|
FP-Typen (#BezPl, Größe, Zugriff) |
|
Komponenten |
|
Außerdem werden jeweils mit Hilfe einer Kurzbezeichnung (KBezSK) die im PC enthaltenen sonstigen Komponenten (W-LAN-Komponente, Kamera, usw.) festgehalten. Natürlich kommt eine bestimmte Komponente in mehreren PC vor. Außerdem hat ein PC typischerweise mehrere solcher "sonstigen Komponenten". |
|
Auch hier wird wieder auf Typebene modelliert, so dass sich die folgende Relation ergibt. |
|
SK (#(KBezSK, InvPC)) //SK : Sonstige Komponenten |
|
Nutzung |
|
Abschließend wird in der Spezifikation beschrieben, wie die Nutzung und Einrichtung datenbankmäßig modelliert wird. |
|
Für jeden ins Unternehmen gegebenen PC wird weiterhin festgehalten, wer ihn nutzt, erfasst über die Personalnummer (PersNr), Name, Vorname (VName) sowie Telefonnummer (Tel) und wann er dort eingerichtet wurde (DatEinr). Ein bestimmter PC wird immer von genau einem Angestellten genutzt, ein Angestellter kann bis zu zwei PC zugeordnet bekommen. |
|
Die Nutzer werden über die Personalnummer erfasst und durch einige weitere Attribute beschrieben, weshalb für sie eine Relation eingerichtet wird.. |
|
Nutzer (#PersNr, Name, VName, Tel) |
|
Bleibt die Einrichtung des PC. Angesichts der Festlegung der Min-/Max-Angaben wird das Attribut PersNr zu einem Bestandteil von PC. Auch das Datum der Einrichtung kann in diese Relation eingefügt werden, die sich damit wie folgt ergibt: |
|
PC (#InvPC, Proz, ArbSp, PersNr, DatEinr) |
|
Damit sind die Relationen des Datenmodells zusammengestellt. Auch die relationalen Verknüpfungen sind schon angelegt. |
|
Kardinalitäten und Min-/Max-Angaben |
|
Alle Kardinalitäten und Min-/Max-Angaben sind in der Abbildung unten eingetragen. Aufzupassen ist da bei den Angaben mit Relationen auf Typ-Ebene. Ein Wert „1“ bedeutet hier bei Geräten nur „ein Typ“, z.B. ein Bildschirmtyp (Eizo xyz). Konkret können da mehrere Geräte vorliegen. |
|
Normalformen |
|
Es wurde schon bei der Erstellung darauf geachtet, dass a) keine Mehrfacheinträge vorliegen und b) die in Abschnitt 4.7 beschriebene Idealform für Relationen realisiert ist: Ein Schlüssel und nur Attribute, die von ihm voll funktional abhängig sind. Deshalb ist die höchste Normalform erreicht. |
|
2.16.3 Lösung |
|
Textliche Fassung |
|
BS-Einzeln (#InvBS, BezBS, DatÜb) |
|
BS-Typen (#BezBS, Art, Zoll) |
|
EntwPC (#InvPC, EntwUmg) |
|
FP-Einzeln (#SerNrF, Qual, BezPL, InvPC) |
|
FP-Typen (#BezPl, Größe, Zugriff) |
|
Gehäuse (#(BezGH, InvPC), Größe) |
|
Grafikkarten (#(BezGK, InvPC), Auflösung) |
|
Hauptplatinen (#(BezHP, InvPC), AnzProz) |
|
Nutzer (#PersNr, Name, VName, Tel) |
|
OptLw (#BezLW, Geschw) //Typebene |
|
OptLw_PC (#(BezLW, InvPC), Anzahl) //Typebene |
|
PC (#InvPC, Proz, ArbSp, PersNr, DatEinr) |
|
PSInstall (#(InvPC, ProgSpr)) |
|
SK (#(KBezSK, InvPC)) //Sonstige Komponenten |
|
|
|
Grafische Fassung |
|
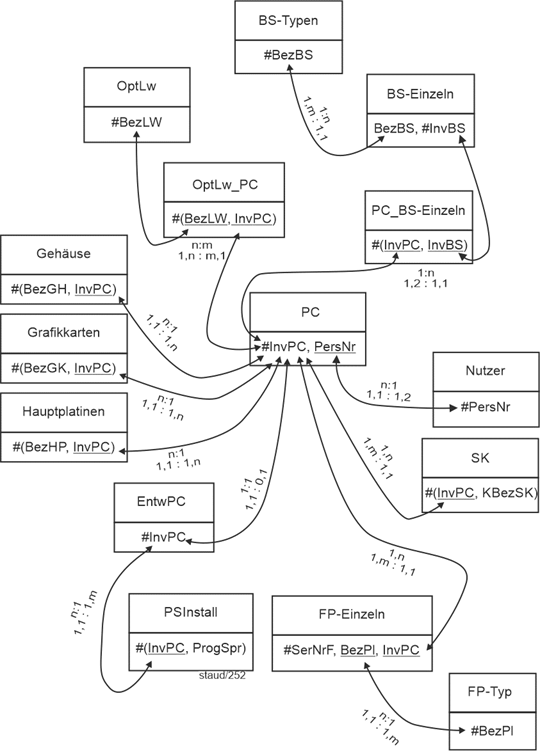
|
|
Abbildung 2.16-1: Datenmodell PC-Beschaffung |
|
|
|

|
|
|
|
Weitere Aufgaben zur Datenmodellierung sind im folgenden Kapitel. Dort werden sie allerdings bis zur Einrichtung der Datenbank weitergeführt. |
|
|
|
3 Relationale Datenbanken - Von der Anforderung zur Datenbank |
|
Zwei Schritte des Gesamtwegs:
Anforderungen – Datenmodell (Schema) – Datenbank – Web-Benutzeroberfläche |
|
Die Aufgaben dieses Kapitel beziehen sich auf die ersten beiden Schritte des Gesamtwegs, von der Anforderungsbeschreibung zum Datenmodell und weiter zur Datenbank. |
|
Für die SQL-Befehle wurde MySQL (Xampp Control Panel v3.2.4) genutzt. In anderen SQL-Dialekten sind zum Teil andere Bezeichnungen, Befehlsstrukturen, usw. realisiert. In diesem einführenden Kontext betrifft dies evtl. Bezeichnungen von Datentypen und die Gestaltung der verschiedenen JOIN-Varianten. |
|
Die Beispiele sind aus Kapazitäts- und Platzgründen einfach und klein gehalten, reichen aber aus, in die Methoden einzuführen und für größere Aufgaben vorzubereiten. |
|
Folgendes ist zu leisten: |
|
- Erstellung des Datenmodells.
- In einigen Fällen: Erstellen von FA-Diagrammen
- Erstellung der Datenbank
- Einfüllen von Daten
- Formulieren einiger Abfragen im jeweils angegebenen Umfang
|
|
|
|
3.1 Rechnungen/Kunden |
|
3.1.1 Anforderungsbeschreibung |
|
Es geht, stark vereinfacht, um die Verwaltung von Rechnungen von Kunden. Erfasst werden sollen die Rechnungen mit ihren Positionen und dem Rechnungsdatum (ReDatum). Außerdem die Artikel, die in den Rechnungspositionen auftauchen mit ihrer Anzahl. Für die Artikel werden eine Beschreibung, der Preis und der Standort der Ware im Lager erfasst. Für die Kunden werden Name, Vorname, Postleitzahl (PLZ), Ort, Straße und ein Festnetztelefonanschluss (FestTelefon) sowie ein Mobiltelefon (MobilTelefon) erfasst. Von einem Kunden werden maximal zwei Adressen in die Datenbank genommen. |
Vgl. Abschnitt 1.2 zur Typographie |
3.1.2 Lösungsschritte |
|
Relationen festlegen |
|
Sofort erkennbar als Relationen ("Identifikation + Beschreibung") sind Rechnungen, Artikel und Kunden. |
|
Für die Rechnungen wird eine Rechnungsnummer (ReNr) ergänzt und als Schlüsselattribut gewählt. Das Rechnungsdatum kommt hinzu (ReDatum). Bei den Positionen ergibt sich ein Problem. Wie wir wissen hat eine Rechnung typischerweise mehrere Positionen, auf denen die gekauften Artikel vermerkt sind – je einer pro Position. Also müssen die Positionen getrennt verwaltet werden. Wir teilen daher das Realweltphänomen Rechnung auf in Rechnungsköpfe (RechKöpfe) und Rechnungspositionen (RechPos). |
Rechnungen |
In die Relation RechKöpfe kommen erstmal die Attribute ReNr und ReDatum: |
RechKöpfe |
RechKöpfe(#ReNr, ReDatum) |
|
Für die Rechnungspositionen (RechPos) führen wir eine Positionsnummer ein (PosNr). Dieses Ergänzen von Attributen ist zulässig und auch immer wieder notwendig. Auch die Artikelnummer des Artikels (ArtNr), der auf der Position auftaucht (immer nur einer, normalerweise), wird hinzugefügt. Er wird Fremdschlüssel und leistet die Verknüpfung mit der später zu erstellenden Relation zu Artikeln (vgl. unten). Hinzugefügt wird noch die Anzahl der Artikel in der Position. Die Artikelbeschreibung wird deshalb nicht einfach bei den Positionen angeführt, weil (hoffentlich) derselbe Artikel auf mehreren Positionen auftaucht, was dann zu Redundanzen und zu einem Verstoß gegen die 3NF führen würde. |
|
Erinnerung: |
|
Schlüssel: identifizierendes Attribut bzw. identifizierende Attributskombination |
|
Schlüsselattribut: Attribut eines Schlüssels |
|
Nichtschlüsselattribut: die übrigen Attribute einer Relation |
|
Fremdschlüssel: ein Attribut, das der relationalen Verknüpfung dient. Es ist in „seiner“ Relation nicht Schlüssel, aber in der anderen zu verknüpfenden Relation. |
|
Mehr dazu in [Staud 2021, Abschnitt 8.2] |
|
Bleibt noch der unabdingbare Schlüssel. Die Positionsnummer kann es nicht sein, denn diese wiederholt sich über die Rechnungen hinweg. Nehmen wir allerdings die Rechnungsnummer dazu, entsteht Eindeutigkeit. Die Kombination aus ReNr und PosNr ergibt den zusammengesetzten Schlüssel. Das darin enthaltene Attribut ReNr ist Fremdschlüssel, es leistet die Verknüpfung mit der Relation RechKöpfe: |
|
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
RechPos |
Anmerkungen: |
|
- Auf die Positionsnummer könnte verzichtet werden. Dann wird hier stattdessen die Artikelnummer gewählt. |
|
- Schlüssel sind unabdingbar. Wenn sie in den Anforderungen vergessen werden, sind sie zu ergänzen. |
|
Die Beziehung zwischen Rechungsköpfen und -positionen hat die Kardinalitä 1:n und die Min-/Max-Angaben 1,n : 1,1. Es liegt also Existenzabhängigkeit (eine Komposition) vor. Mehr dazu unten. |
|
Für die Kunden führen wir als Schlüssel eine Kundennummer ein (KuNr). Wir fügen Name und Vorname hinzu und ebenfalls den Mobilanschluss, denn dieser ist personenspezifisch, d.h. diese Information ist funktional abhängig vom Kunden, nicht von seiner Adresse. Damit ergibt sich: |
Kunden |
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
Normalerweise würden wir hier die Adressattribute ergänzen. Da es aber nach der Anforderungsbeschreibung mehr als eine Adresse je Kunde geben kann, müssen die Adressangaben in einer eigenen Relation verwaltet werden (keine Mehrfacheinträge!). Wir legen wieder einen Schlüssel fest, eine Adressnummer (AdrNr): |
Adressen |
Adressen (#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
FestTelefon wurde zu den Adressen genommen, weil ein Festnetztelefon ortsspezifisch ist, d.h., dieses Attribut ist funktional abhängig von den Adressen. |
|
Als letztes sind noch die Artikel zu klären. Für sie werden in der Beschreibung eine Beschreibung, der Preis und der Standort der Ware im Lager (Standort) verlangt. Wir ergänzen noch den oben schon angelegten Schlüssel, Artikelnummer (ArtNr), und erhalten damit: |
Artikel |
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
Insgesamt liegen damit folgende Relationen vor: |
|
Adressen (#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
RechKöpfe(#ReNr, ReDatum … |
|
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Restliche Verknüpfungen |
|
Eine wichtige relationale Verknüpfung wurde oben schon eingefügt, die Komposition zwischen Rechnungsköpfen und -positionen. Denn es gilt: Eine Rechnung hat mindestens eine Position und eine Position gehört zu genau einer Rechnung. Es liegt also eine 1 :n-Beziehung zwischen Rechnungsköpfen und Rechnungspositionen vor. Der oben angelegte zusammengesetzte Schlüssel (ReNr, PosNr) drückt diese Existenzabhängigkeit aus, da durch den zusammengesetzten Schlüssel festgelegt wird, dass jede Rechnungsposition auch zu einem Rechnungskopf gehören muss (Komposition). |
Komposition |
Verknüpfungen sind oft nicht explizit in den Anforderungsbeschreibungen enthalten, sondern müssen aus der Semantik des Anwendungsbereichs oder von der Methodik abgeleitet werden. Hier z.B. für die Verknüpfung von Rechnungen und Kunden. Für diese gilt folgende Semantik: Jede Rechnung gehört zu genau einem Kunden. Ein Kunde kann mehrere Rechnungen haben. Eine solche 1:n-Verknüpfung zwischen Kunden und Rechnungen wird mit den Min-/Max-Angaben 0,n : 1,1 oder 1,n : 1,1 so umgesetzt: Die Kundennummer (KuNr) wird der Relation Rechnungsköpfe als Fremdschlüssel hinzugefügt: |
Rechnungen und Kunden |
RechKöpfe(#ReNr, KuNr, ReDatum) |
|
Die Verknüpfung zwischen den Artikeln und Rechnungspositionen beruht ebenfalls auf einer 1:n-Verknüpfung: auf einer Rechnungsposition ist genau ein Artikel, ein Artikel kann auf mehreren Positionen auftreten. Die Min-/Max-Angaben (Artikel/Rechnungspositionen) sind entsprechend 0,n : 1,1. Dies wurde bereits oben durch Einfügen der Artikelnummer (ArtNr) in die Relation RechPos realisiert. ArtNr ist dort Fremdschlüssel. |
Artikel und Rechnungs-positionen |
RechPos (#(ReNr, PosNr), ArtNr, Anzahl) |
|
Bleibt noch die Verbindung von Kunden und Adressen. Hier wird in der Anforderungsbeschreibung ausgeführt, dass jeder Kunde in der Datenbank zwei Adressen haben kann. Z.B. eine Liefer- und eine Rechnungsadresse. Dies wäre eine 1:n-Beziehung. Da wir aber gleich noch berücksichtigen, dass unter einer Adresse mehrere Kunden wohnen können, wird diese Beziehung zu einer n:m-Beziehung und bedarf einer eigenen Relation, einer Verbindungsrelation. Wenn wir festlegen, dass ein Kunde nur angelegt wird, wenn mindestens eine Adresse vorliegt und eine Adresse nur, wenn sie tatsächlich zu einem Kunden gehört, sind die Min-/Max-Angaben (Kunden/Adressen) 1,2 : 1,m. |
Kunden und Adressen |
Dies führt zu einer Relation Kundenadressen (KuAdr). Sie hat den zusammengesetzten Schlüssel aus Adressnummer und Kundenummer : |
|
KuAdr (#(AdrNr, KuNr)) |
|
Restliche Prüfung |
|
Die gefundenen Relationen sind in der jeweils letzten Fassung vollständig. Es müssen keine weiteren Attribute ergänzt werden, wir können die Relationenbeschreibungen schließen. |
|
Sie sind auch alle bereits in der höchsten Normalform: Es gibt einen Schlüssel und weitere Attribute, die nur von diesem vollumfänglich funktional abhängig sind (BCNF). Probleme mit der 4NF und 5NF gibt es augenscheinlich nicht. Vgl. auch die FA-Diagramme unten. |
|
3.1.3 Lösung |
|
Damit ergibt sich folgendes Datenmodell. |
|
Textliche Notation |
|
Adressen(#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
KuAdr (#(AdrNr, KuNr)) |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
RechKöpfe(#ReNr, ReDatum, KuNr) |
|
RechPos(#(PosNr, ReNr), ArtNr, Anzahl) |
|
Grafische Notation |
|
Die Frage, ob wirklich alle Verknüpfungen umgesetzt wurden, beantwortet sehr anschaulich die grafische Ausprägung des Datenmodells. |
|
|
|
Abbildung 3.1-1: Relationales Datenmodell Rechnungen/Kunden |
|
3.1.4 FA - Diagramme |
|
Eine Einführung in FA-Diagramme findet sich in [Staud 2021, Kapitel 8] und http://www.staud.info/rm1/rm_t_1.htm#Kapitel9 |
|
Oftmals ist die Betrachtung der funktionalen Abhängigkeiten der Relationen von großem Nutzen. Sie zeigen insbesondere auf, ob wirklich die höchste Normalform bei den Relationen erreicht wurde. |
|
Aufgabe |
|
Erstellen Sie für alle Relationen des Datenmodells ein FA-Diagramm. |
|
Lösung |
|
|
|
Abbildung 3.1-2: FA-Diagramme der Relationen zum Datenmodell Rechnungen/Kunden. |
|
Die FA-Diagramme zeigen, dass tatsächlich alle Relationen in der höchsten Normalform sind. |
|
3.1.5 Umsetzung mit mySQL |
|
Aufgabe |
|
- Erstellen Sie zu diesem Datenmodell die Datenbank mit SQL-Befehlen.
- Füllen Sie Demo-Daten ein, in denen die Verknüpfungen sichtbar werden.
- Führen Sie dann Auswertungen aus, auch über die relationalen Verknüpfungen.
|
|
Lösung |
|
Datenbank und Relationen einrichten |
|
Die Datenbank soll ReKu (Rechnungen/Kunden) genannt werden. Umlaute werden umgewandelt. Einige Attributsbezeichnungen wurden gekürzt. |
|
Aufpassen: Reihenfolge beachten. Bei Verknüpfungen zuerst die Relation mit dem Schlüssel, dann die mit dem Fremdschlüssel. |
|
Der folgende Befehl legt die Datenbank an: |
|
|
create database reku default character set latin1 collate latin1_german1_ci;
|
|
Nun die Relationen: |
|
Relation Kunden |
|
Kunden(#KuNr, Name, Vorname, MobilTelefon) |
|
|
create table kunden (KuNr smallint(5), name char(10), vorname char(10), mobil char(12), primary key (KuNr));
|
|
Anzeige der Struktur der Relation |
|
Die untenstehende Abbildung zeigt einen Teil der Tabelle, die mySQL zur Struktur der Relation ausgibt. Das Schlüsselsymbol in gelb (farbig nur in der Web-Version, nicht in den Print-Versionen) gibt einen Primärschlüssel an. Für diesen wird hier standardmäßig die BTREE-Architektur verwendet. |
|
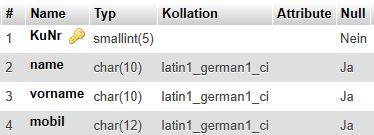
|
|

|
|
Relation Artikel |
|
Artikel (#ArtNr, Beschreibung, Preis, Standort) |
|
|
create table artikel (ArtNr smallint(4), beschreibung varchar(10), preis decimal(7,2), standort char(5), primary key (ArtNr));
|
|
Anzeige der Relationenstruktur |
|
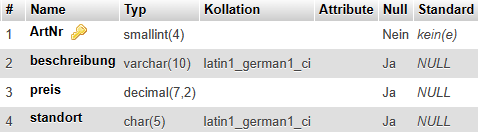
|
|

|
|
Relation Adressen |
|
Adressen(#AdrNr, PLZ, Ort, Straße, FestTelefon) |
|
|
create table adressen (AdrNr smallint(7), plz char(5), ort char(10), strasse char(10), FestTelefon char(15), primary key (adrnr));
|
|
Anzeige der Relationenstruktur |
|
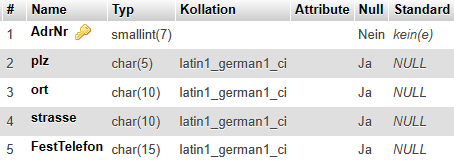
|
|

|
|
Relation RechKoepfe |
|
RechKöpfe(#ReNr, ReDatum, KuNr) |
|
|
create table RechKoepfe (ReNr smallint(6), KuNr smallint(5), primary key (ReNr), ReDatum date, foreign key (KuNr) references kunden(KuNr))
|
|
Anzeige der Relationenstruktur |
|

|
|

|
|
Relation RechPos |
RechPos |
RechPos(#(PosNr, ReNr), ArtNr, Anzahl) |
|
|
create table RechPos (ReNr smallint(6), PosNr tinyint(3) unsigned, ArtNr smallint(4), anzahl smallint(2),
|
|
|
primary key (ReNr, PosNr),
|
|
|
foreign key (ArtNr) references artikel(ArtNR),
|
|
|
foreign key (ReNr) references RechKoepfe(ReNr));
|
|
Anzeige der Relationenstruktur |
|
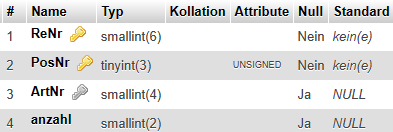
|
|

|
|
Relation KuAdr |
KuAdr |
KuAdr (#(AdrNr, KuNr)) |
|
|
create table KuAdr (AdrNr smallint(7), KuNr smallint(5),
|
|
|
primary key (adrnr, kunr),
|
|
|
foreign key (kunr) references kunden(kunr),
|
|
|
foreign key (adrnr) references adressen(adrnr));
|
|
Anzeige der Relationenstruktur |
|

|
|

|
|
|
|
3.1.6 Einfüllen von Daten |
|
[Falls wegen Fehlern Wiederholung nötig ist, vorab: delete from kunden;] |
|
Relation Kunden |
|
|
insert into kunden (KuNr, Name, Vorname) values (1007, 'Aberer', 'Anton');
|
|
|
insert into kunden (KuNr, Name, Vorname) values (1008, 'Blauer', 'Guiseppe');
|
|
|
insert into kunden (KuNr, Name, Vorname) values (1009, 'Cäser', 'Filippa');
|
|
|
insert into kunden values (1010, 'Dodolo', 'Rita', '1234567890');
|
|
|
insert into kunden values (1011, 'Steiner', 'Sepp', '2345678901');
|
|
|
select * from kunden;
|
|
| #KuNr |
name |
vorname |
mobil |
| 1007 |
Aberer |
Anton |
NULL |
| 1008 |
Blauer |
Guiseppe |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
| 1010 |
Dodolo |
Rita |
1234567890 |
| 1011 |
Steiner |
Sepp |
2345678901 |
| |
Relation Adressen
|
|
|
Insert into adressen (AdrNr, plz, ort) values (1001, '88333', 'Waldhausen');
|
|
|
Insert into adressen (AdrNr, plz, ort, strasse) values (1011, '99333', 'Buchen', 'Am Baum 7');
|
|
|
Insert into adressen values (2011, '11111', 'Karlstadt', 'Hauptstr. 77', '111-2222');
|
|
|
Select * from adressen;
|
|
| #AdrNr |
plz |
ort |
strasse |
FestTelefon |
| 1001 |
88333 |
Waldhausen |
NULL |
NULL |
| 1011 |
99333 |
Buchen |
Am Baum 7 |
NULL |
| 2011 |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| |
Relation KuAdr
|
|
|
insert into KuAdr values (1001, 1007);
|
|
|
insert into KuAdr values (2011, 1007);
|
|
|
insert into KuAdr values (1001, 1008);
|
|
|
insert into KuAdr values (1011, 1009);
|
|
|
insert into KuAdr values (2011, 1010);
|
|
|
select * from KuAdr;
|
|
| AdrNr |
KuNr |
| 1001 |
1007 |
| 1001 |
1008 |
| 1011 |
1009 |
| 2011 |
1010 |
| 2011 |
1010 |
| |
#(AdrNr, KuNr) |
|
Auch die Verknüpfung von kunden und adressen über kuadr klappt: |
|
|
select k.kunr, k.name, k.vorname, k.mobil, a.adrnr, a.plz, a.ort, a.strasse
|
|
|
from kunden k, adressen a, kuadr v
|
|
|
where k.kunr=v.kunr and a.adrnr=v.adrnr;
|
|
| kunr |
name |
vorname |
mobil |
adrnr |
plz |
ort |
strasse |
| 1007 |
Aberer |
Anton |
NULL |
1001 |
88333 |
Waldhausen |
NULL |
| 1008 |
Blauer |
Guiseppe |
NULL |
1001 |
88333 |
Waldhausen |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
1011 |
99333 |
Buchen |
Am Baum 7 |
| 1007 |
Aberer |
Anton |
NULL |
2011 |
11111 |
Karlstadt |
Hauptstr. |
| 1010 |
Dodolo |
Rita |
1234567890 |
2011 |
11111 |
Karlstadt |
Hauptstr. |
| |
Relation Artikel
|
|
|
insert into artikel values (100, 'Gamer-PC', 2500.00, 'ST007');
|
|
|
insert into artikel values (101, 'Büro-PC', 1200.00, 'ST018');
|
|
|
insert into artikel values (102, 'Entwickler-PC', 3200.00, 'ST100');
|
|
|
select * from artikel;
|
|
| #ArtNr |
beschreibung |
preis |
standort |
| 100 |
Gamer-PC |
2500.00 |
ST007 |
| 101 |
Büro-PC |
1200.00 |
ST018 |
| 102 |
Entwickler |
3200.00 |
ST100 |
| |
Relation RechKoepfe
|
|
|
insert into rechkoepfe values (23001, 1007, '2023-03-27');
|
|
|
insert into rechkoepfe values (23010, 1009, '2023-05-20');
|
|
|
select * from rechkoepfe;
|
|
| #ReNr |
KuNr |
ReDatum |
| 23001 |
1007 |
2023-03-27 |
| 23010 |
1009 |
2023-05-20 |
| |
Relation RechPos
|
|
|
insert into rechpos values (23001, 1, 100, 1);
|
|
|
insert into rechpos values (23001, 2, 101, 2);
|
|
|
insert into rechpos values (23001, 3, 100, 1);
|
|
|
insert into rechpos values (23010, 1, 101, 3);
|
|
|
insert into rechpos values (23010, 2, 102, 1);
|
|
|
Select * from rechpos;
|
|
| ReNr |
PosNr |
ArtNr |
anzahl |
| 23001 |
1 |
100 |
1 |
| 23001 |
2 |
101 |
2 |
| 23001 |
3 |
100 |
1 |
| 23010 |
1 |
101 |
3 |
| 23010 |
2 |
102 |
1 |
| |
#(ReNr, PosNr) |
|
|
|
|
3.1.7 Abfragen |
|
Aufgabe |
|
Gib alle Rechnungen mit rechnungsrelevanten Daten aus. Ohne doppelte Attribute wg. Schlüssel/Fremdschlüssel. Die Sortierung soll aufsteigend nach Rechnungsnummer und Positionsnummer erfolgen. |
|
Lösung |
|
|
select rk.renr as ReNr, rk.kunr as KuNr, rk.redatum as ReDatum,
|
|
|
rp.posnr as Position, rp.artnr as ArtNr, rp.anzahl as Anzahl,
|
|
|
a.beschreibung as Beschreibung, a.preis as Preis
|
|
|
from rechkoepfe rk, rechpos rp, artikel a
|
|
|
where rk.renr=rp.renr and rp.artnr=a.artnr
|
|
|
order by rk.renr, rp.posnr;
|
|
|
|
|
| ReNr |
KuNr |
ReDatum |
Position |
ArtNr |
Anzahl |
Beschreibung |
Preis |
| 23001 |
1007 |
2023-03-27 |
1 |
100 |
1 |
Gamer-PC |
2500.00 |
| 23001 |
1007 |
2023-03-27 |
2 |
101 |
2 |
Büro-PC |
1200.00 |
| 23001 |
1007 |
2023-03-27 |
3 |
100 |
1 |
Gamer-PC |
2500.00 |
| 23010 |
1009 |
2023-05-20 |
1 |
101 |
3 |
Büro-PC |
1200.00 |
| 23010 |
1009 |
2023-05-20 |
2 |
102 |
1 |
Entwickler |
3200.00 |
| |
Aufgabe
|
|
Erstelle eine Liste aller Kunden mit ihren Adressen ohne doppelte Attribute. Ohne doppelte Attribute wg. Schlüssel/Fremdschlüssel. |
|
Lösung |
|
|
select k.kunr as KuNr, k.name as Name, k.vorname as Vorname,
|
|
|
k.mobil as MobilTel, a.plz as PLZ, a.ort as Ort, a.strasse as
|
|
|
Straße,a.festtelefon as Festnetz
|
|
|
from kunden k, adressen a, kuadr ka
|
|
|
where k.kunr=ka.kunr and ka.adrnr=a.adrnr;
|
|
|
|
|
| KuNr |
Name |
Vorname |
MobilTel |
PLZ |
Ort |
Straße |
Festnetz |
| 1007 |
Aberer |
Anton |
NULL |
88333 |
Waldhausen |
NULL |
NULL |
| 1008 |
Blauer |
Guiseppe |
NULL |
88333 |
Waldhausen |
NULL |
NULL |
| 1009 |
Cäser |
Filippa |
NULL |
99333 |
Buchen |
Am Baum 7 |
NULL |
| 1007 |
Aberer |
Anton |
NULL |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| 1010 |
Dodolo |
Rita |
1234567890 |
11111 |
Karlstadt |
Hauptstr. |
111-2222 |
| |
3.2 Haushaltsgeräte |
|
Auch bei dieser Aufgabe soll nicht nur das relationale Datenmodell erstellt werden, sondern auch die Datenbank selbst mit mySQL. Anschließend soll eine der n:m-Beziehungen mit Daten befüllt werden. Diese soll mit SQL abgefragt werden, zuerst in einfacher Form, dann mit sortierten Attributen, Spaltenüberschriften, Vermeidung doppelter Spalten und Sortierung. |
|
3.2.1 Anforderungsbeschreibung |
|
Es geht um Haushaltsgeräte in einem Einzelhandelsgeschäft (vereinfacht), die in einer Datenbank erfasst werden sollen. |
|
Für jedes Haushaltsgerät wird die Bezeichnung (Bez) erfasst, z.B. Staubsauger XYZ. Außerdem der Hersteller (Hersteller), der Listenpreis (LPreis) und die Anzahl der Geräte im Lager (AnzLager). Jedes einzelne Gerät erhält eine Gerätenummer (GNr) und es wird festgehalten, wann es hergestellt wurde (MonatHerst; Monat Herstellung) und wann es ins Lager kam (LagAufn). |
|
Für Staubsauger wird zusätzlich festgehalten, welche Saugkraft sie haben und von welchem Typ sie sind (mit Beutel, ohne, …). Für Kaffemaschinen, welche Wassermenge sie maximal verarbeiten können (MengeWasser) und in welcher Zeit sie einen halben Liter Kaffee kochen (Geschw). |
|
Von den Kunden werden Name und Vorname (VName) erfasst und sie erhalten eine Kundennummer (KuNr). Jeder Kunde kann beliebig viele Adressen (PLZ, Ort, Straße) besitzen. Die Erfahrung hat gezeigt, dass unter einer Adresse u.U. mehrere Kunden wohnen (Mehrfamilienhaus, Studierendenwohnheim, …), dies soll datenbanktechnisch festgehalten werden. |
|
Kunden haben inzwischen oft mehrere Telefone (Festnetz und mobil). Diese werden alle erfasst. Es kommt vor, dass unter einer Telefonnummer mehrere Kunden zu erreichen sind (z.B. bei einer Familie). |
|
Beim Verkauf eines Gerätes wird festgehalten, an welchen Kunden das Gerät verkauft wurde. Außerdem das Datum und der tatsächlich erzielte Preis (ErzPreis). Dieser weicht oft vom Listenpreis ab, weil z.B. Nachlässe gegeben werden. |
|
3.2.2 Lösungsschritte |
|
Die Haushaltsgeräte (HG) sind gleich als Relation erkennbar. Sie werden durch die Gerätenummer (GNr) identifiziert und durch zahlreiche weitere Attribute beschrieben: |
|
HG (#GNr, Bez, Hersteller, LPreis, AnzLager, MonatHerst, LagAufn, … |
|
Ein wenig Unbehagen erzeugt diese Relation allerdings. Werden hier nicht Informationen mehrfach erfasst? Z.B. der Hersteller und der Listenpreis für alle identischen Geräte? Genauso ist es und etwas Erinnerung an die Theorie führt zu dem Ergebnis, dass hier ein Muster Einzel/Typ vorliegt. Hier Einzelgeräte vs. Gerätetypen. Bei Tieren z.B. das einzelne Tier und die jeweilige Gattung. Ein wichtiges Muster unserer Realwelt, das beim Modellieren oft übersehen wird. Vgl. [Staud 2021, Abschnitt 14.2]. Obige Relation würde also viele Redundanzen aufweisen. Die Lösung besteht darin, zwei Relationen anzulegen, HG-Einzeln und HG-Typen. |
Hausgeräte (HG) |
Beginnen wir mit HG-Einzeln. Die einzelnen Geräte werden durch die Gerätenummer (GNr) identifiziert und als Einzelgeräte durch den Monat der Herstellung (MonatHerst) und die Lageraufnahme (LagAufn) beschrieben: |
Muster Einzel/Typ |
HG-Einzeln (#GNr, MonatHerst, LagAufn) |
|
Die Geräte als Typen erhalten Bez als Schlüssel und die Attribute Hersteller, LPreis und AnzLager als beschreibende Attribute: |
|
HG-Typen (#Bez, Hersteller, LPreis, AnzLager) |
|
Bleibt noch die Verknüpfung dieser Einzel- und Gerätetyp-Informationen. Diese erfolgt wie meist durch Schlüssel/Fremdschlüssel. Beim Muster Einzel/Typ ist es immer so, dass bei der Einzelinformation der Schlüssel der zugehörigen Typinformation eingefügt wird: |
|
HG-Einzeln (#GNr, MonatHerst, LagAufn, Bez) |
|
Umgekehrt wäre es nicht möglich, da dies zu Mehrfacheinträgen führen würde. Die Kardinalität ist (von HG-Einzeln ausgehend) n:1, die Min-/Max-Angaben sind 1,1 : 0,n: |
|
- Jedes individuelle Hausgerät gehört zu genau einem Gerätetyp
- Zu einem Gerätetyp gehören mehrere Einzelgeräte oder auch keines mehr, nach dem Verkauf des Letzten.
|
|
In der Anforderungsbeschreibung werden dann Staubsauger und Kaffeemaschinen angeführt. Sie sind auch Geräte, erhalten aber zusätzliche Attribute: Staubsauger Saugkraft und Typ, Kaffemaschinen MengeWasser und Geschw. Damit liegt eine Generalisierung / Spezialisierung vor. Vgl. oben sowie [Staud 2021, Abschnitt 14.1]. |
|
In beiden Fällen sind die Attribute auf Typebene: alle einzelnen Kaffeemaschinen haben das Attribut MengeWasser, usw. Insofern gehören sie zur Relation HG-Typen. Ergänzen wir nun aber einfach die Relation HG-Typen um diese Attribute, gibt es das Problem, dass bestimmte Attribute nicht für alle Objekte Gültigkeit haben. Staubsauger haben z.B. nicht die Attribute von Kaffemaschinen, Kühlgeräte weder die von Staubsaugern noch von Kaffeemaschinen, usw. Es gibt also semantische bedingte Leereinträge, die in Datenbeständen absolut unerwünscht sind (vgl. [Staud 2021, S. 180ff]). Die Ursache liegt in der hier vorliegenden Generalisierung / Spezialisierung (Gen/Spez). Diese verlangt für eine korrekte Modellierung, dass die Spezialisierungen (hier: Staubsauger und Kaffeemaschinen) in eigenen Relationen erfasst und mit der Generalisierung (hier: HG-Typen) verknüpft werden. |
GenSpez |
Es entstehen also eigene Relationen für Staubsauger und Kaffeemaschinen, mit dem Schlüssel von HG-Typen: |
HG |
Staubsauger (#Bez, Saugkraft, Typ) |
|
Kaffeemaschinen (#Bez, MengeWasser, Geschw) |
|
Die Schlüssel der Spezialisierungen sind also gleich dem Schlüssel der Generalisierung. Allerdings sind die Schlüsselmengen der Spezialisierungen Teilmengen der Schlüsselmenge der Generalisierung. Es handelt sich um eine Beziehung mit der Kardinalität 1:1 und den Min-/Max-Angaben 0,1 : 1,1 (von der Generalisierung ausgehend). |
|
Auch die Kunden erfüllen die Kriterien für eine Relation. Der Schlüssel ist KuNr, die Attribute sind Name und Vorname. |
Kunden |
Kunden (#KuNr, Name, Vorname) |
|
Wo kommen die Adressinformationen hin? Gäbe es nur eine Adresse, kämen sie einfach in die Kundendatei. Die Möglichkeit mehrerer Adressen je Kunde führt aber zu einer eigenen Relation Adressen mit den Attributen PLZ, Ort, Straße. Da es ohne Schlüssel nicht geht und in der Anforderung keiner spezifiziert ist, legen wir einen fest: AdrNr (Adressnummer): |
Adressen |
Adressen (#AdrNr, PLZ, Ort, Straße) |
|
In der Beschreibung wird ausgeführt, dass Kunden mehrere Telefonanschlüsse haben können. Dafür muss dann eine eigene Relation Telefone angelegt werden. Für diese steht beschreibend nur die Telefonnummer zur Verfügung (Tel). Da zu einem Anschluss mehrere Kunden gehören, liegt eine n:m-Beziehung zwischen Kunden und Telefonen vor. Die MinMax-Angaben sind 0,n : 1,m. Wir lassen also auch zu, dass es in unserer Datenbank Kunden ohne angegebene Telefonnummer gibt. Dies alles erfordert einen zusammengesetzten Schlüssel in Telefone und KuNr als Fremdschlüssel : |
Telefonanschlüsse mit 1:n |
Telefone (#(Tel, KuNr)) |
|
Die bei einer Verbindungsrelation normalerweise folgende dritte Relation (hier zu Telefonanschlüssen) ist mangels beschreibender Attribute für Telefonanschlüsse hier nicht nötig. Wäre aber möglich, z.B. bezüglich Anschlussart, Geschäftstelefon, privater Anschluss, Erreichbarkeit des Anschlusses. |
|
Die Erfassung der Verkäufe gestaltet sich etwas anspruchsvoller. In der Beschreibung ist angedeutet, dass Einzelgeräte erfasst werden sollen, nicht die Bezeichnung der Typ-Ebene. Da wäre modelltechnisch eine Ergänzung der Relation HG-Einzeln durch ein Attribut KuNr als Fremdschlüssel denkbar: |
Verkäufe |
HG-Einzeln (#GNr, KuNr, Bez, … //falsche Lösung |
|
Dies entspricht einer 1:n-Beziehung zwischen KUNDEN und HG-Einzeln. Überdenkt man die damit ausgedrückte Semantik, wird aber klar, dass dies nicht möglich ist. In HG-Einzeln werden alle Geräte erfasst, die auf Lager genommen werden. In die Verkäufe kommen nur die verkauften Geräte, also eine Teilmenge. Will man entsprechend der relationalen Theorie semantisch bedingte Leereinträge (hier bei KuNr) vermeiden, ist eine Relation Verkäufe mit dem Schlüssel/Fremdschlüssel #GNr und dem Fremdschlüssel KuNr die richtige Lösung: |
|
Verkäufe (#GNr, KuNr, Datum, ErzPreis) //richtige Lösung |
|
Hier ist nun jedem tatsächlich verkauften Gerät ein Kunde zugeordnet mit einer 1:n-Beziehung zwischen Kunden und Geräten. |
|
Die Min-/Max-Angaben sind (von den Kunden ausgehend) 0,n : 0,1. Es kann also Kunden geben, die noch nicht gekauft haben und es gibt natürlich Geräte, die noch nicht verkauft sind. Auch hier gilt wieder, dass dies auch anders festgelegt werden kann. |
|
Die Beziehung zwischen Kunden und Adressen ist noch nicht erfasst. Hier wurde in der Anforderung darauf hingewiesen, dass nicht nur ein Kunde mehrere Adressen haben kann, sondern dass unter einer Adresse auch mehrere Kunden wohnen können. Eine solche Situation erfordert eine n:m-Beziehung, die zu einer Verbindungsrelation KuAdr führt: |
Adressen |
KuAdr (#(KuNr, AdrNr)) |
|
Die Min-/Max-Angaben können wir festlegen. Da es in der Datenbank keine Kunden ohne Adressen und keine Adressen ohne Kunden geben soll (beides wäre auch möglich!), ergeben sich die Min-/Max-Angaben 1,n : 1,m. |
|
Damit ist die Modellierung abgeschlossen. Die Relationen sind in der höchsten Normalform: Die BCNF ist erfüllt und es liegen keine Verstöße gegen die 4NF und 5NF vor. Die auftretenden Muster (Gen/Spez und Einzel/Typ) wurden eingearbeitet. Zeitliche Informationen liegen, bis auf das Verkaufsdatum, nicht vor. |
|
3.2.3 Lösung |
|
Textliche Fassung |
|
HG-Einzeln (#GNr, MonatHerst, LagAufn, Bez) |
|
HG-Typen (#Bez, Hersteller, LPreis, AnzLager) |
|
Staubsauger (#Bez, Saugkraft, Typ) |
|
Kaffeemaschinen (#Bez, MengeWasser, Geschw) |
|
Kunden (#KuNr, Name, Vorname) |
|
Adressen (#KuNr, PLZ, Ort, Straße) |
|
KuAdr (#(KuNr, AdrNr)) |
|
Telefone (#(Tel, KuNr)) |
|
Verkäufe (#GNr, KuNr, Datum, ErzPreis) |
|
|
|
Grafische Fassung |
|
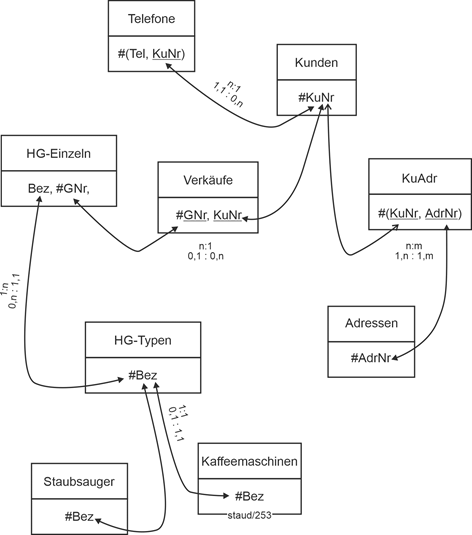
|
|
Abbildung 3.2-1: Relationales Datenodell Haushaltsgeräte |
|
3.2.4 Datenbank erstellen |
|
Zuerst muss die Datenbank angelegt werden. Dies geschieht mit folgendem Befehl: |
|
|
create database HG default character set latin1 collate latin1_german1_ci;
|
|
Dann werden die Relationen angelegt. Dabei muss eine Reihenfolge beachtet werden: Eine Relation mit Fremdschlüssel kann nur eingerichtet werden, wenn die Relation mit dem zugehörigen Schlüssel vorhanden ist. |
|
HG-Typen (#Bez, Hersteller, LPreis, AnzLager) |
|
|
create table hgt (Bez varchar(7), Hersteller varchar(2), LPreis decimal(7,2), AnzLager smallint(3), primary key (bez));
|
|
HG-Einzeln (#GNr, MonatHerst, LagAufn, Bez) |
|
|
create table hge (GNr int(5), MonatHerst date, LagAufn date, bez varchar(7) references hgt (bez), primary key (GNr));
|
|
Kaffeemaschinen (#Bez, MengeWasser, Geschw) |
|
|
create table kaffee (bez varchar(7), wasser decimal(4,1), geschw smallint(3), primary key (bez));
|
|
Staubsauger (#Bez, Saugkraft, Typ) |
|
|
create table staubsauger (bez varchar(7), saug int (4), typ varchar(10), primary key (bez));
|
|
Adressen (#KuNr, PLZ, Ort, Straße) |
|
|
create table adressen (AdrNr int(6), plz varchar(5), ort varchar(10), strasse varchar(10), primary key (adrnr));
|
|
Kunden (#KuNr, Name, Vorname) |
|
|
create table kunden (KNr int(6), name varchar(10), vname varchar(10), primary key (KNr));
|
|
KuAdr (#(KuNr, AdrNr)) |
|
|
create table KuAdr (KNr int(6), AdrNr int(6), primary key (KNr, AdrNr), foreign key (KNr) references kunden(knr), foreign key (adrnr) references adressen(adrnr));
|
|
Verkäufe (#GNr, KuNr, Datum, ErzPreis) |
|
|
create table verkaeufe (GNr int(5), KNr int(6) references kunden(knr), Datum date, ErzPreis decimal (6,2), primary key (GNr));
|
|
Telefone (#(Tel, KuNr)) |
|
|
create table telefone (Tel varchar(10), KNr int(6), primary key (Tel, KNr), foreign key (KNr) references kunden(knr));
|
|
Alternativ, mit Benennung des Fremdschlüssels: |
|
|
create table telefone2 (Tel varchar(10), KNr int(6), primary key (Tel, KNr), constraint fs_tel_ku foreign key (KNr) references kunden(knr));
|
|
Am Stück, für die Übernahme nach mySQL: |
|
create table hgt (Bez varchar(7), Hersteller varchar(2), LPreis decimal(7,2), AnzLager smallint(3), primary key (bez)); |
|
create table hge (GNr int(5), MonatHerst date, LagAufn date, bez varchar(7) references hgt (bez), primary key (GNr)); |
|
create table kaffee (bez varchar(7), wasser decimal(4,1), geschw smallint(3), primary key (bez)); |
|
create table staubsauger (bez varchar(7), saug int (4), typ varchar(10), primary key (bez)); |
|
create table adressen (AdrNr int(6), plz varchar(5), ort varchar(10), strasse varchar(10), primary key (adrnr)); |
|
create table kunden (KNr int(6), name varchar(10), vname varchar(10), primary key (KNr)); |
|
create table KuAdr (KNr int(6), AdrNr int(6), primary key (KNr, AdrNr), foreign key (KNr) references kunden(knr), foreign key (adrnr) references adressen(adrnr)); |
|
create table verkaeufe (GNr int(5), KNr int(6) references kunden(knr), Datum date, ErzPreis decimal (6,2), primary key (GNr)); |
|
create table telefone (Tel varchar(10), KNr int(6), primary key (Tel, KNr), foreign key (KNr) references kunden(knr)); |
|
3.2.5 Einfüllen von Daten |
|
Relation kunden |
|
|
insert into kunden (KNr, name, vname) values (1005, 'Na1', 'VN1');
|
|
|
insert into kunden values (1004, 'Na2', 'VN1');
|
|
|
insert into kunden values (1003, 'Na3', 'VN3'), (1002, 'Na4', 'VN4'), (1001, 'Na5', 'VN5');
|
|
|
SELECT * FROM kunden;
|
|
| KNr |
name |
vname |
| 1001 |
Na5 |
VN5 |
| 1002 |
Na4 |
VN4 |
| 1003 |
Na3 |
VN3 |
| 1004 |
Na2 |
VN1 |
| 1005 |
Na1 |
VN1 |
| |
|
|
Relation adressen |
|
|
Insert into adressen values
|
|
|
(123, '99999', 'Ort99', 'Str123'),
|
|
|
(234, '77777', 'Ort77', 'Str234'),
|
|
|
(789, '55555', 'Ort55', 'Str789'),
|
|
|
(678, '88888', 'Ort88', 'Str678'),
|
|
|
(567, '22222', 'Ort22', 'Str567');
|
|
|
SELECT * FROM adressen;
|
|
| AdrNr |
plz |
ort |
strasse |
| 123 |
99999 |
Ort99 |
Str123 |
| 234 |
77777 |
Ort77 |
Str234 |
| 567 |
22222 |
Ort22 |
Str567 |
| 678 |
88888 |
Ort88 |
Str678 |
| 789 |
55555 |
Ort55 |
Str789 |
| |
|
|
Relation kuadr (Kunden – Adressen) |
|
|
insert into kuadr values
|
|
|
(1001, 789),(1002, 234),(1003, 567),(1004, 123),(1005, 678),(1002, 789),(1005, 678),(1005, 789);
|
|
|
SELECT * FROM kuadr;
|
|
| KNr |
AdrNr |
| 1001 |
789 |
| 1002 |
234 |
| 1002 |
789 |
| 1003 |
567 |
| 1004 |
123 |
| 1005 |
567 |
| 1005 |
678 |
| 1005 |
789 |
| |
3.2.6 Abfragen |
|
Verknüpfung der drei Relationen kunden, adressen und kuadr, zuerst in einfachster Form. |
|
|
select * from kunden k, adressen a, kuadr ka where k.knr=ka.knr and a.adrnr=ka.adrnr;
|
|
| KNr |
name |
vname |
AdrNr |
plz |
ort |
strasse |
KNr |
AdrNr |
| 1001 |
Na5 |
VN5 |
789 |
55555 |
Ort55 |
Str789 |
1001 |
789 |
| 1002 |
Na4 |
VN4 |
234 |
77777 |
Ort77 |
Str234 |
1002 |
234 |
| 1002 |
Na4 |
VN4 |
789 |
55555 |
Ort55 |
Str789 |
1002 |
789 |
| 1003 |
Na3 |
VN3 |
567 |
22222 |
Ort22 |
Str567 |
1003 |
567 |
| 1004 |
Na2 |
VN1 |
123 |
99999 |
Ort99 |
Str123 |
1004 |
123 |
| 1005 |
Na1 |
VN1 |
567 |
22222 |
Ort22 |
Str567 |
1005 |
567 |
| 1005 |
Na1 |
VN1 |
678 |
88888 |
Ort88 |
Str678 |
1005 |
678 |
| 1005 |
Na1 |
VN1 |
789 |
55555 |
Ort55 |
Str789 |
1005 |
789 |
| |
|
|
|
Jetzt mit Vermeidung doppelter Spalten (Attribute), Spaltenüberschriften und Sortierung nach Postleitzahl und Kundennummer. Außerdem sollen die Ortsangaben in der Tabelle vor den Kundenangaben und die PLZ an erster Stelle stehen. |
|
|
select a.plz as PLZ, a.adrnr as AdressNr, a.ort as Ort, a.strasse as Strasse, k.knr as KundenNr, k.name as Name, k.vname as Vorname
|
|
|
from kunden k, adressen a, kuadr ka
|
|
|
where k.knr=ka.knr and a.adrnr=ka.adrnr order by a.plz, k.knr;
|
|
|
|
|
| PLZ |
AdressNr |
Ort |
Strasse |
KundenNr |
Name |
Vorname |
| 22222 |
567 |
Ort22 |
Str567 |
1003 |
Na3 |
VN3 |
| 22222 |
567 |
Ort22 |
Str567 |
1005 |
Na1 |
VN1 |
| 55555 |
789 |
Ort55 |
Str789 |
1001 |
Na5 |
VN5 |
| 55555 |
789 |
Ort55 |
Str789 |
1002 |
Na4 |
VN4 |
| 55555 |
789 |
Ort55 |
Str789 |
1005 |
Na1 |
VN1 |
| 77777 |
234 |
Ort77 |
Str234 |
1002 |
Na4 |
VN4 |
| 88888 |
678 |
Ort88 |
Str678 |
1005 |
Na1 |
VN1 |
| 99999 |
123 |
Ort99 |
Str123 |
1004 |
Na2 |
VN1 |
| |
3.3 Zoo |
|
3.3.1 Anforderungsbeschreibung |
|
|
(1) Für einen Zoo soll eine Datenbank rund um die vorhandenen Tiere erstellt werden. Dabei erfolgt eine Konzentration auf größere Tiere (Säugetiere, Reptilien, …). Allen diesen Tieren wird eine identifizierende Tiernummer (TNr), ihr Name (Name) und die Gattung, zu der sie gehören (Gattung: z.B. afrikanische Elefanten, Bengalen-Tiger, Schimpansen, Nil-Krokodile) zugewiesen. Außerdem wird ihr Geburtstag (GebTag), das Geschlecht und das Gebäude erfasst, in dem Sie gehalten werden. Für jede Gattung wird auch festgehalten, wieviele Tiere davon im Zoo vorhanden sind (z.B. 5 Afrikanische Elefanten oder 20 Schimpansen) (Anzahl). Wegen der Bedeutung der Information für die Gebäude und das Außengelände wird bei Elefanten noch zusätzlich das Gewicht und bei Giraffen die Größe erfasst, jeweils mit dem Datum, zu dem der Wert erhoben wurde.
|
|
|
(2) Auch die Rahmenbedingungen der Fütterung der Tiere werden festgehalten: Welches Futter (Futterbezeichnung; FuttBez) ein Tier bekommt (durchaus mehrere Futterarten, z.B. Heu und Frischkost) und welche Menge davon täglich (Menge). Wieviel Vorrat vorhanden ist und welche Mindestmenge immer vorrätig gehalten wird (MiMenge).
|
|
|
(3) Den Tieren sind Pfleger zugeordnet. Von diesen wird in der Datenbank die Personalnummer (PersNr), der Name und Vorname (VName) festgehalten. Es wird auch festgehalten, in welchem Zeitraum der Pfleger einem Tier zugeordnet ist (Erster Tag: Beginn; Letzter Tag: Ende). Öfters kommt es vor, dass ein Pfleger für einen bestimmten Zeitraum einem Tier zugeordnet ist, dann nicht mehr und später wieder, so dass es mehrere Pflegezeiträume eines Pflegers bei einem Tier geben kann.
|
|
|
(4) Für die einzelnen Gebäude des Zoos wird eine Gebäudenummer (GebNr), die Größe, der Typ (für Säugetiere, für Reptilien, usw.) und die Anzahl der Plätze (AnzPlätze) erfasst. Selbstverständlich wird auch festgehalten, welches Tier aktuell in welchem Gebäude ist.
|
|
|
(5) Für jedes Tier gibt es Tierakten, die digital geführt werden. Eine wird bei der Geburt angelegt, eine beim Weggang bzw. Sterben des Tieres. Dazwischen entstehen digitale Akten bei besonderen Anlässen, z.B. wenn das Tier den Zoo wechselt, eine schwere Verletzung / Erkrankung erleben muss oder Nachwuchs bekommt. Die Akten eines Tieres erhalten eine fortlaufende Nummer (1, 2, 3, …) (AktenNr). Außerdem wird das Datum der Anlage der Akte (DatAnlage) sowie der Grund für die Anlage (Geburt, Krankheit, Tod, …) (Ereignis) und eine Beschreibung des Ereignisses (BeschrEr) in die Datenbank eingetragen. Nach dem Tod des Tieres werden alle Akten aus der Datenbank entfernt.
|
|
3.3.2 Lösungsschritte |
|
Die Anforderungsbeschreibung wird Punkt für Punkt abgearbeitet. |
|
Anforderung Teil 1 |
|
In Teil 1 wird auf die Tiere des Zoos eingegangen. Die Nennung der identifizierenden Tiernummer (Schlüssel) und weiterer beschreibender Attribute deutet eine Relation zu Tieren an: |
|
Tiere (#TNr, Name, Gattung, GebTag, Geschlecht, GebNr) |
|
Die Gebäudenummer (GebNr) wurde weiter unten als Teil einer Relation Gebäude im Text gefunden und konnte deshalb hier gleich als Fremdschlüssel angelegt werden. |
|
An der Stelle „Für jede Gattung …“ werden offensichtlich nicht mehr einzelne Tiere beschrieben, sondern die jeweilige Gattung. Nach einer Prüfung, ob damit eine neue Relation begründet wird (Gattung könnte auch ein Attribut von Tiere sein), wird diese angelegt. BezGatt (Gattungsbezeichnung) wird Schlüssel, Anzahl ein beschreibendes Attribut: |
Muster Einzel/Typ |
Tiere-Gattung (#BezGatt, Anzahl) |
|
Das Attribut Gattung von Tiere wird dann umbenannt in BezGatt und die Relation Tiere in Tiere-Einzeln: |
|
Tiere-Einzeln (#TNr, Name, BezGatt, GebTag, Geschlecht, GebNr) |
|
Dies ist das Muster Einzel/Typ, das in so gut wie jedem Datenmodell vorkommt und trotzdem häufig übersehen wird. |
|
Das Attribut BezGatt realisiert, als Schlüssel und Fremdschlüssel, eine relationale Verknüpfung zwischen den beiden Relationen und hält somit fest, zu welcher Gattung ein einzelnes Tier gehört. Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Tiere-Einzeln zu Tiere-Gattung: n:1 bzw. 1,1 : 1,m. |
|
Beginnend mit „Wegen der Bedeutung …“ wird in der Anforderungsbeschreibung weiter spezifiziert: Es gibt zusätzliche Attribute für (die einzelnen) Elefanten (Gewicht) und Giraffen (Größe). Diese beiden Attribute werden für die übrigen Tiere nicht erfasst. Fügt man sie an Tiere-Einzeln an, gibt es in dieser Relation Attribute, die nicht für alle Tiere erfasst werden. Es gäbe also semantisch bedingte Leereinträge. Dies ist in allen Datenbeständen nicht erwünscht (vgl. [Staud 2021, Stichwortsuche bzw. Index]) und wird auch von der relationalen Theorie unterbunden. In einer solchen Situation, werden die „zusätzlichen“ Attribute in eigene Relationen getan. Es entsteht eine Generalisierung / Spezialisierung. Mit der Datumsangabe (Zeitpunkt der Messung), die jeweils zu einem zusammengesetzten Schlüssel führt, entsteht folgende Generalisierung / Spezialisierung: |
Generalisierung / Spezialisierung |
Elefanten (#(TierNr, Datum), Gewicht) |
|
Giraffen (#(TierNr, Datum), Größe) |
|
Tiere-Einzeln (#TierNr, Name, BezGatt, GebTag, Geschlecht, GebNr) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Tiere-Einzeln zu Giraffen: 1:1 bzw. 0,1 : 1,1. Ebenso von Tiere-Einzeln zu Elefanten. |
|
Hier das Modellfragment zu diesen ersten Schritten: |
|
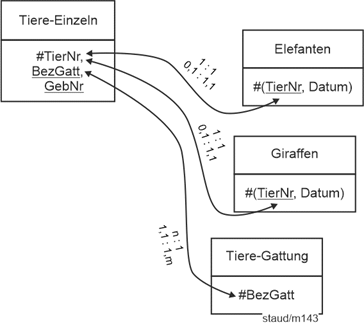
|
|
Abbildung 3.3-1: Datenmodell Zoo – Fragment Tiere |
|
Anforderung Teil 2 |
|
Teil 2 beschreibt die bezüglich der Fütterung zu erfassenden Datenbankaspekte. Zuerst einmal geht es um die tägliche Fütterung. Hier wird eine n:m-Beziehung angedeutet: für ein Tier mehrere Futterarten, eine Futterart für mehrere Tiere. Dies führt zu einer Relation Fütterung mit dem zusammengesetzten Schlüssel (TierNr, FuttBez), der auch gleich das Attribut Menge beigefügt wird. TierNr ist hier Schlüsselattribut (also Teil des Schlüssels) und auch Fremdschlüssel, dient also der Verknüpfung mit Tiere-Einzeln. Im folgenden wird auch noch das Futter hinsichtlich der Entnahmen näher beschrieben. Wir müssen also auch eine Relation Futter anlegen mit dem Schlüssel Bez (Futterbezeichnung) und den beschreibenden Attributen Vorrat und MiMenge (Mindestmenge). |
|
Hier die Relationen dieser n:m-Beziehung: |
|
Futter (#Bez, Vorrat, MiMenge) |
|
Fütterung (#(TierNr, FuttBez), Menge) |
|
Tiere-Einzeln (#TierNr, Name, BezGatt, GebTag, Geschlecht, GebNr) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Tiere-Einzeln über Fütterung zu Futter: n:m, bzw. 1,n : 0,m, weil es auch mal neu beschaffte Futterarten geben kann, die noch nicht verfüttert wurden. |
|
Anforderung Teil 3 |
|
Teil 3 widmet sich den Pflegern und Pflegerinnen. Diese sind gleich als Relation erkennbar: |
|
Pfleger (#PersNr, Name, Vorname) |
|
Der nachfolgende Text spricht – mit einem zeitlichen Aspekt - die Pflege als solche an. Es kann angenommen werden (vor allem mit der zeitlichen Dimension), dass ein Tier von unterschiedlichen Pflegern versorgt wird und ein Pfleger unterschiedliche Tiere versorgt. Der Kern des Schlüssels ist daher die Kombination aus PersNr und TierNr, ergänzt um ein Attribut der Zeitphasen. Wir nehmen dafür hier Beginn. Das zweite zeitliche Attribut wird dann zum Nichtschlüsselattribut der Relation: |
|
Pflege (#(PersNr, TierNr, Beginn), Ende) |
|
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Pfleger über Pflege zu Tiere-Einzeln: n:m, bzw. 0,n : 1,m, weil eine neu eingestellte Pflegekraft erst mal noch keine Zuständigkeit hat. |
|
Anforderung Teil 4 |
|
Teil 4 beschreibt die Gebäude. Die Relation ist sofort erkennbar: |
|
Gebäude (#GebNr, Größe, Typ, AnzPlätze) |
|
Das Attribut GebNr wurde oben schon in der Relation Tiere-Einzeln als Fremdschlüssel genutzt. |
|
Wie bringen wir die Information unter, „welches Tier aktuell in welchem Gebäude ist“. Dies leistet die GebNr (Gebäudenummer) als Fremdschlüssel in Tiere-Einzeln. Möglich ist dies, weil es sich um eine 1:n-Beziehung handelt (ein Tier kann nicht gleichzeitig in zwei Gebäuden sein). Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Gebäude zu Tiere-Einzeln: 1:n, bzw. 0,n : 1,1, weil auch neue Gebäude, denen noch kein Tier zugeordnet ist, in der Datenbank angelegt werden sollen. |
|
Anforderung Teil 5 |
|
Den Anforderungen kann entnommen werden, dass es zu jedem Tier zahlreiche Tierakten gibt. Dies erfordert einen zusammengesetzten Schlüssel (TierNr, AktNr), wobei TierNr Fremdschlüssel ist. Beschreibende Attribute sind das Datum der Anlage (DatAnlage), das die Aktenanlage auslösende Ereignis sowie eine Beschreibung des Ereignisses (BeschrEr). |
Tierakten |
Tierakten (#(TierNr, AktNr), DatAnlage, Ereignis, BeschrEr) |
|
Dies ist ein Beispiel für Existenzabhängigkeit, die in anderen Kontexten auch Komposition genannt wird (Z.B. in der objektorientierten Theorie, vgl. [Staud 2019]). Deutlich wird dies dadurch, dass die Akten nur zur Lebenszeit des Tieres in der Datenbank verbleiben sollen. Nach seinem Tod werden sie aus der Datenbank genommen. Sie sind also existenzabhängig von dem entsprechenden Tupel der Relation Tiere-Einzeln. |
Komposition / Existenzabhängigkeit |
Die Kardinalitäten und Min-/Max-Angaben sind wie folgt: Von Tiere-Einzeln zu Tierakten: 1:n, bzw. 1,n : 1,1, wenn man annimmt, dass ein Tier mit der Geburt die erste Akte erhält. |
|
Im Aufbau des Schlüssels von Tierakten zeigt sich die Abhängigkeit: Da eine Relation immer einen vollständigen Schlüssel haben muss und da TierNr ein Teil des Schlüssels ist, fällt mit Wegfall des Tieres auch das Tupel in Tierakte weg. |
|
3.3.3 Lösung |
|
Textliche Fassung |
|
Elefanten (#(TierNr, Datum), Gewicht) |
|
Futter (#Bez, Vorrat, MiMenge) |
|
Fütterung (#(TierNr, FuttBez, Datum), Menge) |
|
Gebäude (#GebNr, Größe, Typ, AnzPlätze) |
|
Giraffen (#(TierNr, Datum), Größe) |
|
Pflege (#(PersNr, TierNr, Beginn), Ende) |
|
Pfleger (#PersNr, Name, VName) |
|
Tierakten (#(TierNr, AktenNr), DatAnlage, Ereignis, BeschrEr) |
|
Tiere-Einzeln (#TierNr, Name, BezGatt, GebTag, Geschlecht, GebNr) |
|
Tiere-Gattung (#BezGatt, Anzahl) |
|
Nicht selbsterklärende Attributsbezeichnungen: |
|
Futter.MiMenge: Mindestmenge |
|
Fütterung.FuttBez: Bezeichnung des Futters |
|
Gebäude.AnzPlätze: Anzahl der Plätze im Gebäude |
|
Gebäude.GebNr: Eindeutige Nummer des Gebäudes |
|
Pfleger.VName: Vorname |
|
Tierakten.DatAnlage: Datum der Anlage der Akte |
|
Tierakten.BeschrEr: Beschreibung des Ereignisses, das zur Anlage der Akte geführt hat |
|
Tiere-Einzeln.TierNr: Eindeutige, dem Tier zugeordnete Nummer. |
|
Tiere-Gattung.BezGatt: Bezeichnung der Tiergattung |
|
Grafische Fassung |
|
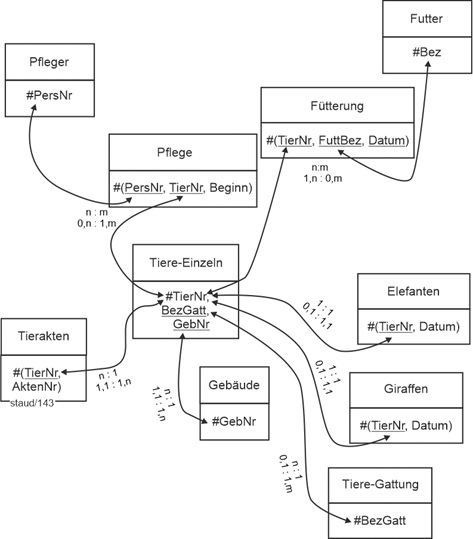
|
|
Abbildung 3.3-2: Relationales Datenmodell Zoo |
|
Muster Komposition bei Tierakten |
|
Muster Einzel/Typ bei Tiere |
|
Muster Gen/Spez bei Elefanten, Giraffen |
|
3.3.4 Einrichten der Datenbank |
|
Datenbank Zoo |
|
|
create database Zoo default character set latin1 collate latin1_german1_ci;
|
|
Futter (#Bez, Vorrat, MiMenge) |
|
|
create table futter (Bez char(10), Vorrat decimal(5,2), MiMenge decimal(5,2), primary key (Bez));
|
|
Gebäude (#GebNr, Größe, Typ, AnzPlätze) |
|
|
create table gebaeude (GebNr tinyint(3), groesse smallint(5), typ varchar(10), AnzPlaetze tinyint(3), primary key (GebNr));
|
|
Pfleger (#PersNr, Name, VName) |
|
|
create table Pfleger (PersNr smallint(3), Name varchar(10), VName varchar(10), primary key (PersNr));
|
|
Tiere-Gattung (#BezGatt, Anzahl) |
|
|
create table TiereG (BezGatt varchar(15), Anzahl tinyint(2), primary key (BezGatt));
|
|
Tiere-Einzeln (#TierNr, Name, BezGatt, GebTag, Geschlecht, GebNr) |
|
|
create table TiereE (TierNr smallint(6), Name char(10), BezGatt varchar(15) references TiereG(BezGatt), GebTag date, Geschlecht char(1), GebNr tinyint(3), primary key (TierNr), foreign key (GebNr) references Gebaeude(GebNr));
|
|
Elefanten (#(TierNr, Datum), Gewicht) |
|
|
create table elefanten (TierNr smallint(6), Datum date, Gewicht decimal (6,2), primary key (TierNr, Datum), foreign key (TierNr) references TiereE(TierNr));
|
|
Giraffen (#(TierNr, Datum), Größe) |
|
|
create table giraffen (TierNr smallint(6), Datum date, Größe decimal (4,2), primary key (TierNr, Datum), foreign key (TierNr) references TiereE(TierNr));
|
|
Fütterung (#(TierNr, FuttBez, Datum), Menge) |
|
|
create table Fuetterung (TierNr smallint(6), FuttBez char(10), Datum date, Menge decimal(3,1), primary key (TierNr, FuttBez, Datum), foreign key (TierNr) references TiereE(TierNr), foreign key (FuttBez) references Futter(Bez));
|
|
Pflege (#(PersNr, TierNr, Beginn), Ende) |
|
|
create table Pflege (PersNr smallint(3), TierNr smallint(6), Beginn date, Ende date, primary key (PersNr, TierNr, Beginn), foreign key (PersNr) references pfleger(PersNR), foreign key (TierNr) references TiereE(TierNR));
|
|
Tierakten (#(TierNr, AktenNr), DatAnlage, Ereignis, BeschrEr) |
|
|
create table Tierakten (TierNr smallint(6), AktenNr smallint(3), DatAnlage date, Ereignis varchar(10), BeschrEr varchar(20), primary key (TierNr, AktenNr), foreign key (TierNr) references TiereE(TierNr));
|
|
Am Stück, für die Übernahme nach mySQL: |
|
create database Zoo default character set latin1 collate latin1_german1_ci; |
|
create table futter (Bez char(10), Vorrat decimal(5,2), MiMenge decimal(5,2), primary key (Bez)); |
|
create table gebaeude (GebNr tinyint(3), groesse smallint(5), typ varchar(10), AnzPlaetze tinyint(3), primary key (GebNr)); |
|
create table Pfleger (PersNr smallint(3), Name varchar(10), VName varchar(10), primary key (PersNr)); |
|
create table TiereG (BezGatt varchar(15), Anzahl tinyint(2), primary key (BezGatt)); |
|
create table TiereE (TierNr smallint(6), Name char(10), BezGatt varchar(15) references TiereG(BezGatt), GebTag date, Geschlecht char(1), GebNr tinyint(3), primary key (TierNr), foreign key (GebNr) references Gebaeude(GebNr)); |
|
create table elefanten (TierNr smallint(6), Datum date, Gewicht decimal (6,2), primary key (TierNr, Datum), foreign key (TierNr) references TiereE(TierNr)); |
|
create table giraffen (TierNr smallint(6), Datum date, Größe decimal (4,2), primary key (TierNr, Datum), foreign key (TierNr) references TiereE(TierNr)); |
|
create table Fuetterung (TierNr smallint(6), FuttBez char(10), Datum date, Menge decimal(3,1), primary key (TierNr, FuttBez, Datum), foreign key (TierNr) references TiereE(TierNr), foreign key (FuttBez) references Futter(Bez)); |
|
create table Pflege (PersNr smallint(3), TierNr smallint(6), Beginn date, Ende date, primary key (PersNr, TierNr, Beginn), foreign key (PersNr) references pfleger(PersNR), foreign key (TierNr) references TiereE(TierNR)); |
|
create table Tierakten (TierNr smallint(6), AktenNr smallint(3), DatAnlage date, Ereignis varchar(10), BeschrEr varchar(20), primary key (TierNr, AktenNr), foreign key (TierNr) references TiereE(TierNr)); |
|
3.3.5 Befüllen mit Daten |
|
Hinweis: Beim Nachvollziehen die Reihenfolge beachten. |
|
Relation TiereG |
|
|
insert into TiereG values ('ElefInd', 5);
|
|
|
insert into TiereG values ('ElefAfr', 6);
|
|
|
insert into TiereG values ('Giraffen', 11);
|
|
|
insert into TiereG values ('Löwen', 4);
|
|
|
select * from TiereG;
|
|
| BezGatt |
Anzahl |
| ElefAfr |
6 |
| ElefInd |
5 |
| Giraffen |
11 |
| Löwen |
4 |
| |
|
|
Relation Gebaeude |
|
|
insert into gebaeude (gebnr, groesse, typ, anzplaetze) values (17, 80, 'Hochhaus', 10);
|
|
|
insert into gebaeude values (22, 60, 'Haus', 5);
|
|
|
insert into gebaeude values (7, 80, 'Massivhaus', 8);
|
|
|
select * from Gebaeude;
|
|
| GebNr |
groesse |
typ |
AnzPlaetze |
| 7 |
80 |
Massivhaus |
8 |
| 17 |
80 |
Hochhaus |
10 |
| 22 |
60 |
Haus |
5 |
| |
|
|
Relation TiereE |
|
|
insert into TiereE values (1001, 'Rudi', 'ElefAfr', '2001-01-01', 'm', 7);
|
|
|
insert into TiereE values (1009, 'Sepp', 'ElefAfr', '2001-01-01', 'm', 7);
|
|
|
insert into TiereE values (1007, 'Otto', 'ElefAfr', '1998-02-05', 'm', 7);
|
|
|
insert into TiereE values (1010, 'Chiara', 'ElefInd', '2005-11-17', 'w', 7);
|
|
|
insert into TiereE values (1019, 'Ella', 'ElefInd', '2018-12-22', 'w', 7);
|
|
|
insert into TiereE values (2001, 'Fipo', 'Giraffen', '1980-05-01', 'm', 17);
|
|
|
insert into TiereE values (2011, 'Betsy', 'Giraffen', '1990-09-10', 'm', 17);
|
|
|
insert into TiereE values (5004, 'Rudi', 'Löwen', '2008-11-01', 'm', 22);
|
|
|
insert into TiereE values (5002, 'Ratzo', 'Löwen', '2006-01-06', 'w', 22);
|
|
|
insert into TiereE values (5001, 'Brutus', 'Löwen', '2016-02-23', 'm', 22);
|
|
|
insert into TiereE values (5003, 'Cäsar', 'Löwen', '2022-01-31', 'w', 22);
|
|
|
Select * from TiereE;
|
|
| TierNr |
Name |
BezGatt |
GebTag |
Geschlecht |
GebNr |
| 1001 |
Rudi |
ElefAfr |
2001-01-01 |
m |
7 |
| 1007 |
Otto |
ElefAfr |
1998-02-05 |
m |
7 |
| 1009 |
Sepp |
ElefAfr |
2001-01-01 |
m |
7 |
| 1010 |
Chiara |
ElefInd |
2005-11-17 |
w |
7 |
| 1019 |
Ella |
ElefInd |
2018-12-22 |
w |
7 |
| 2001 |
Fipo |
Giraffen |
1980-05-01 |
m |
17 |
| 2011 |
Betsy |
Giraffen |
1990-09-10 |
m |
17 |
| 5001 |
Rudi |
Löwen |
2016-02-23 |
m |
22 |
| 5002 |
Ratzo |
Löwen |
2006-01-06 |
w |
22 |
| 5003 |
Brutus |
Löwen |
2022-01-31 |
w |
22 |
| 5004 |
Cäsar |
Löwen |
2008-11-01 |
m |
22 |
| |
|
|
Relation Elefanten |
|
|
insert into elefanten values (1001, '2024-01-31', 520), (1007, '2024-01-18', 601), (1009, '2024-01-01', 720), (1010, '2024-05-05', 480), (1019, '2024-01-16', 515);
|
|
Relation Giraffen |
|
|
insert into giraffen values (2001, '2023-12-12', 3.80), (2011, '2023-12-20', 4.15);
|
|
Am Stück, für die Übernahme nach mySQL: |
|
insert into TiereG values ('ElefInd', 5); |
|
insert into TiereG values ('ElefAfr', 6); |
|
insert into TiereG values ('Giraffen', 11); |
|
insert into TiereG values ('Löwen', 4); |
|
insert into gebaeude (gebnr, groesse, typ, anzplaetze) values (17, 80, 'Hochhaus', 10); |
|
insert into gebaeude values (22, 60, 'Haus', 5); |
|
insert into gebaeude values (7, 80, 'Massivhaus', 8); |
|
insert into TiereE values (1001, 'Rudi', 'ElefAfr', '2001-01-01', 'm', 7); |
|
insert into TiereE values (1009, 'Sepp', 'ElefAfr', '2001-01-01', 'm', 7); |
|
insert into TiereE values (1007, 'Otto', 'ElefAfr', '1998-02-05', 'm', 7); |
|
insert into TiereE values (1010, 'Chiara', 'ElefInd', '2005-11-17', 'w', 7); |
|
insert into TiereE values (1019, 'Ella', 'ElefInd', '2018-12-22', 'w', 7); |
|
insert into TiereE values (2001, 'Fipo', 'Giraffen', '1980-05-01', 'm', 17); |
|
insert into TiereE values (2011, 'Betsy', 'Giraffen', '1990-09-10', 'm', 17); |
|
insert into TiereE values (5004, 'Rudi', 'Löwen', '2008-11-01', 'm', 22); |
|
insert into TiereE values (5002, 'Ratzo', 'Löwen', '2006-01-06', 'w', 22); |
|
insert into TiereE values (5001, 'Brutus', 'Löwen', '2016-02-23', 'm', 22); |
|
insert into TiereE values (5003, 'Cäsar', 'Löwen', '2022-01-31', 'w', 22); |
|
insert into elefanten values (1001, '2024-01-31', 520), (1007, '2024-01-18', 601), (1009, '2024-01-01', 720), (1010, '2024-05-05', 480), (1019, '2024-01-16', 515); |
|
insert into giraffen values (2001, '2023-12-12', 3.80), (2011, '2023-12-20', 4.15); |
|
3.3.6 Abfragen |
|
Auswahl der weiblichen Elefanten und Giraffen mit den Attributen TierNr, Name, Gattung, GebNr, AnzPlaetze, GebTag und Geschlecht. |
|
|
SELECT e.TierNr, e.Name, g.BezGatt as Gattung, h.GebNr as 'Nr Gebäude', h.AnzPlaetze as 'Zahl Plätze', e.GebTag as Geburtstag, e.Geschlecht as G
|
|
|
FROM tiereE E, TiereG G, Gebaeude H
|
|
|
where e.Geschlecht='w' and e.GebNr=h.GebNr and e.BezGatt =g.BezGatt;
|
|
|
|
|
| TierNr |
Name |
Gattung |
Nr Gebäude |
Zahl Plätze |
Geburtstag |
G |
| 1010 |
Chiara |
ElefInd |
7 |
8 |
2005-11-17 |
w |
| 1019 |
Ella |
ElefInd |
7 |
8 |
2018-12-22 |
w |
| 5002 |
Ratzo |
Löwen |
22 |
5 |
2006-01-06 |
w |
| 5003 |
Brutus |
Löwen |
22 |
5 |
2022-01-31 |
w |
| |
|
|
Auswahl der Elefanten mit den Attributen TierNr, Name, BezGatt, Gewicht und Wiegedatum (datum). |
|
|
select t.TierNr, t.name as Name, t.BezGatt as Gattung,
|
|
|
e.gewicht as Gewicht, e.datum as Wiegedatum
|
|
|
from TiereE t, Elefanten e
|
|
|
where t.TierNr=e.tiernr order by t.BezGatt, t.Name;
|
|
|
|
|
| TierNr |
Name |
Gattung |
Gewicht |
Wiegedatum |
| 1007 |
Otto |
ElefAfr |
601.00 |
2024-01-18 |
| 1001 |
Rudi |
ElefAfr |
520.00 |
2024-01-31 |
| 1009 |
Sepp |
ElefAfr |
720.00 |
2024-01-01 |
| 1010 |
Chiara |
ElefInd |
480.00 |
2024-05-05 |
| 1019 |
Ella |
ElefInd |
515.00 |
2024-01-16 |
| |
|
|
4 Relationale Datenbanken - Von der Anforderung zur Web-Benutzeroberfläche |
|
Gesamtweg:
Anforderungen – Datenmodell (Schema) – Datenbank – Web-Benutzeroberfläche |
|
Gesamtaufgabe |
|
Ziel dieses Kapitels ist es, den in den obigen zwei Kapiteln aufgezeigten Weg von den Anforderungen bis zum Datenmodell bzw. bis zur Datenbank fortzusetzen bis zur Web-Oberfläche, von der aus die Datenbank abgefragt und ausgewertet wird. Auch für diesen letzten Schritt des Gesamtwegs werden die elementaren Techniken trainiert. Damit ist dann der oben gezeigte Gesamtweg in seinen Grundzügen in den Aufgaben thematisiert. Insgesamt also: |
|
- Anforderungen zum Anwendungsbereich bearbeiten.
- Relationales Datenmodell (Schema) erstellen (Kapitel 2).
- Relationale Datenbank mit mySQL unter XAMPP einrichten (Kapitel 3).
- Realisierung exemplarischer Abfragen und Auswertungen mit mySQL (Kapitel 3).
- Erstellung einer einfachen webbasierten Benutzerschnittstelle („WebOberfläche“; Graphical User Interface; GUI) (mit HTML, CSS) für exemplarische Abfragen und Auswertungen mit der Datenbank (Kapitel 4).
|
|
Für diesen letzten Schritt werden zusätzlich zu den oben genannten Methoden auch noch Kenntnisse in HTML und PHP benötigt. Die wichtigsten daraus benötigten Theorieelemente werden in den Kapiteln 11 und 12 wiederholt. |
|
|
|
4.1 Kindergarten |
|
Aufgabenstellung: Prof. Dr. Josef L. Staud |
|
Lösung: stud. oec. inf. Karolin Staud |
|
Diese Aufgabe ist Grundlage für die nachfolgenden (4.2 – 4.7). d.h., die hier erstellte Datenbank wird für die Aufgaben 4.2 - 4.7 genutzt. |
|
4.1.1 Anforderungsbeschreibung |
|
Ein Kindergarten möchte seine Daten in einer Datenbank verwalten. Folgendes soll erfasst werden: |
|
- Die Kinder mit Name, Vorname, Adresse (Straße, PLZ, Ort), Eintrittsdatum, Geburtstag. Außerdem wird erfasst, ob es ein Geschwisterkind ist, d.h., ob ein Geschwister auch im Kindergarten ist.
- Für die Kinder über 4 Jahre wird erfasst, an welchen Förderprogrammen sie teilnehmen (Sprachförderung, Förderung Feinmotorik, …) und von wann bis wann (Datumsangaben) diese durchgeführt werden. Es kommt durchaus vor, dass ein Kind an mehreren Fördermaßnahmen teilnimmt.
- Die Eltern mit Name, Vorname, Telefon (mehrere Telefonnummern, z.B. eine zu Hause, eine von der Arbeitsstätte, ein Handy) und Adresse. Natürlich wird festgehalten, welche Eltern zu welchem Kind gehören. Eltern und Kinder müssen nicht denselben Nachnamen haben. Die Eltern können an unterschiedlichen Orten wohnen (z.B., weil sie geschieden sind).
|
|
4.1.2 Aufgaben |
|
- Erstellen Sie für diesen Anwendungsbereich ein Relationales Datenmodell in textlicher und grafischer Fassung.
- Richten Sie zum obigen Datenmodell eine Datenbank ein. Führen Sie zwei SQL-Abfragen durch, die jeweils mindestens zwei Relationen verknüpfen.
|
|
4.1.3 Datenmodell erstellen |
|
Am Anfang der Anforderungsbeschreibung kommt man auf die Relation der Kinder, in der der Name, der Vorname, die Adresse, das Eintrittsdatum, das Austrittsdatum und das Geschwister (falls vorhanden) festgehalten werden soll. Hier fügt man am besten einen konstruierten eindeutigen Schlüssel hinzu, da sonst der Schlüssel zu groß und damit schwer zu verarbeiten wird. Dadurch kommt man relativ schnell auf folgende Relation: |
|
Kinder (#KindID, Name, Vorname, AdressID, Eintrittsdatum, Geburtstag) |
|
Da das Attribut, das aussagt, ob ein Kind ein Geschwister hat oder nicht, als Verknüpfung sehr schwer darzustellen wäre, fügt man dies hier als Attribut (GKindJN) einfach an die Relation Kinder an. Hier kann man mit 1 (Ja) oder 0 (Nein) den Sachverhalt erfassen. |
|
Kinder (#KindID, Name, Vorname, Eintrittsdatum, Geburtstag, GKindJN) |
|
Nun zur Erfassung der Adressen. Da ein Kind nur an einer Adresse wohnt, könnte man die ganze Adresse direkt in der Relation Kinder anführen. Da aber weiter unten in der Anforderungsbeschreibung von Adressen von Elternteilen die Rede ist, werden die Adressen in einer eigenen Relation erfasst: |
|
Adressen (#AdressID, Straße, PLZ, Ort) |
|
Die Relation Kinder wird dann um einen Fremdschlüssel AdressID ergänzt: |
|
Kinder (#KindID, Name, Vorname, AdressID, Eintrittsdatum, Geburtstag, GKindJN) |
|
Beim weiteren Lesen erkennt man eine Generalisierung / Spezialisierung im nächsten Teil der Anforderungsbeschreibung, nämlich darin, dass über 4-jährige Kinder spezifische Attribute erhalten. Dies wird im relationalen Modell so umgesetzt, dass die Ü4-jährigen Kinder eine neue Relation erhalten, mit demselben Schlüssel wie Kinder. Angehängt werden die Attribute die im Text aufgezählt sind. |
Generalisierung / Spezialisierung |
Kinderü4 (#KindID, Förderprogramm, Anfang, Ende) |
|
Da ein Kind jedoch an mehreren Förderprogrammen teilnehmen kann, muss „Förderprogramm“ in eine neue Relation ausgelagert werden und in der Kindü4-Relation zum Fremdschlüssel gemacht werden. Sonst kann es zu Mehrfacheinträgen kommen. In der neuen Relation wird auch ein Schlüssel „FördID“ angelegt, da alles andere nur schwer eindeutig zu machen wäre: |
|
Kinderue4 (#(KindID, FördProg)) |
|
FoerdProg (#FördID, Bez, Art, Anfang, Ende) |
|
Da für die Relation Kindü4 der Schlüssel KindID nicht eindeutig wäre, wird KindID und FördProg gemeinsam zum Schlüssel. |
|
Im nächsten Abschnitt werden die Eltern beschrieben. Hier werden einige Attribute aufgenommen, unter anderem die Telefonnummer und die Adresse. Auch hier wird eine eindeutige ID festgelegt. |
|
Elternteil (#ElternID, Name, Vorname, AdressID) |
|
Da es verschiedene Telefonnummern und auch Adressen gibt, müssen diese wieder in extra Relationen ausgelagert werden, um Mehrfacheinträge zu vermeiden. |
|
Da die Telefonnummern nur durch die Nummer an sich nicht eindeutig werden, weil auch diese zu z.B. 2 Elternteilen gehören können (zum Beispiel bei Festnetz), muss sich der Schlüssel hier aus der Telefonnummer und der ElternID zusammensetzen. Das Attribut „Art“ legt fest, ob es sich um die Mobilfunknummer, die Festnetznummer oder eine andere Nummer handelt. |
|
ElternTel (#(ElternID, TelNr), Art) |
|
Die Kinder der Eltern müssen in einer Verbindungsrelation aufgenommen werden, da wir hier eine N-zu-M Beziehung haben. Ein Kind hat womöglich 2 oder mehrere Elternteile, ein Elternteil kann auch mehrere Kinder haben. |
|
Dies kann man also nicht wie bisher einfach durch einen Fremdschlüssel lösen, sondern durch eine neue Relation, die Elternteil und Kinder verbindet und die durch die zusammengesetzten Schlüssel der beiden Relationen eindeutige Ausprägungen hat. |
|
EltTeilKind (#(KindID, ElternID)) |
|
Textliche Fassung |
|
Kinder (#KindID, Name, Vorname, AdressID, Eintrittsdatum, Austrittsdatum, GKindJN) |
|
Kinderue4(#(KindID, FoerdProg)) |
|
FoerdProg (#FoerdId, Bez, Art, Anfang, Ende) |
|
Elternteil (#ElternID, Name, Vorname, AdressID) |
|
EltTeilKind (#(KindID, ElternID)) |
|
ElternTel (#(ElternId, TelNr), Art) |
|
Adressen (#AdressID, Straße, PLZ, Ort) |
|
Grafische Fassung |
|
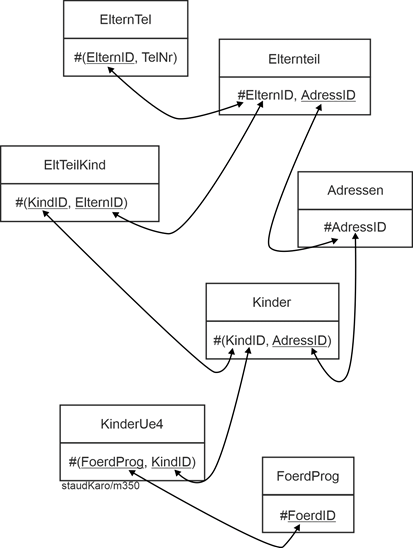
|
|
Abbildung 4.1-1: Relationales Datenmodell Kindergarten |
|
4.1.4 Datenbank einrichten |
|
Lösung: stud. oec. inf. Karolin Staud |
|
Zunächst muss die Datenbank an sich angelegt werden: |
|
|
create database Kindergarten default character set latin1 collate latin1_german1_ci;
|
|
Dann müssen zuerst die Relationen ohne Fremdschlüssel angelegt werden, da diese auf keine anderen (womöglich noch nicht erstellten) Relationen zugreifen. |
|
Anlegen der Relation für die Förderprogramme: |
|
|
create table FoerdProg (FoerdID smallint(2), Bez varchar(15),
|
|
|
Art varchar(15), Anfang date, Ende date, primary key (FoerdID));
|
|
Anlegen der Adressen: |
|
|
create table Adressen (AdressID smallint(3), Strasse varchar(20),
|
|
|
PLZ varchar(5), Ort varchar(15), primary key(AdressID));
|
|
Jetzt kann man auch die Relationen mit Fremdschlüssel anlegen, da die Basis gelegt wurde. Anlegen der Kinderrelation: |
|
|
create table Kinder(KindID smallint(3), Name char(10),
|
|
|
Vorname char(10), AdressID smallint(3), Eintrittsdatum date,
|
|
|
Geburtstag date, GKindJN boolean,
|
|
|
primary key(KindID),
|
|
|
foreign key(AdressID) references adressen(AdressID));
|
|
Anlegen der Relation für Kinder über 4: |
|
|
create table Kinderue4 (KindID smallint(3), FoerdProg smallint(2),
|
|
|
primary key(KindID, FoerdProg),
|
|
|
foreign key (FoerdProg) references FoerdProg(FoerdID));
|
|
Anlegen der Relation für die Eltern: |
|
|
create table Elternteil (ElternID smallint(3), Name varchar(15), Vorname varchar(9), AdressID smallint(3),
|
|
|
primary key (ElternID),
|
|
|
foreign key (AdressID) references Adressen(AdressID));
|
|
Anlegen der Verbindung zwischen Kindern und Eltern: |
|
|
create table EltTeilKind(KindID smallint(3), ElternID smallint(3),
|
|
|
primary key (KindID, ElternID),
|
|
|
foreign key (KindID) references Kinder (KindID),
|
|
|
foreign key (ElternID) references Elternteil (ElternID));
|
|
Anlegen der Telefone der Eltern: |
|
|
create table ElternTel(ElternID smallint(3), TelNr char(12), Art varchar(8),
|
|
|
primary key (ElternID, TelNr),
|
|
|
foreign key (ElternID) references Elternteil(ElternID));
|
|
Zusammengefasst für die Übernahme nach mySQL: Die Datenbank und alle Relationen. |
|
Zuerst die Datenbank anlegen: |
|
create database Kindergarten default character set latin1 collate latin1_german1_ci; |
|
Jetzt die Datenbank anwählen, dann: |
|
create table FoerdProg (FoerdID smallint(2), Bez varchar(15), Art varchar(15), Anfang date, Ende date, primary key (FoerdID)); |
|
create table Adressen (AdressID smallint(3), Strasse varchar(20), PLZ varchar(5), Ort varchar(15), primary key(AdressID)); |
|
create table Kinder(KindID smallint(3), Name char(10), Vorname char(10), AdressID smallint(3), Eintrittsdatum date, Geburtstag date, GKindJN boolean, primary key(KindID), foreign key(AdressID) references adressen(AdressID)); |
|
create table Kinderue4 (KindID smallint(3), FoerdProg smallint(2), primary key(KindID, FoerdProg), foreign key (FoerdProg) references FoerdProg(FoerdID)); |
|
create table Elternteil (ElternID smallint(3), Name varchar(15), Vorname varchar(9), AdressID smallint(3), primary key (ElternID), foreign key (AdressID) references Adressen(AdressID)); |
|
create table EltTeilKind(KindID smallint(3), ElternID smallint(3), primary key (KindID, ElternID), foreign key (KindID) references Kinder (KindID), foreign key (ElternID) references Elternteil (ElternID)); |
|
create table ElternTel(ElternID smallint(3), TelNr char(12), Art varchar(8), primary key (ElternID, TelNr), foreign key (ElternID) references Elternteil(ElternID)); |
|
Einfüllen von fiktiven Daten |
|
Auch hier gilt: Zuerst die Relationen ohne Fremdschlüssel befüllen! |
|
Relation FoerdProg |
|
|
insert into foerdprog values
|
|
|
(1, 'Sprachförderung', 'Sprache', '2022-06-01', '2022-11-30'),
|
|
|
(2, 'Feinmotorik', 'Körper', '2022-01-05', '2022-3-22'),
|
|
|
(3, 'Motivation', 'Intellekt', '2023-10-13', '2023-12-24'),
|
|
|
(4, 'Reaktionen', 'Körper', '2022-07-26', '2023-02-19');
|
|
Relation Adressen |
|
|
insert into adressen values
|
|
|
(001, 'Schlossstraße 2', '12345', 'München'),
|
|
|
(002, 'Auf der Mauer 17', '55874', 'Heiligenbach'),
|
|
|
(003, 'Alleeweg 5', '37254', 'Weingarten'),
|
|
|
(004, 'Weinstraße 1', '37254', 'Weingarten'),
|
|
|
(005, 'Schlossstraße 4', '12345', 'München'),
|
|
|
(006, 'Am Bergweg 11', '55874', 'Heiligenbach'),
|
|
|
(007, 'Klabusterstraße 7', '55874', 'Heiligenbach'),
|
|
|
(008, 'Heinzelgasse 63', '74385', 'Überlingen'),
|
|
|
(009, 'Gartenstraße 29', '94743', 'Passau'),
|
|
|
(010, 'Beethovenstraße 12', '94743', 'Passau');
|
|
Relation Elternteil |
|
|
insert into Elternteil VALUES
|
|
|
(1, 'Meier', 'Alexander', 6),
|
|
|
(2, 'Meier', 'Sandra', 6),
|
|
|
(3, 'Schneider', 'Josef', 1),
|
|
|
(4, 'Müller', 'Bernd', 7),
|
|
|
(5, 'Wagner', 'Luise', 3),
|
|
|
(6, 'Wagner', 'Benedikt', 3),
|
|
|
(7, 'Bäcker', 'Angelika', 2),
|
|
|
(8, 'Hoffmann', 'Pamela', 10),
|
|
|
(9, 'Hoffmann', 'Jim', 10),
|
|
|
(10, 'Lenz', 'Moritz', 8),
|
|
|
(11, 'Rose', 'Emma', 8),
|
|
|
(12, 'Rose', 'Maria', 9),
|
|
|
(13, 'Sturm', 'Lorenz', 4),
|
|
|
(14, 'Wiese', 'Hannes', 5),
|
|
|
(15, 'Wiese', 'Clemenz', 5);
|
|
Relation Kinder |
|
|
insert into Kinder VALUES
|
|
|
(1, 'Meier', 'Max', 6, '2021-03-20', '2016-06-12', true),
|
|
|
(2, 'Meier', 'Moritz', 6, '2019-01-04', '2016-01-25', true),
|
|
|
(3, 'Schneider', 'Elli', 1, '2023-05-24', '2017-01-25', true),
|
|
|
(4, 'Schneider', 'Luca', 1, '2022-01-18', '2018-10-23', true),
|
|
|
(5, 'Müller', 'Johannes', 7, '2018-09-03', '2015-12-18', false),
|
|
|
(6, 'Wagner', 'Karla', 3, '2019-04-23', '2016-10-14', false),
|
|
|
(7, 'Bäcker', 'Klaus', 2, '2022-04-27', '2017-01-25', false),
|
|
|
(8, 'Hoffmann', 'Claudia', 10, '2018-01-01', '2015-01-01', true),
|
|
|
(9, 'Hoffmann', 'Lena', 10, '2019-01-01', '2021-01-01', true),
|
|
|
(10, 'Hoffmann', 'Sabrina', 10, '2022-01-01', '2018-01-25', true),
|
|
|
(11, 'Lenz', 'Barbie', 8, '2020-07-16', '2021-11-11', false),
|
|
|
(12, 'Rose', 'Max', 9, '2019-09-10', '2021-09-10', true),
|
|
|
(13, 'Rose', 'Lukas', 9, '2021-09-10', '2022-03-25', true),
|
|
|
(14, 'Sturm', 'Niklas', 4, '2022-08-12', '2018-01-25', false),
|
|
|
(15, 'Wiese', 'Elisabeth', 5, '2023-08-21', '2020-01-25', false);
|
|
Relation Kinderü4 |
|
|
insert into Kinderue4 VALUES
|
|
|
(1, 2),
|
|
|
(3, 1),
|
|
|
(3, 3),
|
|
|
(8, 4),
|
|
|
(9, 1),
|
|
|
(9, 2),
|
|
|
(9, 4),
|
|
|
(14, 3);
|
|
Relation EltTeilKind |
|
|
insert into EltTeilKind VALUES
|
|
|
(1, 1),(1, 2),(2, 1),(2, 2),(3, 3),(4, 3),(5, 4),(6, 5),(6, 6),(7, 7),(8, 8),(8, 9),(9, 8),(9, 9),(10, 8),(10, 9),(11, 10),(11, 11),(12, 12),(13, 12),(14, 13),(15, 14),(15, 15);
|
|
Relation ElternTel |
|
|
insert into ElternTel VALUES
|
|
|
(1, '012345678901', 'mobil'),
|
|
|
(2, '234567898765', 'mobil'),
|
|
|
(1, '456789876543', 'Festnetz'),
|
|
|
(2, '456789876543', 'Festnetz'),
|
|
|
(3, '564738574612', 'mobil'),
|
|
|
(4, '098675463415', 'mobil'),
|
|
|
(4, '867594876676', 'Arbeit'),
|
|
|
(5, '048396775844', 'mobil'),
|
|
|
(5, '346384739288', 'Festnetz'),
|
|
|
(6, '346384739288', 'Festnetz'),
|
|
|
(7, '574987336452', 'mobil'),
|
|
|
(8, '476302980014', 'Arbeit'),
|
|
|
(8, '120923847625', 'Festnetz'),
|
|
|
(9, '120923847625', 'Festnetz'),
|
|
|
(10, '473639567386', 'mobil'),
|
|
|
(11, '003927562834', 'mobil'),
|
|
|
(12, '874630112742', 'Arbeit'),
|
|
|
(13, '493823465989', 'Festnetz'),
|
|
|
(14, '112653049378', 'Festnetz'),
|
|
|
(15, '112653049378', 'Festnetz');
|
|
Alles zusammen, für die Übernahme in mySQL: |
|
insert into foerdprog values |
|
(1, 'Sprachförderung', 'Sprache', '2022-06-01', '2022-11-30'), |
|
(2, 'Feinmotorik', 'Körper', '2022-01-05', '2022-3-22'), |
|
(3, 'Motivation', 'Intellekt', '2023-10-13', '2023-12-24'), |
|
(4, 'Reaktionen', 'Körper', '2022-07-26', '2023-02-19'); |
|
insert into adressen values |
|
(001, 'Schlossstraße 2', '12345', 'München'), |
|
(002, 'Auf der Mauer 17', '55874', 'Heiligenbach'), |
|
(003, 'Alleeweg 5', '37254', 'Weingarten'), |
|
(004, 'Weinstraße 1', '37254', 'Weingarten'), |
|
(005, 'Schlossstraße 4', '12345', 'München'), |
|
(006, 'Am Bergweg 11', '55874', 'Heiligenbach'), |
|
(007, 'Klabusterstraße 7', '55874', 'Heiligenbach'), |
|
(008, 'Heinzelgasse 63', '74385', 'Überlingen'), |
|
(009, 'Gartenstraße 29', '94743', 'Passau'), |
|
(010, 'Beethovenstraße 12', '94743', 'Passau'); |
|
insert into Elternteil VALUES |
|
(1, 'Meier', 'Alexander', 6), |
|
(2, 'Meier', 'Sandra', 6), |
|
(3, 'Schneider', 'Josef', 1), |
|
(4, 'Müller', 'Bernd', 7), |
|
(5, 'Wagner', 'Luise', 3), |
|
(6, 'Wagner', 'Benedikt', 3), |
|
(7, 'Bäcker', 'Angelika', 2), |
|
(8, 'Hoffmann', 'Pamela', 10), |
|
(9, 'Hoffmann', 'Jim', 10), |
|
(10, 'Lenz', 'Moritz', 8), |
|
(11, 'Rose', 'Emma', 8), |
|
(12, 'Rose', 'Maria', 9), |
|
(13, 'Sturm', 'Lorenz', 4), |
|
(14, 'Wiese', 'Hannes', 5), |
|
(15, 'Wiese', 'Clemenz', 5); |
|
insert into Kinder VALUES |
|
(1, 'Meier', 'Max', 6, '2021-03-20', '2016-06-12', true), |
|
(2, 'Meier', 'Moritz', 6, '2019-01-04', '2016-01-25', true), |
|
(3, 'Schneider', 'Elli', 1, '2023-05-24', '2017-01-25', true), |
|
(4, 'Schneider', 'Luca', 1, '2022-01-18', '2018-10-23', true), |
|
(5, 'Müller', 'Johannes', 7, '2018-09-03', '2015-12-18', false), |
|
(6, 'Wagner', 'Karla', 3, '2019-04-23', '2016-10-14', false), |
|
(7, 'Bäcker', 'Klaus', 2, '2022-04-27', '2017-01-25', false), |
|
(8, 'Hoffmann', 'Claudia', 10, '2018-01-01', '2015-01-01', true), |
|
(9, 'Hoffmann', 'Lena', 10, '2019-01-01', '2021-01-01', true), |
|
(10, 'Hoffmann', 'Sabrina', 10, '2022-01-01', '2018-01-25', true), |
|
(11, 'Lenz', 'Barbie', 8, '2020-07-16', '2021-11-11', false), |
|
(12, 'Rose', 'Max', 9, '2019-09-10', '2021-09-10', true), |
|
(13, 'Rose', 'Lukas', 9, '2021-09-10', '2022-03-25', true), |
|
(14, 'Sturm', 'Niklas', 4, '2022-08-12', '2018-01-25', false), |
|
(15, 'Wiese', 'Elisabeth', 5, '2023-08-21', '2020-01-25', false); |
|
insert into Kinderue4 VALUES (1, 2), (3, 1), (3, 3), (8, 4), (9, 1), (9, 2), (9, 4), (14, 3); |
|
insert into EltTeilKind VALUES (1, 1), (1, 2), (2, 1), (2, 2), (3, 3), (4, 3), (5, 4), (6, 5), (6, 6), (7, 7), (8, 8), (8, 9), (9, 8), (9, 9), (10, 8), (10, 9), (11, 10), (11, 11), (12, 12), (13, 12), (14, 13), (15, 14), (15, 15); |
|
insert into ElternTel VALUES |
|
(1, '012345678901', 'mobil'), |
|
(2, '234567898765', 'mobil'), |
|
(1, '456789876543', 'Festnetz'), |
|
(2, '456789876543', 'Festnetz'), |
|
(3, '564738574612', 'mobil'), |
|
(4, '098675463415', 'mobil'), |
|
(4, '867594876676', 'Arbeit'), |
|
(5, '048396775844', 'mobil'), |
|
(5, '346384739288', 'Festnetz'), |
|
(6, '346384739288', 'Festnetz'), |
|
(7, '574987336452', 'mobil'), |
|
(8, '476302980014', 'Arbeit'), |
|
(8, '120923847625', 'Festnetz'), |
|
(9, '120923847625', 'Festnetz'), |
|
(10, '473639567386', 'mobil'), |
|
(11, '003927562834', 'mobil'), |
|
(12, '874630112742', 'Arbeit'), |
|
(13, '493823465989', 'Festnetz'), |
|
(14, '112653049378', 'Festnetz'), |
|
(15, '112653049378', 'Festnetz'); |
|
Abfragebeispiele |
|
In der ersten Abfrage werden Eltern mit ihren Kindern ausgegeben: |
|
|
select e.elternid, k.kindid, e.name as "Elternteil Name",
|
|
|
e.vorname as "Elternteil VName", k.name as "Name Kind",
|
|
|
k.vorname as "Vorname Kind"
|
|
|
from Elternteil e, kinder k, eltteilkind et
|
|
|
where k.kindid=et.kindid and e.elternid= et.elternid
|
|
|
order by elternid, kindid;
|
|
|
|
|
| elternid |
kindid |
Elternteil Name |
Elternteil VName |
Name Kind |
Vorname Kind |
| 1 |
1 |
Meier |
Alexander |
Meier |
Max |
| 1 |
2 |
Meier |
Alexander |
Meier |
Moritz |
| 2 |
1 |
Meier |
Sandra |
Meier |
Max |
| 2 |
2 |
Meier |
Sandra |
Meier |
Moritz |
| 3 |
3 |
Schneider |
Josef |
Schneider |
Elli |
| 3 |
4 |
Schneider |
Josef |
Schneider |
Luca |
| 4 |
5 |
Müller |
Bernd |
Müller |
Johannes |
| 5 |
6 |
Wagner |
Luise |
Wagner |
Karla |
| 6 |
6 |
Wagner |
Benedikt |
Wagner |
Karla |
| 7 |
7 |
Bäcker |
Angelika |
Bäcker |
Klaus |
| 8 |
8 |
Hoffmann |
Pamela |
Hoffmann |
Claudia |
| 8 |
9 |
Hoffmann |
Pamela |
Hoffmann |
Lena |
| 8 |
10 |
Hoffmann |
Pamela |
Hoffmann |
Sabrina |
| 9 |
8 |
Hoffmann |
Jim |
Hoffmann |
Claudia |
| 9 |
9 |
Hoffmann |
Jim |
Hoffmann |
Lena |
| 9 |
10 |
Hoffmann |
Jim |
Hoffmann |
Sabrina |
| 10 |
11 |
Lenz |
Moritz |
Lenz |
Barbie |
| 11 |
11 |
Rose |
Emma |
Lenz |
Barbie |
| 12 |
12 |
Rose |
Maria |
Rose |
Max |
| 12 |
13 |
Rose |
Maria |
Rose |
Lukas |
| 13 |
14 |
Sturm |
Lorenz |
Sturm |
Niklas |
| 14 |
15 |
Wiese |
Hannes |
Wiese |
Elisabeth |
| 15 |
15 |
Wiese |
Clemenz |
Wiese |
Elisabeth |
| |
|
|
In der zweiten Abfrage werden die Kinder in alphabetischer Reihenfolge mit ihren Förderprogrammen ausgegeben: |
|
|
SELECT ki.name as Name, ki.vorname as VName,
|
|
|
ki.geburtstag as Geburtstag, fo.foerdid, fo.bez as Programm,
|
|
|
fo.anfang as Beginn, fo.ende as Ende
|
|
|
FROM kinder ki, kinderue4 k4, foerdprog fo
|
|
|
where ki.kindid = k4.kindid and k4.foerdprog=fo.foerdid
|
|
|
order by ki.name, fo.foerdid;
|
|
|
|
|
| Name |
VName |
Geburtstag |
foerdid |
Programm |
Beginn |
Ende |
| Hoffmann |
Lena |
2021-01-01 |
1 |
Sprachförderung |
2022-06-01 |
2022-11-30 |
| Hoffmann |
Lena |
2021-01-01 |
2 |
Feinmotorik |
2022-01-05 |
2022-03-22 |
| Hoffmann |
Claudia |
2015-01-01 |
4 |
Reaktionen |
2022-07-26 |
2023-02-19 |
| Hoffmann |
Lena |
2021-01-01 |
4 |
Reaktionen |
2022-07-26 |
2023-02-19 |
| Meier |
Max |
2016-06-12 |
2 |
Feinmotorik |
2022-01-05 |
2022-03-22 |
| Schneider |
Elli |
2017-01-25 |
1 |
Sprachförderung |
2022-06-01 |
2022-11-30 |
| Schneider |
Elli |
2017-01-25 |
3 |
Motivation |
2023-10-13 |
2023-12-24 |
| Sturm |
Niklas |
2018-01-25 |
3 |
Motivation |
2023-10-13 |
2023-12-24 |
| |
4.2 Leitseite für WebAbfragen |
|
Diese und die Aufgaben 4.3 – 4.7 basieren auf dem Datenmodell von Aufgabe 4.1, genauer auf der Relation Kinder. |
|
4.2.1 Aufgabe |
|
Erstellen Sie eine Webseite mit Buttons, die Abfragen auf der Datenbank durchführen, so wie in der folgenden Webseite gezeigt. Diese grafische Bedienoberfläche mit HTML und CSS soll etwa so aussehen: |
|
|
|
Alle Schaltflächen beziehen sich nur auf die Daten der Kinder. Legen Sie für die Buttons folgende Bezeichnungen für die Programme an: |
|
- Daten aller Kinder anzeigen : KiGaTabelle.php
- Neuzugang erfassen: KiGaNeueintrag.php
- Daten eines Kindes löschen: KiGaLoeschen_a.php
- Daten ausgewählter Kinder anzeigen: KiGaName.php
- Daten von Kindern ändern: Ki_aendern_a.php
|
|
4.2.2 Lösung |
|
Die Lösung verlangt für die Leitseite eine HTML-Datei, eine Stylesheet-Datei und die Vorbereitung mehrerer PHP-Dateien. |
|
- Kindergarten.html (für die Leitseite)
- kindergarten.css (für die Stylesheets)
Die Leitseite Kindergarten.html ist vollständig HTML-basiert und hat deshalb ein entsprechendes Suffix. Die Schaltflächen werden fix positioniert, siehe Stylesheets in kindergarten.css. |
|
Kindergarten.html |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title><center>Abfragen zur Datenbank Kindergarten</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<div id='p100'>
|
|
|
<h1>Datenbank KINDERGARTEN</h1>
|
|
|
</div>
|
|
|
<div id='p101'>
|
|
|
<p class="text_1">Daten aller Kinder anzeigen</p>
|
|
|
<form action="KiGaTabelle.php" method="post">
|
|
|
<p><input type="submit" value="Los geht's">
|
|
|
</form>
|
|
|
</div>
|
|
|
<div id='p102'>
|
|
|
<p class="text_1">Neuzugang erfassen</p>
|
|
|
<form action="KiGaNeueintrag.php" method="post">
|
|
|
<p><input type="submit" value="Los geht's">
|
|
|
</form>
|
|
|
</div>
|
|
|
<div id='p106'>
|
|
|
<p class="text_1">Daten eines Kindes lamp;ouml;schen</p>
|
|
|
<form action="KiGaLoeschen_a.php" method="post">
|
|
|
<p><input type="submit" value="Los geht's">
|
|
|
</form>
|
|
|
</div>
|
|
|
<div id='p104'>
|
|
|
<p class="text_1">Daten ausgewamp;auml;hlter Kinder anzeigen.<br>Anfangsbuchstaben eingeben.</p>
|
|
|
<form action="KiGaName.php" method="post">
|
|
|
<input name="anfang"> <input type="submit" value="Los geht's">
|
|
|
</form>
|
|
|
</div>
|
|
|
<div id='p105'>
|
|
|
<p class="text_1"><a href="ki_aendern_a.php">Daten von Kindern amp;auml;ndern</a></p>
|
|
|
</div>
|
|
|
</body>
|
|
|
</html>
|
|
Stylesheet-Datei Kindergarten.css |
|
/*ID-Selektoren für <div... */ |
|
|
#p100 { height:40px; width: 900px;position: absolute; top: 70px; left: 40px; text-align: center;}
|
|
|
#p101 { height:70px; background-color:yellow; width: 440px; border: 1px solid green;position: absolute; top: 130px; left: 110px; text-align: center;}
|
|
|
#p102 { height:70px; background-color:yellow; width: 440px; border: 1px solid green;position: absolute; top: 220px; left: 110px; text-align: center;}
|
|
|
#p106 { height:70px; background-color:yellow; width: 440px; border: 1px solid green; position: absolute; top: 310px; left: 110px; text-align: center;}
|
|
|
#p104 { height:100px; background-color:yellow; width: 440px; border: 1px solid green; position: absolute; top: 130px; left: 490px; text-align: center;}
|
|
|
#p105 { height:40px; background-color:yellow; width: 440px; border: 1px solid green; position: absolute; top: 250px; left: 490px; text-align: center;}
|
|
/*Typ-Selektoren für HTML-Elemente*/ |
|
|
h1 { font-size:16pt; font-weight: bold; text-align: center; font-family: Calibri, Arial, sans-serif; color: blue; margin-bottom:10px; margin-right:0px; margin-top:5px; margin-left:0px;}
|
|
|
p {color: black; font-family: Arial, sans-serif; margin-bottom:10px; margin-right:10px; margin-top:10px; margin-left:10px;}
|
|
|
table {font-family: Arial, sans-serif;}
|
|
|
td {border: 1px solid black; vertical-align: middle; text-align: left;} td {padding: 3px}
|
|
|
thead {font-size: 10pt; color: black; font-family: Arial, sans-serif;}
|
|
/*Klassenselektoren mit Punkt*/ |
|
|
.text_1 { font-family: Arial, sans-serif; font-size:12pt; font-weight: bold; color:black;}
|
|
|
.text_2 { font-family: Arial, sans-serif; font-size:16pt; font-weight: bold;}
|
|
|
.text_3 {font-family: Arial, sans-serif; font-size:14pt; font-weight: bold;}
|
|
|
4.3 Daten aller Kinder anzeigen |
|
Diese Aufgabe basiert auf den Aufgaben 4.1 und 4.2. |
|
Erläutern Sie die notwendigen PHP-Programme, v.a. dort, wo es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.3.1 Aufgabe |
|
Mit dem obersten linken Button der Leitseite wird eine Tabelle mit den Daten aller Kinder ausgegeben. |
|

|
|
Die Tabelle soll so aussehen: |
|
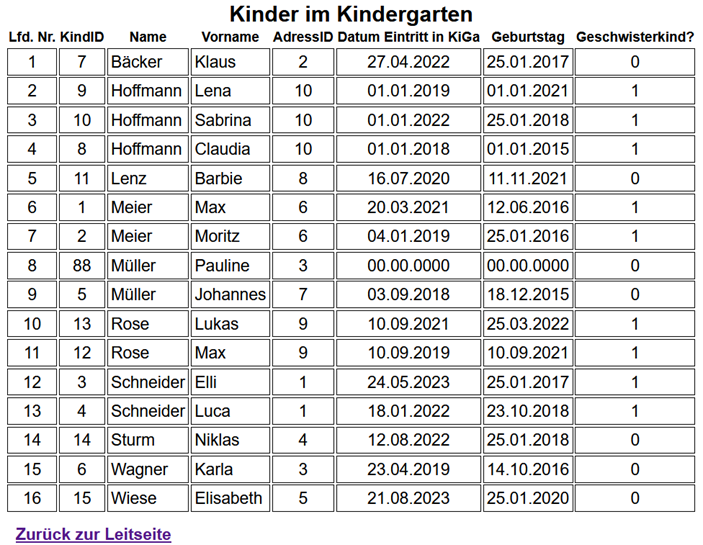
|
|
Erstellen Sie die notwendigen PHP-Programme. Erläutern Sie diese, v.a., wenn es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.3.2 Lösung |
|
Das Programm ist in der Datei KiGaTabelle.php realisiert. Es realisiert den Zugriff von der Webseite auf die Relation mit tabellarischer Ausgabe aller Tupel. Außerdem werden entsprechend der Vorgabe in der Tabelle Spaltenüberschriften vergeben. |
|
KiGaTabelle.php |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Ausgabe in Tabelle</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<table>
|
|
|
<caption class="text_2">Kinder im Kindergarten</caption>
|
|
|
<thead>
|
|
|
<th>Lfd. Nr.</th>
|
|
|
<th>KindID</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
<th>AdressID</th>
|
|
|
<th>Datum Eintritt in KiGa</th>
|
|
|
<th>Geburtstag</th>
|
|
|
<th>Geschwisterkind?</th></thead>
|
|
An den letzten drei Attributen ist zu erkennen, dass die Spaltenüberschriften der Tabelle losgelöst von den Attributsbezeichnungen und auch losgelöst von etwaigen Spaltenüberschriften gestaltet werden können. Allerdings bleibt es dabei: Die Attributsbezeichnungen für die Funktion fetch_assoc() müssen die des SQL-Befehls sein. |
|
|
<?php
|
|
|
include "zeit2.inc.php"; //siehe Anmerkung und Programm unten
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$sql = "SELECT KindID, Name, Vorname, AdressID, Eintrittsdatum, Geburtstag, GKindJN FROM kinder order by name";
|
|
|
$res = $con->execute_query($sql);
|
|
|
$lf = 1;
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><center>$lf</td>";
|
|
|
echo "<td><center>" . $dsatz["KindID"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Name"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Vorname"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["AdressID"] . "</td>";
|
|
|
echo "<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"]) . "</td>";
|
|
|
echo "<td><center>" . db_datum_aus($dsatz["Geburtstag"]) . "</td>";
|
|
|
echo "<td><center>" . $dsatz["GKindJN"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
$lf++;
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Der folgende Link führt zurück zur Leitseite: |
|
|
<p class="text_1"><a href="http://localhost/kindergarten.html">Zuramp;uuml;ck zur Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
Programm zeit2.inc.php |
|
Dieses Programm wird oben eingefügt. Es liefert die Umwandlung von US-Datumsangaben in das deutsche Datumsformat. |
|
|
<?php
|
|
|
function db_datum_aus($db_datum)
|
|
|
{
|
|
|
$feld = mb_split("-", $db_datum);
|
|
|
$tag = intval($feld[2]);
|
|
|
$monat = intval($feld[1]);
|
|
|
$jahr = intval($feld[0]);
|
|
|
$ausgabe = sprintf("%'.02d.%'.02d.%'.04d", $tag, $monat, $jahr);
|
|
|
return $ausgabe;
|
|
|
}
|
|
|
?>
|
|
4.4 Neuzugang erfassen |
|
Diese Aufgabe basiert auf den Aufgaben 4.1 und 4.2. |
|
Erläutern Sie die notwendigen PHP-Programme, v.a. dort, wo es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.4.1 Aufgabe |
|
Mit dem zweiten Button werden die Daten eines neu hinzugekommenen Kindes angelegt. |
|

|
|
Dies erfordert die Abspeicherung von Daten in der Datenbank. Die Erfassungsmaske soll so gestaltet sein: |
|

|
|
Folgendes soll das Programm leisten: |
|
- Erfassen und Abspeichern eines neuen Datensatzes, evtl. auch gleich mehrerer hintereinander.
- Zurücksetzen wegen eventueller Fehleingaben.
- Anzeigen der Relation mit den neuen Daten.
|
|
4.4.2 Lösung |
|
Das Programm wird KiGaNeueintrag.php genannt und ergibt sich wie im Folgenden gezeigt. Der Übersichtlichkeit wegen zuerst das Programm ohne Anmerkungen. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Eingabe von Datensätzen</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
<?php
|
|
|
include "pruefen.inc.php";
|
|
|
if(isset($_POST["gesendet"]))
|
|
|
{
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$fehler=false;
|
|
|
if(int_positiv("Kindid", $_POST["id"], $id))
|
|
|
{
|
|
|
if(id_neu_doppelt("KinderId", $id, $con, "kinder", "kindid"))
|
|
|
$fehler = true;
|
|
|
}
|
|
|
else
|
|
|
$fehler = true;
|
|
|
if(!datum_gueltig("Eintrittsdatum", $_POST["ei"], $ei))
|
|
|
$fehler = true;
|
|
|
if(!datum_gueltig("Geburtstag", $_POST["gt"], $gt))
|
|
|
$fehler = true;
|
|
|
if(!$fehler)
|
|
|
{
|
|
|
$sql = "INSERT INTO kinder" . "(kindid, name, vorname, adressid, eintrittsdatum, geburtstag, gkindjn)"
|
|
|
. "VALUES(?, ?, ?, ?, ?, ?, ?)";
|
|
|
$con->execute_query($sql, [$_POST["id"], $_POST["na"],
|
|
|
$_POST["vn"], $_POST["ad"], $ei, $gt, $_POST["gk"]]);
|
|
|
}
|
|
|
else
|
|
|
echo "<p><big>Kein Datensatz eingetragen</p></big>";
|
|
|
$con->close();
|
|
|
}
|
|
|
?>
|
|
|
</head>
|
|
|
<body>
|
|
|
<p>Geben Sie bitte einen Datensatz ein<br>und senden Sie
|
|
|
das Formular ab:</p>
|
|
|
<form action="KiGaneueintrag.php" method="post">
|
|
|
<p><input type="text" name="id"> KindID</p>
|
|
|
<p><input type="text" name="na"> Name</p>
|
|
|
<p><input name="vn"> Vorname</p>
|
|
|
<p><input name="ad"> AdressID (eine ganze Zahl, 1 - 10)</p>
|
|
|
<p><input name="ei"> Eintrittsdatum (in T.M.JJJJ)</p>
|
|
|
<p><input name="gt"> Geburtstag (in T.M.JJJJ)
|
|
|
<p><input name="gk"> Geschwisterkind: 1 (ja), 0 (nein)</p>
|
|
|
<p><input type="submit" name="gesendet">
|
|
|
<input type="reset"></p>
|
|
|
</form>
|
|
|
<p>Alle Daten <a href="kigaAlleKi.php">anzeigen</a></p>
|
|
|
<p class="text_1">Zuramp;uuml;ck zur
|
|
|
<a href="http://localhost/kindergarten.html">Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
Nun das Programm mit Erläuterungen |
|
Zu Beginn des PHP-Abschnitts wird die Datei pruefen.inc.php eingefügt. Sie enthält mehrere Funktionen zum Prüfen der Eingaben in die Felder. |
|
|
include "pruefen.inc.php";
|
|
Mit der Funktion isset() kann geprüft werden, ob eine Variable existiert und welchen Wert sie hat. Dies wird hiergenutzt, um festzustellen, ob das untenstehende Erfassungsformular schon mal gesendet wurde. Dazu erhält das Formular die Bezeichnung gesendet. Dieses ist erstmal false, nach dem ersten Senden hat es den Wert true. |
|
|
if(isset($_POST["gesendet"]))
|
|
|
{
|
|
Im positiven Fall wird die Verknüpfung hergestellt: |
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$fehler=false;
|
|
Nachfolgend erfolgt die Prüfung, ob die Eingabe in KindId (sie erhält unten die Bezeichnung id) eine positive ganze Zahl ist. Dazu wird eine Funktion aus pruefen.inc.php benutzt. |
|
|
if(int_positiv("Kindid", $_POST["id"], $id))
|
|
|
{
|
|
Falls ja, wird geprüft, ob die KinderId schon da ist. |
|
|
if(id_neu_doppelt("KinderId", $id, $con, "kinder", "kindid"))
|
|
|
$fehler = true;
|
|
|
}
|
|
|
else
|
|
|
$fehler = true;
|
|
Es folgt die Prüfung des angegebenen Eintrittsdatums durch eine Funktion aus pruefen.inc.php. |
|
|
if(!datum_gueltig("Eintrittsdatum", $_POST["ei"], $ei))
|
|
|
$fehler = true;
|
|
Ebenso zum Geburtstag. |
|
|
if(!datum_gueltig("Geburtstag", $_POST["gt"], $gt))
|
|
|
$fehler = true;
|
|
Falls die Variable $fehler auf false steht ("if (!$fehler)") kann nun die Verbindung zwischen Webseite und Datenbank hergestellt werden. Das Formular ist ja dank der isset-Prüfung auf jeden Fall beschrieben. |
|
Im Formular unten wurde für jedes Feld eine Bezeichnung vergeben. Z.B. |
|
|
<p><input type="text" name="id"> #KindID</p>
|
|
In $_POST["id"] steht dann der Wert von KindId. |
|
Damit wird dann die Verknüpfung wie folgt realisiert: Zuerst der SQL-Befehl insert into. An den Stellen, wo dann normalerweise die einzutragenden Werte stehen, werden Fragezeichen eingefügt. Für jeden Werte eines. |
|
|
if(!$fehler)
|
|
|
{
|
|
|
$sql = "INSERT INTO kinder" . "(kindid, name, vorname, adressid,
|
|
|
eintrittsdatum, geburtstag, gkindjn)"
|
|
|
. "VALUES(?, ?, ?, ?, ?, ?, ?)";
|
|
Bei der nachfolgenden Ausführung des Befehls in der Datenbank werden die geposteten Werte in derselben Reihenfolge, wie im übrigen SQL-Befehl angelegt, in die VALUES-Liste eingefügt. Damit ist ein sog. Prepared Statement umgesetzt. |
|
|
$con->execute_query($sql, [$_POST["id"], $_POST["na"], $_POST["vn"],
|
|
|
$_POST["ad"], $ei, $gt, $_POST["gk"]]);
|
|
|
}
|
|
Prepared Statement |
|
Man könnte die geposteten Werte im INSERT INTO-Befehl auch direkt eingeben, was aber Schwierigkeiten machen und der sog. SQL Injection (Hacker-Angriff) den Weg öffnen würde. Dies verhindern die sog. Prepared Statements. Dabei handelt es sich um ein Konstrukt in PHP, dessen Hauptmotiv die Verhinderung von SQL Injection ist. Vgl. [Theis 2023, Abschnitt 3.7] sowie [Wenz und Hauser 2021, Abschnitt 33.3]. |
|
Bei den Werten, die schon einer Prüfung unterzogen wurden ($ei, $gt), kann auf $_POST verzichtet werden, da sie von den Prüffunktionen über Referenzparameter zurückgegeben werden. |
|
Die folgende Abbildung verdeutlicht diese Zuordnung. |
|
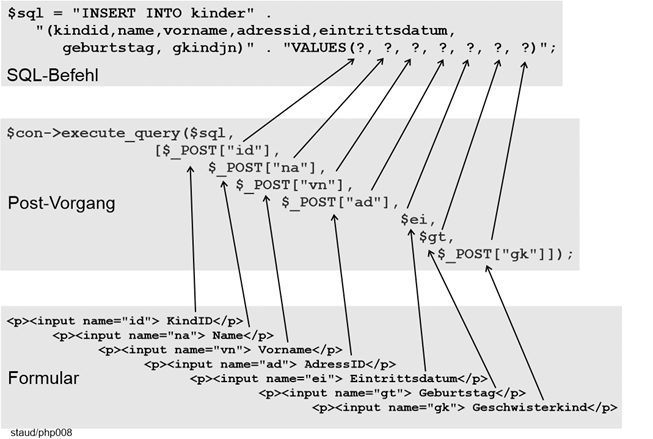
|
|
Abbildung 4.4-1: Datensätze erzeugen mit einem Prepared Statement. |
|
Weiter im Programm: |
|
|
else
|
|
|
echo "<p><big>Kein Datensatz eingetragen</p></big>";
|
|
|
$con->close();
|
|
|
}
|
|
|
?>
|
|
|
</head>
|
|
Im Body-Teil folgt das Formular für die Datenerfassung. |
|
- Das Attribut action verweist auf das PHP-Auswertungsprogramm KiGaNeueintrag.php. D.h., hier ruft das Formular das "eigene" Programm auf. Dadurch können mehrere neue Einträge hintereinander getätigt werden.
- Das Attribut method gibt die Übermittlungsmethode zum Webserver (post) an.
- Es folgen die Texteingabefelder. Das Attribut name gibt dabei jeweils eine Kurzbezeichnung für jedes Attribut an, die im Befehl execute_query benötigt wird. Vgl. auch die Abbildung oben.
- Die Absende-Schaltfläche wird durch <input type="submit" name="gesendet"> angefordert. Hier wird die Bezeichnung vergeben, die oben mit isset benötigt wird.
- Abschließend wird die Schaltfläche für das Zurücksetzen mit <input type="reset"> angefordert.
|
|
|
<body>
|
|
|
<p>Geben Sie bitte einen Datensatz ein<br>und senden Sie das Formular ab:</p>
|
|
|
<form action="KiGaneueintrag.php" method="post">
|
|
|
<p><input type="text" name="id"> KindID</p>
|
|
|
<p><input type="text" name="na"> Name</p>
|
|
Bei diesem input type kann type=“text“ auch weggelassen werden: |
|
|
<p><input name="vn"> Vorname</p>
|
|
|
<p><input name="ad"> AdressID (eine ganze Zahl)</p>
|
|
|
<p><input name="ei"> Eintrittsdatum (in T.M.JJJJ)</p>
|
|
|
<p><input name="gt"> Geburtstag (in T.M.JJJJ)</p>
|
|
|
<p><input name="gk"> Geschwisterkind: 1 (ja), 0 (nein)</p>
|
|
|
<p><input type="submit" name="gesendet">
|
|
|
<input type="reset"></p>
|
|
|
</form>
|
|
Es folgt der Link für das Programm zum Anzeigen aller Daten der Relation. |
|
|
<p>Alle Daten <a href="kigaAlleKi.php">anzeigen</a></p>
|
|
Ein weiterer Link führt zur Leitseite zurück. |
|
|
<p class="text_1">Zuramp;uuml;ck zur <a href="http://localhost/kindergarten.html">Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
Programm Pruefen.inc.php |
|
Diese Datei enthält die oben und in den folgenden Programmen benötigten Prüffunktionen für Eingaben. Sie wird von Theis in [Theis 2023] zur Verfügung gestellt (siehe [Theis 2023, S. 210]). |
|
|
<?php
|
|
|
function int_positiv($bereich, $text, amp;$zahl)
|
|
|
{
|
|
|
if(!is_numeric($text))
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>$bereich: Zahl eintragen</p>";
|
|
|
return false;
|
|
|
}
|
|
|
if($text == "0")
|
|
|
{
|
|
|
$zahl = 0;
|
|
|
return true;
|
|
|
}
|
|
|
$zahl = intval($text);
|
|
|
if($zahl < 0)
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>" . "$bereich: Ganze Zahl >= 0 eintragen</p>";
|
|
|
return false;
|
|
|
}
|
|
|
else
|
|
|
return true;
|
|
|
}
|
|
|
function id_neu_doppelt($bereich, $pk, $con, $tab, $feld)
|
|
|
{
|
|
|
$sql = "SELECT * FROM $tab WHERE $feld = ?";
|
|
|
$res = $con->execute_query($sql, [$pk]);
|
|
|
$anzahl = $res->num_rows;
|
|
|
$res->close();
|
|
|
if($anzahl > 0)
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>$bereich: Bereits vorhanden</p>";
|
|
|
return true;
|
|
|
}
|
|
|
else
|
|
|
return false;
|
|
|
}
|
|
|
function datum_gueltig($bereich, $datum, amp;$gt)
|
|
|
{
|
|
|
$feld = mb_split("\.", $datum);
|
|
|
if(count($feld) != 3)
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>". "$bereich: Datum in T.M.JJJJ eintragen</p>";
|
|
|
return false;
|
|
|
}
|
|
|
if(!is_numeric($feld[0]) || !is_numeric($feld[1]) || !is_numeric($feld[2]))
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>". "$bereich: Zahlen für Tag, Monat und Jahr eintragen</p>";
|
|
|
return false;
|
|
|
}
|
|
|
$tag = intval($feld[0]);
|
|
|
$monat = intval($feld[1]);
|
|
|
$jahr = intval($feld[2]);
|
|
|
if(checkdate($monat, $tag, $jahr))
|
|
|
{
|
|
|
$gt = $jahr . "-" . $monat . "-" . $tag;
|
|
|
return true;
|
|
|
}
|
|
|
else
|
|
|
{
|
|
|
echo "<p style='color:#ff0000;'>" . "$bereich: Gültiges Datum eintragen</p>";
|
|
|
return false;
|
|
|
}
|
|
|
}
|
|
|
?>
|
|
Programm KiGaAlleKi.php |
|
Dieses Programm dient zur Ausgabe aller Datensätze nach einem Neueintrag. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Ausgabe in Tabelle</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<table>
|
|
|
<tr>
|
|
|
<td>KindID</td>
|
|
|
<td>Name</td>
|
|
|
<td>Vorname</td>
|
|
|
<td>AdressID</td>
|
|
|
<td>Eintrittsdatum</td>
|
|
|
<td>Geburtstag</td>
|
|
|
<td>GKind JN</td>
|
|
|
</tr>
|
|
|
<?php
|
|
|
include "zeit2.inc.php";
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$sql = "SELECT * FROM kinder";
|
|
|
$res = $con->execute_query($sql);
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><center>" . $dsatz["KindID"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Name"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Vorname"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["AdressID"] . "</td>";
|
|
|
echo "<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"]) . "</td>";
|
|
|
echo "<td><right>" . db_datum_aus($dsatz["Geburtstag"]) . "</td>";
|
|
|
echo "<td><center>" . $dsatz["GKindJN"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
|
<p class="text_1"><a href="http://localhost/kindergarten.html">
|
|
|
Zuramp;uuml;ck zur Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
4.5 Daten eines Kindes löschen |
|
Diese Aufgabe basiert auf den Aufgaben 4.1 und 4.2. |
|
Erläutern Sie die notwendigen PHP-Programme, v.a. dort, wo es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.5.1 Aufgabe |
|
Der dritte Button soll erlauben, die Daten eines Kindes zu löschen. |
|

|
|
Dazu soll zuerst in einer Gesamttabelle das betreffende Kind ausgewählt werden: |
|
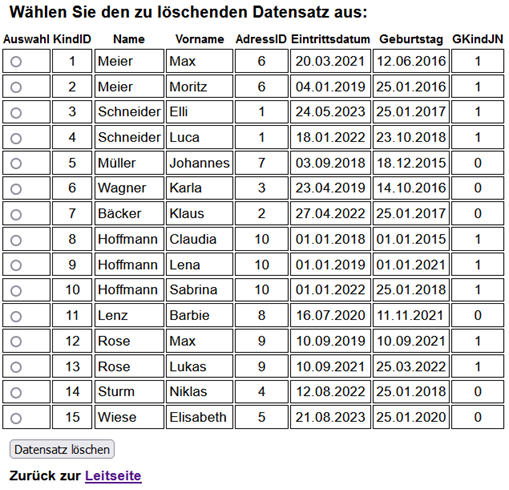
|
|
Nach Wahl eines Datensatzes und Anforderung der Löschung soll diese durchgeführt werden. |
|
4.5.2 Lösung |
|
Das Gesamtprogramm ist in zwei Dateien aufgeteilt, KiGaLoeschen_a.php und KiGaLoeschen_b.php. |
|
Programm KiGaLoeschen_a.php. |
|
In diesem Programm erfolgt der Aufbau des Formulars. |
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Datensatz auswählen</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<p class="text_3">Wamp;auml;hlen Sie den zu lamp;ouml;schenden Datensatz aus:</p>
|
|
Folgende Zeile legt fest, was beim "Submit" passiert. Es wird die zweite Datei aufgerufen, in der die Datenbankaktionen festgelegt sind. |
|
|
<form action="KiGaloeschen_b.php" method="post">
|
|
|
<table>
|
|
|
<thead>
|
|
|
<th>Auswahl</th>
|
|
|
<th>KindID</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
<th>AdressID</th>
|
|
|
<th>Eintrittsdatum</th>
|
|
|
<th>Geburtstag</th>
|
|
|
<th>GKindJN</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
include "zeit2Auf diese .inc.php";
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$sql = "SELECT * FROM kinder";
|
|
|
$res = $con->execute_query($sql);
|
|
Jetzt stehen die gemäß der SQL-Abfrage gehosteten Attribute und ihre Ausprägungen in der assoziativen Variablen $dsatz zur Verfügung. |
|
Mit … |
|
|
input type='radio' name='auswahl'
|
|
wird das Auswahlmenü angefordert. |
|
Weiter im Programm: |
|
|
while($dsatz = $res->fetch_assoc())
|
|
Das Formular erhält die Bezeichnung auswahl. Damit wird vor dem Löschvorgang in KiGaLoeschen_b.php geprüft, ob wirklich eine Auswahl für den zu löschenden Datensatz getroffen wurde. |
|
|
echo "<tr><td><input type='radio' name='auswahl'"
|
|
|
. " value='" . $dsatz["KindID"] . "'></td>"
|
|
|
. "<td><center>" . $dsatz["KindID"] . "</td>"
|
|
|
. "<td>" . $dsatz["Name"] . "</td>"
|
|
|
. "<td>" . $dsatz["Vorname"] . "</td>"
|
|
|
. "<td><center>" . $dsatz["AdressID"] . "</td>"
|
|
|
. "<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"]) . "</td>"
|
|
|
. "<td>" . db_datum_aus($dsatz["Geburtstag"]) . "</td>"
|
|
|
. "<td><center>" . $dsatz["GKindJN"] . "</td></tr>";
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Die folgende Schaltfläche erlaubt es den Löschvorgang zu starten. |
|
|
<p><input type="submit" value="Datensatz lamp;ouml;schen"></p>
|
|
|
<p class="text_1">Zuramp;uuml;ck zur <a href="http://localhost:80/kindergarten.html">Leitseite</a></p>
|
|
|
</form>
|
|
|
</body>
|
|
|
</html>
|
|
Programm KiGaLoeschen_b.php |
|
Hier wird das Löschen des Datensatzes durchgeführt. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Datensatz loeschen</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<?php
|
|
Prüfen, ob Auswahl getroffen wurde: |
|
|
if(isset($_POST["auswahl"]))
|
|
|
{
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
Lösche-Befehl in $sql speichern und ausführen: |
|
|
$sql = "delete from kinder where kindid= " . intval($_POST["auswahl"]);
|
|
|
$res = $con->execute_query($sql);
|
|
|
echo "<p>Datensatz ist gelamp;ouml;scht</p>";
|
|
|
}
|
|
|
else
|
|
|
echo "<p>Keine Auswahl getroffen</p>";
|
|
|
?>
|
|
Das Programm KiGaAlleKi wurde oben beschrieben. |
|
|
<p>Alle Daten <a href="kigaAlleKi.php">anzeigen</a></p>
|
|
|
<p class="text_1"><a href="http://localhost:80/kindergarten.html">Zuramp;uuml;ck zur Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
4.6 Daten ausgewählter Kinder anzeigen |
|
Diese Aufgabe basiert auf den Aufgaben 4.1 und 4.2. |
|
Erläutern Sie die notwendigen PHP-Programme, v.a. dort, wo es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.6.1 Aufgabe |
|
Diese Schaltfläche soll erlauben, die Datensätze bestimmter Kinder, ausgewählt nach den Anfangsbuchstaben des Namens, auszuwählen und auszugeben. |
|
|
|
Das Ergebnis soll, bei Wahl des Anfangsbuchstabens S, so aussehen: |
|
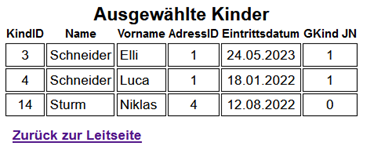
|
|
4.6.2 Lösung |
|
Das Programm KiGaName.php leistet das Gewünschte. Neu hinzu kommt gegenüber den obigen Beispielen der Maskierungsoperator LIKE im SQL-Statement. |
Programm KiGaName.php |
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Auswahl mit Namensanfang</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<table>
|
|
|
<caption class="text_2">Ausgewamp;auml;hlte Kinder</caption>
|
|
|
<thead>
|
|
|
<th>KindID</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
<th>AdressID</th>
|
|
|
<th>Eintrittsdatum</th>
|
|
|
<th>GKind JN</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
include "zeit2.inc.php";
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
Der Zugriff von der Webseite auf die (Server-Datenbank) erfolgt wieder mit einem Prepared Statement. |
|
|
$sql = "SELECT KindID, Name, Vorname, AdressID, Eintrittsdatum,
|
|
|
GKindJN FROM kinder where Name like ?";
|
|
|
$anfang = $_POST["anfang"] . "%";
|
|
|
$res = $con->execute_query($sql, [$anfang]);
|
|
Prüfung der Zahl der Treffer. |
|
|
if($res->num_rows == 0)
|
|
|
echo "<br>Keine Ergebnisse<br><br>";
|
|
Obige Prüfung sollte bei Abfragen der Datenbank immer erfolgen. Sie wurde hier aus Platzgründen meist weggelassen. |
|
Falls keine Treffer vorliegen, startet die While-Schleife nicht. |
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><center>" . $dsatz["KindID"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Name"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Vorname"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["AdressID"] . "</td>";
|
|
|
echo "<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"])
|
|
|
. "</td>";
|
|
|
echo "<td><center>" . $dsatz["GKindJN"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
|
<p class="text_1"><a href="http://localhost/kindergarten.html"> Zuramp;uuml;ck zur Leitseite</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
4.7 Daten von Kindern ändern |
|
Diese Aufgabe basiert auf den Aufgaben 4.1 und 4.2. |
|
Erläutern Sie die notwendigen PHP-Programme, v.a. dort, wo es um die Verknüpfung von Datenbank und Webseite geht. |
|
4.7.1 Aufgabe |
|
Die folgende Schaltfläche soll erlauben, die Daten eines Kindes zu ändern. |
|

|
|
4.7.2 Lösung |
|
Die Lösung ist auf drei Programme verteilt: |
|
- ki_aendern_a.php
- ki_aendern_b.php
- ki_aendern_c.php
|
|
Ki_aendern_a.php |
|
Das erste Programm fordert eine Auswahlliste mit Radiobuttons an, wie schon in Abschnitt 2.7 vorgestellt. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Datensatz auswählen</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<p class="text_3">Treffen Sie Ihre Auswahl:</p>
|
|
Am Anfang des Formulars wird über den Parameter action festgelegt, was bei submit zu tun ist und über method mit welcher Methode dies geschehen soll. |
|
|
<form action="ki_aendern_b.php" method="post">
|
|
|
<table>
|
|
|
<thead>
|
|
|
<th>Auswahl</th>
|
|
|
<th>KindID</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
<th>AdressID</th>
|
|
|
<th>Eintrittsdatum</th>
|
|
|
<th>Geburtstag</th>
|
|
|
<th>GKindJN</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
include "zeit2.inc.php";
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
$sql = "SELECT * FROM kinder";
|
|
|
$res = $con->execute_query($sql);
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
Anforderung Auswahl-Button (type='radio') mit Bezeichnung auswahl: |
|
|
echo "<tr><td><input type='radio' name='auswahl'" .
|
|
|
" value='" . $dsatz["KindID"] . "'></td>" .
|
|
|
"<td><center>" . $dsatz["KindID"] . "</td>"
|
|
|
"<td>" . $dsatz["Name"] . "</td>" .
|
|
|
"<td>" . $dsatz["Vorname"] . "</td>" .
|
|
|
"<td><center>" . $dsatz["AdressID"] . "</td>"
|
|
|
"<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"]) .
|
|
|
"</td>" .
|
|
|
"<td>" . db_datum_aus($dsatz["Geburtstag"]) . "</td>" .
|
|
|
"<td><center>" . $dsatz["GKindJN"] . "</td></tr>"; .
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Mit submit wird – siehe oben – das Programm ki_aendern_b.php aufgerufen. |
|
|
<p><input type="submit" value="Datensatz anzeigen"></p>
|
|
|
<p class="text_1">Zuramp;uuml;ck zur <a href="http://localhost/kindergarten.html">Leitseite</a></p>
|
|
|
</form>
|
|
|
</body>
|
|
|
</html>
|
|
Das Programm führt zu folgender Ausgabe: |
|
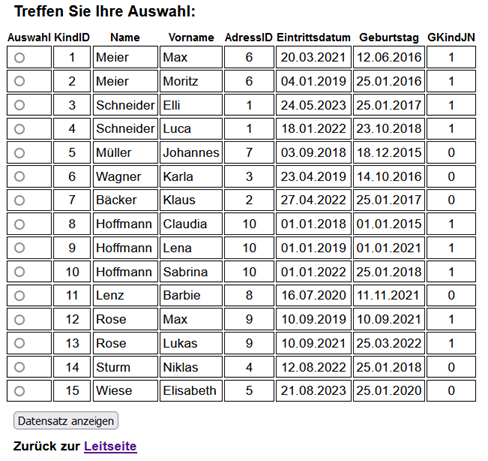
|
|
Wurde ein Datensatz gewählt und dann die Schaltfläche Datensatz anzeigen angeklickt, startet das folgende Programm. |
|
Ki_aendern_b.php |
|
Dies führt zu folgender Ausgabe, falls Moritz Meier angewählt wurde. |
|
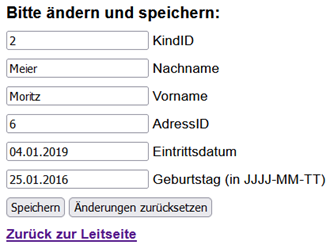
|
|
Hier das Programm: |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Datensatz anzeigen</title>
|
|
|
</head>
|
|
|
<body>
|
|
|
<?php
|
|
Für die Umstellung des Datums: |
|
|
include "zeit2.inc.php";
|
|
|
if(isset($_POST["auswahl"]))
|
|
|
{
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
Hier wird im SQL-Befehl das Ergebnis des Post-Vorgangs (die KindID), abgesichert als Integer-Wert eingesetzt. |
|
|
$sql = "SELECT * FROM kinder WHERE KindID = "
|
|
|
. intval($_POST["auswahl"]);
|
|
|
$res = $con->execute_query($sql);
|
|
|
$dsatz = $res->fetch_assoc();
|
|
|
echo "<p class='text_3'>Bitte amp;auml;ndern und speichern:</p>";
|
|
Wiederum wird als Aktion ein Programm aufgerufen (zum Ändern des Datensatzes) und die zu verwendende Methode spezifiziert. |
|
|
echo "<form action='ki_aendern_c.php' method='post'>";
|
|
|
echo "<p><input name='id' value='" . $dsatz["KindID"]
|
|
|
. "'> KindID</p>";
|
|
|
echo "<p><input name='na' value='" . $dsatz["Name"]
|
|
|
. "'> Nachname</p>";
|
|
|
echo "<p><input name='vn' value='" . $dsatz["Vorname"]
|
|
|
. "'> Vorname</p>";
|
|
|
echo "<p><input name='ad' value='" . $dsatz["AdressID"]
|
|
|
. "'> AdressID</p>";
|
|
|
echo "<p><input name='ei' value='" .
|
|
|
db_datum_aus($dsatz["Eintrittsdatum"]) . "'>Eintrittsdatum</p>";
|
|
|
echo "<p><input name='gt' value='" .
|
|
|
db_datum_aus($dsatz["Geburtstag"]) . "'>
|
|
|
Geburtstag (in JJJJ-MM-TT)</p>";
|
|
|
echo "<input type='hidden' name='oripn' value='" .
|
|
|
$_POST["auswahl"] . "'>";
|
|
|
echo "<p><input type='submit' value='Speichern'>
|
|
|
<input type='reset' value='amp;Auml;nderungen zurücksetzen'></p>";
|
|
|
echo "</form>";
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
}
|
|
|
else
|
|
|
echo "<p>Keine Auswahl getroffen</p>";
|
|
|
?>
|
|
|
<p class="text_1"><a href="http://localhost/kindergarten.html">
|
|
|
Zuramp;uuml;ck zur Leitseite</a></p>
|
|
|
</body>
|
|
|
</html></body>
|
|
|
</html>
|
|
Ki_aendern_c.php |
|
Dieses Programm führt mit Hilfe eines Update-Befehls die Änderung durch. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Datensatz ändern</title>
|
|
|
<link rel="stylesheet" type="text/css" href="kindergarten.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<?php
|
|
|
include "pruefen.inc.php";
|
|
|
$con = new mysqli("localhost", "root", "", "kindergarten");
|
|
|
echo "<p class='text_3'>Datensatz geändert!<br>";
|
|
Wieder ein Prepared Statement: |
|
|
$sql = "UPDATE kinder SET kindid= ?, name = ?, vorname = ?," .
|
|
|
" adressid = ?, eintrittsdatum = ?, geburtstag = ?" .
|
|
|
" WHERE kindid = " . $_POST["oripn"];
|
|
|
$con->execute_query($sql, [$_POST["id"], $_POST["na"],
|
|
|
$_POST["vn"], $_POST["ad"], $_POST["ei"], $_POST["gt"]]);
|
|
|
$con->close();
|
|
|
?>
|
|
|
<p>Zur <a href="ki_aendern_a.php">Auswahl</a></p>
|
|
|
</body>
|
|
|
</html>
|
|
|
|
5 Relationale Theorie |
|
Für eine umfassende Einführung in die relationale Modellierung vgl. [Staud 2021]: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
Auszüge finden sich auf http://www.staud.info/rm1/rm_t_1.htm |
|
Aufbau von Relationen |
|
In [Staud 2021, Kapitel 4] wird der Aufbau von Relationen erläutert. Hieraus nur eine Abbildung, die den Aufbau von Relationen und die hier gewählte Begrifflichkeit erläutert. Sie zeigt auch, dass zwischen beliebigen Tabellen und Relationen große Unterschiede bestehen. |
|
g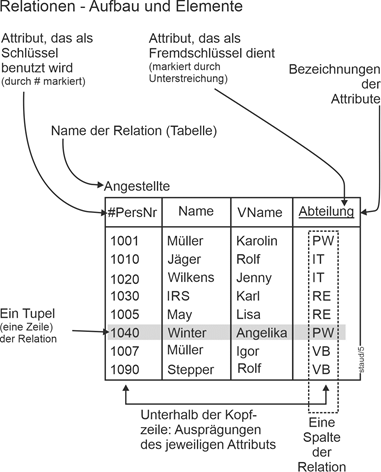 |
|
Abbildung 4.7-1: Aufbau von Relationen. Quelle: [Staud 2019, S. 57] |
|
Abkürzungen: |
|
VName: Vorname |
|
PW: Personalwesen, IT: IT-Abteilung, RE: Rechnungswesen, PW: Personalwesen, VB: Vertrieb |
|
Die Antwort auf die Frage „Durch welche Eigenschaften wird eine Tabelle zu einer Relation?“ findet sich in Aufgabe 5.1. |
|
Rollen von Attributen |
|
Attribute können folgende "Rollen" in Relationen annehmen (vgl. [Staud 2021, S. 117ff]): |
|
- Schlüssel
- Schlüsselkandidaten (candidate keys). Identifizierende Attribute, die nicht als Schlüssel eingesetzt werden.
- Teil eines zusammengesetzten Schlüssels, dann werden sie Schlüsselattribute (SA) genannt
- Attribute außerhalb des Schlüssels/der Schlüssel. Diese werden Nichtschlüsselattribute (NSA) genannt
- Determinanten. Attribute, von denen andere funktional abhängig sein können.
|
|
Zur Veranschaulichung hier ein FA-Diagramm (Diagramm der funktionalen Abhängigkeiten) einer Relation zu Aufträgen (Aufträge_1NF) bei der die Determinanten (D), Schlüsselattribute (SA) und Nichtschlüsselattribute (NSA) markiert sind. |
|
|
|
Abbildung 4.7-2: Schlüsselattribute (SA), Nichtschlüsselattribute (NSA) und Determinanten (D) in Aufträge_1NF. Quelle: [Staud 2021, S. 118] |
|
Abkürzungen: |
|
AuftrNr: Auftragsnummer |
|
PosNr: Positionsnummer |
|
AuftrDatum: Auftragsdatum |
|
KuNr: Kundennummer |
|
KuName: Kundenname |
|
ProdNr: Produktnummer |
|
ProdBez: Produktbezeichnung |
|
Nun zu den Aufgaben. |
|
|
|
5.1 Relation - Eigenschaften |
|
5.1.1 Aufgabe |
|
Durch welche Eigenschaften wird eine Tabelle zu einer Relation? |
|
5.1.2 Lösung |
|
Folgende Eigenschaften sind dafür verantwortlich: |
|
|
(1) Jede Zeile (auch "Reihe" oder "Tupel") beschreibt ein Objekt (bzw. eine Beziehung), die Tabelle als Ganzes beschreibt die Objekt- oder Beziehungsklasse.
|
|
|
(2) In jeder Spalte steht als Kopf der Name eines Attributs, darunter stehen die Attributsausprägungen, die das jeweilige Objekt (die Beziehung) beschreiben.
|
|
|
(3) Eine Relation hat immer einen Schlüssel, der auch aus mehr als einem Attribut bestehen kann, und mindestens ein beschreibendes Attribut.
|
|
|
(4) Es gibt keine zwei identischen Tupel, d.h. jedes Tupel beschreibt ein anderes Objekt.
|
|
|
(5) Im Schnittpunkt jeder Zeile und Spalte wird genau eine Attributsausprägung festgehalten, nicht mehr. Dies macht die Tabelle zur flachen Tabelle.
|
|
|
Vgl. [Staud 2021, Abschnitt 4.2]
|
|
5.2 Funktionale Abhängigkeiten |
|
5.2.1 Aufgabe |
|
Wie sind funktionale Abhängigkeiten definiert? Erläutern Sie auch mit Hilfe aussagekräftiger Beispiele. |
|
5.2.2 Lösung |
|
Funktionale Abhängigkeit basiert auf der Semantik des Anwendungsbereichs und bezieht sich auf das Verhältnis zweier Attribute. Ein Attribut A2 ist funktional abhängig von einem Attribut A1, wenn von den Ausprägungen bei A1 auf die von A2 geschlossen werden kann. Es besteht also ein entsprechender inhaltlicher Zusammenhang. Die Notation: |
Definition FA |
A1 => A2 |
|
A1 determiniert A2, A1 ist Determinante für A2. Vgl. [Staud 2021, Kapitel 8] für detailliertere Ausführungen. |
|
Beispiele: |
|
BezAbteilung => AbtLeiter //Von der Bezeichnung der Abteilung kann auf den Abteilungsleiter geschlossen werden. |
|
PersNr => Wohnort //Von der Personalnummer kann auf den Wohnort geschlossen werden bzw. für eine Personalnummer gibt es genau einen Wohnort. Sollten die Angestellten auch mehrere Adressen in der Firmendatenbank angeben können, wäre diese funktionale Abhängigkeit nicht da. |
|
(PosNr, ReNr) => ArtNr //Von Rechnungsnummer UND Positionsnummer kann auf die Artikelnummer geschlossen werden bzw. für eine Kombination von Rechnungsnummer und Positionsnummer gibt es genau eine Artikelnummer. |
|
ArtNr => Preis //Von der Artikelnummer kann auf den Peis geschlossen werden bzw. für eine Artikelnummer gibt es genau einen Preis. |
|
5.3 3NF - Definition |
|
5.3.1 Aufgabe |
|
|
a) Wie ist die 3NF definiert?
|
|
|
b) Geben Sie textlich ein inhaltlich tragfähiges Beispiel einer Relation an, die in 2NF und nicht in 3NF ist.
|
|
5.3.2 Lösung |
|
a) |
|
Die 3NF beseitigt funktionale Abhängigkeiten zwischen Nichtschlüsselattributen (NSA). Solche führen insgesamt – vom Schlüssel über die zwei Nichtschlüsselattribute – zu transitiven Abhängigkeiten. Deshalb kann die 3NF so definiert werden: |
Definition 3NF |
Eine Relation ist in 3NF, falls sie in 2NF ist und falls keine transitiven Abhängigkeiten zwischen dem Schlüssel und den Nichtschlüsselattributen vorliegen. |
|
Vgl. [Staud 2021, Abschnitt 10.5]. |
|
b) |
|
Rechnungsköpfe (#RechNr, RechDatum, KundenNr, Kundenname) |
|
Begründung: 2NF ist erfüllt, da es keinen zusammengesetzten Schlüssel gibt. Die 3NF wird durch folgende transitive Abhängigkeit verhindert: RechNr => KundenNr => KundenName, d.h. der Name des Kunden wird jedesmal erfasst, wenn in einer Rechnung seine Kundennummer benötigt wird. |
|
5.4 2NF - Definition |
|
5.4.1 Aufgabe |
|
|
a) Wie ist die 2NF definiert?
|
|
|
b) Geben Sie textlich ein inhaltlich tragfähiges Beispiel einer Relation an, die in 1NF und nicht in 2NF ist.
|
|
5.4.2 Lösung |
|
a) |
|
Die 2NF beseitigt funktionale Abhängigkeiten zwischen Schlüsselattributen (Teilen des Schlüssels) und Nichtschlüsselattributen (NSA): „SA => NSA“. Für solche Schlüsselattribute gilt, dass Attributsausprägungen auch mehrfach vorkommen können. Dann taucht auch jedesmal dieselbe Ausprägung beim NSA auf, was redundant ist. |
|
b) |
|
Das Beispiel betrifft Projektmitarbeit. Diese hat einen Schlüssel aus Angestelltennummer (AngNr) und Projektbezeichnung (ProjBez). Die 1NF kann angenommen werden. |
|
Projektmitarbeit (#(AngNr, ProjNr), Beginn, ProjBez) |
|
Die 2NF ist nicht erfüllt, denn es gilt: ProjNr => ProjBez, d.h. die Projektbezeichnung ist funktional abhängig von der Projektnummer und wird, da in diesem Schlüssel eine Projektnummer natürlich mehrfach vorkommen kann, mehrfach gespeichert. |
|
5.5 Normalisierung - Angestellte |
|
5.5.1 Aufgabe |
|
Folgende Relation ist gegeben: |
|
Angestellte (#(PersNr, ProgSprBez), BezCompiler, Name, Vorname) |
|
Hinweis : ProgSprBez bedeutet Bezeichnung einer Programmiersprache. BezCompiler bedeutet Bezeichnung des Compilers, der für die Programmiersprache im Unternehmen genutzt wird. |
|
|
a) Erstellen Sie ein FA-Diagramm dieser Relation. Vermerken Sie bei jedem Attribut, welche Rolle es hat (NSA, Schlüssel, usw.).
|
|
|
b) In welcher NF ist diese Relation? Bitte begründen.
|
|
|
c) Beschreiben Sie, wo bei dieser Relation Redundanz steckt.
|
|
|
d) Normalisieren Sie! Das Ergebnis soll in 3NF sein. Geben Sie für jede Ergebnisrelation ein FA-Diagramm an. Geben Sie in jedem entstehenden FA-Diagramm für jedes Attribut seine Rolle an. Kennzeichnen Sie eventuelle Fremdschlüssel.
|
|
5.5.2 Lösungen |
|
a) |
|
|
|
Abbildung 5.5-1: FA-Diagramm der Relation Angestellte mit Rollen von Attributen |
|
S: Schlüssel, SA: Schlüsselattribut, NSA: Nichtschlüsselattribut, D: Determinante |
|
b) |
|
1NF, nicht 2NF, da Schlüsselattribute Determinanten sind. |
|
c) |
|
Es wird z.B. mehrfach erfasst, welchen Namen eine Person hat, wenn sie mehrere Programmiersprachen beherrscht. Genauso wird mehrfach erfasst, welchen Compiler das Unternehmen für die jeweilige Programmiersprache nutzt, falls mehrere Mitarbeiter dieselbe Programmiersprache nutzen. |
|
d) |
|
|
|
Abbildung 5.5-2: FA-Diagramme der normalisierten Relation Angestellte |
|
5.6 Nicht 1NF, nicht 3NF |
|
5.6.1 Aufgabe |
|
Erstellen Sie eine inhaltlich aussagekräftige Relation, die einen Verstoß gegen die 1NF und einen gegen die 3NF enthält. Bringen Sie diese Relation in die BCNF. Erstellen Sie vom Ergebnis ein textliches Datenmodell. |
|
5.6.2 Lösungsbeispiel |
|
Angestellte (#PersNr, ProgrSpr, Abteilung, Abteilungsleiter) |
|
Das Attribut ProgrSpr hat Mehrfacheinträge – Verstoß gegen die 1NF. Abteilungsleiter ist funktional abhängig von Abteilung, für jede Person wird nicht nur die Abteilung, sondern auch der Abteilungsleiter erfasst – Verstoß gegen die 3NF. Dieser wird beseitigt, indem eine neue Relation Abteilungen angelegt wird und Angestellte.Abteilung zum Fremdschlüssel wird: |
non 3NF,
3NF |
Abteilungen (#Abteilung, Abteilungsleiter) |
|
Angestellte (#PersNr, Abteilung) |
|
Die Mehrfacheinträge werden beseitigt, indem eine Relation zur Programmiersprachenkompetenz mit zusammengesetztem Schlüssel eingerichtet wird: |
|
ProgSprKompetenz (#(PersNr, ProgrSpr)) |
|
PersNr wird hier zum Fremdschlüssel. |
|
5.7 Idealform |
|
5.7.1 Aufgabe |
|
Es gibt eine Idealform für eine Relation, bei der diese ohne jegliche Redundanz ist. Beschreiben Sie sie. |
|
5.7.2 Lösung |
|
Eine solche Relation hat entweder nur Schlüsselattribute oder einen Schlüssel mit Attributen, die nur von diesem voll funktional abhängig sind. Auch mehrere Schlüssel sind möglich. M.a.W.: Jede Determinante ist Schlüssel, wodurch die BCNF erreicht ist [Staud 2021, Kapitel 11]. Hier sind dann auch die 4NF und 5NF erfüllt. |
5NF |
Zwei abstrakte Beispiele: |
|
|
|
Abbildung 5.7-1: FA-Diagramm Idealform 1 mit zusammengesetztem Schlüssel |
|
|
|
Abbildung 5.7-2: FA-Diagramm Idealform 2 mit einfachem Schlüssel |
|
5.8 Von UN zu 1NF |
|
5.8.1 Aufgabe |
|
|
a) Erstellen Sie eine inhaltlich fundierte Relation in tabellarischer Darstellung, die ein mehrwertiges Attribut aufweist, also nicht in 1NF ist. Bringen Sie diese mittels Tupelvermehrung in die 1NF.
|
|
|
b) Bringen Sie die Relation in die 2NF. Geben Sie die textliche Notation an. Erstellen Sie für jede Relation ein FA-Diagramm.
|
|
5.8.2 Lösungsbeispiel |
|
a) |
|
Die folgende Relation erfasst – unnormalisiert – den Besuch von Vorlesungen durch Studierende. |
|
Vorlesungsbesuch_UN |
|
| MatrikelNr |
NameStud |
LVBez |
| 1007 |
Stauber |
DBS, GPROZ |
| 1008 |
Ranz |
DBS, UMOD |
| 1009 |
Rübezahl |
GPROZ |
| |
Die normalisierte Fassung (Tupelvermehrung, vgl. [Staud 2021, Abschnitt 7.3]) ist wie folgt: |
1NF |
Vorlesungsbesuch_1NF |
|
| MatrikelNr |
NameStud |
LVBez |
| 1007 |
Stauber |
DBS |
| 1007 |
Stauber |
GPROZ |
| 1008 |
Ranz |
DBS |
| 1008 |
Ranz |
UMOD |
| 1009 |
Rübezahl |
GPROZ |
| |
LVBez: Kurzbezeichnung einer Lehrveranstaltung |
|
Die Redundanz liegt darin, dass der Zusammenhang zwischen MatrikelNr und NameStud mehrfach erfasst wird. |
|
b) |
|
Die Normalisierung für die 2NF verlangt, dass die Redundanz beseitigt wird. Dazu erstellen wir eine Relation zu den Studierenden: |
2NF |
Studierende_2NF (#MatrikelNr, NameStud) |
|
Jetzt wird der Zusammenhang zwischen MatrikelNr und NameStud nur noch jeweils einmal festgehalten. Den Vorlesungsbesuch erfassen wir in einer neuen „schlanken“ Relation: |
|
Vorlesungsbesuch_2NF (#(MatrikelNr, LVBez)) |
|
Hier wird die MatrikelNr zum Fremdschlüssel. |
|
2NF?: Tatsächlich sind beide Relationen bereits in der höchsten Normalform (5NF). |
|
|
|
Abbildung 5.8-1: FA-Diagramme zu Vorlesungsbesuch und Studierende |
|
LVBez: Bezeichnung der Lehrveranstaltung |
|
5.9 Von 1NF zu 3NF |
|
5.9.1 Aufgabe |
|
Die folgende Tabelle zeigt eine Relation in 1NF, bei der es um Projektmitarbeit geht. |
|
Projektmitarbeit_1NF |
|
| Name |
PersonalNr |
NameProj |
Funktion |
FunktionsSpez |
ProjDauer |
ProjZugeh |
ProjBudget |
| Stein |
12345 |
SmartC |
Leiter |
ArbGr02 |
24 |
24 |
10 |
| Maier |
12346 |
SmartC |
DV |
Gesamt |
24 |
18 |
10 |
| Müller |
23456 |
NetBNG |
Leiter |
Gesamt |
18 |
18 |
30 |
| Bach |
54321 |
NetBNG |
InfMan |
BPR |
18 |
10 |
30 |
| Bach |
54321 |
SmartC |
DV |
Vernetzung |
24 |
24 |
10 |
| Baum |
65432 |
W2.0 |
Finanzen |
Ausgaben |
36 |
36 |
5 |
| Baum |
65432 |
W2.0 |
Contr |
Gesamt |
36 |
24 |
5 |
| Baum |
65432 |
BPR |
Contr |
Einnahmen |
12 |
12 |
1 |
| ..... |
|
|
|
|
|
|
|
| |
Erläuterungen zu Aufbau und Semantik
|
|
- Schlüssel der Relation: #(PersonalNr, NameProj, Funktion)
- Funktion beschreibt, welche Funktion der Angestellte im Projekt wahrnimmt.
- Das Attribut FunktionsSpez beschreibt die Tätigkeit der Person im jeweiligen Projekt. Dies bedeutet, dass dieselbe Funktion bei einer anderen Person oder in einem anderen Projekt anders beschrieben sein kann.
- ProjDauer beschreibt, für wie viele Monate das Projekt eingerichtet wurde.
- ProjZugeh beschreibt, für wie viele Monate der Angestellte diesem Projekt zugeordnet wurde.
- ProjBudget gibt die finanziellen Mittel an, die dem Projekt zur Verfügung stehen.
- Die Abkürzung BPR bei der Funktionsspezifikation bedeutet Business Process Reengineering.
- Eine Person kann in verschiedenen Projekten dieselbe Funktion haben.
- Eine Person kann im selben Projekt mehrere Funktionen ausüben.
|
|
Führen Sie für obige Relation folgende Schritte durch: |
|
|
a) Erstellen Sie ein FA-Diagramm der obigen Relation.
|
|
|
b) Überführen Sie diese Relation in die 3NF und geben Sie die textliche Notation an. Erstellen Sie für jede neu entstehende Relation ein FA-Diagramm.
|
|
|
c) Geben Sie dann das Datenmodell in textlicher und grafischer Notation an.
|
|
5.9.2 Lösung |
|
a) |
|
Das FA-Diagramm ergibt sich wie folgt: |
|
|
|
Abbildung 5.9-1: FA-Diagramm Projektmitarbeit |
|
Begründung: |
|
- Da nur die drei Attribute Funktion, PersNr und BezProj zusammen die FunktionsSpez determinieren, müssen sie zusammen Schlüssel sein.
- Ein Teil des Schlüssels, (PersNr, BezProj), ist Determinante für die drei Attribute ProjZugeh, ProjBudget und ProjDauer.
- PersNr ist Determinante für Name
|
|
b) |
|
Die Lösung besteht darin, alle Determinanten zu Schlüsseln zu machen (=>BCNF!) und die neu entstehenden Relationen der Semantik gemäß zu verknüpfen. Gemäß der Aufgabenstellung entstehen Relationen mit FA-Diagrammen in BCNF: |
Von 1NF zu BCNF |
Funktionsspezifikation (#(Funktion, BezProj, PersNr), FunktionsSpez) |
|
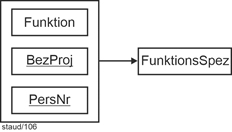
|
|
Abbildung 5.9-2: FA-Diagramm zu Funktionsspezifikation |
|
Funktionsspezifikation.NameProj ist Fremdschlüssel bzgl. Projekte. |
|
Funktionsspezifikation.PersonalNr ist Fremdschlüssel bzgl. Personal |
|
Personal (#PersonalNr, Name) |
|

|
|
Abbildung 5.9-3: FA-Diagramm zu Personal |
|
Projektmitarbeit (#(PersNr, BezProj), Funktion, ProjZugeh) |
|
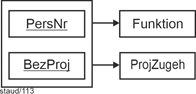
|
|
Abbildung 5.9-4: FA-Diagramm zu Projektmitarbeit |
|
Projektmitarbeit.NameProj ist Fremdschlüssel bzgl. Projekte. |
|
Projektmitarbeit.PersNr ist Fremdschlüssel bzgl. Personal |
|
Projekte (#NameProj, ProjBudget, ProjDauer) |
|
|
|
Abbildung 5.9-5: FA-Diagramm zu Projekte |
|
NF?: Alle obigen Relationen sind in der höchsten Normalform (5NF). |
|
c) |
|
Das Datenmodell in textlicher Notation |
|
Funktionsspezifikation (#(Funktion, BezProj, PersNr), FunktionsSpez) |
|
Personal (#PersNr, Name) |
|
Projekte (#BezProj, ProjBudget, ProjDauer) |
|
Projektmitarbeit (#(PersNr, NameProj), Funktion, ProjZugeh) |
|
Das Datenmodell in grafischer Notation |
|
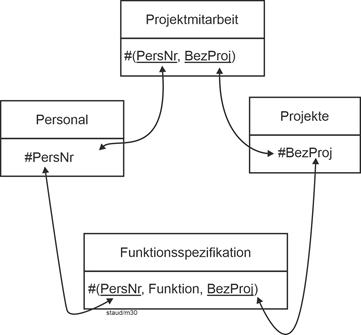
|
|
Abbildung 5.9-6: Datenmodell Projektmitarbeit |
|
5.10 Von 1NF zu BCNF |
|
5.10.1 Aufgabe |
|
|
a) Zeichnen Sie das FA-Diagramm der folgenden Relation, bei der es um Projektmitarbeit geht.
|
|
Projektmitarbeit (#(AngNr, ProjNr, Beginn), Ende, NameAng, BezProjekt) |
|
Erläuterungen zu den Attributen: |
|
AngNr: Identifizierende Nummer für die Angestellten |
|
NameAng: Name Angestellte/r |
|
ProjNr: Identifizierende Nummer für die Projekte |
|
BezProjekt: Bezeichnung Projekte |
|
Beginn: Beginn der Mitarbeit im Projekt |
|
Ende: Ende der Mitarbeit im Projekt |
|
|
b) In welcher NF ist diese Relation? Begründen Sie Ihr Ergebnis.
|
|
|
c) Bringen Sie die Relation in die BCNF. Geben Sie die neuen Relationen als FA-Diagramme an.
|
|
5.10.2 Lösung |
|
a) |
|
FA-Diagramm: |
|
|
|
Abbildung 5.10-1: FA-Diagramm zu Projektmitarbeit_1NF |
|
Die 1NF wird aufgrund der Semantik erstmal angenommen. Mehrfacheinträge ergäben hier auch aufgabentechnisch keinen Sinn. |
|
b) |
|
Die 1NF ist ja gegeben (siehe oben). Die funktionalen Abhängigkeiten AngNr => NameAng und ProjNr => BezProj verstoßen gegen die 2NF. Also bleibt es bei der 1NF. |
|
c) |
|
Für die BCNF müssen alle Determinanten zu Schlüsseln werden und die entstehenden Relationen entsprechend der Semantik verknüpft werden. Dabei entstehen: |
|
Angestellte_BCNF (#AngNr, AngName) |
|
Projekte_BCNF (#ProjNr, BezProjekt) |
|
Projektmitarbeit_BCNF (#(AngNr, ProjNr, Beginn), Ende)) |
|
|
|
Abbildung 5.10-2: FA-Diagramme zu Projektmitarbeit in BCNF |
|
Tatsächlich sind diese Relationen bereits in der höchsten Normalform (5NF), da keine Verstöße gegen die 4NF und 5NF vorliegen. |
5NF |
5.11 Redundanz 2NF, 3NF |
|
5.11.1 Aufgabe |
|
a) Erläutern Sie, warum bei einem Verstoß gegen die 2NF Redundanz in den Daten entsteht. |
|
b) Erläutern Sie, warum bei einem Verstoß gegen die 3NF Redundanz in den Daten entsteht. |
|
5.11.2 Lösung |
|
a) |
|
Bei einem Verstoß gegen die 2NF liegt eine funktionale Abhängigkeit zwischen einem Schlüsselattribut (Teil des Schlüssels!) und einem NSA vor. Da ein Schlüsselattribut typischerweise auch gleiche Attributsausprägungen hat, kommen beim funktional abhängigen NSA auch gleiche Ausprägungen mehrfach vor, was zu Redundanz führt. |
|
b) |
|
Bei einem Verstoß gegen die 3NF liegt eine funktionale Abhängigkeit zwischen 2 Nichtschlüsselattributen vor: NSA1 => NSA2. Da dann die Determinante (NSA1) dieselbe Attributsausprägung mehrfach haben kann, wird auch beim „Zielattribut“ (dem anderen Nichtschlüsselattribut: NSA2) die entsprechende Attributsausprägung mehrfach vorkommen. |
|
5.12 2NF, nicht 3NF |
|
5.12.1 Aufgabe |
|
Erstellen Sie mit inhaltlich aussagekräftigen Attributen eine Relation (als FA-Diagramm), die in 2NF ist und nicht in 3NF. Erläutern Sie die Relation. |
|
5.12.2 Lösungsbeispiel |
|
Die folgende Relation erfüllt die 2NF, aber nicht die 3NF. Die funktionale Abhängigkeit KundenNr => KundenName verhindert die 3NF. Durch sie entsteht eine sog. transitive Abhängigkeit AuftragsNr => KundenNr => Kundenname, die auch als Kennzeichen für die Nichtexistenz der 3NF genommen werden kann. |
|
|
|
Abbildung 5.12-1: FA-Diagramm zu Aufträgen und Kunden |
|
5.13 FAD, Rechnungen |
|
5.13.1 Aufgabe |
|
Gegeben ist die folgende Relation Rechnungen als FA-Diagramm: |
|
|
|
Abbildung 5.13-1: FA-Diagramm Rechnungen |
|
RNr: Rechnungsnummer; PosNr: Positionsnummer; RechnDatum: Rechnungsdatum; ArtikelBez: Artikelbezeichnung |
|
|
a) Geben Sie die textliche Notation dieser Relation an.
|
|
|
b) In welcher NF ist diese Relation? Erläutern Sie alle erkennbaren Verstöße gegen Normalformen.
|
|
|
c) Normalisieren Sie bis zur höchsten Normalform. Geben Sie die textlichen Notationen der Relationen an. Vergeben Sie geeignete Relationenbezeichnungen.
|
|
5.13.2 Lösung |
|
a) |
|
Rechnungen (#(RNr, PosNr), RechnDatum, KundenNr, KundenTel, ArtNr, ArtikelBez, ArtikelPreis) |
|
b) |
|
Sie ist nicht in 3NF, wegen der funktionalen Abhängigkeiten zwischen Nichtschlüsselattributen: |
|
ArtikelNr => ArtikelBez |
|
ArtikelBez => ArtNr |
|
ArtikelNr => ArtikelPreis |
|
KundenNr => KundenTel |
|
Die Artikelbezeichnung wird auch als eindeutig angenommen. Sie ist auch nicht in 2NF, weil funktionale Abhängigkeiten zwischen Schlüsselattributen und Nichtschlüsselattributen bestehen: |
|
RNr => RechnDatum |
|
RNr => KundenNr |
|
RNr => KundenTel |
|
Sie ist also in 1NF. |
|
c) |
|
Die Zerlegung ergibt: |
|
Rechnungsköpfe (#RNr, RechnDatum, KundenNr) |
|
Der Fremdschlüssel Rechnungsköpfe.KundenNr verknüpft mit Kunden. |
|
Rechnungspositionen (#(RNr, PosNr), ArtikelNr)) |
|
Der Fremdschlüssel Rechnungspositionen.RNr verknüpft mit Rechnungsköpfe. Rechnungspositionen.ArtikelNr verknüpft mit Artikel. |
|
Kunden (#KundenNr, KundenTel) |
|
Artikel (#ArtikelNr, #ArtikelBez, Artikelpreis) |
|
Zwei „konkurrierende“ Schlüssel kann es schon mal geben. ArtikelBez ist allerdings nur Schlüssel, wenn die Artikelbezeichnung tatsächlich identifizierend ist. |
|
5.14 BCNF - Definition |
|
5.14.1 Aufgabe |
|
Die Definition der BCNF ist sehr elegant und umfasst auch die der unteren Normalformen (bis auf die 1NF). Beschreiben Sie, warum das so ist, warum also, wenn die BCNF erfüllt ist, auch die 3NF und die 2NF erfüllt sind. |
|
5.14.2 Lösung |
|
Die BCNF ist erfüllt, falls alle Determinanten auch Schlüssel sind. Falls dies erfüllt ist, können keine Schlüsselattribute (Schlüsselbestandteile) Determinanten sein. Damit ist die 2NF erfüllt. Es ist dann auch nicht möglich, dass ein Nichtschlüsselattribut Determinante ist, denn es ist ja kein Schlüssel. Damit ist die 3NF auch erfüllt. |
|
5.15 FAD - Vorlesungsbesuch |
|
5.15.1 Aufgaben |
|
|
a) Zeichnen Sie das FA-Diagramm der folgenden Relation, die den Besuch von Lehrveranstaltungen beschreibt:
|
|
VB (#(MatrikelNr, LVNr, DozNr, Semester), NameStud, E-MailStud, BezLV, StudGang, DozName, Fakultät) |
|
Erläuterung der Abkürzungen und Attribute: |
|
VB: Vorlesungsbesuch |
|
LV: Lehrveranstaltung |
|
LVNr: Nummer der Lehrveranstaltung |
|
DozNr: Nummer des Dozenten |
|
DozName: Name des Dozenten |
|
Fakultät: Fakultät, zu der der Dozent gehört |
|
Semester, in dem der Studierende die LV besuchte z.B. SS2023 |
|
BezLV: Bezeichnung der LV, z.B. Datenbanksysteme 1 |
|
|
b) In welcher NF ist diese Relation? Begründen Sie Ihr Ergebnis. Erläutern Sie, wo hier Redundanz entsteht.
|
|
|
c) Bringen Sie die Relationen in die BCNF. Geben Sie die neuen Relationen in textlicher Form und als FA-Diagramme an. Vergeben Sie geeignete Relationenbezeichnungen.
|
|
5.15.2 Lösung |
|
a) |
|
Hier das FA-Diagramm. Falls es eine funktionale Abhängigkeit des Studiengangs von der Matrikelnummer gibt, |
|
MatrikelNr => StudGang, |
|
müsste diese noch ergänzt werden. |
|
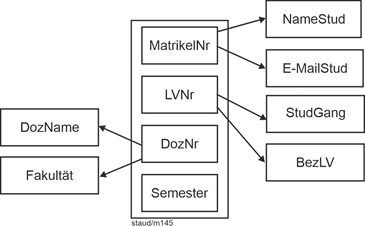
|
|
Abbildung 5.15-1: FA-Diagramm Vorlesungsbesuch - unnormalisiert |
|
b) |
|
Alle funktionalen Abhängigkeiten von Schlüsselattributen zu Nichtschlüsselattributen stellen Verstöße gegen die 2NF dar. Die Relation ist also in 1NF. |
|
Bei jeder dieser funktionalen Abhängigkeiten entsteht Redundanz, weil Schlüsselteile gleiche Ausprägungen haben, was zu gleichen Ausprägungen bei dem funktional abhängigen Attribut führt. Z.B. bei DozNr => DozName. Die Dozentennummer kommt als Ausprägung eines Schlüsselattributs mehrfach vor. Entsprechend wird mehrfach der Dozentenname erfasst. |
|
c) |
|
Die Normalisierung besteht darin, alle Determinanten zu Schlüsseln neuer Relationen zu machen. Die neuen Relationen enthalten dann jeweils die vom Schlüssel funktional abhängigen Attribute: |
|
Studierende (#MatrikelNr, NameStud, E-MailStud) |
|
Lehrveranstaltungen (#LVNr, StudGang, BezLV) |
|
Dozenten (#DozNr, DozName, Fakultät) |
|
Lehrveranstaltungsbesuch (#(MatrikelNr, LVNr, DozNr, Semester)) |
|
Der Fremdschlüssel Lehrveranstaltungsbesuch.MatrikelNr verknüpft mit Studierende. |
|
Der Fremdschlüssel Lehrveranstaltungsbesuch.LVNr verknüpft mit Lehrveranstaltungen. |
|
Der Fremdschlüssel Lehrveranstaltungsbesuch.DozNr verknüpft mit Dozenten. |
|
Die Relationen sind alle in BCNF. |
|
Hier die FA-Diagramme: |
|
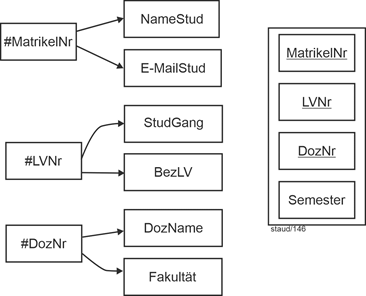
|
|
Abbildung 5.15-2: FA-Diagramme zu Vorlesungsbesuch - normalisiert |
|
5.16 BCNF, Projektmitarbeit |
|
Im Rahmen eines Datenbankentwurfs wurden zum Aspekt Projektmitarbeit folgende Attribute und funktionalen Abhängigkeiten gefunden: |
|
- PersNr (Personalnummer)
- AngName (Angestelltenname)
- Projektbezeichnung (ProjBez)
- Funktion (der Person im jeweiligen Projekt)
- Beginn (der Zugehörigkeit zum Projekt)
|
|
Die Namen sind, da es sich um ein kleines Unternehmen handelt, eindeutig. Die funktionalen Abhängigkeiten sind wie folgt: |
|
- PersNr => AngName
- AngName => PersNr
- (PersNr, ProjBez) => Funktion
- (PersNr, ProjBez) => Beginn
- (AngName, ProjBez) => Funktion
- (AngName, ProjBez) => Beginn
|
|
5.16.1 Aufgaben |
|
|
a) Erstellen Sie die Relation als FA-Diagramm.
|
|
|
b) Wo liegt hier Redundanz vor?
|
|
|
c) Ist diese Relation in BCNF?
|
|
|
d) Ist diese Relation in 3NF?
|
|
|
e) Ist diese Relation in 2NF?
|
|
|
f) Bringen Sie die Relation in 5NF und stellen sie das Ergebnis textlich sowie in FA-Diagrammen dar.
|
|
Wo nötig, begründen Sie Ihre Antwort. |
|
5.16.2 Lösung |
|
a) |
|
Es gibt zwei sich überlappende Schlüssel: (PersNr, ProjBez) und (AngName, ProjBez). Von ihnen sind jeweils Funktion und Beginn funktional abhängig. Damit ergibt sich das FA-Diagramm der Relation wie folgt: |
|
|
|
Abbildung 5.16-1: FA-Diagramm der Relation Projektmitarbeit. |
|
b) |
|
Die Redundanz entsteht durch die funktionalen Abhängigkeiten zwischen den Schlüsselattributen PersNr und AngName. Beide haben in dieser Relation Mehrfacheinträge (weil typischerweise in einem Projekt mehrere Personen mitarbeiten) wodurch mehrfach erfasst wird, dass z.B. die Person Müller die Personalnummer 12345 hat. |
|
c) |
|
Die BCNF ist erfüllt, falls alle Determinanten auch Schlüssel sind. Hier sind aber AngName und PersNr als Schlüsselteile Determinanten. Somit ist die BCNF nicht erfüllt. |
|
d) |
|
Sie ist in 3NF, da kein Nichtschlüsselattribut von einem anderen Nichtschlüsselattribut funktional abhängig ist. |
|
e) |
|
Da höhere Normalformen die niedrigeren umfassen, ist sie wegen d) auch in 2NF. Direkt auf die Definition bezugnehmend: Sie ist in 2NF, da kein Nichtschlüsselattribut(!) von einem Teil des Schlüssels funktional abhängig ist. Die funktionale Abhängigkeit zwischen Schlüsselattributen wird bei der 2NF nicht betrachtet. |
|
f) |
|
Für das Erreichen der BCNF muss der überlappende Schlüssel beseitigt werden. Hier wird (AngName, ProjBez) rausgenommen. Damit der Zusammenhang zwischen PersNr und AngName nicht verloren geht (Kein Informationsverlust durch Normalisierung!) wird dafür eine eigene Relation eingerichtet. Somit ergibt sich: |
Kein Informationsverlust |
Personal (#PersNr, #AngName) |
|
Projektmitarbeit (#(PersNr, ProjBez), Funktion, Beginn) |
|
Projektmitarbeit.PersNr wird zum Fremdschlüssel bzgl. Personal. |
|
|
|
Abbildung 5.16-2: FA-Diagramme der Relation Projektmitarbeit_5NF |
|
Da keine Verstöße gegen die 4NF und 5NF vorliegen ist die 5NF erreicht. |
|
5.17 Nicht 3NF, Abteilungen |
|
5.17.1 Aufgabe |
|
Die folgende Relation ist nicht in 3NF. |
|
Abteilungen (#BezAbt, PersNrAbtLeiter, AnzahlMitarb, Standort, NameAbtLeiter) |
|
BezAbt: Bezeichnung der Abteilung, AbtLeiter: Abteilungsleiter, Standort: Ort, an dem die Abteilung angesiedelt ist. |
|
|
a) Geben Sie alle funktionalen Abhängigkeiten zwischen den Attributen von Abteilungen an.
|
|
|
b) Erläutern Sie an diesem Beispiel, wie und warum bei Nichterreichung der 3NF Redundanz entsteht, wenn Daten abgespeichert werden.
|
|
|
c) Erstellen sie ein FA-Diagramm zu dieser Relation (genau zu dieser!).
|
|
5.17.2 Lösung |
|
a) |
|
Folgende funktionalen Abhängigkeiten liegen vor: |
|
|
BezAbt => PersNrAbtLeiter
|
|
|
BezAbt => AnzahlMitarb
|
|
|
BezAbt => Standort
|
|
|
BezAbt => Name-AbtLeiter
|
|
|
PersNrAbtLeiter => NameAbtLeiter
|
|
b) |
|
Die 3NF wird durch die letzte funktionale Abhängigkeit verhindert. Hier wird für jede Abteilung der Zusammenhang zwischen der Personalnummer und dem Namen der Abteilungsleiter erfasst. Wenn also mehrere Abteilungen durch dieselbe Abteilungsleiterin geführt werden, wird der Zusammenhang zwischen PersNr und Name mehrfach erfasst. Auch wenn dies in diesem Beispiel nicht zu großer Redundanz führen dürfte, verbietet die 3NF eine solche funktionale Abhängigkeit zwischen Nichtschlüsselattributen. |
|
c) |
|
Das FA-Diagramm ergibt sich wie folgt: |
|
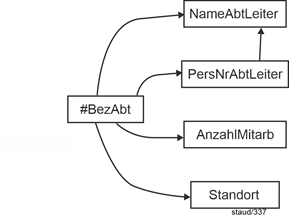
|
|
Abbildung 5.17-1: FA-Diagramm der Relation Abteilungen |
|
5.18 FA-Diagramm, Projektmitarbeit |
|
5.18.1 Aufgaben |
|
In einem Workshop mit dem Ziel des Datenbankdesigns hat sich als erster Entwurf für die Modellierung von Projektmitarbeit die folgende Relation ergeben. |
|
Projektmitarbeit (PersonalNr, ProjektNr, Funktion, AngName, AngVorname, ProjektBez, ProjektDauer, BeginnFunktion, EndeFunktion) |
|
Erläuterung der Attribute/Semantik: |
|
Funktion : Funktion, die von der Person in einem bestimmten Projekt wahrgenommen wird. Eine Person kann in verschiedenen Projekten unterschiedliche oder auch dieselbe Funktion wahrnehmen sowie in einem Projekt mehrere Funktionen übernehmen. |
|
Beispiel : Person 1007 ist Controller im Projekt BPR, LeiterEntwicklung und Softwarearchitekt im Projekt ERP2.0 und im Projekt CRM2.0 wiederum Controller. |
|
BeginnFunktion: Monat, in dem die Person die Funktion übernahm. EndeFunktion: Monat, in dem die Person die Funktion abgab. AngName: Name des Angestellten. AngVorname: Vorname des Angestellten. ProjektBez: Bezeichnung des Projekts. ProjektDauer: Dauer des Projekts. |
|
|
a) Legen Sie den Schlüssel fest. Erstellen Sie dann für diese Relation ein FA-Diagramm.
|
|
|
b) An welchen Stellen entsteht in dieser Relation Redundanz?
|
|
|
c) In welcher Normalform ist diese Relation?
|
|
5.18.2 Lösung |
|
a) |
|
Als Schlüssel kann hier kein einzelnes Attribut dienen, weil keines für die Tupel identifizierenden Charakter hat. Es muss also eine Attributskombination sein. Beginnen können wir mit der PersonalNr. Ergänzen wir diese um die ProjektNr, wird die Projektmitarbeit modelliert, was nach der Anforderungsbeschreibung zielführend ist. Die Attributskombination (PersonalNr, ProjektNr) reicht aber nicht als Determinante für alle Attribute. Nicht für die Funktion, nicht für deren Beginn und Ende. Da nach der Beschreibung eine Person in unterschiedlichen Projekten verschiedene zeitliche Phasen haben kann, muss die Funktion auch in den Schlüssel. Von diesem Schlüssel mit drei Attributen sind dann auch BeginnFunktion und EndeFunktion funktional abhängig. |
Mit Semantik zum Schlüssel |
Damit entsteht die folgende Relation: |
|
Projektmitarbeit (#(PersonalNr, ProjektNr, Funktion), AngName, AngVorname, ProjektBez, ProjektDauer, BeginnFunktion, EndeFunktion) |
|
Das FA-Diagramm : |
|
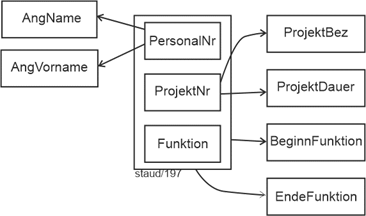
|
|
Abbildung 5.18-1: FA-Diagramm Projektmitarbeit |
|
b) |
|
Die funktionalen Abhängigkeiten zwischen Nichtschlüsselattributen und Schlüsselattributen (Teilen des Schlüssels) sind immer Ursache von Redundanz. Das Schlüsselattribut hat ja üblicherweise mehrere gleiche Ausprägungen. Für jede dieser identischen Ausprägungen wird dann auch die Ausprägung des funktional abhängigen Nichtschlüsselattributs wiederholt gespeichert. Für folgende funktionalen Abhängigkeiten gilt dies hier: |
|
|
ProjektNr => ProjektBez
|
|
|
ProjektNr => ProjDauer
|
|
|
PersNr => AngName
|
|
|
PersNr => AngVorname
|
|
c) |
|
Die funktionalen Abhängigkeiten von Schlüsselattributen zu Nichtschlüsselattributen verhindern die 2NF. Damit ist die Relation in 1NF. |
|
5.19 Angestellte, FA-Diagramm |
|
5.19.1 Aufgaben |
|
|
a) Erstellen Sie für die folgende Relation (so wie sie ist, mit der üblichen Semantik; eine Person kann mehrere Adressen haben) ein FA-Diagramm.
|
|
Angestellte (#(PersNr, AdrNr), Name, VName, AbtBez, AbtLeiter, PLZ, Ort, Straße) |
|
AdrNr: Adressnummer, AbtNr: Abteilungsnummer, AbtLeiter: Abteilungsleiter |
|
|
b) Normalisieren Sie die Relation bis zur 5NF. Geben Sie dafür die textlichen Notationen der Relationen an und beschreiben Sie bei jedem notwendigen Schritt die dabei beseitigten Redundanzen.
|
|
5.19.2 Lösung |
|
a) |
|
Die Aufgabenbeschreibung führt aus, dass es mehrere Adressen je Person geben kann. Dies bedeutet, dass die 1NF nicht erfüllt ist. Dieser Tatbestand ist in FA-Diagrammen nicht ausdrückbar. Für FA-Diagramme muss mindestens die 1NF erfüllt sein. Diese ist hier mit folgender Zerlegung realisiert: |
Kein FAD ohne 1NF |
Angestellte (#(PersNr, AdressNr), Name, Vname, AbtBez, AbtLeiter) |
|
Adressen (#AdrNr, PLZ, Ort, Straße) |
|
Die FA-Diagramme: |
|
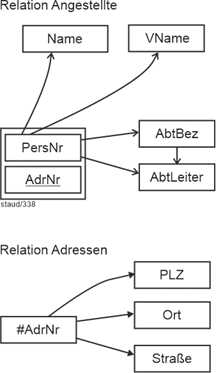
|
|
Abbildung 5.19-1: FA-Diagramme Angestellte, Adressen |
|
b) |
|
In Angestellte liegen zahlreiche funktionale Abhängigkeiten zwischen Schlüsselattributen (Teilen des Schlüssels) und Nichtschlüsselattributen vor. Diese verhindern die 2NF und sind Ursache von Redundanz. Das Schlüsselattribut hat ja üblicherweise mehrere gleiche Ausprägungen. Für jede dieser identischen Ausprägungen wird dann auch die Ausprägung des funktional abhängigen Nichtschlüsselattributs wiederholt gespeichert. Für folgende funktionalen Abhängigkeiten gilt dies hier: |
Auf zur 2NF |
|
PersNr => AbtBezZ
|
|
|
PersNr => AbtLeiter
|
|
|
PersNr => Name
|
|
|
PersNr => Vorname
|
|
Die Herbeiführung der 2NF führt zu folgenden Relationen: |
|
Angestellte_2NF (#PersNr, Name, VName, AbtBez, AbtLeiter) |
|
PersAdr (#(PersNr, AdrNr) |
|
Relation Adressen ist bereits in 5NF: |
|
Adressen_5NF (#AdrNr, PLZ, Ort, Straße) |
|
Die 3NF in Angestellte wird durch die funktionale Abhängigkeit zwischen den zwei Nichtschlüsselattributen AbtBez und AbtLeiter verhindert: |
Auf zur 3NF |
|
AbtBez => AbtLeiter
|
|
Da AbtBez Nichtschlüsselattribut ist, gibt es identische Ausprägungen. Für jede dieser Ausprägungen wird der jeweilige Abteilungsleiter erfasst. Die Lösung besteht wieder in einer Zerlegung: |
|
Angestellte (#PersNr, Name, VName, AbtBez) |
|
Abteilungen (#AbtBez, AbtLeiter) |
|
Diese Relationen sind alle in 3NF. Da auch gilt, dass alle Determinanten Schlüssel sind, liegt die BCNF vor. Leicht zu erkennen ist, dass die Hindernisse für die 4NF und 5NF nicht vorliegen. Damit liegen hier insgesamt folgende Relationen vor: |
|
Abteilungen_5NF (#AbtBez, AbtLeiter) |
|
Adressen_5NF (#AdrNr, PLZ, Ort, Straße) |
|
Angestellte_5NF (#PersNr, Name, VName, AbtBez) |
|
PersAdr_5NF (#(PersNr, AdrNr)) |
|
5.20 „Attributshaufen“ |
|
5.20.1 Gegenstand |
|
Gegenstand der folgenden Aufgabe sind folgende Attribute aus einem Anwendungsbereich Auftragsabwicklung: |
|
AuftragsNr, PositionsNr, ProduktNr, ProduktBez, Menge, AuftragsDatum, KundenNr, KundenName |
|
Beginnen Sie ihre Arbeit mit einer Universalrelation, die alle Attribute enthält. |
Universalrelation |
5.20.2 Aufgabe |
|
|
a) Bringen Sie Ordnung in diesen „Attributshaufen“. Stellen Sie dazu in der Universalrelation alle funktionalen Abhängigkeiten fest.
|
|
|
b) Legen Sie die Relationen fest, mit Schlüsseln und Fremdschlüsseln. Falls Relationen noch nicht in 5NF sind, normalisieren sie weiter, bis diese erreicht ist.
|
|
5.20.3 Lösung |
|
a) |
|
Eine sinnvolle Vorgehensweise ist, alle funktionalen Abhängigkeiten in der Universalrelation festzustellen. Dies kann auch grafisch dargestellt werden. Die Universalrelation wird Aufträge genannt und stellt sich in der ersten Fassung so dar: |
|
Aufträge (AuftragsNr, PositionsNr, ProduktNr, ProduktBez, Menge, AuftragsDatum, KundenNr, KundenName) |
|
Zuerst wird der Schlüssel geklärt. Gibt es ein Attribut oder eine Attributskombination, von der alle anderen funktional abhängig sind? Nach längerem Reflektieren und mit Kenntnis der kaufmännischen „Tiefensemantik“ ergibt sich, dass AuftrNr und PositionsNr zusammen diese Aufgabe erfüllen. Jede Kombination aus Ausprägungen dieser beiden Attribute ist eindeutig, wodurch diese zur Determinante für alle anderen und damit zum Schlüssel wird. Es ergibt sich: |
Schlüsselklärung |
Aufträge (#(AuftragsNr, PositionsNr), ProduktNr, ProduktBez, Menge, AuftragsDatum, KundenNr, KundenName) |
|
Das leichte Unbehagen, dass dabei (vielleicht / hoffentlich) aufkommt, ist berechtigt, denn der Schlüssel ist für einige Attribute „überausgestattet“, zum Beispiel im Fall der KundenNr. Hier würde die AuftragsNr alleine als Determinante genügen. Es liegt also eine einfache funktionale Abhängigkeit vor (vgl [Staud 2021, S. 121]). |
Überausstattung |
Ohne überflüssige Attribute sind ProduktNr, ProduktBez und Menge vom Schlüssel abhängig. Diese vollen funktionalen Abhängigkeiten (vgl [Staud 2021, S. 121f]) sind in der folgenden Abbildung als Pfeillinien eingezeichnet: |
Im Einzelnen |

|
|
Abbildung 5.20-1: Die ersten funktionalen Abhängigkeiten im „Attributshaufen“ zu Aufträgen |
|
Welche weiteren funktionalen Abhängigkeiten gibt es? Wiederum durch Reflektieren der Semantik finden wir: |
|
ProduktNr => ProduktBez |
|
Da hier die Produktbezeichnung eindeutig sein soll gilt auch: |
|
ProduktBez => ProduktNr |
|
Die funktionale Abhängigkeit zwischen Kundennummer und -name gilt nur in eine Richtung |
|
KundenNr => KundenName) |
|
Damit verändert sich die Abbildung: |
|

|
|
Abbildung 5.20-2: Weitere funktionalen Abhängigkeiten „im Attributshaufen“ zu Aufträgen |
|
Das Ergebnis ist noch nicht zufriedenstellend. Auch ohne inhaltlich nachzudenken, fällt auf, dass AuftragsDatum noch nicht eingebunden ist. Das ist nicht möglich, denn es gilt: zumindest lose Kopplung ist im Datenmodell nötig. Die Überprüfung der Semantik führt zu dem Ergebnis, dass AuftragsDatum von der AuftragsNr abhängt. Weitere Reflektion der Semantik führt zur Erkenntnis, dass auch KundenNr und KundenName von der AuftragsNr abhängen. Somit ergeben sich folgende weiteren funktionalen Abhängigkeiten: |
Lose Kopplung |
AuftragsNr => AuftragsDatum |
|
AuftragsNr => KundenNr |
|
AuftragsNr => KundenName |
|
Damit ergibt sich die folgende wiederum ergänzte Abbildung. |
|
|
|
Abbildung 5.20-3: Die letzten funktionalen Abhängigkeiten im „Attributshaufen“ zu Aufträgen |
|
b) |
|
Obiges macht die Relationenstruktur deutlich. Da kann gleich die BCNF umgesetzt werden. Wir fügen die Attribute zusammen, für die dann gilt, dass jede Determinante auch Schlüssel ist. Dazu nehmen wir jeden Schlüssel als Ausgangspunkt für eine Relation und ergänzen ihn um die Attribute, die von ihm funktional abhängig sind. Die Relationenbezeichnungen wählen wir inhaltlich passend: |
|
Produkte (#ProduktNr, #ProduktBez) |
|
Kunden (#KundenNr, KundenName) |
|
Auftragsköpfe (#AuftragsNr, AuftragsDatum, KundenNr) |
|
KundenName lassen wir oben weg, da dieser schon in Kunden erfasst ist und er hier zu einer transitiven Abhängigkeit führen würde. |
|
Auftragspositionen (#(AuftragsNr, PositionsNr), ProduktNr, Menge) |
|
ProduktBez lassen wir weg, da die Produktbezeichnungen schon in Produkte erfasst ist und sie hier zu einer transitiven Abhängigkeit führen würde. |
|
Hier fehlt noch etwas wichtiges, was bei jedem Datenmodell am Schluss gründlich bedacht werden muss: die relationalen Verknüpfungen und die dafür nötigen Fremdschlüssel. Denn es gilt: |
Verknüpfung |
Durch Zerlegungen von Relationen darf keine Information verloren gehen, die relationalen Verknüpfungen durch Schlüssel und Fremdschlüssel haben dies zu leisten. |
|
Hier gilt: |
|
- Auftragsköpfe.KundenNr ist Fremdschlüssel bzgl. Kunden.
- Auftragspositionen.AuftragsNr ist Fremdschlüssel bzgl. Auftragsköpfe.
- Auftragspositionen.ProduktNr ist Fremdschlüssel bzgl. Produkte.
|
|
Wir ergänzen diese und erhalten dann folgende Relationen: |
|
Produkte (#ProduktNr, #ProduktBez) |
|
Kunden (#KundenNr, KundenName) |
|
Auftragsköpfe (#AuftragsNr, AuftragsDatum, KundenNr) |
|
Auftragspositionen (#(AuftragsNr, PositionsNr), ProduktNr, Menge) |
|
Alle Relationen sind in der höchsten, der 5NF. |
|
5.21 Anomalien |
|
5.21.1 Aufgabe |
|
Zeigen Sie am Beispiel einer Relation, die nicht in 2NF ist, die Aktualisierungs-Anomalie (Update-Anomalie), Einfüge-Anomalie (Insert-Anomalie) und Lösche-Anomalie (Delete-Anomalie) auf und erläutern Sie, welche Probleme diese bereiten. |
|
5.21.2 Lösungsbeispiel |
|
Folgende Relation zur Projektmitarbeit ist nicht in 2NF: |
|
ProjektMitarbeit (#(PersNr, ProjektBez), Name, Vorname, ProjektBudget) |
|
Der Grund sind folgende funktionalen Abhängigkeiten von einem Teil des Schlüssels: |
|
|
PersNr => Name
|
|
|
PersNr => Vorname
|
|
Die Anomalien entstehen, weil Name und Vorname nur von einem Teil des Schlüssels abhängig sind, von PersNr. Dies führt dazu, dass PersNr gleiche Ausprägungen aufweist (für jede Projektmitarbeit einer Person) und dass deshalb die Namen und Vornamen mehrfach erfasst werden. |
|
Die Aktualisierungs-Anomalie beschreibt die Notwendigkeit, Änderungen an mehreren Stellen vorzunehmen. Im Beispiel: Wenn Herr Müller bei der Heirat den Namen seiner Frau annimmt und er in mehreren Projekten mitarbeitet, müssen mehrere Aktualisierungen vorgenommen werden. |
|
Die Einfüge-Anomalie beschreibt das Problem, dass ein Eintrag bzgl. eines Schlüsselattributs nicht möglich ist, weil zum anderen Schlüsselattribut kein Wert vorliegt. Im Beispiel: Eine Person kann nicht erfasst werden, wenn sie nicht in einem Projekt mitarbeitet. |
|
Die Lösche-Anomalie beschreibt, dass beim Löschen eines Tupels Information gelöscht wird, die nicht gelöscht werden sollte. Im Beispiel: Verlässt die letzte Person das Projekt, geht auch die Information zum Projekt verloren. |
|
5.22 Normalformen |
|
5.22.1 Gegenstand |
|
Relation Aufträge_1NF |
|
Diese Relation hält Informationen zu Aufträgen fest. Die AuftrNr identifiziert den Auftrag, die PosNr die einzelnen Positionen eines Auftrags. Jede Position bezieht sich auf ein Produkt, das durch ProdBez(eichnung) benannt und zusätzlich durch die ProdNr identifiziert wird. Menge gibt an, wieviele Produkte in der Position aufgeführt sind. Das Attribut KuNr identifiziert den Kunden, auf den sich der Auftrag bezieht. Die Kundennamen (KuName) sind nicht eindeutig. |
|
Aufträge_1NF |
|
| AuftrNr |
PosNr |
ProdNr |
ProdBez |
Menge |
Auftr-
Datum |
KuNr |
KuName |
| 0001 |
1 |
9901 |
Laser Dr xyz |
1 |
30.06.23 |
1700 |
Müller |
| 0001 |
2 |
9910 |
Toner xyz |
3 |
30.06.23 |
1700 |
Müller |
| 0001 |
3 |
9905 |
Papier abc |
5.000 |
30.06.23 |
1700 |
Müller |
| 0010 |
1 |
9905 |
Papier abc |
30.000 |
01.07.22 |
1201 |
Sammer |
| 0010 |
2 |
9910 |
Toner xyz |
1 |
01.07.22 |
1201 |
Sammer |
| 0011 |
1 |
9901 |
Laser Dr xyz |
1 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
2 |
9911 |
Tintenpatr x |
20 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
3 |
9905 |
Papier abc |
5.000 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
4 |
9906 |
InkJet-Dru y |
2 |
02.07.23 |
1600 |
Stanzl KG |
| 0012 |
1 |
9998 |
z-Bildschirm |
1 |
04.07.24 |
1900 |
Max OHG |
| ... |
|
|
|
|
|
|
|
| |
Schlüssel: #(AuftrNr, PosNr) |
|
Schlüssel der Relation. Es ist unschwer zu erkennen, dass die beiden Attribute AuftrNr und PosNr den Schlüssel der Relation darstellen, weil mit den Ausprägungen dieser Attribute jedes Tupel (jede Zeile) eindeutig identifiziert werden kann. |
|
5.22.2 Aufgabe |
|
Welche funktionalen Abhängigkeiten stellen in Aufträge_1NF Verstöße gegen welche Normalformen dar? |
|
5.22.3 Lösung |
|
AuftrNr => AuftrDatum stellt einen Verstoß gegen die 2NF dar. |
|
AuftrNr => KuNr stellt einen Verstoß gegen die 2NF dar. |
|
KuNr => KuName stellt einen Verstoß gegen die 3NF dar. |
|
ProdNr => ProdBez stellt einen Verstoß gegen die 3NF dar. Ebenso ProdBez => ProdNr. |
|
5.23 Aktualisierungs-Anomalien |
|
5.23.1 Gegenstand |
|
Relation Aufträge_1NF |
|
Diese Relation hält Informationen zu Aufträgen fest. Die AuftrNr identifiziert den Auftrag, die PosNr die einzelnen Positionen eines Auftrags. Jede Position bezieht sich auf ein Produkt, das durch ProdBez(eichnung) benannt und zusätzlich durch die ProdNr identifiziert wird. Menge gibt an, wieviele Produkte in der Position aufgeführt sind. Das Attribut KuNr identifiziert den Kunden, auf den sich der Auftrag bezieht. Die Kundennamen (KuName) sind nicht eindeutig. |
|
Aufträge_1NF |
|
| AuftrNr |
PosNr |
ProdNr |
ProdBez |
Menge |
Auftr-
Datum |
KuNr |
KuName |
| 0001 |
1 |
9901 |
Laser Dr xyz |
1 |
30.06.23 |
1700 |
Müller |
| 0001 |
2 |
9910 |
Toner xyz |
3 |
30.06.23 |
1700 |
Müller |
| 0001 |
3 |
9905 |
Papier abc |
5.000 |
30.06.23 |
1700 |
Müller |
| 0010 |
1 |
9905 |
Papier abc |
30.000 |
01.07.22 |
1201 |
Sammer |
| 0010 |
2 |
9910 |
Toner xyz |
1 |
01.07.22 |
1201 |
Sammer |
| 0011 |
1 |
9901 |
Laser Dr xyz |
1 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
2 |
9911 |
Tintenpatr x |
20 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
3 |
9905 |
Papier abc |
5.000 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
4 |
9906 |
InkJet-Dru y |
2 |
02.07.23 |
1600 |
Stanzl KG |
| 0012 |
1 |
9998 |
z-Bildschirm |
1 |
04.07.24 |
1900 |
Max OHG |
| ... |
|
|
|
|
|
|
|
| |
Schlüssel: #(AuftrNr, PosNr) |
|
Die beiden Attribute AuftrNr und PosNr stellen den Schlüssel der Relation dar, weil mit den Ausprägungen dieser Attribute jedes Tupel (jede Zeile) eindeutig identifiziert werden kann. |
|
5.23.2 Aufgabe |
|
|
a) Wie sind Aktualisierungsanomalien definiert?
|
|
|
b) Welche Aktualisierungsanomalien liegen in Aufträge_1NF vor und welches Problem erzeugen sie?
|
|
5.23.3 Lösung |
|
a) |
|
Eine Aktualisierungsanomalie liegt vor, wenn die Änderung einer Information dazu führt, dass in mehreren Tupeln die Ausprägung des entsprechenden Attributs verändert werden muss. Dies ist grundsätzlich unerwünscht. Es hat bei der Aktualisierung des Werts die Konsequenz, dass die Zahl der zu ändernden Tupel im Vornehinein unbekannt ist. Unter Umständen muss die gesamte Relation durchsucht werden. |
|
b) |
|
Werden die Produktbezeichnungen geändert, indem z.B. der Produktnummer 9901 statt "Laser Dr(ucker) xyz" jetzt "HP Laser Dru Serie 5" zugeordnet wird, dann muss die Produktbezeichnung nicht nur in einem Tupel, sondern in mehreren geändert werden. |
|
Gleiches gilt für das AuftrDatum. Müssen wir dieses aus irgendwelchen Gründen ändern, muss dies mehrfach geschehen. Auch KuName weist diese Eigenschaft auf. Ändert sich der Kundenname des Kunden 1700 von "Müller" nach "Müller und Paul", sind bei der Aktualisierung wieder mehrfache Änderungen nötig. |
|
5.24 Einfüge-Anomalien |
|
5.24.1 Gegenstand |
|
Relation Aufträge_1NF |
|
Diese Relation hält Informationen zu Aufträgen fest. Die AuftrNr identifiziert den Auftrag, die PosNr die einzelnen Positionen eines Auftrags. Jede Position bezieht sich auf ein Produkt, das durch ProdBez(eichnung) benannt und zusätzlich durch die ProdNr identifiziert wird. Menge gibt an, wieviele Produkte in der Position aufgeführt sind. Das Attribut KuNr identifiziert den Kunden, auf den sich der Auftrag bezieht. Die Kundennamen (KuName) sind nicht eindeutig. |
|
Aufträge_1NF |
|
| AuftrNr |
PosNr |
ProdNr |
ProdBez |
Menge |
Auftr-
Datum |
KuNr |
KuName |
| 0001 |
1 |
9901 |
Laser Dr xyz |
1 |
30.06.23 |
1700 |
Müller |
| 0001 |
2 |
9910 |
Toner xyz |
3 |
30.06.23 |
1700 |
Müller |
| 0001 |
3 |
9905 |
Papier abc |
5.000 |
30.06.23 |
1700 |
Müller |
| 0010 |
1 |
9905 |
Papier abc |
30.000 |
01.07.22 |
1201 |
Sammer |
| 0010 |
2 |
9910 |
Toner xyz |
1 |
01.07.22 |
1201 |
Sammer |
| 0011 |
1 |
9901 |
Laser Dr xyz |
1 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
2 |
9911 |
Tintenpatr x |
20 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
3 |
9905 |
Papier abc |
5.000 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
4 |
9906 |
InkJet-Dru y |
2 |
02.07.23 |
1600 |
Stanzl KG |
| 0012 |
1 |
9998 |
z-Bildschirm |
1 |
04.07.24 |
1900 |
Max OHG |
| ... |
|
|
|
|
|
|
|
| |
Schlüssel: #(AuftrNr, PosNr) |
|
Die beiden Attribute AuftrNr und PosNr stellen den Schlüssel der Relation dar, weil mit den Ausprägungen dieser Attribute jedes Tupel (jede Zeile) eindeutig identifiziert werden kann. |
|
5.24.2 Aufgabe |
|
|
a) Wie sind Einfüge-Anomalien definiert?
|
|
|
b) Welche Einfüge-Anomalien liegen in Aufträge_1NF vor und welches Problem erzeugen sie?
|
|
5.24.3 Lösung |
|
a) |
|
Eine Einfüge-Anamolie liegt vor, wenn ein neues (noch) unvollständiges Tupel nicht in die Relation eingetragen werden kann, weil unter den fehlenden Attributen ein Schlüssel- oder Fremdschlüsselattribut ist. Täte man das doch, wäre es ein (unsinniger) Verstoß gegen die Forderung nach Objektintegrität. |
Objektintegrität |
b) |
|
Nehmen wir neue Produkte mit ProdNr und ProdBez auf, so können wir sie in der Relation erst erfassen, wenn wir zumindest einen Auftrag mit Positionsnummer haben, in dem sie erscheinen. Sonst wäre eine Erfassung nicht möglich, da ja kein Schlüsselattribut vorliegen würde. Ähnliches gilt für das AuftragsDatum. Es kann erst erfasst werden, wenn die erste Position des Auftrags bekannt ist. Auch bei den Informationen zu Kunden gäbe es Probleme. Ein neuer Kunde könnte mit KuNr und KuName nur aufgenommen werden, falls auch ein Auftrag vorliegt. |
|
5.25 Lösche-Anomalie |
|
5.25.1 Gegenstand |
|
Relation Aufträge_1NF |
|
Diese Relation hält Informationen zu Aufträgen fest. Die AuftrNr identifiziert den Auftrag, die PosNr die einzelnen Positionen eines Auftrags. Jede Position bezieht sich auf ein Produkt, das durch ProdBez(eichnung) benannt und zusätzlich durch die ProdNr identifiziert wird. Menge gibt an, wieviele Produkte in der Position aufgeführt sind. Das Attribut KuNr identifiziert den Kunden, auf den sich der Auftrag bezieht. Die Kundennamen (KuName) sind nicht eindeutig. |
|
Aufträge_1NF |
|
| AuftrNr |
PosNr |
ProdNr |
ProdBez |
Menge |
Auftr-
Datum |
KuNr |
KuName |
| 0001 |
1 |
9901 |
Laser Dr xyz |
1 |
30.06.23 |
1700 |
Müller |
| 0001 |
2 |
9910 |
Toner xyz |
3 |
30.06.23 |
1700 |
Müller |
| 0001 |
3 |
9905 |
Papier abc |
5.000 |
30.06.23 |
1700 |
Müller |
| 0010 |
1 |
9905 |
Papier abc |
30.000 |
01.07.22 |
1201 |
Sammer |
| 0010 |
2 |
9910 |
Toner xyz |
1 |
01.07.22 |
1201 |
Sammer |
| 0011 |
1 |
9901 |
Laser Dr xyz |
1 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
2 |
9911 |
Tintenpatr x |
20 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
3 |
9905 |
Papier abc |
5.000 |
02.07.23 |
1600 |
Stanzl KG |
| 0011 |
4 |
9906 |
InkJet-Dru y |
2 |
02.07.23 |
1600 |
Stanzl KG |
| 0012 |
1 |
9998 |
z-Bildschirm |
1 |
04.07.24 |
1900 |
Max OHG |
| ... |
|
|
|
|
|
|
|
| |
Schlüssel: #(AuftrNr, PosNr) |
|
Die beiden Attribute AuftrNr und PosNr stellen den Schlüssel der Relation dar, weil mit den Ausprägungen dieser Attribute jedes Tupel (jede Zeile) eindeutig identifiziert werden kann.. |
|
5.25.2 Aufgabe |
|
|
a) Wie sind Lösche-Anomalien definiert?
|
|
|
b) Welche Lösche-Anomalien liegen in Aufträge_1NF vor und welches Problem erzeugen sie?
|
|
5.25.3 Lösung |
|
a) |
|
Eine Lösche-Anomalie liegt vor, wenn beim Löschen einer Information, die nur einen Teil des Tupels betrifft, auch die übrigen Attributswerte verloren gehen. |
|
b) |
|
Löscht man den Auftrag 0012, der nur eine Position hat, geht auch die Information verloren, dass z-Bildschirme die Produktnummer 9998 haben. |
|
5.26 Generalisierung / Spezialisierung |
|
Zum Muster Generalisierung / Spezialisierung vgl. [Staud 2021, Abschnitt 14.1]. |
|
5.26.1 Gegenstand |
|
Folgende Attribute liegen in einem Anwendungsbereich zu den Angestellten eines Unternehmens vor: Personalnummer (PersNr), Name (Name), Vorname (VName), Abteilungsbezeichnung (AbtBez), Einstellungsdatum (EinstDat). Für die Entwickler/innen sollen noch die Attribute Entwicklungsumgebung (EntwU), Programmiersprache (ProgSpr) (jeweils nur eine, die meist genutzte) erfasst werden. Für das leitende Management außerdem noch: Entgeltmodell (Entgelt) und Bereich, den sie verantworten (Bereich). |
|
5.26.2 Aufgaben |
|
|
a) Welches Muster findet sich in dieser Attributskonstellation?
|
|
|
b) Erstellen Sie für diesen Anwendungsbereich ein relationales Modellfragment. Erläutern Sie den Aufbau.
|
|
5.26.3 Lösung |
|
a) |
|
Diese Situation wird in der semantischen Modellierung und in der objektorientierten Theorie als Generalisierung / Spezialisierung (Gen/Spez) bezeichnet (vgl. [Staud 2021, Abschnitt 14.1]). |
|
b) |
|
In der relationalen Theorie kann dies wie folgt umgesetzt werden: alle gemeinsamen Attribute werden in eine eigene Relation getan, das ist die sog. Generalisierung. Die Attribute der Angestellten mit spezifischen Attributen kommen in eigene Relationen, die Spezialisierungen. Hier also: |
|
Angestellte (#PersNr, Name, VName, AbtBez, EinstDat) |
|
Entwickler (#PersNr, EntwU, ProgSpr) |
|
TopManagement (#PersNr, Entgelt, Bereich) |
|
In die Spezialisierungen wird der Schlüssel der Generalisierung übernommen. Obwohl diese keine Fremdschlüssel sind, werden sie in manchen Texten auch unterstrichen. Zu beachten ist: die Wertebereiche von Entwickler.PersNr und TopManagement.PersNr sind eine Teilmenge von Angestellte.PersNr. |
|
5.27 Einzel / Typ |
|
Zum Muster Einzel/Typ vgl. [Staud 2021, Abschnitt 14.2]. |
|
5.27.1 Gegenstand |
|
In einem Zoo sollen die größeren Tiere in einer Datenbank erfasst werden. Dabei haben sich folgende zu erfassenden Attribute ergeben: |
|
|
- Tiernummer (TNr, eindeutig), Namen (Name), Geburtstag (GebTag), Geschlecht.
|
|
|
- Gattung, zu der das Tier gehört (BezGatt). Anzahl der Tiere jeder Gattung (Anzahl). Bezeichnung der Tiergattung in einer umfassenden Tierklassifikation (Klassifikation)
|
|
|
- Nummer des Gebäudes (GebNr), in dem das Tier untergebracht ist.
|
|
5.27.2 Aufgaben |
|
|
a) Welches Muster findet sich in dieser Attributskonstellation?
|
|
|
b) Erstellen Sie für diesen Anwendungsbereich ein relationales Modell.
|
|
5.27.3 Lösung |
|
a) |
|
Hier muss erkannt werden, dass zum einen einzelne Tiere beschrieben werden, zum anderen Tiergattungen. Eine solche Struktur wird hier als Muster Einzel/Typ bezeichnet. |
|
b) |
|
Eine solche Attributskonstellation wird wie folgt modelliert. Für die Einzelobjekte (hier: einzelne Tiere) wird eine Relation angelegt. Schlüssel ist TNr: |
|
Tiere-Einzeln (#TNr, Name, GebTag, Geschlecht, GebNr. |
|
Für die Objekttypen (hier: Tiergattungen) wird ebenfalls eine Relation angelegt. Schlüssel ist hier BezGatt: |
|
Tiere-Gattung (#BezGatt, Anzahl, Klassifikation) |
|
Bleibt noch die Verknüpfung der beiden Relationen. Für Tiergattungen und Einzeltiere gilt eine 1:n-Beziehung. Deshalb wird die Gattungsbezeichnung in Tiere-Einzeln aufgenommen, so dass insgesamt folgendes Datenmodell entsteht: |
Verknüpfung |
Tiere-Einzeln (#TNr, Name, BezGatt, GebTag, Geschlecht, GebNr |
|
Tiere-Gattung (#BezGatt, Anzahl, Klassifikation) |
|
Diese beiden Relationen beschreiben den Sachverhalt absolut redundanzfrei. |
|
5.28 Aggregation |
|
Das Muster hier ist Enthaltensein ohne Existenzabhängigkeit. |
|
5.28.1 Gegenstand |
|
Hier geht es um die Modellierung von Attributen zu PCs und ihren Komponenten. Für die PC wird eine Inventarnummer (InvPC), die Bezeichnung des Prozessors (Proz) und die Größe des Arbeitsspeichers (ArbSp) erfasst. Für die Komponenten die Bezeichnung (BezKomp), eine Inventarnummer (InvNrKomp) und die Beschreibung der Funktion. |
|
Bei den Komponenten handelt es sich hier um solche (Grafikkarten, Speichermedien, …), die eine eigene Existenz aufweisen, die also z.B. auch mal in einen anderen PC wechseln. |
|
5.28.2 Aufgabe |
|
|
a) Welches Muster findet sich in dieser Attributskonstellation? Begründen Sie.
|
|
|
b) Erstellen Sie für diesen Anwendungsbereich ein relationales Modell.
|
|
5.28.3 Lösung |
|
a) |
|
Hier liegt eine enge Beziehung zwischen PC und Komponenten vor, ein Enthaltensein. Wegen der Forderung nach Eigenständigkeit handelt es sich um eine Aggregation und nicht um eine Komposition (vgl. dazu die nächste Aufgabe). |
|
b) |
|
Dieses Muster erfordert in relationalen Datenbanken folgende Modellierung. Eine Relation PC für die Personal Computer. Schlüssel ist InvPC, davon funktional abhängig sind ArbSp und Proz: |
|
PC (#InvPC, ArbSp, Proz) |
|
Eine Relation für die Komponenten. Schlüssel ist hier InvNrKomp, davon funktional abhängig sind Bez und Funktion: |
|
Komponenten (#InvNrKomp, Bez, Funktion) |
|
Die Aggregation wird durch eine eigene Relation PCKomp ausgedrückt. Wegen der 1:n-Beziehung (eine Komponente ist in genau einem PC) erhält PCKomp den Schlüssel InvNrKomp. Mit dem hinzugefügten Fremdschlüssel InvNrPC wird das Enthaltensein ausgedrückt. Das ist die relationale Lösung für das Muster Aggregation: |
Aggregation |
PCKomp (#InvNrKomp, InvNrPC) |
|
Damit kann eine Komponente datenbanktechnisch problemlos von einem zum anderen PC „wandern“ und sie kann in Komponenten auch „existieren“, falls sie nicht mehr in einem PC eingebaut ist. |
|
5.29 Komposition |
|
Hier geht es um das Muster Enthaltensein mit Existenzabhängigkeit. |
|
5.29.1 Gegenstand |
|
Es geht um Rechnungen. Erfasst werden sollen die Rechnungsnummer (ReNr), das Rechnungsdatum (ReDat), die Kundennummer (KuNr) und die Zahlungsvereinbarung (ZV). Außerdem für die Rechnungspositionen eine Positionsnummer (PosNr), die Artikelnummer (ArtNr), die Anzahl der Artikel auf der Position und der Einzelpreis (Preis) |
|
5.29.2 Aufgabe |
|
|
a) Welches Muster findet sich in dieser Attributskonstellation? Begründen Sie.
|
|
|
b) Erstellen Sie für diesen Anwendungsbereich ein relationales Modell.
|
|
5.29.3 Lösung |
|
a) |
|
Zu unterscheiden sind Rechnungsköpfe (ReKöpfe) und Rechnungspositionen (RePos). Zwischen diesen liegt eine sehr enge Beziehung vor, ein Enthaltensein mit Existenzabhängigkeit. Diese wird als Komposition bezeichnet. Vgl. dazu [Staud 2021, Abschnitt 14.4]. |
|
b) |
|
Es sind die zwei Relationen ReKöpfe (Rechnungsköpfe) und RePos (Rechnungspositionen) anzulegen. ReKöpfe hat den Schlüssel ReNr, von dem die Attribute ReDat, KuNr und ZV funktional abhängig sind: |
|
ReKöpfe (#ReNr, ReDat, KuNr, ZV) |
|
RePos erhält die Attribute PosNr, ArtNr, Anzahl und Preis. Wegen der 1:n-Beziehung zwischen ReKöpfe und RePos erhält RePos einen zusammengesetzten Schlüssel: (ReNr, PosNr). Außerdem wird RePos.ReNr zum Fremdschlüssel: |
|
RePos (#(ReNr, PosNr), ArtNr, Anzahl, Preis) |
|
Dieser Schlüssel ist die relationale Antwort auf das Muster Komposition. Damit gehören Rechnungsköpfe und -positionen untrennbar zusammen und die Rechnungspositionen werden gelöscht (sollten gelöscht werden!), wenn der zugehörige Rechnungskopf gelöscht wird. |
|
5.30 UN zu 1NF |
|
5.30.1 Aufgabe |
|
Wie bringt man eine unnormalisierte Relation mit Mehrfacheinträgen (Wiederholungsgruppen) in einem Attribut in die 1NF und weiter. Erläutern Sie, auch mit Hilfe eines aussagekräftigen Beispiels. |
|
5.30.2 Lösung |
|
Gibt es nur Mehrfacheinträge in einem Attribut, kann man zur Tupelvermehrung greifen (vgl. [Staud 2021, Abschnitt 7.3]). Dabei wird für jeden der Mehrfacheinträge ein eigenes Tupel angelegt. Der Schlüssel der neuen Relation besteht aus dem alten Schlüssel und dem Attribut mit Mehrfachausprägungen. |
Tupelvermehrung |
Die Relation Personal_UN beschreibt Angestellte eines Softwarehauses mit ihrem Namen, der Personalnummer und einer Kurzbezeichnung der Programmiersprachen, die sie beherrschen. |
Beispiel Personal_UN |
Personal_UN |
|
| #PersNr |
Name |
ProgSpr |
| 123 |
Maier |
C, COBOL, PHP, C++ |
| 234 |
Primus |
C++, Java, C |
| 345 |
Wanderer |
C#, Java |
| 456 |
König |
PHP |
| ... |
|
|
| |
Die Tupelvermehrung führt zu folgender Lösung: |
|
Personal_1NF |
|
| PersNr |
ProgSpr |
Name |
| 123 |
C |
Maier |
| 123 |
COBOL |
Maier |
| 123 |
PHP |
Maier |
| 123 |
C++ |
Maier |
| 234 |
C++ |
Primus |
| 234 |
Java |
Primus |
| 234 |
C |
Primus |
| 345 |
C# |
Wanderer |
| 345 |
Java |
Wanderer |
| 456 |
PHP |
König |
| ... |
|
|
| |
Der Schlüssel der normalisierten Relation ist #(PersNr, ProgSpr). Die Relation ist in 1NF, aber nicht in 2NF, und weist dementsprechend Redundanzen auf. |
|
|
|

|
|
|
|
6 Entity Relationship Modellierung |
|
Eine Einführung in die Entity Relationship – Modellierung findet sich hier: |
|
http://www.staud.info/erm2/er_t_1.htm |
|
Die Entity Relationship Modellierung ist ein Teilgebiet der sog. Semantischen Datenmodellierung. Diese hatte sich ab den 1970-er Jahren zum Ziel gesetzt, mehr Semantik als damals mit der relationalen Modellierung möglich war, in die Datenmodelle zu bringen. Heute wird sie vor allem in einführenden Lehrverantaltungen zur Datenbanktheorie und -praxis als Ausgangspunkt der Datenmodellierung verwendet. |
Semantische Datenmodellierung |
Im Bereich der Entity Relationship – Modellierung sind die Begriffe Entität (für Objekte) und Entitätstypen (für die Zusammenfassung gleich strukturierter Entitäten) üblich. Vgl. |
Entitäten und Entitätstypen |
http://www.staud.info/erm2/er_t_1.htm |
|
für eine Einführung. |
|
Das Ergebnis der ER-Modellierung ist ein grafisches Modell. Vgl. obige Quelle und die nachfolgenden Beispiele. |
|
Folgende Aufgaben sind zu lösen, um ein korrektes ER-Modell (ERM) zu erstellen: |
|
- Entitätstypen: Entitätstypen identifizieren. Dafür ist zuerst ein Schlüssel aus einem Attribut oder aus mehreren festzulegen. Die Vorgaben dafür sind so, dass sich alle Attribute auf alle Entitäten des Entitätstyps beziehen müssen. Damit werden semantisch bedingte Leereinträge in der späteren Datenbank vermieden. Mehrfacheinträge sind zugelassen, werden aber grafisch gekennzeichnet.
- Beziehungstypen: Beziehungstypen einschließlich der Min-/Max-Angaben festlegen. Wegweisend ist hier die Regel: Alle Entitätstypen sind (zumindest lose) miteinander verknüpft. Attribute von Beziehungstypen klären.
- Generalisierung / Spezialisierung: Auftretende Muster Gen/Spez klären und mit dem dafür vorgesehenen Methodenelement anlegen.
- Aggregation: Auftretende Muster Aggregation klären und mit dem dafür vorgesehenen Methodenelement anlegen.
- Komposition: Auftretende Muster Komposition klären und mit dem dafür vorgesehenen Methodenelement anlegen.
- Zeitaspekte: Zeitliche Aspekte klären und modellieren, auch die in der Anforderung vergessenen.
|
|
|
|
6.1 Mitglieder / Adressen |
|
In dieser einführenden Aufgabe geht es um die einfache Zuordnung von Attributen zu Entitätstypen. |
|
6.1.1 Anforderungen |
|
Im Rahmen des Datenbankdesigns für einen Sportverein wurden für die Mitglieder folgende Anforderungen formuliert: |
|
Die Mitglieder des Vereins werden durch Name, Vorname (VName), Telefon (Tel), Geburtstag (GebTag), Alter, eine Mitgliedsnummer (MiNr) und ihre Adressen (PLZ, Ort, Straße) festgehalten. Erfasst wird außerdem der Tag des Eintritts (Eintritt) in den Verein. |
|
Erstellen Sie dazu ein ER-Modell. Nutzen Sie auch die Möglichkeit, Attribute zu gruppieren. |
|
6.1.2 Lösung |
|
Sofort erkennbar als Entitätstyp sind die Vereinsmitglieder. Schlüssel ist die Mitgliedsnummer (MiNr). Die problemlosen beschreibenden Attribute sind VName, Name, Tel, GebTag und Alter. Problemlos sind sie deshalb, weil es genau eine Ausprägung je Mitglied gibt. Name und VName werden gruppiert zu Name. Dies dient nur der Übersichtlichkeit, es hat keine inhaltliche oder methodische Bedeutung. |
|
Das Attribut Alter ist ein sog. abgeleitetes Attribut, das mit gestrichelter Linie dargestellt werden muss. Seine Einträge werden vom Datenbanksystem berechnet. Hier aus dem abgespeicherten Geburtsdatum (GebTag) und dem vom System gelieferten Tagesdatum. Mit dem Datenbanksystem wird auch der Aktualisierungszeitpunkt festgelegt. |
abgeleitetes Attribut |
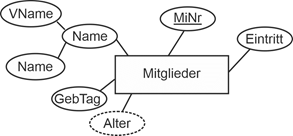
|
|
Abbildung 6.1-1: Entitätstyp Mitglieder |
|
Etwas mehr Aufwand verlangen die Adressangaben. Da es mehrere Adressen pro Mitglied gibt, erhalten sie einen eigenen Entitätstyp Adressen. Diese erhalten die Attribute PLZ, Ort und Straße. Ergänzen muss man einen Schlüssel AdrId. Auch hier wurden die Attribute der Übersichtlichkeit wegen gruppiert. |
|
|
|
Abbildung 6.1-2: Entitätstyp Adressen |
|
Bleibt noch die Verknüpfung der beiden Entitätstypen. Hier wird ein Beziehungstyp M_Adr eingerichtet. Auf Nachfrage erfahren wir, dass nicht nur ein Mitglied mehrere Adressen haben kann, sondern unter einer Adresse auch mehrer Mitglieder. Somit egibt sich die Kardinalität n:m. Da Mitglieder nur erfasst werden, wenn mindestens eine Adresse vorliegt und Adressen nur, wenn mindestens ein Mitglied dort wohnt, ergeben sich die Min-/Max-Angaben 1,n : 1,m. |
|
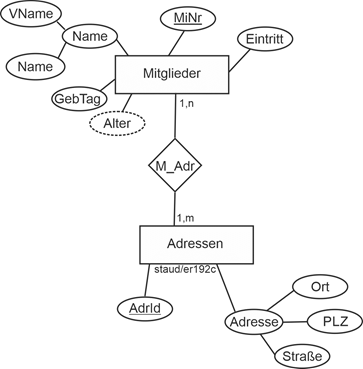
|
|
Abbildung 6.1-3: ER-Modell Mitglieder / Adressen |
|
6.2 Mitgliedergruppen |
|
In dieser einführenden Aufgabe geht es um die Bewältigung von Ähnlichkeit mittels Generalisierung / Spezialisierung. |
|
6.2.1 Ausgangspunkt |
|
Ausgangspunkt dieser Aufgabe ist das ER-Modell der vorigen Aufgabe, aus darstellungstechnischen Gründen grafisch etwas umgestellt. |
|
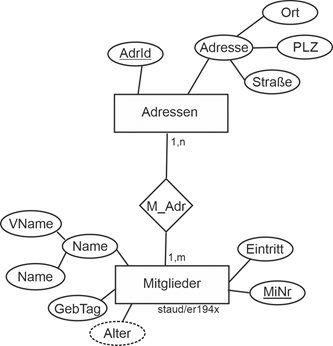
|
|
Abbildung 6.2-1: ER-Modell Mitglieder / Adressen |
|
6.2.2 Anforderungen |
|
Obiges Datenmodell soll ergänzt werden. Zusätzlich soll für die Vereinsmitglieder erfasst werden: |
|
|
(1) Bei ausgetretenen Mitgliedern der Grund (Grund) und Tag des Austritts (Austritt).
|
|
|
(2) Für verstorbene Mitgliedern der Todestag (Todestag). Außerdem wird festgehalten, wieviele Jahre das Mitglied im Verein war (AnzJahre).
|
|
|
(3) Die telefonischen Verbindungen (Telefon). Dies können durchaus mehrere sein. Z.B. neben dem Festnetzanschluss noch ein mobiler Anschluss.
|
|
Ergänzen Sie das ER-Modell aus obiger Aufgabe. |
|
6.2.3 Lösungsschritte |
|
Anforderung (1) |
|
Da die Daten der ausgetretenen Mitglieder erhalten bleiben sollen, wie wir auf Nachfrage erfahren, kann für die ausgetretenen Mitglieder ein neuer Entitätstyp als Spezialisierung von Mitglieder eingerichtet werden. Er erhält die Attribute Austritt und Grund. |
|
Anforderung (2) |
|
Auch für die verstorbenen Mitglieder gilt, dass ihre Daten erhalten bleiben sollen. Deshalb kann ebenfalls ein neuer Entitätstyp als Spezialisierung von Mitglieder eingerichtet werden. Er erhält die Attribute Todestag und AnzJahre. AnzJahre ist ein abgeleitetes Attribut, dessen Einträge aus dem Eintrittsdatum und dem Todestag vom Datenbanksystem berechnet werden. |
|
Anforderung (3) |
|
Auf den ersten Blick wird man mehrere telefonische Verbindungen einfach als mehrwertiges Attribut beim Entitätstyp Mitglieder einfügen. Dies wäre aber nicht sinnvoll, da für verstorbene und ausgetretene Mitglieder die Telefonverbindungen nicht erfasst werden sollen. Da bleibt nur, eine weitere Spezialisierung für nicht ausgetretene und nicht verstorbene Mitglieder anzulegen. Sie soll Aktive Mitglieder genannt werden und erhält Telefon als Attribut. |
|
Dabei wird deutlich, dass auch das Attribut Alter hierher gehört, denn dessen Bestimmung macht nur Sinn für aktive Mitglieder. |
|
6.2.4 Lösung |
|
Damit ergibt sich das ER-Modell der folgenden Abbildung. |
|
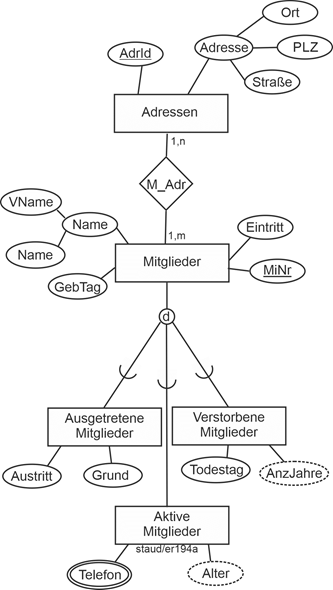
|
|
Abbildung 6.2-2: ER-Modell Mitglieder / Adressen |
|
6.3 Sportverein |
|
Aus eigenen Erfahrungen und aus vielen Diskussionen mit Teilnehmern von Schulungen und Studierenden in Vorlesungen weiß ich, dass reale Sportvereine eine viel reichere und tiefere Semantik haben. Ich bitte daher vor allem alle Sportvereinsmitglieder um Verzeihung für die Einfachheit des Beispiels, denke aber, dass es trotzdem seine Aufgabe erfüllen kann. |
|
Bei dieser Aufgabe werden die Lösungsschritte sehr viel ausführlicher erläutert als in den übrigen Aufgaben, um eventuelle Wissenslücken beim Leser aufzufüllen bzw. um Wissen zu vertiefen. |
|
6.3.1 Anforderungen |
|
Ein Sportverein beschließt, seine Aktivitäten (Mitgliederverwaltung, Sportveranstaltungen, usw. ) in Zukunft computergestützt abzuwickeln. Dazu soll im ersten Schritt eine einfache Datenbank aufgebaut werden, für die folgende Spezifikationen festgehalten werden: |
|
- Der Sportverein ist in Abteilungen gegliedert. Eine für Handball, eine für Fußball. Weitere können in der Zukunft dazukommen.
- Jede Abteilung hat einen Leiter.
- Jede Abteilung hat mehrere Mannschaften.
- Von jeder Mannschaft werden die Spieler, der Kapitän und die Liga festgehalten, in der sie spielt (Bundesliga, usw.)
- Jede Mannschaft hat einen Trainer.
- Die Begegnungen von Mannschaften des Vereins mit Datum, gegnerischer Mannschaft und Ergebnis sollen festgehalten werden.
- Die Mitglieder des Vereins werden durch Name, Vorname, PLZ, Ort, Straße, Telefon, Geburtstag, Alter und eine Mitgliedsnummer festgehalten.
|
|
Außerdem wird für die Mitglieder erfasst, ob es sich um ein passives oder ein aktives Mitglied handelt. Für jedes aktive Mitglied wird dann noch festgehalten, welche Sportart es in welcher Leistungsstufe betreibt; für die passiven Mitglieder wird erfasst, für welche ehrenamtliche Tätigkeit sie zur Verfügung stehen. |
|
6.3.2 Erste Schritte |
|
Wie sehen nun die konkreten Modellierungsschritte aus? Sinnvoll ist es, zuerst die Entitätstypen zu suchen. Dies ist dann allerdings keine endgültige Festlegung, sondern eine, die im Verlauf der Modellierung auch wieder korrigiert werden kann. |
|
Beginnen wir also mit Entitäten und Entitätstypen. Diese erkennt man im modellierungstechnischen Sinne daran, dass es sich erstens um Objekte im allgemeinen Sinn handelt und dass zweitens diese Objekte durch Attribute beschrieben werden. Zweiteres ist von zentraler Bedeutung, denn sonst kann es sich auch um ein Attribut handeln, wie auch dieses Beispiel gleich zeigen wird. |
Entitäten und Entitätstypen erkennen |
Natürlich etablieren auch andere nicht-konventionelle Attribute einen Entitätstyp. Z.B. Grafiken, Bilder, Videos, usw. Allerdings sind diese nur Ergänzungen der Basisbeschreibung durch Attribute, die auf jeden Fall vorhanden sein muss. |
|
Hier ist ein Entitätstyp sofort erkennbar, die Mitglieder. Die Vereinsmitglieder existieren - auch im allgemeinen Sinn - und sie werden durch Attribute beschrieben: |
|
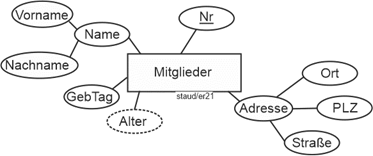
|
|
Abbildung 6.3-1: Entitätstyp Mitglieder |
|
Offen bleibt nun noch die Frage, wie die Eigenschaft, aktives oder passives Vereinsmitglied zu sein, erfasst wird. Ginge es nur um diese Eigenschaft, würde einfach ein Attribut „aktiv/passiv“ mit diesen zwei Eigenschaften an den Entitätstyp Mitglieder angefügt. Nun ist es hier aber so, dass für die aktiven und passiven Mitglieder jeweils unterschiedliche Attribute festgehalten werden sollen. Deshalb müssen diese Teilgruppen der Mitglieder getrennt erfasst und - da sie ja als Mitglieder auch gemeinsame Attribute haben - in der im ersten Teil vorgestellten Notation als Generalisierung / Spezialisierung angelegt werden: |
aktiv / passiv |
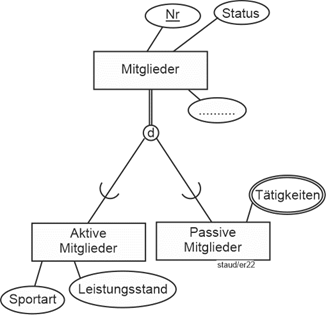
|
|
Abbildung 6.3-2: Aktive und passive Mitglieder in einer Generalisierung / Spezialisierung |
|
Soweit der erste Entitätstyp Mitglieder. Hinzugenommen wurde ein Attribut Status mit den Ausprägungen passiv und aktiv, mit dem es später beim Umgang mit der Datenbank möglich ist, die Spezialisierungen gezielt anzusprechen. Dies verlangt die Theorie nicht, empfiehlt sich aber aus Gründen der Pragmatik. |
Differenzierung |
Das Attribut mit den Punkten soll oben und im folgenden die schon vorher eingeführten Attribute andeuten. |
Hinweis: |
Die aktiven Mitglieder erhalten die Attribute Sportart (derzeit nur Handball oder Fußball) und Leistungsstand. Es wird davon ausgegangen, dass ein Spieler nur eine Sportart betreibt. Das Attribut ehrenamtliche Tätigkeit der passiven Mitglieder erfasst in einer irgendwie verkodeten Form, für was das Mitglied zur Verfügung steht. Es handelt sich um ein mehrwertiges Attribut. |
|
Oftmals möchte man bei einer Spezialisierung ausdrücken, dass alle Entitäten des übergeordneten Typs an der Spezialisierung teilnehmen müssen. Dies geschieht, wie in der obigen Abbildung, durch einen Doppelstrich zwischen dem übergeordneten Typ und dem d-Kreis. Er signalisiert hier, dass alle Mitglieder entweder aktive oder passive Mitglieder sein müssen. Eine andere Mitgliedschaft gibt es somit modelltechnisch nicht. Alternativ könnten hier statt der Spezialisierung passive Mitglieder nur die ehrenamtlich tätigen Mitglieder erfasst sein. Dann müsste der Doppelstrich beseitigt werden, da es dann Mitglieder gäbe, die in keine der beiden Spezialisierungen eingehen (die passiven, die nicht ehrenamtlich tätig sind). |
Totale
Beteiligung |
Bei Beziehungen wird „totale Beteiligung“ durch die Min-/Max-Angaben festgelegt. Steht als Mindestwert ein Wert größer 0 da, müssen alle Entitäten des Entitätstyps an der Verbindung teilhaben. |
|
6.3.3 Die Mannschaften |
|
Betrachten wir nun die Mannschaften. Sie tauchen mit folgenden Beschreibungen auf: |
|
- Jede Abteilung hat mehrere Mannschaften, insofern könnte „Mannschaft“ ein Attribut von Abteilung sein.
- Von jeder Mannschaft werden Spieler, Kapitän, Liga, Trainer und Begegnungen festgehalten.
|
|
Letzteres macht die Mannschaften zu Entitätstypen, da sie durch weitere Attribute beschrieben werden. Die Klärung der Frage, ob sie evtl. ein Beziehungstyp sein können, wird auf eine spätere Phase des Modellierungsvorgangs verschoben. Damit ergibt sich folgender erster Entwurf: |
|
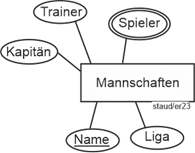
|
|
Abbildung 6.3-3: Entitätstyp Mannschaften |
|
Hinzugefügt wurde ein Attribut Name, mit der Bezeichnung der Mannschaften. Das Attribut Spieler ist mehrwertig, da jede Mannschaft mehrere Spieler hat. |
|
Auf die Aufnahme eines Attributs Begegnung wurde verzichtet, da die Begegnungen durch weitere Attribute zu einer eigenständigen Existenz kommen. |
|
6.3.4 Begegnungen |
|
In den Anforderungen wurde festgelegt, dass alle Begegnungen von Mannschaften des Vereins mit Tagesdatum, Gegner und Ergebnis festgehalten werden sollen. Damit entsteht ein entsprechender Entitätstyp. Gleichzeitig wird hier der erste Beziehungstyp deutlich, der mit M-B bezeichnet werden soll und schlicht die Tatsache beschreibt, dass die Mannschaften des Vereins an den Begegnungen teilnehmen. Da auch nur solche Begegnungen erfasst werden, handelt es sich um einen singulären Entitätstyp, der durch ein Rechteck mit Doppellinie dargestellt wird. Der zugehörige Beziehungstyp erhält ebenfalls eine solche. |
|
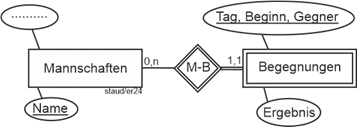
|
|
Abbildung 6.3-4: Singulärer Entitätstyp Begegnungen |
|
Das Attribut Beginn wurde zusätzlich aufgenommen, um mehrere Begegnungen an einem Tag, z.B. im Rahmen eines Turniers, unterscheiden zu können. Schlüssel für diesen Entitätstyp sind die Attribute Tag, Beginn und Gegner zusammen. |
|
Zu beachten ist, dass es nur um die Spiele des betrachteten Vereins geht, nicht um alle Spiele einer Liga, was die Situation verändern würde. |
|
Als Schlüssel wurde hier ein zusammengesetzter genommen, der bei der Überführung in konkretere Strukturen (Z.B. in Relationen) um den Schlüssel von Mannschaften ergänzt werden müsste. Dies ist typisch für singuläre Entitätstypen. Ihre Existenzabhängigkeit zeigt sich auch darin, dass ihr Schlüssel um den des anderen Entitätstyps ergänzt werden muss. |
Existenzabhängigkeit |
6.3.5 Abteilungen |
|
Jetzt müssen noch die Abteilungen betrachtet werden. Für sie wurde in den Anforderungen festgehalten, dass der Verein in Abteilungen gegliedert ist (Handball und Fußball), dass jede Abteilung eine/n Leiter/in und mehrere Mannschaften hat. |
|
In Konfrontation mit den schon erstellten Modellfragmenten lässt sich damit festhalten, dass Abteilungen ein Entitätstyp mit den Attributen Leiter und Sportart ist. Die Tatsache, welche Mannschaft zu welcher Abteilung gehört, wird nicht durch ein Attribut festgehalten, sondern durch einen Beziehungstyp M-A zwischen Mannschaften und Abteilungen: |
|
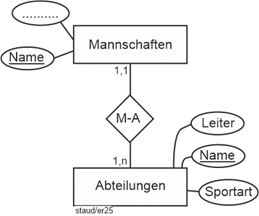
|
|
Abbildung 6.3-5: Mannschaften in Abteilungen |
|
6.3.6 Zusammenstellung |
|
Damit sind die wichtigsten Komponenten des zu erstellenden Datenmodells realisiert. In der folgenden Abbildung werden sie zusammengestellt. Die Min-/Max-Angaben in der Abbildung haben folgende Bedeutung: |
|
- 1,1 bei Mannschaften zu Abteilungen (M-A): Eine Mannschaft gehört zu genau einer Abteilung.
- 1,n bei Abteilungen zu Mannschaften (M-A): Eine Abteilung hat mindestens eine Mannschaft.
- 0,n bei Mannschaften zu Begegnungen (M-B): Eine Mannschaft hat an keiner (z.B., wenn sie neu aufgestellt wurde) oder an mehreren Begegnungen teilgenommen.
- 1,1 bei Begegnungen zu Mannschaften (M-B): Eine Begegnung wird nur dann als solche aufgenommen, wenn genau eine Mannschaft „unseres“ Vereins teilgenommen hat. Wir schließen hier also bewusst Begegnungen zwischen zwei Mannschaften unseres Vereins aus.
|
|
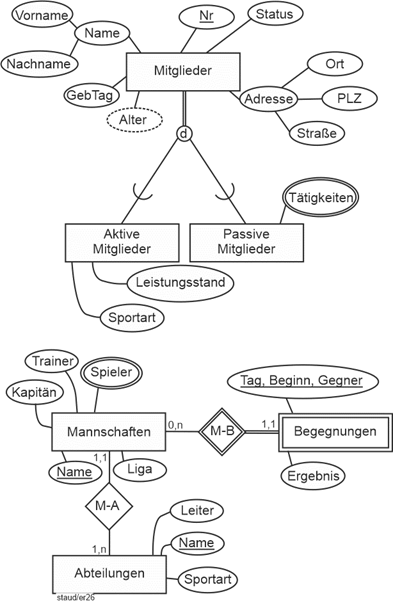
|
|
Abbildung 6.3-6: Entity Relationship-Modell Sportverein - Erster Versuch |
|
Dieses Gesamtmodell ist nun aber in einem wichtigen Punkt fehlerhaft: Eine Trennung eines Datenmodells in zwei unverbundene Teile ist nicht möglich. So etwas gibt es nicht, da ein Datenmodell ja gerade dadurch ausgezeichnet ist, dass zusammengehörige Informationen über einen Weltausschnitt verwaltet werden. Sonst sind es zwei Datenmodelle mit zwei verschiedenen Datenbanken. |
Defizit: Trennung |
6.3.7 Lösung durch Verschmelzung |
|
Bei genauerer Betrachtung zeigt sich nun aber, dass natürlich die Mitglieder mit den organisatorischen Aspekten des Vereins auf vielfältige Weise verknüpft sind. Insbesondere sind dies folgende Aspekte: |
|
- Aktive Mitglieder spielen in Mannschaften
- Aktive Mitglieder können Kapitän einer Mannschaft sein
- Aktive Mitglieder trainieren die Mannschaften (wir gehen davon aus, dass die Trainer als aktive Mitglieder zum Verein gehören)
- Aktive Mitglieder leiten die Abteilungen
|
|
Alle diese Informationen wurden im obigen ersten Entwurf - herrührend von den Modellkomponenten - als Attribute von Entitätstypen definiert. Dies muss nun geändert werden. |
|
Beginnen wir mit den Spielern der Mannschaften. Diese Information sollte nicht als mehrwertiges Attribut von Mannschaften erfasst werden, sondern als Beziehungstyp zwischen Mannschaften und Aktive Mitglieder: AM-S. Damit ist nicht nur die Information der Mannschaftszugehörigkeit eindeutig erfasst, sondern es stehen auch die Adressen der Mannschaftsmitglieder zur Verfügung und die Namen der Spieler werden nur einmal erfasst, im Mitgliederverzeichnis, wo sie hingehören. |
Korrektur |
Ganz ähnlich bei der Erfassung der Trainer. Bisher als Attribut von Mannschaft erfasst, werden sie nun zu einer Beziehung zwischen Trainern und Mannschaften mit dem Beziehungstyp AM-T. |
|
Die Kapitäne der Mannschaften werden ebenfalls durch eine Beziehung zwischen Mannschaften und Aktive Mitglieder erfasst, AM-K, denn die Kapitäne sollen in unserem Datenmodell aktive Mitglieder sein. |
|
Die Leiter der Abteilungen werden dementsprechend als Beziehung zwischen Abteilungen und Aktive Mitglieder erfasst: AM-A. |
|
In der folgenden Abbildung nun das Gesamtmodell mit den besprochenen Korrekturen. Weggefallen sind die Attribute, mit denen vorher die Beziehungen festgelegt wurden. Die weiteren Min-/Max-Angaben sind ebenfalls angegeben. Sie bedeuten: |
|
- 0,1 bei Aktive Mitglieder zu Mannschaften und Beziehung AM-S: Ein aktives Mitglied spielt in maximal einer Mannschaft. Selbstverständlich wäre an der zweiten Position auch ein höherer Wert möglich, falls die Semantik es erfordert. Ebenso ein Wert größer Null an der ersten Position.
- 0,1 bei Aktive Mitglieder zu Mannschaften und Beziehung AM-T: Ein aktives Mitglied kann in maximal einer Mannschaft Trainer sein.
- 0,1 bei Aktive Mitglieder zu Mannschaften und Beziehung AM-K: Ein aktives Mitglied ist in maximal einer Mannschaft Kapitän.
- 0,1 bei Aktive Mitglieder zu Abteilungen und Beziehung AM-A: Ein aktives Mitglied leitet maximal eine Abteilung.
- 1,1 bei Mannschaften zu Aktive Mitglieder und Beziehung AM-T: Eine Mannschaft wird von genau einem aktiven Mitglied trainiert.
- 11,15 bei Mannschaften zu Aktive Mitglieder und Beziehung AM-S: Eine Mannschaft besteht aus mindestens 11 und maximal 15 Spielern (aktive Mitglieder).
- 0,1 bei Mannschaften zu Aktive Mitglieder und Beziehung AM-K: Eine Mannschaft hat maximal einen Kapitän.
|
|
Für alle diese Festlegungen gilt, dass die Semantik und deren modelltechnische Umsetzung auch eine andere sein kann. |
|
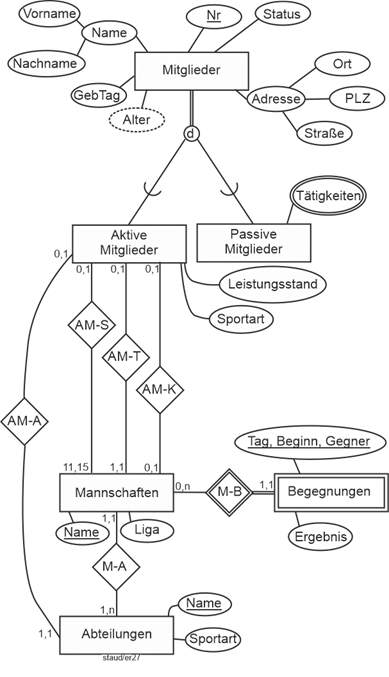
|
|
Abbildung 6.3-7: Entity Relationship-Modell Sportverein |
|
6.4 PC-Beschaffung |
|
6.4.1 Anforderungen |
|
In einem Unternehmen soll der Vorgang der PC-Beschaffung durch eine Datenbank festgehalten werden. Dafür soll ein ER-Modell erstellt werden. Folgende Festlegungen ergaben sich in den Interviews, die im Vorfeld mit den Betroffenen geführt wurden. Die Attributsnamen wurden, soweit möglich, auch gleich geklärt: |
Vgl. Abschnitt 1.4 zur Typographie |
|
(1) Jeder PC erhält eine Inventarnummer (InvPC). Neben dieser wird der Prozessortyp (Proz) und die Größe des Arbeitsspeichers (ArbSp) festgehalten. Für die PC der Entwickler wird festgehalten, welche Programmiersprachen (PS) installiert sind und welches die hauptsächlich verwendete Entwicklungsumgebung (EntwUmg) ist.
|
|
|
(2) Für jede Festplatte wird festgehalten: Bezeichnung und Größe (PlBez, Größe) sowie die Zugriffsgeschwindigkeit (Zugriff), die Seriennummer (SerNr) (diese ist eindeutig, auch über Hersteller hinweg) und der Tag, an dem die Platte in den Rechner eingebaut wurde (TagEinb).
|
|
|
(3) Ein PC kann mehrere Festplatten haben, eine Festplatte ist aber nur einem PC zugeordnet.
|
|
|
(4) Für jeden PC wird weiterhin festgehalten, wer ihn nutzt (PersNr), in welcher Abteilung er steht (AbtBez) und wer der Abteilungsleiter der Abteilung ist (AbtLeiter).
|
|
|
(5) Ein PC wird von genau einem Mitarbeiter genutzt. Jeder Mitarbeiter nutzt auch einen PC, es gibt einzelne Mitarbeiter, die mehrere PC nutzen.
|
|
|
(6) Die Nutzer werden durch ihre Personalnummer (PersNr), den Namen (Name, Vorname) und ihre Telefonnummer (Tel) erfasst. Außerdem wird festgehalten, ab welchem Datum er/sie den PC nutzt (Beginn). Gibt er/sie ihn später ab, wird auch dies festgehalten (Ende).
|
|
6.4.2 Lösungsschritte |
|
Auch hier gilt: Realweltphänomene, die durch Attribute identifiziert und durch mindestens ein Attribut beschrieben werden, sind Kandidaten für die elementaren Modellfragmente (hier: Entitätstypen). |
PC |
Der erste Punkt liefert auch gleich einen Entitätstyp. Wir nennen ihn PC und weisen ihm den Schlüssel InvPC sowie die beschreibenden Attribute Proz und ArbSp zu. Die Formulierung „Für die PC der Entwickler …“ gibt den Hinweis auf eine Generalisierung / Spezialisierung. Wir können daher die Spezialisierung Entw-PC mit den Attributen ProgSpr (mit Mehrfacheinträgen) und EntwU(mgebung) anlegen. Die Tatsache, dass bei ProgSpr (Programmiersprachen) pro Entwickler-PC mehrere Einträge möglich sind, wird durch die Doppellinie ausgedrückt. |
|
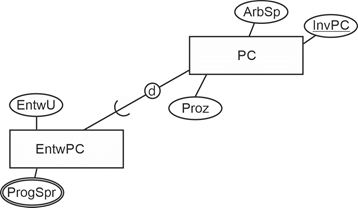
|
|
Abbildung 6.4-1: Generalisierung / Spezialisierung mit PC und EntwPC |
|
Vgl. zur grafischen Gestaltung von ER-Modellen: www.staud.info/erm2/er_t_1.htm |
|
Der zweite Punkt signalisiert einen Entitätstyp zu Festplatten (FP). Beim Studium der Attribute erkennen wir aber, dass zum einen einzelne Festplatten beschrieben werden (Seriennummer, SerNr; Tag des Einbaus, TagEinbau), zum anderen Gerätetypen (Bezeichnung und Größe (PlBez, Größe), Zugriffsgeschwindigkeit (Zugriff)). Es liegt also das Muster Einzel/Typ vor. Entsprechend müssen zwei Entitätstypen angelegt werden: FP-Typen und FP-Einzeln. Diese werden durch einen Beziehungstyp (FP-T/E) verknüpft. Die Kardinalität (Typen => Einzeln) ist 1:n, die Min-/Max-Angaben sind 1,n bzw. 1,1 (vgl. auch Abschnitt 2.4.1). Damit ergibt sich das folgende Fragment. |
Festplatten |
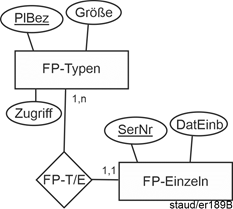
|
|
Abbildung 6.4-2: Muster Einzel/Typ für Festplatten |
|
Punkt 3 klärt die Beziehung zwischen PC und Festplatten. Um diese eindeutig zu erfassen, sollte sie mit Hilfe von FP-Einzeln realisiert werden. Für den dabei entstehenden Beziehungstyp PC-F gelten (für die Richtung PC => FP-Einzeln) die Kardinalität 1:n und die Min-/Max-Angaben 1,n : 1,1. Vgl. die folgende Abbildung. Wir legen also fest, dass jede Festplatte sofort nach Beschaffung einem PC zugeordnet werden muss und dass jeder PC mindestens eine Festplatte besitzt. |
Beziehungstyp PC-F |
Punkt 4 klärt die organisatorische Zuordnung der PC. Da ist zum einen der Nutzer oder die Nutzerin, die durch die Personalnummer (PersNr) identifiziert wird. Ein Blick auf den letzten Punkt der Anforderungsbeschreibung zeigt, dass die Nutzer tatsächlich auch in der Datenbank erfasst werden, sodass der Schlüssel PersNr noch um weitere Attribute ergänzt wird. Somit kann ein Entitätstyp Nutzer mit den Attributen PersNr, Name, Vorname, Tel(efon) angelegt werden. |
Nutzer |
In Punkt 4 wird auch festgelegt, dass die Abteilung festgehalten wird, die den PC erhält. Dies könnte einfach zu einem weiteren Attribut von PC führen. Da aber für die Abteilungen auch der Abteilungsleiter festgehalten wird (AbtLeiter), muss ein eigener Entitätstyp Abteilungen angelegt werden mit den Attributen AbtBez und AbtLeiter. Die Verknüpfung mit PC erfolgt durch einen Beziehungstyp PC-A mit der Kardinalität 1:n und den Min-/Max-Angaben 0,n : 1,1 (Abteilungen => PC). Es wird hier also angenommen, dass man auch Abteilungen in der späteren Datenbank anlegen möchte, denen noch kein PC zugewiesen ist und dass jeder erfasste PC sofort einer Abteilung zugeordnet wird. |
Abteilung |
Punkt 5 klärt die Nutzung der PC durch die Mitarbeiter, also den Beziehungstyp zwischen PC und Nutzer. Er soll PC-N genannt werden. Die Min-/Max-Angaben (Nutzer=>PC) sind 1,n : 1,1. |
Nutzung |
Punkt 6 verlangt, dass Beginn und Ende der Nutzungszeit festgehalten werden. Wohin gehören diese Attribute, worauf beziehen sie sich? Sicherlich nicht auf den PC, dieser kann ja von verschiedenen Personen genutzt werden. Sicherlich auch nicht auf die Nutzer, denn diese nutzen verschiedene PC zu verschiedenen Zeiten. Sie gehören auf die Kombination PC/Nutzer, denn genau dafür sind sie jeweils eindeutig. Dies drückt der Beziehungstyp PC-N aus. Deshalb fügen wir hier die beiden Attribute dazu. |
Nutzungszeit |
Damit sind die verschiedenen Aspekte der Anforderungen modelliert und die Modellfragmente können zusammengefügt werden. |
|
6.4.3 Lösung |
|
In der Grafik werden nur die Min-/Max-Angaben ausgewiesen. Die Kardinalitäten können von diesen abgeleitet werden. |
|
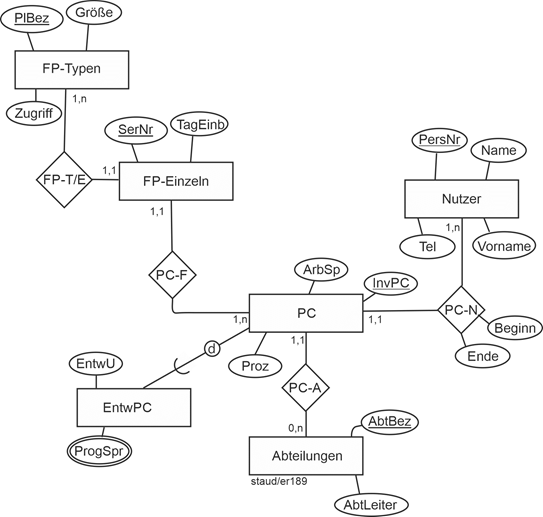
|
|
Abbildung 6.4-3: Entity Relationship – Modell PC-Beschaffung |
|
Vgl. zur Gestaltung von ER-Modellen in allen Aspekten: |
|
http://www.staud.info/erm2/er_t_1.htm |
|
6.5 Fahrzeugvermietung |
|
6.5.1 Anforderungen |
|
Es geht um ein Unternehmen, das Fahrzeuge aller Art vermietet und dies durch eine Datenbank unterstützen möchte. Folgende Attribute werden für die Fahrzeuge erfasst: |
|
|
(1) Für alle Fahrzeuge: Tag der Anschaffung (TagAnsch), Preis, nötiger Führerschein zum Fahren des Fahrzeugs (Führerschein)
|
|
|
(2) Für PKW: Motorart (Diesel oder Benziner), Motorstärke (PS). Hierunter fallen Cabriolets (Dach fest oder flexibel: Dachart), Sportwagen (Beschleunigung von 0 auf 100: Beschl) und Familienautos (Zahl der Sitzplätze)
|
|
|
(3) Für LKW: Getriebeart (Getriebe)
|
|
|
(4) Für Busse: Zahl der Sitzplätze (Plätze)
|
|
|
(5) Für Kettenfahrzeuge: bewältigbare Steigung (Steigung)
|
|
|
(6) Für militärische Kettenfahrzeuge: mit oder ohne Bewaffnung (Waffejn). Hier wird außerdem festgehalten, ob es sich um Kampfpanzer (für diese wird Feuerkraft erfasst) oder um Brückenlegepanzer (für diese wird Brückenlänge erfasst) handelt.
|
|
|
(7) Für zivile Kettenfahrzeuge: Schiebekraft (wieviel Erde sie maximal wegschieben können)
|
|
Die Ausleihe eines jeden Fahrzeugs wird mit Beginn (Tag der Ausleihe) und Ende (Tag der Rückgabe) festgehalten. Es versteht sich, dass ein Kunde öfters ein Fahrzeug ausleihen kann und dass ein Fahrzeug im Zeitverlauf möglichst oft ausgeliehen werden soll. |
|
Nach jeder Rückgabe des Fahrzeugs durch einen Kunden wird der Fahrzeugzustand festgehalten (ZustandF). Die Ausprägungen sind tadellos, normal, beschädigt, schwer beschädigt, funktionsunfähig. Ziel ist hier, die Historie der Zustandsentwicklung festzuhalten. |
|
Von den Ausleihern werden die Adressangaben (nur eine Adresse) erhoben (Name, Vorname, PLZ, Ort, Straße, Telefon). Sie erhalten außerdem einen Status, der folgende Ausprägungen haben kann: Neukunde (0), langjähriger solider Kunde (1), nicht solider Kunde (2). |
|
6.5.2 Lösungsschritte |
|
Ein Entitätstyp ist hier gleich erkennbar: Fahrzeuge. Das Durchlesen der Anforderungen macht dann deutlich, dass es hier um Einzelfahrzeuge geht, die aber nach Fahrzeugtypen gruppiert werden und bei denen neben Attributen für alle Fahrzeuge auch spezifische Attribute für die Fahrzeugtypen vorliegen. Es liegt hier also eine Generalisierung / Spezialisierung vor. |
|
Beginnen wir mit der Generalisierung, mit den Attributen für alle Fahrzeuge. Diese werden im ersten Punkt angeführt, allerdings müssen wir einen Schlüssel ergänzen: FNr (Fahrzeugnummer). |
|
Durch die Generalisierung / Spezialisierung geraten die Bezeichnungen der Spezialisierungen auf eine Metaebene, „über“ den Datenbestand. Sie stehen zwar als Relationenbezeichnungen, aber nicht im Datenbestand zur Verfügung. Dies kann Abfragen kompliziert machen, weshalb es empfehlenswert ist, in der Generalisierung die Bezeichnungen der Spezialisierungen zu erfassen. Wir ergänzen hier also Ftyp (Fahrzeugtyp). Damit ergibt sich der erste Entitätstyp. |
|
|
|
Abbildung 6.5-1: Entitätstyp Fahrzeuge |
|
Der zweite Punkt legt als Spezialisierung von Fahrzeuge einen Entitätstyp PKW mit Motorart und PS fest. Der anschließende Satz definiert dann noch Spezialisierungen der Spezialisierung PKW: Cabriolets mit Dachart, Sportwagen mit Beschl und Familienautos mit Sitzplätze. Damit haben wir an dieser Stelle der Spezialisierungshierarchie drei Ebenen. |
Spezialisierung der Spezialisierung |
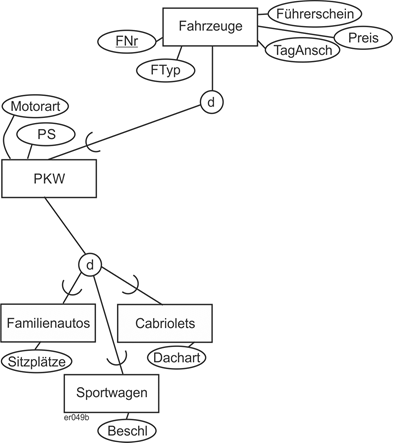
|
|
Abbildung 6.5-2: Generalisierung / Spezialisierung 1 – Fahrzeuge mit PKW |
|
In Punkt 3 werden die LKW (mit Getriebe), in Punkt 4 die Busse (mit Plätze) und in Punkt 5 die Kettenfahrzeuge (mit Steigung) eingeführt. Dies sind alles Spezialisierungen von Fahrzeuge. |
|
In Punkt 6 werden die Kettenfahrzeuge weiter spezifiziert in militärische Kettenfahrzeuge (KettenfahrzeugeMilitärisch) und diese wiederum in Kampfpanzer und Brückenlegepanzer. Da in Punkt 7 noch zivile Kettenfahrzeuge spezifiziert werden, liegt ab Kettenfahrzeuge, folgende Spezialisierungshierarchie vor: |
|
| Kettenfahrzeuge |
Kettenfahrzeuge Zivil |
Kettenfahrzeuge Militärisch |
Brückenlegepanzer |
Kampfpanzer |
| Steigung |
Steigung |
Steigung |
Steigung |
Steigung |
| |
Schiebekraft |
WaffeJN |
WaffeJN |
WaffeJN |
| |
|
|
Brückenlänge |
Feuerkraft |
| |
Damit ist die Generalisierung / Spezialisierung vollständig modelliert. |
|
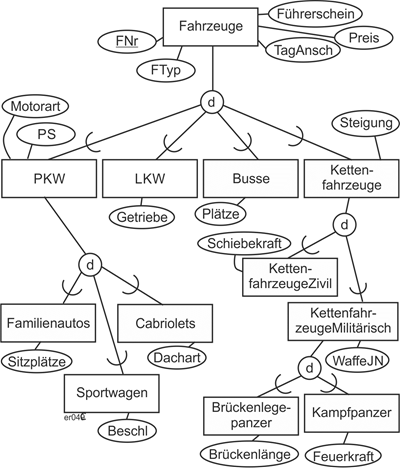
|
|
Abbildung 6.5-3: Generalisierung / Spezialisierung 1 – Fahrzeuge mit PKW |
|
In den nachfolgenden Absätzen wird die Ausleihe von Fahrzeugen modelliert. Die Ausleiher sind gleich als Entitätstypen erkennbar mit den Attributen Name, Vorname, PLZ, Ort, Straße, Telefon und Status. Wir ergänzen noch eine Kundennummer (KNr). |
Ausleiher und Fahrzeuge |
Für die Ausleihe legen wir einen Beziehungstyp F_A fest, denn der Beginn und das Ende der Ausleihe gehören zu der Beziehung zwischen Ausleihe und Fahrzeuge. Auch die Erfassung des Zustands nach der Rückgabe durch das Attribut ZustandF gehört hierher. Die Forderung, eine Ausleihhistorie und eine Historie der Zustandsentwicklungzu erfassen, ist durch diesen Beziehungstyp auch erfüllt. |
|
Sehen wir davon ab, das Ende des Ausleihvorgangs gleich beim Erfassen der Ausleihe festzulegen, gibt es hier, ähnlich wie in der relationalen Modellierung bei der Erfassung von Zeitabschnitten, eine Ungereimtheit. Das Ende der Ausleihe steht beim Eintrag des Ausleihvorgangs noch nicht zur Verfügung. Dieses Attribut kann also erstmal nicht beschrieben werden. Solche semantisch bedingten Leereinträge sind eigentlich nicht gewollt, hier aber aus pragmatischen Gründen akzeptiert. Die vollständig korrekte Lösung wäre die getrennte Erfassung von Beginn und Ende des Ausleihzeitraums. |
Zeitabschnitte mit Pragmatik |
Der Entitätstyp Ausleiher kann direkt der Anforderungsbeschreibung entnommen werden. Die Wertigkeiten können wie folgt festgelegt werden: 0,n bei Fahrzeuge, da wir neue Fahrzeuge auch aufnehmen wollen, wenn sie noch nicht verliehen wurden. 1,n bei Ausleiher legt fest, dass wir nur Personen aufnehmen, die auch ausgeliehen haben. |
|
Damit ergibt sich das folgende Modellfragment. |
|
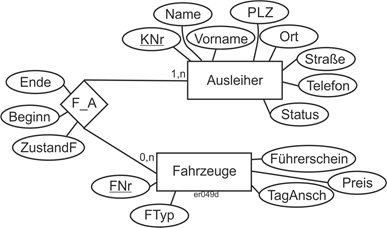
|
|
Abbildung 6.5-4: Modellfragment Ausleiher – Fahrzeuge |
|
6.5.3 Lösung |
|
Jetzt bleibt nur noch, die Modellierung der Generalisierung / Spezialisierung und der Ausleihe zusammenzufügen und das Gesamtmodell ist fertig. |
|
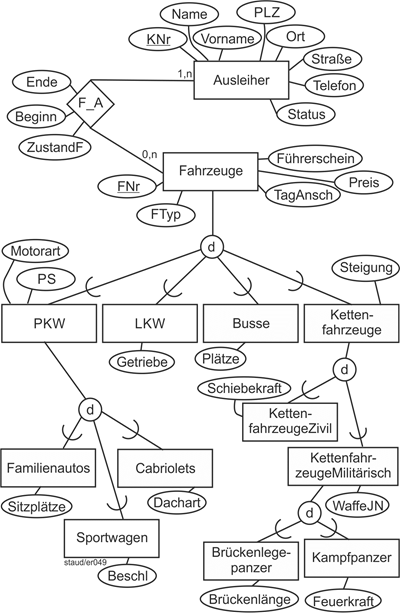
|
|
Abbildung 6.5-5: ER-Modell der Aufgabe Fahrzeuge. |
|
Die in der Anforderungsbeschreibung angeführten zulässigen Einträge in die Attribute ZustandF und Status betreffen nicht die Datenmodellierung, sondern die nachfolgende Einrichtung der Datenbank. |
|
6.6 WebShop |
|
6.6.1 Anforderungen |
|
Für einige Aspekte eines WebShops soll eine Datenbank erstellt werden. Hier die Anforderungen. |
Zeitliche Aspekte |
|
(1) Wenn die Warensendung im WebShop fertig ist wird die Rechnung erstellt und der Sendung beigelegt. Damit ist das kaufmännische Konstrukt Rechnung existent. Wie üblich, wird es über Rechnungsköpfe (ReKöpfe) und Rechnungspositionen (RePos) erfasst. Die Rechnungsköpfe erhalten als identifizierendes Attribut eine Rechnungsnummer (RNr) und als beschreibende Attribute das Rechnungsdatum (RDatum), die Zahlungsart (ZahlArt) (L (per Lastschrift), U (per Überweisung)) und die Versandart (VersArt). Die Rechnung wird als PDF-Dokument mit versandt, deshalb wird dessen Identifikation (PDFId) hier ebenfalls festgehalten.
|
|
|
(2) Die Kunden werden durch ihre Kundennummer (KNr) und durch ihre Adressangaben (Name, Vorname (VN), PLZ, Ort, Straße) erfasst. Es versteht sich, dass ein Kunde u.U. mehrere Rechnungen beim WebShop hat.
|
|
|
(3) Unsere Artikel erfassen wir durch eine Artikelnummer ArtNr, eine Artikelbezeichnung ArtBez, den Preis und eine Artikelbeschreibung (ArtBeschr).
|
|
|
(4) Die einzelnen Rechnungspositionen einer Rechnung erhalten eine Positionsnummer (PosNr), die Bezeichnung, den Preis des Artikels, die Anzahl (Anzahl) und den Gesamtpreis der Position (PosPreis).
|
|
|
(5) Für alle Artikel wird auch der gültige Mehrwertsteuersatz (MWStSatz) und bei jedem Verkauf die einbehaltene Mehrwertsteuer (MWStBetrag) erfasst. Zu beachten ist, dass verschiedene Produkte des WebShops unterschiedliche Mehrwertsteuersätze haben).
|
|
|
(6) Für Produkte von Fremdanbietern (Firmen, die über unseren WebShop auch verkaufen) wird noch die Firmennummer (FiNr) des Fremdanbieters erfasst und seine Lieferzeit (LiefZeit).
|
|
|
(7) Auch die ausgesandten Mahnungen und Zahlungserinnerungen werden erfasst. Jede wird identifiziert (MahnId) und bezieht sich auf genau eine Rechnung. Es versteht sich, dass es zu einer Rechnung mehrere Mahnungen geben kann. Festgehalten wird, an welchem Tag die Mahnung (Versand) verschickt wurde und von welchem Typ sie war.
|
|
|
(8) Eine Rechnung kann sich in verschiedenen Zuständen befinden. Folgende sind möglich:
|
|
Zustände einer Rechnung |
|
| ZustandsNr |
Bezeichnung |
| 100 |
neu (nach Erstellung) |
| 200 |
offen (nach Versand zum Kunden) |
| 300 |
nicht bezahlt |
| 310 |
nicht bezahlt (1. Zahlungserinnerung) |
| 320 |
nicht bezahlt (2. Zahlungserinnerung) |
| 330 |
nicht bezahlt (1. Mahnung) |
| 340 |
nicht bezahlt (2. Mahnung) |
| 350 |
nicht bezahlt (rechtsanwaltliche Mahnung) |
| 400 |
Widerspruch |
| 500 |
Gutschrift |
| 600 |
storniert |
| 700 |
bezahlt (Rückbuchbar) |
| 710 |
bezahlt |
| |
|
(9) Diese Zustände sollen für jede Rechnung erfasst werden. Nach der Erstellung hat sie den Zustand (ZustNr) „neu“, nach Zusendung zum Kunden den Zustand „offen“, nach Bezahlung den Zustand „bezahlt“. Zu beachten ist, dass ALLE sich im Zeitverlauf ergebenden Zustände erfasst werden sollen, so dass die gesamte Historie einer Rechnung erfasst wird. Deshalb wird auch bei jedem neuen Zustand das Datum (DatumZ) erfasst, zu dem er eintrat.
|
|
6.6.2 Lösungsschritte |
|
Anforderung (1), (3), (4), (5) |
|
Der erste Punkt weist auf das Konstrukt Rechnung über die Entitätstypen Rechnungsköpfe (ReKöpfe) und Rechnungspositionen (RePos) hin. Einige Attribute sind direkt angegeben. ReKöpfe erhält RNr als Schlüssel und RDatum, ZahlArt, VersArt sowie PDFId als weitere beschreibenden Attribute. |
|
Die Rechnungspositionen werden in (4) beschrieben. Sie erhalten eine Positionsnummer (PosNr), die Bezeichnung und den Preis des Artikels sowie die Anzahl der Artikel auf der Position und den Gesamtpreis der Position (PosPreis). |
|
Diese Attribute verweisen auf einen weiteren Entitätstyp, Artikel, der in (3) und (5) beschrieben ist. Nach den Regeln der ER-Modellierung werden alle Attribute, die Entitäten des Entitätstyps Artikel beschreiben, diesem zugeordnet. Dies sind ArtNr (als Schlüssel), ArtBez, Preis, ArtBeschr und MWStSatz. |
|
Der Entitätstyp RePos erhält die Attribute PosNr, Anzahl, den MWStBetrag und den PosPreis. MWStBetrag und PosPreis werden gleich hier, im ER-Modell, als Attribute gekennzeichnet, die durch das Datenbanksystem berechnet werden. PosPreis als Produkt von Preis (von Artikel) und Anzahl, MWStBetrag als Produkt von PosPreis und MWStSatz (von Artikel). |
Abgeleitete (berechnete) Attribute |
Die Beziehungstypen ergeben sich wie folgt: RePos ist existenzabhängig von ReKöpfe, da es Rechnungspositionen nicht ohne zugehörigen Rechnungskopf gibt. Dies wird in der ER-Modellierung durch einen singulären Entitätstyp (weak entity type) ausgedrückt, wie in der Grafik gezeigt. Er wird RK_RP genannt. Für den Beziehungstyp zwischen Artikel und RePos sind die Kardinalitäten 1:n, die Min-/Max-Angaben 0,n : 1,1. Er wird A_RP genannt. Damit ergibt sich die folgende Abbildung. |
Beziehungstypen |
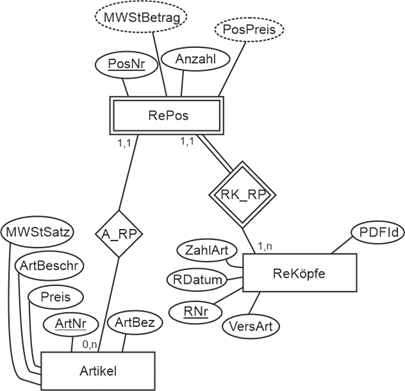
|
|
Abbildung 6.6-1: ER-Fragment zu Rechnungen / Artikel |
|
Anforderung (2) |
|
Im zweiten Punkt der Anforderungen wird auf die Kunden und deren Adressen verwiesen. Da es mehrere Adressen pro Kunde geben kann, ist eine theoriekonforme Aufteilung der Attribute wie folgt: |
|
- Entitätstyp Kunden mit KNr, Name, Vorname (VN) und ein
- Entitätstyp Adressen mit PLZ, Ort, Straße
|
|
Letzterer wird noch ergänzt um eine Adressnummer (AdrNr), die als Schlüssel dient. |
|
Die Beziehungstypen ergeben sich wie folgt: Kunden muss mit ReKöpfe verknüpft werden (Beziehungstyp RK_Ku) mit den Kardinalitäten 1:n und den Min-/Max-Angaben 1,n : 1,1. Kunden muss aber auch mit Adressen verknüpft werden (Kunden haben Adressen, Adressen gehören zu Kunden; Beziehungstyp Ku_Ad)) mit den Kardinalitäten 1:n und den Min-/Max-Angaben 1,n : 1,1. Es wird also darauf verzichtet den Fall zu erfassen, dass unter einer Adresse mehrere Kunden wohnen. |
|
Damit ergibt sich das folgende ER-Modell. |
|
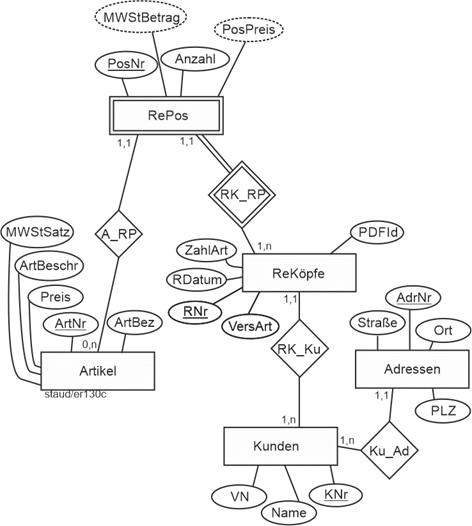
|
|
Abbildung 6.6-2: ER-Fragment zu Rechnungen / Artikel / Kunden |
|
Anforderung (6) |
|
Hier werden Produkte angesprochen, die auch Artikel des WebShops sind, die aber von Fremdanbietern stammen. Da dafür Attribute vorliegen, die nicht bei den oben schon angelegten Artikeln vorliegen (FiNr, LiefZeit), diese also ergänzen, handelt es sich um eine Spezialisierung. Sie soll F-Artikel genannt werden und wird als Spezialisierung an Artikel angefügt. |
|
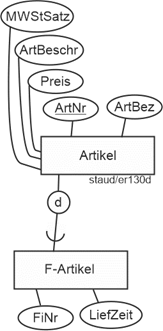
|
|
Abbildung 6.6-3: ER-Fragment zu Artikel / F-Artikel |
|
Anforderung (7) |
|
Punkt 7 befasst sich mit Mahnungen. Der erste Gedanke ist, die Attribute zu Mahnungen dem Entitätstyp ReKöpfe hinzuzufügen. Dies wäre aber methodisch falsch, da Mahnungen einen eigenen Entitätstyp darstellen: Sie haben einen Schlüssel (MahnId) und weitere beschreibende Attribute (Versand, Typ), die Mahnungen beschreiben und nicht Rechnungsköpfe. Außerdem gibt es auch Rechnungen ohne Mahnungen und u.U. mehrere Mahnungen pro Rechnung. |
|
Dieser Entitätstyp Mahnungen wird an das schon vorliegende ER-Modell mit Hilfe eines Beziehungstyps RK_M zwischen ReKöpfe und Mahnungen angefügt. Die Kardinalitäten sind 1:n, die Min-/Max-Angaben 0.n : 1,1. Vgl. die Abbildung unten. |
Anbindung |
Anforderung (8), (9) |
|
Der letzte Punkt bringt ein wenig die Geschäftsprozessthematik in die Aufgabe. Eine Rechnung ist ein Geschäftsobjekt und nimmt im Prozess der Zahlungsabwicklung verschiedene Zustände ein. Diese sind in den Anforderungen angeführt. In den Anforderungen wird verlangt, dass die Entwicklung der Zustände protokolliert wird. Jedesmal, wenn ein Zustand eintritt, wird das Datum mit erfasst. |
|
Dies soll über einen singulären Entitätstyp modelliert werden. Dann können die Werte in ZustNr für jede Rechnung hochgezählt werden. Außerdem verschwinden damit diese Informationen, wenn die Rechnung gelöscht wird. |
|
Ausgehend von den Rechnungsköpfen ist die Kardinalität 1:n, die Min-/Max-Angaben sind 0,n : 1,1. Die grafische Umsetzung findet sich in der Abbildung unten. |
|
6.6.3 Lösung |
|
Die folgende Abbildung fasst obige Ergebnisse zusammen. |
|
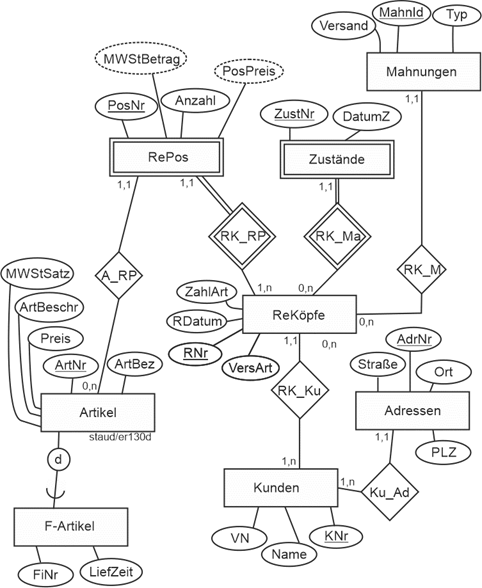
|
|
Abbildung 6.6-4: ER-Modell WebShop |
|
6.7 Zoo |
|
6.7.1 Anforderungen |
|
Für einen Zoo soll eine Datenbank rund um die vorhandenen Tiere erstellt werden. Dafür wird zuerst ein ER-Modell erstellt. |
|
Im ersten Schritt erfolgt eine Konzentration auf größere Tiere (Säugetiere, Reptilien, …). Allen diesen Tieren wird eine identifizierende Tiernummer (TierNr), ihr Name (Name; vom Pflegepersonal vergeben), ihr Geburtstag (GebTag) und das Geschlecht zugewiesen. Außerdem wird das Gebäude erfasst, in dem Sie gehalten werden und die Gattung, zu der sie gehören (z.B. Afrikanische Elefanten, Bengalen-Tiger, Schimpansen, Nil-Krokodile). Für jede Gattung wird auch festgehalten, wie viele Tiere dieser Gattung der Zoo hat (z.B. 5 Afrikanische Elefanten oder 20 Schimpansen) (Anzahl). Wegen der Bedeutung der Information für die Gebäude und das Außengelände wird bei Elefanten noch zusätzlich das Gewicht und bei Giraffen die Größe erfasst, jeweils mit dem Datum der Messung (DatumMessung). |
|
Auch die Rahmenbedingungen der Fütterung der Tiere wird festgehalten: Welches Futter (Bez) ein Tier bekommt (durchaus mehrere Futterarten, z.B. Heu und Frischkost), wieviel Mindestvorrat (MindMenge) gehalten werden muss und welche Menge davon ein Tier typischerweise täglich (MengeJeTag) verzehrt. |
|
Für die einzelnen Gebäude des Zoos wird eine Gebäudenummer (GebNr), die Größe, der Typ (für Säugetiere, für Reptilien, usw.) und die Anzahl der Plätze (AnzPlätze) erfasst. |
|
6.7.2 Lösungsschritte |
|
Ganz klar ist bei diesem Anwendungsbereich, dass die Tiere essentieller Bestandteil des Entity Relationship-Modells sind. Für sie wird daher ein Entitätstyp mit den angegebenen Attributen angelegt. Der Entitätstyp wird Tiere-Einzeln genannt, weil zu Beginn die gesamte Anforderung gelesen wurde (immer empfehlenswert!) und dabei deutlich wurde, dass auch noch Tiergattungen erfasst werden sollen. |
|
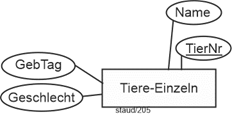
|
|
Abbildung 6.7-1: ER-Modell Zoo – Entitätstyp Tiere-Einzeln |
|
Für bestimmte Tiere werden noch zusätzliche Attribute erfasst. Für die Giraffen die Größe, für die Elefanten das Gewicht, jeweils mit dem Datum der Messung. Dies erfordert eine Generalisierung / Spezialisierung mit den Entitätstypen Giraffen und Elefanten und den angeführten Attributen. |
|
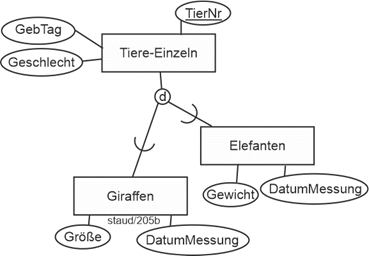
|
|
Abbildung 6.7-2: ER-Modell Zoo – Generalisierung / Spezialisierung |
|
Auch die Gebäude sollen, so die Anforderungen, mit GebNr (Schlüssel), Größe, Typ, AnzPlätze erfasst werden. Es entsteht ein Beziehungstyp G_T, die Min-/Max-Angaben ergeben sich mit 1,1 bei den Tieren und 0,m bei den Gebäuden. |
Gebäude |
Für die Tiergattungen wird der Entitätstyp Tiere-Gattung angelegt mit den Attributen Bez als Schlüssel und Anzahl. Er wird mit einem Beziehungstyp TG_T mit Tiere-Einzeln verknüpft. Die Min-/Max-Angaben sind 1,1 bei Tiere-Einzeln und 1,m bei Tiere-Gattung. |
Gattung |
Bleiben noch die Rahmenbedingungen der Fütterung. Da die Futterarten nicht nur erwähnt sondern beschrieben werden, entsteht für sie ein Entitätstyp Futterarten mit dem Schlüssel Bez und den Attributen MinMenge und Vorrat. Der typische tägliche Verzehr wird über einen Beziehungstyp Fütt zwischen Tiere-Einzeln und Futterarten festgehalten. Der Beziehungtyp erhält das Attribut MengeJeTag. Die Min-/Max-Angaben sind bei beiden Etn 1,1, denn jedes Tier wird mindestens einmal am Taag gefüttert und von jeder Futterart wird mindestens einmal am Tag etwas verabreicht. |
Fütterung |
6.7.3 Lösung |
|
Damit ergibt sich das folgende Gesamtmodell. |
|
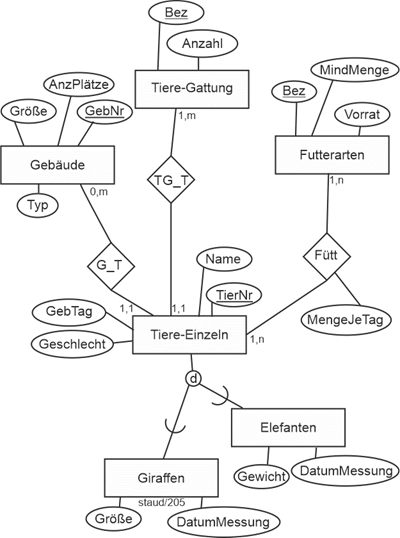
|
|
Abbildung 6.7-3: ER-Modell Zoo |
|
6.8 Hochschule - Vorlesungsbetrieb |
|
6.8.1 Anforderungen |
|
Für den Vorlesungsbetrieb einer Hochschule soll ein ER-Modell (ERM) erstellt werden. Folgende Realweltaspekte sind zu erfassen: |
|
- Die Lehrveranstaltungen (LV) als solche mit ihrer Bezeichnung (BezLV) und der Angabe des Semesters, indem sie nach Studienplan stattfinden (SemPlan). Außerdem soll festgehalten werden, in welchem Studiengang (SG) sie stattfinden (Bachelor WI, Bachelor AI, Master WI, usw.).
- Die Dozenten mit Name, Vorname, E-Mail und Typ (intern / extern).
- Die konkreten Termine einer jeden Lehrveranstaltung mit Tag, Beginn, Ende, Raum, Semester. Die Redundanz, die in der gleichzeitigen Erfassung von Tag und Semester liegt, soll akzeptiert werden.
- Welcher Dozent welche Lehrveranstaltung grundsätzlich zu halten bereit (und fähig) ist.
- Welcher Dozent die Termine einer LV konkret wahrnimmt. Es ist durchaus möglich, dass sich mehrere Dozenten die Veranstaltungstermine einer Lehrveranstaltung aufteilen, allerdings ist zu einem Vorlesungstermin immer nur ein Dozent anwesend.
- Für externe Dozenten, welche konkreten LV (BezLV) sie zu geben in der Lage sind.
- Die Studierenden mit Matrikelnummer MatrNr, Name, Vorname.
- Der Besuch der Veranstaltungstermine durch die Studierenden. An dieser Hochschule ist es üblich, die Anwesenheit zu kontrollieren. Deshalb wird für jeden Veranstaltungstermin einer Lehrveranstaltung festgehalten, welche Studierenden anwesend waren.
6.8.2 Lösungsschritte |
|
Sofort erkennbar als Entitätstyp (Identifikation + Beschreibung) sind die Lehrveranstaltungen (LV) mit den angeführten Attributen. Schlüssel ist BezLV. |
|
|
|
Abbildung 6.8-1: Entitätstyp zu Lehrveranstaltungen |
|
Danach kommt die Beschreibung der Dozenten und Dozentinnen. Für sie wird ein Entitätstyp Doz mit dem Schlüssel DozNr und den weiteren angeführten Attributen geschaffen. Der Text verrät, dass es interne und externe Dozenten gibt. Erstere bei der Hochschule beschäftigt, zweitere von außerhalb kommend. Das deutet eine Generalisierung / Spezialisierung an. Da aber im weiteren keine spezifiaschen Attribute für die internen Dozenten genannt werden, muss nur eine Spezialisierung für die externen Dozenten (Doz-Extern) angelegt werden. Das kommt nicht oft vor, ist aber möglich. Weiter unten ist angeführt, dass externe Dozenten durchaus auch mehrere Vorlesungen halten können. Deshalb ist das Attribut BezLV (Bezeichnung Lehrveranstaltung) hier mehrwertig. |
Generalisierung / Spezialisierung |
Weiter unten in den Anforderungen ist zu lesen, dass erfasst werden soll, welcher Dozent welche Lehrveranstaltung grundsätzlich zu halten bereit und fähig ist. Das ist eine für die Vorlesungsplaner wichtige Information, die durch einen Beziehungstyp Doz-LV dargestellt werden kann. Doz-LV verknüpft Doz und LV mit den Min-/Max-Angaben 1,n bzw. 1,m. |
Doz |
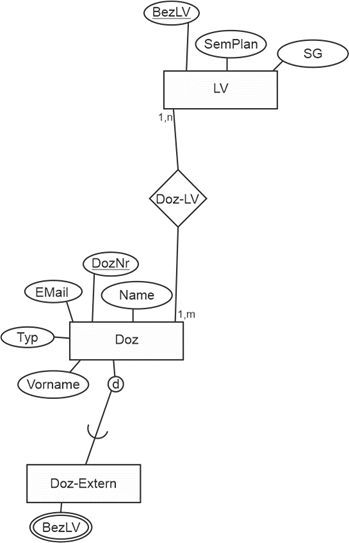
|
|
Abbildung 6.8-2: ER-Fragment Dozenten und ihre Lehre |
|
An dieser Hochschule wird die Anwesenheit bei den einzelnen Terminen der Lehrveranstaltungen festgehalten. Dies erfordert einen entsprechenden Entitätstyp, der hier LV-Termine genannt werden soll. Er hat (natürlich) eine zeitliche Dimension. Die angeführten Attribute sind identifizierend, ja sogar schon Teile davon. Es ist trotzdem nicht sinnvoll, daraus einen Schlüssel zu konstruieren, da ein solcher im späteren praktischen Umgang mit den Daten zu großer Komplexität bei Abfragen und Auswertungen führen würde. Wir legen deshalb einen Schlüssel LVTNr (Lehrveranstaltungsterminnummer) an, der jeden einzelnen Termin identifiziert. |
|
LV und LV-Termine sind verknüpft. Der Beziehungstyp wird LV-T genannt. Die Min-/Max-Angaben sind 1,m bei LV (zu einer Lehrveranstaltung gehören typischerweise mehrere Termine) und 1,1 bei LV-Termine (jeder Termin gehört zu einer Lehrveranstaltung). |
|
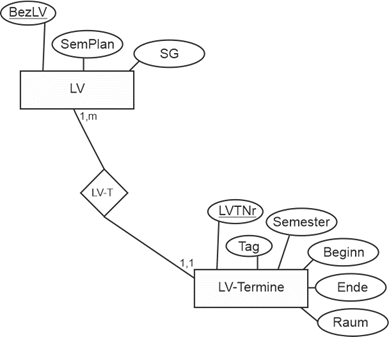
|
|
Abbildung 6.8-3: ER-Fragment zu Lehrveranstaltungen und ihren Terminen |
|
Bleiben noch die Studierenden und der Besuch der einzelnen Veranstaltungstermine durch diese. Der Entitätstyp Studierende erhält als Schlüssel MatrNr (Matrikelnummer) und als beschreibende Attribute Name und Vorname. Für die Anwesenheitskontrolle wird ein Beziehungstyp S-LVT angelegt. Er verknüpft LV-Termine und Studierende. Die Min-/Max-Angaben sind 0,n bei Studierende (ein/e Studierende/r starte mit Null, kann dann aber viele Termine besuchen) und 3,n bei LV-Termine (ein Termin findet statt, falls mindestens 3 Studierende anwesend sind). |
Studierende |
Die Information zur Anwesenheit kannn über ein Attribut AnwesendJN auf dem Beziehungstyp S-LVT erfassbar gemacht werden. |
|
Die Anforderungen verlangen auch noch, dass festgehalten wird, wer welche konkreten Lehrveranstaltungstermine wahrnimmt. Dafür wird ein Beziehungstyp D-LVT zwischen Dozenten und LV-Termine eingefügt. Er erhält die Min-/Max-Angabe 0,m bei Dozenten (ein Dozent kann mehrere Termine wahrnehmen) und 1,1 bei LV-Termine, da in den Anforderungen steht, dass maximal eine Lehrkraft bei jedem Termin anwesend ist. |
Lehrbetrieb |
Diese letzten Fragmente des Entity Relationship-Modells sind unten in die Lösung eingefügt. |
|
6.8.3 Lösung |
|
Damit sind alle Fragment des ER-Modells modelliert. Fügen wir sie zussammen, erhalten wir untenstehende Lösung. |
|
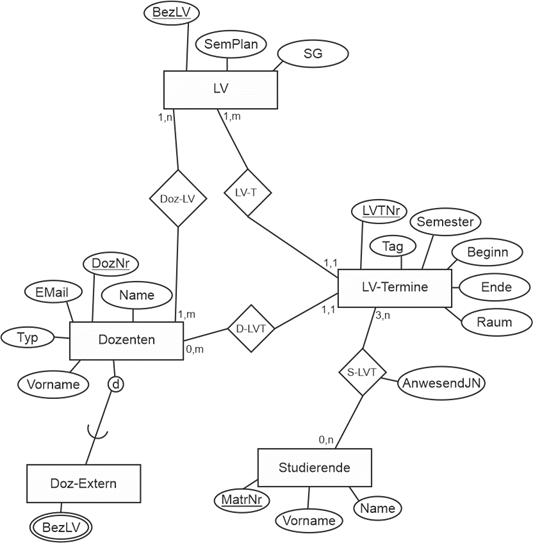
|
|
Abbildung 6.8-4: Entity Relationship-Modell Vorlesungsbetrieb |
|
|
6.9 Wörterbuchverlag |
|
6.9.1 Anforderungen |
|
Es geht um die Produkte eines Verlages, der Wörterbücher (z.B. Deutsch nach Englisch), digital oder auch gedruckt, herstellt und verkauft und der seit einiger Zeit auch Übersetzungsprogramme anbietet. Seine Produkte sollen in einer Datenbank verwaltet werden. Einige Attribute sind schon angeführt. Zu erfassen ist folgendes: |
|
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. Deutsch nach Englisch und Englisch nach Deutsch, Deutsch nach Französisch und Französisch nach Deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt.
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wieviele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum) und wieviele Seiten es hat (AnzSeiten).
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wieviele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe).
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wieviele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde. Festgehalten wird außerdem, ob das Systemlexikon durch den Anwender erweiterbar ist (Erweiterbarkeit) und ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf. Falls ein Produkt mit der Möglichkeit der Internetaktualisierung nicht mehr angeboten wird, wird dies auch festgehalten (RunterVomMarkt).
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm. Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. Zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArten) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (Integrierbarkeit).
- Die Programme für die digitalen Wörterbücher werden nicht erfasst.
- Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) und ihrer zentralen E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm von mehreren Softwarehäusern erstellt wird. Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich.
|
|
6.9.2 Lösungsschritte |
|
Hier wird nun obiger Text Schritt für Schritt bearbeitet und in ein Entity Relationship-Modell überführt. |
|
- Alle Wörterbücher und Volltextübersetzer (vgl. unten) mit den Sprachen, die abgedeckt sind (z.B. deutsch nach englisch und englisch nach deutsch, deutsch nach französisch und französisch nach deutsch), …). Es ist grundsätzlich möglich, dass ein Wörterbuch auch nur eine Richtung abdeckt. |
|
Zwei Tatsachen sind direkt ableitbar. Erstens, dass es wohl Wörterbücher und Volltextübersetzer als solche gibt – und zwar wahrscheinlich als „Spitze“ einer Generalisierungshierarchie. Nennen wir sie Produkte und geben ihnen den Schlüssel ProdNr. Zweites, dass die abgedeckten Sprachen zu erfassen sind, und zwar als mehrwertige Attribute an diesem Entitätstyp: |
|
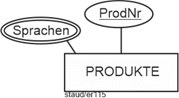
|
|
Abbildung 6.9-1: Entitätstyp Produkte – Version 1 |
|
Nächste Anforderungen: |
|
- Für jedes gedruckte Wörterbuch wird auch festgehalten, wieviele Einträge es hat (Einträge), für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe), wann es auf den Markt gebracht wurde (ErschDatum), wieviele Seiten es hat (AnzSeiten). |
|
Hier wird eine erste Spezialisierung deutlich: Gedruckte Wörterbücher. Sie werden WöBüBuch genannt und haben (erstmal) die angeführten Attribute. |
|
- Für jedes digitale Wörterbuch wird auch festgehalten, wann es auf den Markt gebracht wurde (ErschDatum), welche Bezeichnung (SWBez) die aktuelle Software hat (z.B. Professional English 7.0), wieviele Einträge es hat (Einträge) und für welche Zielgruppe es gedacht ist (Schüler, Studierende, „Anwender“, „Profi-Anwender“, Übersetzer) (Zielgruppe). |
|
Damit ist die zweite Spezialisierung klar: digitale Wörterbücher. Dieser Entitätstyp wird WöBüDigital genannt. Da hier zum Teil dieselben Attribute wie in WöBüBuch auftauchen, gibt es also Attribute, die der Generalisierung zuzuordnen sind: Einträge, ErschDatum und Zielgruppe. Damit ergibt sich das folgende ER-Fragment. |
|
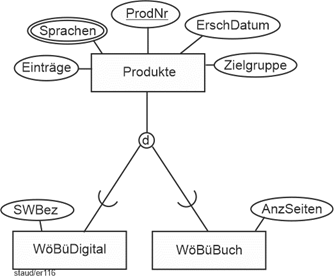
|
|
Abbildung 6.9-2: Entitätstyp Produkte – Version 2 |
|
Es kann aufgrund der Anforderungen vermutet werden, dass die Generalisierung / Spezialisierung noch weitergeführt wird, deshalb legen wir eine Tabelle mit den zugehörigen Entitätstypen und Attributen an. |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 1 |
|
| Produkte |
Gedruckte Wörterbücher (WöBüBuch) |
Digitale Wörterbücher (WöBüDigital) |
| ProdNr |
ProdNr |
ProdNr |
| Sprachen (mehrwertig) |
Sprachen (mehrwertig) |
Sprachen (mehrwertig) |
| Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
| |
AnzSeiten |
|
| |
|
SWBez |
| |
Der Übersichtlichkeit halber wurde der Schlüssel der Generalisierung auch in den Spalten der Spezialisierungen angeführt. |
|
Nun wieder die Anforderungen: |
|
- Für jeden „Volltextübersetzer“ (Programm zur automatischen Übersetzung) wird auch festgehalten, welche Sprachen abgedeckt sind, wieviele Einträge das Systemlexikon hat (Einträge), für welche Zielgruppe das Produkt gedacht ist und wann es auf den Markt gebracht wurde. Festgehalten wird außerdem, ob das Systemlexikon durch den Anwender erweiterbar ist (Erweiterbarkeit) und ob man den Käufern anbietet, es durch Internetzugriffe regelmäßig aktualisieren zu lassen. Falls ja, wie lange dies möglich ist (AktJahre), z.B. 5 Jahre ab Kauf. Falls ein Produkt mit der Möglichkeit der Internetaktualisierung nicht mehr angeboten wird, wird dies auch festgehalten (RunterVomMarkt). |
|
Dies zeigt eine weitere Spezialisierung: Volltextübersetzer. Ergänzen wir damit die Attributtabelle: |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 2 |
|
| Produkte |
WöBüBuch |
WöBüDigital |
Volltextübersetzer (VTÜ) |
| ProdNr |
ProdNr |
ProdNr |
ProdNr |
| Sprachen |
Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
ErschDatum |
| |
AnzSeiten |
|
|
| |
|
SWBez |
|
| |
|
|
Nur bestimmte: ErweiterbarkeitJN |
| |
|
|
Nur bestimmte: AktJahre |
| |
Wir wissen, dass in der ER-Modellierung eine Situation wie hier beim Entitätstyp VTÜ (Volltextübersetzer) mit den spezifischen Attributen für Volltextübersetzer mit Aktualisierung zu einer weiteren Spezialisierung führt, weshalb wir die Attributtabelle gleich verändern und einen weiteren Entitätstyp VTÜmitAkt (Volltextübersetzer mit Aktualisierung) anlegen können. |
|
Attributtabelle: Produkte und ihre Spezialisierungen - 3 |
|
| Produkte |
WöBüBuch |
WöBüDigital |
VTÜ |
VTÜmitAkt |
| ProdNr |
ProdNr |
ProdNr |
ProdNr |
ProdNr |
| Sprachen |
Sprachen |
Sprachen |
Sprachen |
Sprachen |
| Einträge |
Einträge |
Einträge |
Einträge |
Einträge |
| Zielgruppe |
Zielgruppe |
Zielgruppe |
Zielgruppe |
Zielgruppe |
| ErschDatum |
ErschDatum |
ErschDatum |
ErschDatum |
ErschDatum |
| |
AnzSeiten |
|
|
|
| |
|
SWBez |
|
|
| |
|
|
ErweiterbarkeitJN |
|
| |
|
|
|
AktJahre |
| |
|
|
|
RunterVomMarkt |
| |
Damit wird folgende Generalisierung / Spezialisierung deutlich: Die Zahl der Einträge, die Sprachen, die Zielgruppe und das Erscheinungsdatum (ErschDatum) erfassen wir weiterhin in der Generalisierung Produkte. Das Attribut SWBez bei WöBüDigital, das Attribut AnzSeiten bei WöBüBuch, ErweiterbarkeitJN bei VTÜ und AktJahre sowie RunterVomMarkt bei VTÜmitAkt. |
|
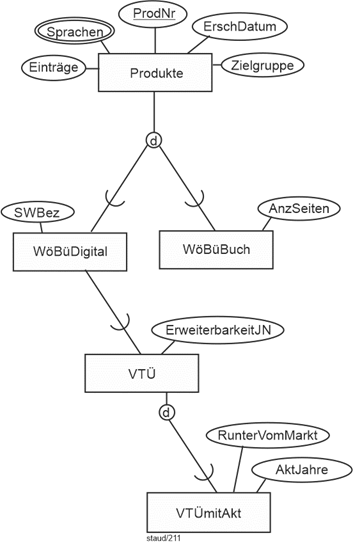
|
|
Abbildung 6.9-3: Generalisierung / Spezialisierung rund um Produkte |
|
Nun wieder die Anforderungen: |
|
- Die Volltextübersetzer beruhen jeweils auf einem Übersetzungsprogramm. Es kann sein, dass ein Volltextübersetzer mit verschiedenen Programmen angeboten wird (z.B. zielgruppenspezifisch). Natürlich dient ein Programm u.U. vielen Volltextübersetzern (z.B. Deutsch nach Englisch, Französisch nach Deutsch). Für diese Programme wird festgehalten, welche Dokumentarten (DokArt) sie auswerten können (Word, PDF, Bildformate, usw.) und ob es möglich ist, die Programmleistung in Textprogramme zu integrieren (IntegrierbarkeitJN). |
|
Hier werden nun die Übersetzungsprogramme zu einem Entitätstyp, der ÜbProgramme genannt werden soll. Er erhält die oben angeführten Attribute. Da Programme mehrere Dokumentarten auswerten können, ist das Attribut DokArt mehrwertig. |
|
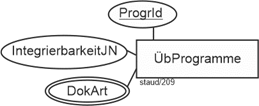
|
|
Abbildung 6.9-4: Entitätstyp ÜbProgramme |
|
Es wird auch gleich die Beziehung zwischen Übersetzungsprogrammen und den Volltextübersetzern geklärt. Für diese muss ein eigener Beziehungstyp VTÜ-P eingerichtet werden. |
|
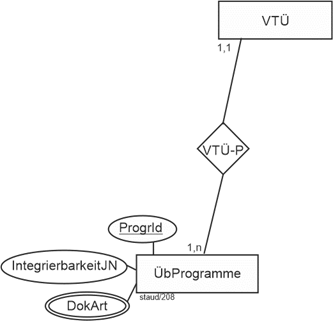
|
|
Abbildung 6.9-5: Beziehungstyp VTÜ-P |
|
Da ein Übersetzungsprogramm vielen Volltextübersetzern dienen kann, umgekehrt aber ein bestimmter Volltextübersetzer nur ein Übersetzungsprogramm hat, werden die Min-/Max-Angaben wie folgt: |
|
- 1:1 beim Entitätsty Vollextübersetzer
- 1:n beim Entitätstyp ÜbProgramme
|
|
Die Anforderungen: |
|
- Die Programme für die digitalen Wörterbücher werden nicht erfasst. |
|
Daraus folgt, dass beim „Einbau“ der Programme in das Datenmodell an die digitalen Wörterbücher nicht gedacht werden muss. |
|
Weiter mit den Anforderungen: |
|
Für die Programme der Volltextübersetzer werden außerdem die Softwarehäuser, die an der Erstellung mitgearbeitet haben, mit ihrer Anschrift (nur die Zentrale) festgehalten. Es wird auch die zentrale E-Mail-Adresse erfasst. Es kommt durchaus vor, dass ein Programm von mehreren Softwarehäusern erstellt wird. |
|
Festgehalten wird auch, wann die Zusammenarbeit mit dem Softwarehaus bzgl. eines Programmes begann (Beginn) und – gegebenenfalls – wann sie endete (Ende). Diese Angaben sind natürlich i.d.R. je nach Produkt, bei dem zusammengearbeitet wurde, unterschiedlich. |
|
Obiger Punkt führt die Softwarehäuser als Entitätstyp ein. Er wird SWH genannt. Wir legen die Bezeichnung (Bez) als Schlüssel und die Attribute Ort, PLZ, Straße, E-Mail als Adressattribute fest. |
|
Der zweite Satz gibt den Hinweise, dass zwischen Programmen und Softwarehäusern eine n:m-Beziehung vorliegt, wenn man davon ausgeht, dass ein Softwarehaus im Zeitverlauf auch an mehreren Programmen des Verlags mitgearbeitet hat. Dies wird durch einen Beziehungstyp SH-P modelliert. Zusammen mit dem Hinweise auf die zu erfassenden Start- und Endtermine (Beginn, Ende) für die Zusammenarbeit ergibt sich das folgende Modellfragment. |
|
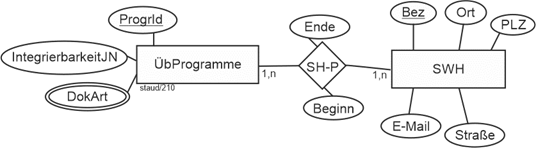
|
|
Abbildung 6.9-6: Beziehung zwischen Übersetzungsprogrammen und Softwarehäusern |
|
6.9.3 Lösung |
|
Fügt man die einzelnen Modellfragmente zusammen, ergibt sich das folgende Datenmodell. |
|
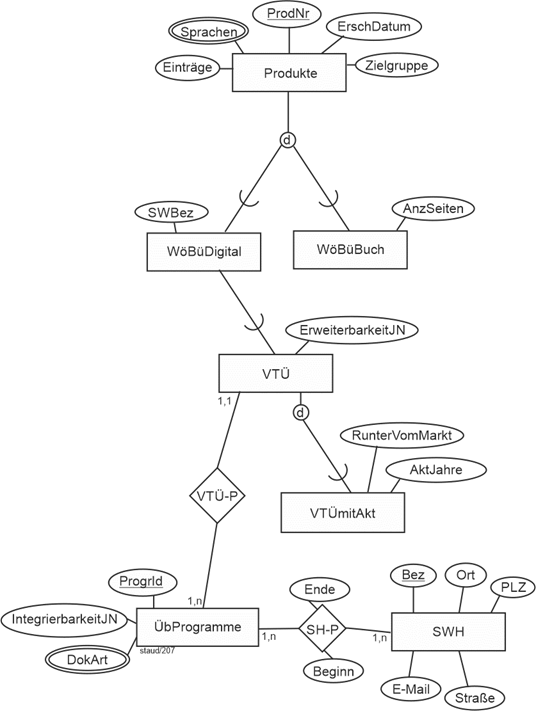
|
|
Abbildung 6.9-7: ER-Modell Wörterbuchverlag |
|
|
|
7 Von ERM zu RM |
|
Irgendwann passiert es, dass Semantische Datenmodelle umgewandelt werden in Modelle, die näher an den konkreten Strukturen datenverwaltender Systeme sind. Denn sie sollen ja zum Einsatz kommen. Im Fall von Entity Relationship-Modellen sind dies meist relationale Datenmodelle, die mit relationalen Datenbanksystemen umgesetzt werden können. Diese Umwandlung soll mit den folgenden Aufgaben geübt werden. |
|
|
|
7.1 Entitätstypen 1 |
|
7.1.1 Aufgabe |
|
Erstellen Sie für folgenden Entitätstyp ein relationales Modellfragment. |
|
|
|
Abbildung 7.1-1: Entitätstyp mit Attributen |
|
7.1.2 Lösung |
|
Entitätstypen ohne mehrwertige Attribute werden in eine einzelne eigene Relation überführt. In der folgenden Relation wird angenommen, dass das Attribut Name ebenfalls Schlüsselcharakter hat. |
|
Angestellte (#PersNr, #Name, Alter, Geschlecht, Gehalt) |
|
7.2 Entitätstypen, Attributsonderfälle |
|
7.2.1 Aufgabe |
|
Erstellen Sie für folgenden Entitätstyp ein relationales Modellfragment. |
|
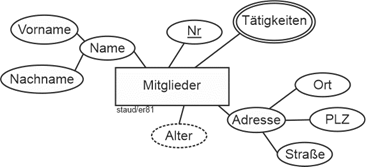
|
|
Abbildung 7.2-1: Attributsonderfälle |
|
7.2.2 Lösung |
|
Die Abbildung zeigt die Sonderfälle zusammengesetzte Attribute, abgeleitete Attribute und mehrwertige Attribute. Diese Attributsonderfälle werden wie folgt in relationale Datenmodelle abgebildet: |
|
- Bei zusammengesetzten Attributen werden nur die "äußersten" Attribute übernommen. Die Information, dass die Attribute etwas zusammen modellieren, dass sie „zusammengehören“, geht verloren. Hier bleiben also Ort, PLZ und Straße sowie Nachname und Vorname übrig.
- Abgeleitete Attribute können nicht direkt modelliert werden. Bei vielen Datenbanksystemen ist es allerdings möglich, im Rahmen der Einrichtung der Datenbank, ein solches "berechnetes" Attribut anzulegen.
- Jedes mehrwertige Attribut wird zu einer eigenen Relation, entsprechend der Behandlung mehrwertiger Attribute im relationalen Ansatz.
|
|
Aus dem obigen ER-Modell werden damit die folgenden zwei Relationen: |
|
Mitglieder (#Nr, Nachname, Vorname, PLZ, Ort, Straße) |
|
Mitgliedertätigkeiten (#(Nr, Tätigkeit)) |
|
7.3 Beziehungstypen 1 |
|
7.3.1 Aufgabe |
|
Erstellen Sie für das folgende Entity Relationship-Modell ein relationales Modellfragment. Das ERM gehört zu einem Anwendungsbereich Datenbanksysteme. Es enthält technische und preisliche Beschreibungen von Datenbanksystemen. Der Grund für deren Trennung ist, dass die technischen Informationen immer erhoben werden, die kaufmännischen aber nur für einen Teil der Datenbanksysteme. Diese Situation könnte, so wie hier in der folgenden Abbildung, zur Bildung zweier Entitätstypen geführt haben, die durch eine 1:1 - Beziehung T_P verknüpft sind. |
|
Außerdem wird zwischen Produzenten und DBS_T eine 1:n- und zwischen Datentypen und DBS_T eine n:m - Beziehung angenommen. Es liegen somit drei Kardinalitäten in einem Modellfragment vor. |
|
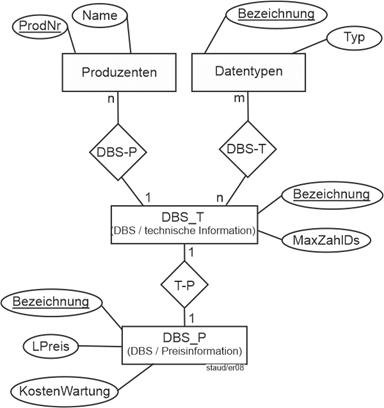
|
|
Abbildung 7.3-1: Drei Kardinalitäten in einem Modellfragment |
|
Entitätstyp DBS_P: Datenbanksysteme / Preisinformation |
|
Entitätstyp DBS_T: Datenbanksysteme / Technische Information |
|
LPreis: Listenpreis |
|
MaxZahlDs: Maximale Anzahl der Datensätze, die das Datenbanksystem verwalten kann |
|
Typ: Typ des Datentyps: numerisch, alphanumerisch, … |
|
7.3.2 Lösung |
|
Beziehungstypen werden unterschiedlich modelliert, je nach der Kardinalität und dem Min-/Max-Wert der Beziehung. Für die Übertragung in ein relationales Modell wird zuerst für jeden Entitätstyp eine Relation angelegt: |
|
Produzenten (#ProdNr, Name) |
|
Datentypen (#Bezeichnung, Typ) |
|
DBS_T (#Bezeichnung, MaxZahlDs) |
|
DBS_P (#Bezeichnung, LPreis, KostenWartung) |
|
Für jede n:m - Beziehung muss (unabhängig von den Kardinalitäten) bei der Übertragung eine eigene Relation angelegt werden, so also auch hier für den Beziehungstyp DBS-T: |
Lösung für
n zu m |
DBS_T-Typ (#(BezeichnungDB, BezeichnungDatentyp)) |
|
Alle 1:n - Beziehungen werden in eine Schlüssel/Fremdschlüssel - Beziehung übertragen. Hier muss also die Relation DBS_T ergänzt werden um den Schlüssel von Produzenten: |
Lösung für
1 zu n |
DBS_T (#Bezeichnung, MaxZahlDs, ProdNr) |
|
Bei 1:1 - Beziehungen ist die Regellösung die, dass einer der beiden Schlüssel als Fremdschlüssel in die andere Relation genommen wird. Mit obigem Beispiel und der Annahme, dass es sich um eine Pflichtbeziehung handelt (beide Min-/MAX-Angaben also 1,1 sind), ergeben sich folgende möglichen Lösungen: |
Lösung für
1 zu 1 |
DBS_T (#BezTech, MaxZahlDs, BezPreis) |
|
Oder |
|
DBS_P (#BezPreis, LPreis, KostenWartung, BezTech)) |
|
DBS_T und DBS_P sind hier bei jeder Beziehung identisch. Die unterschiedlichen Bezeichnungen wurden nur aus didaktischen Gründen gewählt. |
|
7.4 Beziehungstypen 2 |
|
7.4.1 Aufgabe |
|
Erstellen Sie für folgende Entity Relationship-Modelle jeweils ein relationales Modellfragment. Es geht um das Zusammenwirken von Trainern und Mannschaften, jeweils mit derselben Kardinalität, aber mit unterschiedlichen Min-/Max-Angaben. |
|

|
|
Abbildung 7.4-1: Verschiedene Min-/Max-Angaben |
|
7.4.2 Lösung |
|
Im ersten Beispiel wird auf beiden Seiten von einer Min-/Max-Angabe des Typs 1,1 ausgegangen. Dies bedeutet, dass es für jede Mannschaft einen Trainer gibt und für jeden Trainer eine Mannschaft. Dies wird so modelliert, dass in einer der beiden Relationen der Schlüssel der anderen als Fremdschlüssel eingefügt wird: |
|
Mannschaften (#MNr, TrNr, ...) |
|
Trainer (#TrNr, ...) |
|
Oder |
|
Mannschaften (#MNR, ...) |
|
Trainer (#TrNr, MNr, ...) |
|
Im zweiten Beispiel liegt auf einer Seite die Min-/Max-Angabe 0,1 vor. Dies bedeutet: Eine Mannschaft kann, muss aber nicht einen Trainer haben. Umgekehrt liegt 1,1 vor. Hier ist also den Trainern immer eine Mannschaft zugeordnet, nicht aber den Mannschaften ein Trainer. In einer solchen Situation muss der Relation mit der Min-/Max-Angabe 1,1 der Schlüssel der anderen als Fremdschlüssel hinzugefügt werden. Hier also: |
|
Mannschaften (#MNR, ...) |
|
Trainer (#TrNr, MNr, ...) |
|
Im untersten Fall liegt auf beiden Seiten die Min-/Max-Angabe 0,1 vor. Dies bedeutet bei einer Fremdschlüssellösung, dass auf jeden Fall semantisch bedingte Leereinträgeentstehen. D.h., nicht Leereinträge, die durch fehlende Angaben entstehen, sondern solche, die dadurch entstehen, weil es die entsprechende Information einfach nicht gibt. In einem solchen Fall ist die Anlage einer eigenen Relation notwendig, in der die Schlüssel der beiden Relationen jeweils auch Schlüssel sind: |
|
Mannschaften (#MNR, ...) |
|
Trainer (#TrNr, ...) |
|
Mannschaften-Trainer (#MNr, #TrNr)) |
|
Weil dieser Tatbestand und vor allem die dabei entstehende Relation erfahrungsgemäß Probleme bereitet, hier die tabellarische Darstellung. Es gibt vier Mannschaften und drei Trainer. Zwei der Trainer sind für zwei Mannschaften eingesetzt. Die übrigen Trainer und Mannschaften sind nicht in einem Trainingsverhältnis. Die Relation Mannschaften-Trainer zeigt, dass in einer solchen Situation tatsächlich beide Attribute für sich Schlüsselcharakter haben. |
|
Mannschaften |
|
| #MNr |
..... |
| M123 |
..... |
| M234 |
..... |
| M345 |
..... |
| M456 |
..... |
| |
Trainer
|
|
| #TrNr |
..... |
| T010 |
..... |
| T009 |
..... |
| T007 |
..... |
| |
Mannschaften_Trainer
|
|
| #TrNr |
#MNr |
| T010 |
M123 |
| T007 |
M345 |
| |
Diese Lösung erinnert an die Verbindungsrelation bei n:m - Beziehungen, hat aber eine andere Ursache. Da in der neuen Relation jeder Mannschaftsname und auch jede Trainernummer nur einmal vorkommen kann, können beide als Schlüssel dienen. Durch ihre verbindende Funktion mit Mannschaften bzw. Trainer sind sie gleichzeitig auch Fremdschlüssel. |
Keine Verbindungsrelation! |
7.5 Singuläre Entitätstypen |
|
7.5.1 Aufgabe |
|
Erstellen Sie für das folgende Entity Relationship-Modell mit einem singulären Entitätstyp ein relationales Modell. Es geht um die Beziehung zwischen Auftragsköpfen und Auftragspositionen, wie sie üblicherweise modelliert wird. |
|
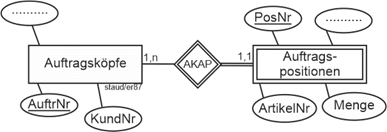
|
|
Abbildung 7.5-1: Singulärer Entitätstyp Auftragspositionen |
|
Die Attribute mit Punkten deuten die Vielzahl von Attributen an, die bei solchen Entitätstypen normalerweise noch vorliegen. |
|
7.5.2 Lösung |
|
Singuläre Entitätstypen erfassen so etwas wie Existenzabhängigkeit eines Entitätstyps von einem anderen . Damit beruhen sie auf einer Beziehung, die auf einer Seite eine Min-/Max-Angabe mit einem unteren Wert von 1 haben muss, da auf dieser Seite jede Entität an der Beziehung teilnimmt. |
|
Die Umsetzung erfolgt so, dass für die beiden Entitätstypen Relationen angelegt werden, wobei – und das ist zwingend für singuläre Entitätstypen mit ihren Existenzabhängigkeiten – der Schlüssel der Relation, die aus dem singulärem Entitätstyp hervorging, um den Schlüssel der anderen ergänzt wird. Das ist der Grund, weshalb einige Autoren diese Schlüsselergänzung auch gleich im ER-Modell vornehmen, was aber nicht notwendig ist, da der Tatbestand ja durch die Singularität ausgedrückt wird. Hier also: |
|
Auftragsköpfe (#AuftrNr, KundNr, ...) |
|
Auftragspositionen (#(AuftrNr, PosNr), ArtikelNr, Menge, ...) |
|
Damit ergibt sich – wiederum notwendigerweise – in der „singulären“ Relation ein zusammengesetzter Schlüssel mit einem Fremdschlüssel, der dem Schlüssel der anderen entspricht. |
|
7.6 Mehrstellige Beziehungen |
|
Mit Pflichtbeteiligung. |
|
7.6.1 Aufgabe |
|
Erstellen Sie für das folgende Entity Relationship-Modell mit einer mehrstelligen Beziehung ein relationales Modell. Es geht um Trainingsaktivitäten. |
|
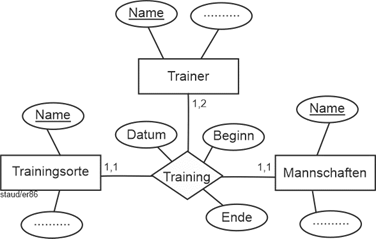
|
|
Abbildung 7.6-1: Dreistellige Beziehungen |
|
7.6.2 Lösung |
|
Mehrstellige Beziehungen werden so aufgelöst, dass für jeden Entitätstyp und für den Beziehungstyp je eine eigene Relation entsteht. In die so entstehende Verbindungsrelation werden die Schlüssel der beteiligten anderen Relationen als Fremdschlüssel aufgenommen. |
|
Hier entsteht somit: |
|
Trainer (#Name, ...) |
|
Trainingsort (#Name, ...) |
|
Mannschaften (#Name, ...) |
|
Training (#(TrainerName, TrOrtName, MannschName), Datum, Beginn, Ende) |
|
Sind die Min-/Max-Angaben nicht 1,1 wird bei der Schlüsselbildung entsprechend dem relationalen Regelwerk verfahren. |
|
Beispielsdaten |
|
| Trainingsort |
Trainer |
Mannschaften |
Datum |
Beginn |
Ende |
| TO1 |
T1 |
M1 |
1.1.24 |
8.00 |
12.00 |
| TO1 |
T2 |
M1 |
1.1.24 |
8.00 |
12.00 |
| TO1 |
T1 |
M2 |
10.1.24 |
14.00 |
16.00 |
| |
7.7 Generalisierung / Spezialisierung |
|
7.7.1 Aufgabe |
|
Erstellen Sie für das folgende Entity Relationship-Modell mit einer Generalisierung / Spezialisierung ein relationales Modell. Die Attribute mit Punkten deuten weitere beschreibende Attribute an. Im Fall der Relation Kunden solche, die alle Kunden gemeinsam haben, bei den anderen die jeweils spezifischen. |
|
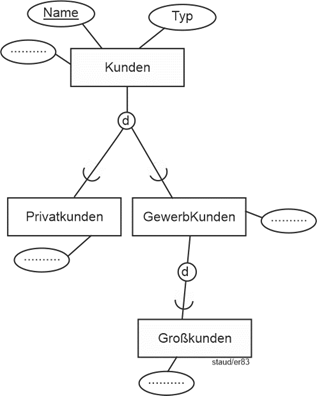
|
|
Abbildung 7.7-1: Generalisierung / Spezialisierung bzgl. Kunden |
|
7.7.2 Lösung |
|
Eine Generalisierung / Spezialisierung kann auf verschiedene Weise übertragen werden. Die Variante, die der relationalen Philosophie am nächsten kommt, ist die folgende: Aus dem generalisierten Entitätstyp und aus allen Spezialisierungen wird jeweils eine eigene Relation. |
|
Der Entitätstyp Kunden ist hier spezialisiert in Privatkunden und GewerbKunden (gewerbliche Kunden), letztere dann noch in Großkunden. Damit entstehen folgende Relationen: |
|
Kunden (#Name, Typ, ...) |
|
Privatkunden (#Name, ...) |
|
GewerbKunden (#Name, ...) |
|
Grosskunden (#Name, ...) |
|
Die Punkte stehen für weitere Attribute. Im Fall der Relation Kunden für solche, die alle Kunden gemeinsam haben, bei den anderen für die jeweils spezifischen Attribute. Die Schlüssel der Relationen, die Spezialisierungen darstellen, sind gleichzeitig auch Fremdschlüssel. Dies entspricht nicht der üblichen relationalen Verknüpfung, ist aber unvermeidbar. Hier gilt nicht, dass es für jede Ausprägung des Schlüssels eine oder mehrere Ausprägungen des Fremdschlüssels gibt, sondern dass die Menge der Ausprägungen des Schlüssels in der „Generalisierungsrelation“ die Ausprägungen der anderen enthält und dass es für jede Schlüsselausprägung in der „Generalisierungsrelation“ genau eine Ausprägung in einer der Spezialisierungen gibt. |
Fremdschlüssel besonderer Art |
Das relationale Modell enthält damit nicht mehr die Information, dass es sich um eine Generalisierung / Spezialisierung handelt. Diese Information muss über die Anwendung in das System gebracht werden. |
|
Die zweite Lösung für die Übertragung einer Generalisierung / Spezialisierung besteht darin, für jede Spezialisierung eine Relation anzulegen, die zusätzlich zu den spezifischen Attributen auch die allgemeinen enthält. Für die Generalisierung wird keine Relation angelegt. Im obigen Beispiel entstünden damit folgende Relationen: |
Zweite Lösung |
Privatkunden (#Name, "allgemeine Attribute", "spezifische Attribute") |
|
GewerbKunden (#Name, "allgemeine Attribute", "spezifische Attribute") |
|
Grosskunden (#Name, "allgemeine Attribute", "Attribute von GewerbKunden", "spezifische Attribute") |
|
Hier wurde eine totale Beteiligung angenommen, d.h., die Spezialisierungen decken alle Entitäten der Generalisierung ab. Liegt keine totale Beteiligung vor, ist diese Lösung nicht geeignet. |
|
Die dritte Lösung besteht darin, eine einzige Relation zu erstellen, die alle Attribute enthält. Im Beispiel: |
Dritte Lösung |
Kunden (#Name, Typ, "allgemeine Attribute Kunden", "spezifische Attribute Privatkunden", "spezifische Attribute GewerbKunden", "spezifische Attribute Großkunden") |
|
Eine solche Relation ist allerdings nicht für effizientes Arbeiten geeignet, denn die Attribute beziehen sich ja, bis auf die allgemeinen, nur jeweils auf eine Auswahl der Tupel. |
|
7.8 Angestellte/Kinder |
|
7.8.1 Aufgabe |
|
Wandeln Sie das folgende Modellfragment in ein relationales Modell um. |
|
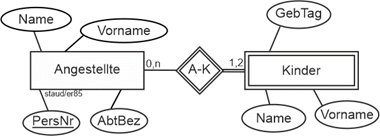
|
|
Abbildung 7.9-1: ER-Modell Angestellte / Kinder |
|
AbtBez: Abteilungsbezeichnung |
|
GebTag: Geburtstag |
|
7.8.2 Lösung |
|
Der Entitätstyp Kinder ist ein sog. schwacher Entitätstyp (singulärer Entitätstyp; weak entity type), vgl. auch Aufgabe 7.5. Das bedeutet, dass die Existenz einer Entität in Kinder davon abhängt, dass in einem anderen Entitätstyp (hier: Angestellte) eine bestimmte Entität vorliegt (hier: ein Elternteil). Es liegt also eine Existenzabhängigkeit vor. Im Beispiel ist es so, dass Kinder nur in der Datenbank erfasst werden, wenn mindestens ein Elternteil im Unternehmen ist. |
Singulärer Entitätstyp |
Die Überführung in ein relationales Datenmodell erfolgt so, dass jeweils eine Relation zu den Angestellten und Kindern angelegt wird: |
|
Angestellte (#PersNr, Name, Vorname, AbtBez) |
|
Kinder (Name, Vorname, GebTag) //vorläufig |
|
Wegen der Herkunft von einem schwachen Entitätstyp benötigt die identifizierende Information von Kinder (Name, Vorname) der Ergänzung durch PersNr.Angestellte, um Schlüsselcharakter zu erhalten. Mit den vorliegenden Min-/Max-Angaben kann die Verknüpfung so realisiert werden, dass in Kinder der Schlüssel von Angestellte zum Fremdschlüssel wird. Damit ergibt sich: |
|
Angestellte (#PersNr, Name, Vorname, AbtBez) |
|
Kinder (#(PersNr, Name, Vorname), GebTag) //final |
|
|
|

|
|
|
|
8 Objektorientierte Modellierung mit der UML 2.5 |
|
Für eine umfassende Einführung in die objektorientierte (Daten-)Modellierung vgl. [Staud 2019]: |
|
Staud, Josef Ludwig: Unternehmensmodellierung - Objektorientierte Theorie und Praxis mit UML 2.5. Berlin u.a. 2019 (Springer Verlag) |
|
|
|
8.1 Vorbemerkungen |
|
Ausrichtung |
|
Die folgenden Aufgabenbeispiele beziehen sich auf den inhaltlichen Teil einer objektorientierten Anwendung, die objektorientierte Datenbank. Um die objektorientierte Programmierung und die dafür notwendige Klassenbildung geht es nicht. |
|
Wenn Sie also eine objektorientierte Sprache gelernt haben, haben Sie hauptsächlich von programmtechnischen Aspekten gehört, wenig von der inhaltlichen Struktur der zu verwaltenden und verarbeitenden Daten. Diese kommen nur in einführenden Beispielen vor. Das ist verwunderlich, zumal mit der UML 2.5 eine umfassendes Theoriegebäude vorliegt. Deshalb die Ergänzung in [Staud 2019] und die Aufgaben hier. |
|
Ein paar grundsätzliche Anmerkungen zum Klassenkonzept der objektorientierten Theorie: Auch hier in der objektorientierten Datenbankgestaltung gilt, dass die Grundelemente des Ansatzes, die Klassen, i.d.R. durch Attribute gebildet werden, die ein Realweltphänomen (Angestellte, Produkte, Verträge, …) beschreiben. Ganz ähnlich wie in der ER-Modellierung und der relationalen Theorie gibt es das Einzelne (hier: Objekte, Instanzen) und die Zusammenfassung der Objekte mit identischem Aufbau (die Klasse). Und auch hier umfasst „das Ganze“ viele gleich aufgebaute „Einzelne“. Auch wenn die Objekte der Klassen eine systemgetragene Id erhalten, gibt es im Datenteil i.d.R. Attribute, die Schlüsselcharakter haben. Diese werden hier verwendet. Ein Attribut identifiziert also die Objekte und weitere Attribute beschreiben sie. |
Klassen |
Notationen |
|
Wie in [Staud 2019] sind hier alle Klassendiagramme und sonstigen Modelle sowie die typographische Notation, nach der UML 2.5 gestaltet. |
|
In den hier gezeigten Klassendiagrammen werden auch Datentypen angegeben. Folgende werden in den Texten der UML und in [Rumbaugh, Jacobson und Booch 2005] verwendet und kommen deshalb auch hier zum Einsatz: Category, Money, String, Date, Integer, Boolean, TimeofDay. Einige Beispiele werden auch in C++ angegeben. Da finden folgende Datentypen Verwendung: Char, Float, Double, Int. Wo nötig und sinnvoll sind noch selbsterklärende weitere Datentypen eingefügt. |
UML-Datentypen |
Lesehilfe |
|
Da das Lesen der Wertigkeiten der Assoziationen oft Schwierigkeiten bereitet, vor allem wenn man vorher die Wertigkeiten (Min-/Max-Angaben) in der relationalen und semantischen Modellierung gelernt hat, hier eine Anmerkung dazu. Die Wertigkeiten (Min-/Max-Angaben) der Assoziationen sind in der UML wie in der folgenden Abbildung gezeigt angeordnet. |
|
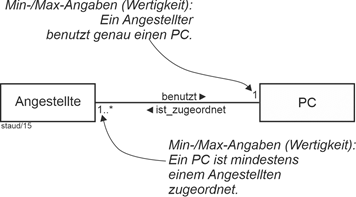
|
|
Abbildung 8.1-1: Lesehilfe für Min-/Max-Angaben in der UML 2.5 |
|
Nun die Aufgaben |
|
8.2 Klassenfindung - Angestellte |
|
8.2.1 Aufgabe |
|
Für die Angestellten eines Softwarehauses soll eine Klasse erstellt werden. Erfasst werden sollen Personalnummer (persNr; identifizierend), Name (name), Vorname (vorname) und Geburtstag (gebTag). Als Methoden sollen einstellen, entlassen und Gehalt zahlen (zahlenGehalt) angelegt werden. |
|
8.2.2 Lösung |
|
Die Darstellung einer Klasse ist in der UML wie folgt. Oben wird die Klassenbezeichnung angegeben, darunter die Attribute mit Datentypen, ganz unten die Methoden. Eines der Attribute ist Schlüssel. Der Schlüssel identifiziert Realweltphänomene, die hier meist Objekte bzw. Instanzen genannt werden. Sie werden durch die übrigen Attribute beschrieben. Und zwar so, dass alle Attribute für alle einzelnen Objekte Gültigkeit haben. Ähnliches gilt für die Methoden einer Klasse. Sie müssen auf die Objekte der Klasse anwendbar sein. |
|
Die Klasse wird in der objektorientierten Theorie, insbesondere der objektorientierten Programmierung, deshalb auch als Vorlage für die einzelnen Objekte gesehen. Alle Objekte sind also gleich aufgebaut. Ergibt sich dies einmal anders, müssen weitere Modellierungskonstrukte gewählt werden. |
|

|
|
Abbildung 8.2-1: Klassen in der UML 2.5 |
|
8.3 Projektmitarbeit |
|
8.3.1 Aufgabe |
|
Für die Angestellten eines Softwarehauses soll ein Klassendiagramm zur Projektmitarbeit erstellt werden. Folgende Aspekte sind zu erfassen: |
|
- Die Angestellten, so wie in Aufgabe 8.2 geschehen.
- Die Projekte, an denen sie teilnehmen mit einer Bezeichnung (bez; identifizierend) und dem Standort (standort).
- Die Mitarbeit: Ein Angestellter kann in mehreren Projekten sein und ein Projekt hat typischerweise mehrere Mitwirkende.
|
|
8.3.2 Lösung |
|
Die Klasse Angestellte kann von Aufgabe 8.2 übernommen werden. Für die Projekte ergibt sich eine eigene Klasse, da sie identifiziert und beschrieben werden. Die Mitarbeit bringt die beiden Klassen in eine Beziehung, die in der objektorientierten Theorie Assoziation genannt wird. Die Wertigkeiten sind hier klar angegeben. Ein Angestellter kann in keinem, einen oder mehreren Projekten mitarbeiten, das wird durch einen Stern ausgedrückt: *. Ein Projekt hat mindestens einen zugeordneten Angestellten (z.B. den Projektleiter bei Einrichtung des Projekts), kann aber auch beliebig viele haben. Die wird durch 1..* festgelegt. |
|
Da man vermuten kann, dass die Angestellten im Gesamtgeschehen noch mehrere Assoziation aufweisen werden, wird hier eine Rollenbezeichnung (Projektmitarbeiter) vergeben. |
|
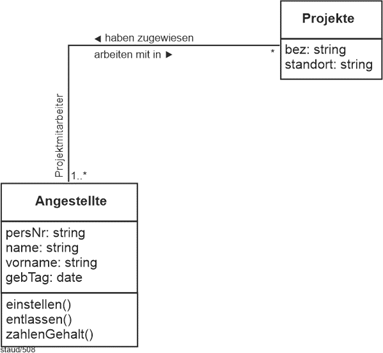
|
|
Abbildung 8.3-1: Assoziation zur Projektmitarbeit |
|
8.4 Abteilungszugehörigkeit |
|
8.4.1 Aufgabe |
|
Für die Angestellten eines Softwarehauses soll ein Klassendiagramm zur Abteilungszugehörigkeit erstellt werden. Folgende Aspekte sind zu erfassen: |
|
- Die Angestellten, so wie in Aufgabe 8.2 geschehen.
- Die Zugehörigkeit der Angestellten zu Abteilungen: In einer Abteilung sind mehrere Angestellte, ein Angestellter gehört aber zu genau einer Abteilung. Die Abteilungen werden durch die Abteilungsbezeichnung (abtBez; identifizierend), den Standort (standort) und den Abteilungsleiter mit seiner Personalnummer (Id), seinem Namen (Name) und seine Büronummer (Raum) erfasst.
|
|
8.4.2 Lösung |
|
Die Klasse Angestellte kann von Aufgabe 8.2 übernommen werden. Für die Abteilungszugehörigkeit, wie sie in der Anforderung beschrieben wird, müssen zwei Klassen angelegt werden, da zwei unterschiedliche Realweltphänomene beschrieben werden: |
|
- Abteilungen mit dem Schlüssel abtBez und dem Attribut standort
- Abteilungsleiter mit dem Schlüssel Id und den Attributen Name und Raum
|
|
Dies ist notwendig, weil beide Realweltphänomene identifiziert und beschrieben werden. Diese Aufteilung in Klassen erfordert Assoziationen. Zum einen zwischen Angestellte und Abteilungen, zum anderen ein zwischen Abteilungen und Abteilungsleiter. Die Wertigkeiten müssen teilweise festgelegt werden (normalerweise würde man nachfragen): |
|
- Für Angestellte / Abteilungen soll gelten: Ein/e Angestellte/r ist höchstens in einer einzigen Abteilung, es gibt aber auch Mitarbeiter, die keiner Abteilung zugeordnet sind.
- Für Abteilungen / Abteilungsleiter soll gelten: Eine Abteilung hat einen einzigen Abteilungsleiter, soll aber in den Daten schon angelegt werden können, wenn noch kein Abteilungsleiter feststeht. Umgekehrt gilt, ein Abteilungsleiter leitet genau eine Abteilung.
|
|
Damit ergibt sich die folgende Lösung. |
|
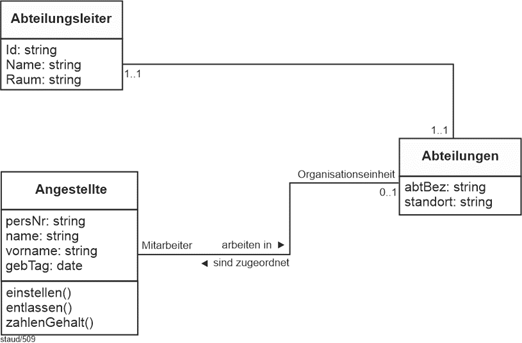
|
|
Abbildung 8.4-1: Projektmitarbeit im Klassendiagramm |
|
8.5 PC-Nutzung |
|
8.5.1 Aufgabe |
|
Für die Angestellten eines Softwarehauses soll ein Klassendiagramm zur PC-Nutzung erstellt werden. Folgende Aspekte sind zu erfassen: |
|
- die Angestellten (w/m/d)
- die PC
- die Nutzung der PC durch die Angestellten
|
|
Folgende Informationen sollen festgehalten werden: |
|
- Für die Angestellten wie in Aufgabe 8.2 die Personalnummer (persNr; identifizierend), der Name (name), Vorname (vorname) und Geburtstag (gebTag). Als Methoden sollen einstellen, entlassen und Gehalt zahlen (zahlenGehalt) angelegt werden.
- Für die von den Angestellten benutzten PC die Inventarnummer (inventarNr; identifizierend), die Bezeichnung (bez) und der Typ (typ).
- Die Nutzung der PC entlang folgender Feststellung: Ein PC ist genau einem Angestellten zugeordnet und ein Angestellter nutzt maximal einen PC.
- Außerdem soll durch eine Methode jederzeit die Anzahl aller PC festgestellt und gespeichert werden können.
|
|
8.5.2 Lösung |
|
Die Klasse Angestellte kann von Aufgabe 8.2 übernommen werden. Für die Personal Computer kann ebenfalls eine Klasse angelegt werden, PC, da sie durch die inventarNr identifiziert und durch bez und typ weiter beschrieben werden. Die Methode für die Feststellung der Anzahl PC wird feststellenAnzahl() genannt und der Klasse PC zugeordnet. Dort passt auch das Attribut hin, in dem die jeweils aktuelle Anzahl festgehalten wird, anzahlPC. Wir merken uns vor, in der nächsten Besprechung mit den Auftraggebern zu fragen, wie es um die Erfassung des Datums der Messung steht. |
|
Die PC-Nutzung wird durch eine Assoziation zwischen den beiden Klassen ausgedrückt. Entsprechend den Anforderungen ist sie 1 für die PC und 0..1 für die Angestellten, da es hier wohl auch Angestellte geben kann („maximal einen“), die keinen PC nutzen. Für die Angestellten vergeben wir die Rollenbezeichnung PC-Nutzer. |
|
Die folgende Abbildung zeigt die Lösung. |
|
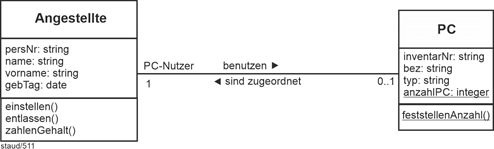
|
|
Abbildung 8.5-1: Assoziation zur Projektmitarbeit |
|
8.6 Programmiersprachenkompetenz |
|
8.6.1 Aufgabe |
|
Für die Angestellten eines Softwarehauses soll ein Klassendiagramm zur Programmiersprachenkompetenz der Beschäftigten erstellt werden. Folgende Aspekte sind zu erfassen: |
|
- die Angestellten (w/m/d)
- die von den Angestellten beherrschten Programmiersprachen mit Angabe der Jahre Programmiererfahrung.
|
|
Folgende Informationen sollen dabei festgehalten werden: |
|
- Für die Angestellten wie in Aufgabe 8.2 die Personalnummer (persNr; identifizierend), Name (name), Vorname (vorname) und Geburtstag (gebTag). Als Methoden sollen einstellen, entlassen und Gehalt zahlen (zahlenGehalt) angelegt werden.
- Für die Programmiersprachen, die von den Angestellten beherrscht werden die Bezeichnung der Sprache (bezPS; identifizierend), die Bezeichnung des Compilers (bezComp) und der Preis (preisLiz) für eine Lizenz.
|
|
Weiterhin gilt: Es ist in diesem Unternehmen so, dass nur Mitarbeiter eingestellt werden, die mindestens zwei Programmiersprachen beherrschen und außerdem wird darauf geachtet, dass für jede Programmiersprache mindestens zwei kompetente Angestellte da sind. Wegen der Bedeutung der Programmiererfahrung wird außerdem festgehalten, wieviel Jahre Programmierpraxis (erfahrPS) jeder Angestellte in seinen Programmiersprachen hat. |
|
8.6.2 Lösung |
|
Für die Angestellten übernehmen wir die in Abschnitt 8.2 entwickelte Klasse. Da für die Programmiersprachen ein identifizierendes Attribut (bezPS) und mehrere beschreibende vorliegen, wird für sie auch eine Klasse angelegt, PSn. Zwischen Angestellte und PSn ist eine Assoziation anzulegen, da ja festgehalten werden soll, wer welche Programmiersprachen beherrscht. Diese hat gemäß den Anforderungen auf beiden Seiten die Wertigkeiten 2..*. |
|
Bleibt noch die Programmiererfahrung, die Kompetenz in den einzelnen Programmiersprachen. Diesbezüglich soll die Anzahl der Jahre Programmierpraxis erfasst werden. Dies ist eine einfache numerische Angabe, die aber weder den Angestellten, noch den Programmiersprachen zugeordnet werden kann. Sie beschreibt die Verknüpfung der beiden, die Assoziation. Für eine solche Situation, Beschreibung einer Beziehung, sieht die objektorientierte Theorie Assoziationsklassen vor. Sie haben den üblichen Aufbau von Klassen und werden mit gestrichelter Linie an die Assoziation angefügt, wie es die folgende Abbildung zeigt. |
|
Der obere Teil zeigt die Standarddarstellung, wobei die Angestellten hier die Rolle Programmierer haben. Im unteren Teil der Abbildung ist eine Alternative für die Darstellung einer Assoziationsklasse angeben, eine sog. aufgelöste Assoziationsklasse. Sie ist leichter überführbar in die Programmierkonstrukte objektorientierter Programmiersprachen. |
|
Die folgende Abbildung zeigt die Lösung. |
|
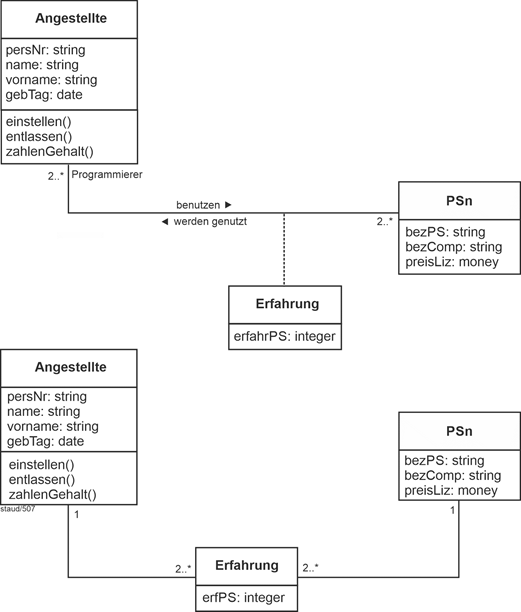
|
|
Abbildung 8.6-1: Programmiersprachenkompetenz mit und ohne aufgelöste Assoziationsklasse |
|
Unten: aufgelöste Assoziationsklasse |
|
8.7 Softwarehaus |
|
In dieser Aufgabe werden die Themen der obigen Aufgaben, etwas vereinfacht, integriert betrachtet. Sie kann unabhängig von den obigen bearbeitet werden. Es geht um einen Anwendungsbereich, der in einfacher Form wichtige Aspekte eines Softwarehauses erfasst. |
|
8.7.1 Anforderungen |
|
Erfasst werden sollen: |
|
- die Angestellten (w/m/d)
- die Projekte, an denen sie teilnehmen
- die Abteilungen, denen sie zugehörig sind
- die genutzten PCs
- die von den Angestellten beherrschten Programmiersprachen mit Angabe der Jahre Programmiererfahrung.
|
|
Folgende Informationen sollen für das objektorientiertes Modell festgehalten werden: |
|
- Für die Angestellten Personalnummer (persNr; identifizierend), Name (name), Vorname (vorname) und Geburtstag (gebTag). Als Methoden sollen einstellen, entlassen und Gehalt zahlen (zahlenGehalt) angelegt werden.
- Für die Projekte Bezeichnung (bez; identifizierend) und Standort (standort). Ein Angestellter kann in mehreren Projekten sein und ein Projekt hat typischerweise mehrere Mitwirkende.
- Für die Abteilungen die Abteilungsbezeichnung (abtBez; identifizierend) und den Abteilungsleiter (abtLeiter). In einer Abteilung sind mehrere Angestellte, ein Angestellter gehört aber zu genau einer Abteilung.
- Für die von den Angestellten benutzten PC die Inventarnummer (inventarNr; identifizierend), die Bezeichnung (bez) und der Typ (typ). Ein PC ist genau einem Angestellten zugeordnet und ein Angestellter nutzt maximal einen PC.
- Für die Programmiersprachen, die von den Angestellten beherrscht werden die Bezeichnung der Sprache (bezPS; identifizierend), die Bezeichnung des Compilers (bezComp) und der Preis (preisLiz) für eine Lizenz. Es ist in diesem Unternehmen so, dass nur Mitarbeiter eingestellt werden, die mindestens zwei Programmiersprachen beherrschen und außerdem wird darauf geachtet, dass für jede Programmiersprache mindestens zwei kompetente Angestellte da sind. Wegen der Bedeutung der Programmiererfahrung wird außerdem festgehalten, wieviel Jahre Programmierpraxis (erfahrPS) jeder Angestellte in seinen Programmiersprachen hat.
|
|
Außerdem soll durch eine Methode die Liste aller PC erstellt werden können und die Anzahl aller PC immer verfügbar sein. |
|
8.7.2 Lösungsschritte |
|
Klassen |
|
Es empfiehlt sich, zu Beginn nach den anzulegenden Klassen zu suchen. Unschwer als solche erkennbar sind Angestellte, Projekte, Abteilungen, PC und Programmiersprachen (PSn), denn sie werden a) identifiziert und b) durch weitere Attribute und Methoden beschrieben. Angestellte erhalten persNr, name, vorname und gebTag als Attribute und einstellen(), entlassen(), zahlenGehalt() als Methoden. Projekte werden durch bez und standort beschrieben. Abteilungen durch abtBez und abtLeiter. Die Klasse PC erhält inventarNr, bez und typ. Programmiersprachen (PSn) erhalten die Attribute bezPS, bezComp und preis. Die identifizierenden Attribute sind jeweils an der ersten Position. Vgl. die folgende Abbildung für die die grafische Gestaltung der Klassen. |
Identifikation + Beschreibung |
|
|
Abbildung 8.7-1: Klassen im Anwendungsbereich Angestellte |
|
PC: Personal Computer |
|
PSn: Programmiersprachen |
|
Assoziationen |
|
Zu Assoziationen gehören nach der UML die Wertigkeiten (Pflicht), Bezeichnungen (gerichtet, optional) und, falls eine Klasse mehrere Assoziationen aufweist, Rollenbezeichnungen (optional). Vgl. die Abbildung unten für die Darstellung. |
|
Nun zu den Assoziationen. Eine Assoziation liegt vor, wenn die Objekte verschiedener Klassen in Beziehung stehen. Dies ist hier in folgenden Fällen der Fall: |
|
- Angestellte – Projekte
- Angestellte – Abteilungen
- Angestellte – Personal Computer (PC)
- Angestellte – Programmiersprachen (PSn)
|
|
Die Assoziation zwischen Angestellten und Projekten hat die Wertigkeiten * bzw. 1..*, da es hier so ist, dass ein Projekt erst eingerichtet wird, wenn zumindest der Projektleiter bekannt ist. Umgekehrt gibt es auch Angestellte, die in keinem Projekt sind. Die Angestellten nehmen hier die Rolle Projektmitarbeiter ein. Vgl. die Abbildung unten. |
Angestellte /Projekte |
Die Assoziation zwischen Angestellten und Abteilungen erforderte bzgl. der Wertigkeiten einige Nachfragen. So stellte sich heraus, dass es auch Angestellte gibt, die keiner Abteilung zugeordnet sind. Da man immer nur zu einer einzigen Abteilung gehören kann, ergibt sich die Wertigkeit 0..1. Ebenso stellt sich heraus, dass Abteilungen erst eingerichtet werden, wenn zumindest ein/e Abteilungsleiter/in bekannt ist, was zu der Wertigkeit 1..* führt. Die Angestellten nehmen hier die Rolle Mitarbeiter ein. |
Angestellte /Abt |
Die nächste angeforderte Assoziation betrifft Angestellte / Personal Computer. Auch hier klären Nachfragen, dass Personal Computer erst dann erfasst werden sollen, wenn sie einem zugeordneten Angestellten zugewiesen werden können. Es gibt also keine PC ohne Zuweisung. Daraus ergibt sich die Wertigkeit 1. Umgekehrt stellt sich heraus, dass es auch Angestellte gibt, denen kein PC zugewiesen ist, was zur Wertigkeit 0..1 führt. Die Angestellten nehmen hier die Rolle PC-Nutzer ein. |
Angestellte / Personal Computer |
Nun die Programmiersprachen (PSn) und die Programmierkompetenz. Auch hier ist eine Assoziation nötig, zwischen Angestellten und Programmiersprachen. Die Wertigkeiten sind hier klar angegeben, auf beiden Seiten 2..*. Die Angestellten nehmen hier die Rolle Programmierer ein. |
|
Bleibt die Programmiererfahrung. Sie ist eine Eigenschaft der obigen Assoziation, da sie sich auf die Kombination Angestellte(r) / PSe bezieht. Für diese Situation bietet die objektorientierte Theorie die Assoziationsklassen an. Diese erhält hier die Bezeichnung Erfahrung und das Attribut erfPS. Mit ihr kann nun, wie gefordert, festgehalten werden, wieviel Jahre Programmierpraxis (erfahrPS) jeder in jeder seiner Programmiersprachen hat. Auf Nachfrage erfahren wir, dass diese Angaben jährlich aktualisiert werden. Dies übernimmt das Anwendungsprogramm, wobei die vorigen Werte einfach überschrieben werden. |
Assoziationsklasse |
Klassenattribute und Klassenmethoden |
|
Die letzte Anforderung verlangt, dass eine Methode die Liste aller PC erstellen kann und eine andere die Anzahl aller PC immer verfügbar hält. Dafür sind in der objektorientierten Theorie die Klassenattribute und Klassenmethoden vorgesehen. Da sich die gewünschte Information auf die PC bezieht, ist die gleichnamige Klasse der richtige Platz für ein Attribut anzahlPC. Ebenso gehört die Klassenmethode, sie soll feststellenAnzahl() genannt werden, in diese Klasse. Auf Nachfrage erfahren wir, dass die Feststellung der Anzahl automatisiert jeden Tag geschieht. |
|
8.7.3 Lösung |
|
Damit sind alle Elemente des objektorientierten Modells erarbeitet. Fügt man sie zusammen, erhält man das folgende Gesamtmodell. |
|
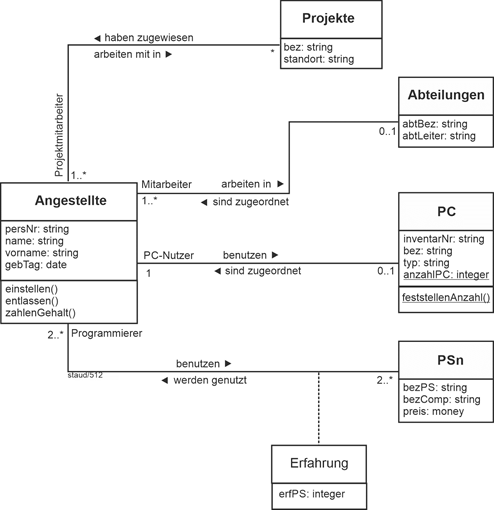
|
|
Abbildung 8.7-2: Klassendiagramm Softwarehaus |
|
8.8 Besuch Lehrveranstaltungen |
|
8.8.1 Aufgabe |
|
Für eine Hochschule soll eine objektorientierte Datenbank zu Aspekten des Lehrbetriebs eingerichtet werden. Erfasst werden sollen: |
|
|
(1) Die Lehrveranstaltungen über eine identifizierende Veranstaltungsnummer (lvNr), ihre Bezeichnung (bezLV) und die Bezeichnung des Studienganges (WI, AI, …), der die Lehrveranstaltung durchführt (bezStudiengang).
|
|
|
(2) Die Studierenden. Sie werden durch ihre identifizierende Matrikelnummer, den Namen, Vornamen und die E-Mail-Adresse (matrikelNr, name, vname, email) und ihre Wohnadresse (plz, ort, strasse) erfasst. Außerdem wird der Beginn des Studiums (beginnStudium), das Ende (endeStudium), der gewählte Studiengang (studiengang) und das Fachsemester (fachsemeser) festgehalten.
|
|
|
(3) Der Besuch von Lehrveranstaltungen. Dazu soll vermerkt werden, in welchem Semester sie welche Lehrveranstaltung besucht und welche Note sie erzielt haben. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss.
|
|
|
(4) Als Operationen werden die Ein- und Ausschreibung (imatrikulieren() und exmatrikulieren()) angelegt. Da die Hochschulleitung um die Möglichkeit bittet, jederzeit die genaue Anzahl der Studierenden festzustellen, sollen entsprechende Elemente eingebaut werden.
|
|
8.8.2 Lösung |
|
Liest man den obigen Anforderungskatalog, erkennt man auf Anhieb die Klassen LV (Lehrveranstaltungen) und Studierende, denn deren Objekte werden identifiziert und durch weitere Attribute beschrieben. |
Objekte, Klassen |
Bei den Lehrveranstaltungen ist der Schlüssel lvNR, zwei beschreibende Attribute sind bezLV und bezStudiengang. Für die Studierenden ist der Schlüssel matrikelNr, die beschreibenden Attribute sind name, vname und email. Da es augenscheinlich nur um eine einzige Adresse gehen soll (die Hauptadresse für die Hochschulmitteilungen), werden die Adressattribute plz, ort, strasse ebenfalls hier eingefügt. Außerdem die Attribute für den Anfang und das Ende des Studiums (beginnStudium, endeStudium), der gewählte Studiengang (studiengang) und das Fachsemester (fachsemeser). |
LV, Studierende |
Als Methoden werden immatrikulieren() und exmatrikulieren() angelegt. Für die jederzeitige Feststellung der Anzahl der Studierenden wird ein Klassenattribut anzahl und und eine Klassenmethode anzahlStud() hinzugetan. |
|
Für den Besuch der Lehrveranstaltungen benötigen wir erstmal eine Assoziation zwischen LV und Studierende. Die Wertigkeiten sind 3..* (eine Lehrveranstaltung muss, um stattfinden zu können, mindestens drei anwesende Studierende haben) bzw. * (ein Studierender kann keine oder beliebig viele Lehrveranstaltungen besuchen). Die Studierenden nehmen hier die Rolle Teilnehmer LV ein. Für die Beschreibung der Assoziation durch semester und note wird eine Assoziationsklassebenötigt. Sie wird LVBesuche genannt und erhält die Attribute semester und note. Damit werden nicht nur die Veranstaltungsbesuche erfasst, sondern auch eventuelle Mehrfachbesuche. |
Assoziationsklasse LVBesuche |
Für das Feststellen der Anzahl der Studierenden wird in Studierende eine Methode anzahlStud() hinzugefügt. Das Speichern der Anzahl erfolgt im Klassenattribut anzahl. Die Zählung erfolgt täglich. |
|
Damit ergibt sich das folgende Klassendiagramm. |
|
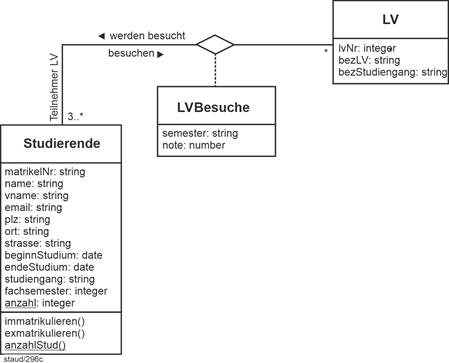
|
|
Abbildung 8.8-1: Studierende und Lehrveranstaltungen |
|
8.9 Dozenten an Hochschulen |
|
8.9.1 Anforderungsbeschreibung |
|
Für eine Hochschule soll eine objektorientierte Datenbank zu Aspekten des Lehrbetriebs eingerichtet werden. Dabei ergaben sich rund um die Dozenten folgende zu erfassenden Aspekte: |
|
|
(1) Die Dozenten über eine Dozentennummer (dozNr), den Namen (name) und Vornamen (vname).
|
|
|
(2) Für die Dozenten der Hochschule (interne Dozenten) wird auch die Nummer ihres Büros (büroNr), ihre E-Mail-Adresse (email) und die Angabe des Gebäudes, in dem sich das Büro befindet (gebäudeBez), z.B „V“), festgehalten. Für diese Gebäude wird noch die Straßenadresse erfasst und welcher DV-Betreuer für das Gebäude zuständig ist (strasse, dvb).
|
|
|
(3) Es gibt auch externe Dozenten. Für diese wird erfasst, von welchem Unternehmen, bzw. von welcher Hochschule sie kommen (herkunft).
|
|
|
(4) Alle Dozenten halten Vorlesungen und führen Prüfungen durch. Dies soll in den Daten vermerkt werden können. Dabei geht es nur um die grundsätzliche Möglichkeit, nicht um die konkrete Realisierung zu gewissen Zeitpunkten, usw.
|
|
|
(4) Folgende Methoden werden gleich zu Beginn eingebaut: Dozenten halten Vorlesungen und führen Prüfungen durch.
|
|
8.9.2 Lösung |
|
Auf den ersten Blick erscheint die Lösung simpel: Es ist eine Klasse zu den Dozenten zu erstellen. Schaut man genauer hin, erkennt man aber, dass es um zwei Gruppen von Dozenten geht, die gemeinsame, aber auch unterschiedliche Attribute aufweisen: interne und externe Dozenten. Für eine solche Situation sehen alle attributbasierten Modellierungsansätze eine Aufteilung vor, die Generalisierung / Spezialisierung. Dabei entstehen hier drei Klassen: |
|
- Alle Dozenten (Doz-Allg) mit: dozNr, name, vname
- Interne Dozenten (Doz-Intern) mit: büroNr und email
- Externe Dozenten (Doz-Ext) mit: herkunft
|
|
Den Methoden werden haltenVorlesung() und haltenPrüfung() genannt und Doz-Allg zugeordnet. Eine Generalisierung / Spezialisierung wird grafisch ausgedrückt. Die folgende Abbildung zeigt die Lösung. |
|
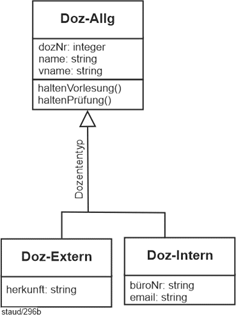
|
|
Abbildung 8.9-1: Generalisierung / Spezialisierung für Dozenten |
|
8.10 Lehrveranstaltungen mit Terminen |
|
8.10.1 Aufgabe |
|
Für eine Hochschule soll eine objektorientierte Datenbank zu Aspekten des Lehrbetriebs eingerichtet werden. Dabei ergaben sich rund um den Lehrbetrieb folgende zu erfassenden Aspekte: |
|
|
(1) Die Lehrveranstaltungen über eine Veranstaltungsnummer (lvNr), ihre Bezeichnung (bezLV) und die Bezeichnung des Studienganges (WI, AI, …), der die Lehrveranstaltung durchführt (bezStudiengang).
|
|
|
(2) Die einzelnen Termine der Lehrveranstaltungen über den Tag (tag), den Beginn (beginn) und das Ende (ende). Also z.B. Mittwochs, 8.00 – 8.30 Uhr. Natürlich wird festgehalten, welcher Lehrveranstaltungstermin zu welcher Lehrveranstaltung gehört.
|
|
|
(3) Der Raum (raum) der Lehrveranstaltungen wird ebenfalls festgehalten. Für die Räume sind die identifizierende Raumnummer (raumNr), die Anzahl der Plätze (anzPlae), das WLan-Kennwort (wlan) und die Existenz eines Beamers (beamer) festzuhalten.
|
|
|
(4) Bzgl. der Raumnutzung geht man davon aus, dass in einem Semester eine Lehrveranstaltung zwar meist in einem bestimmten Raum stattfindet, aber u.U. auch mal ausweichen muss.
|
|
8.10.2 Lösung |
|
Liest man die Anforderungen wird klar, dass für die Lehrveranstaltungen eine Klasse angelegt werden muss. Sie soll LV genannt werden und erhält die in (1) genannten Attribute. Der Schlüssel ist lvNR. Punkt (2) macht deutlich, dass in diesem Klassendiagramm neben den Lehrveranstaltungen auch die einzelnen Termine erfasst werden sollen. Die Attribute sind tag, beginn, ende und raum. Wir ergänzen einen durch das System generierten Schlüssel id. Die dadurch entstehende Klasse wird LVTermine genannt. |
Zeitliche Dimension |
Der letzte Satz von (2) macht auf die Verknüpfung von LV und LVTermine durch eine Assoziation aufmerksam. An diese werden die Wertigkeiten 1 bzw. 1..* angefügt, denn es gilt: Eine Lehrveranstaltung hat mehrere Termine und ein Termin gehört zu genau einer Lehrveranstaltung. Spätestens da erkennt man, dass es sich um eine Komposition handelt. Die Objekte von LVTermine sind existentiell abhängig von den Objekten in LV. Wird z.B. eine Lehrveranstaltung gelöscht, können auch ihre Termine gelöscht werden. |
Komposition |
Die folgende Abbildung zeigt die grafische Darstellung der Lösung und damit auch, wie eine Komposition in einem Klassendiagramm dargestellt wird. |
|
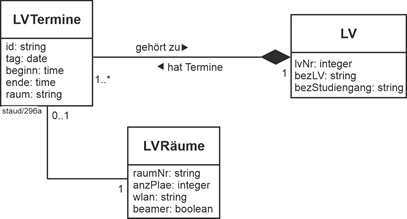
|
|
Abbildung 8.10-1: Lehrveranstaltungen und ihre Termine |
|
Zu beachten ist, dass die Objekte von LVTermine zeitpunktbezogen sind. Das erklärt die Wertigkeiten. |
|
8.11 Lehrbetrieb einer Hochschule |
|
In dieser Aufgabe werden die Themen der obigen Aufgaben zum Hochschulbereich, etwas vereinfacht, integriert betrachtet. Sie kann unabhängig von den obigen bearbeitet werden. |
|
8.11.1 Anforderungsbeschreibung |
|
Für eine Hochschule soll eine objektorientierte Datenbank zur Verwaltung des Lehrbetriebs eingerichtet werden. Im Rahmen eines vorbereitenden Workshops haben sich für das Klassendiagramm folgende Anforderungen ergeben. Erfasst werden sollen: |
|
|
(1) Die Lehrveranstaltungen (LV) über eine Veranstaltungsnummer (lvNr), ihre Bezeichnung (bezLV) und die Bezeichnung des Studienganges (WI, AI, …), der die Lehrveranstaltung durchführt (bezStudiengang).
|
|
|
(2) Die einzelnen Termine der Lehrveranstaltungen (LVTermine) über den Tag (tag), den Beginn (beginn) und das Ende (ende). Also z.B. Mittwochs, 8.00 – 8.30 Uhr.
|
|
|
(3) Die Räume, in denen die Lehrveranstaltungen stattfinden. Für sie wird eine identifizierende Raumnummer (raumNr), die Anzahl der Plätze (anzPlae), das WLan-Kennwort (wlan) und die Existenz/Nichtexistenz eines Beamers (beamer) festzuhalten.
|
|
|
(4) Die Dozenten über eine Dozentennummer (dozNr), den Namen (name) und Vornamen (vname). Für die Dozenten der Hochschule (interne Dozenten) wird auch die Nummer ihres Büros (büroNr) und ihre E-Mail-Adresse (email) festgehalten. Es gibt auch externe Dozenten. Für diese wird erfasst, von welchem Unternehmen, bzw. von welcher Hochschule sie kommen (herkunft). Alle Dozenten halten Vorlesungen durch. Dies soll festgehalten werden.
|
|
|
(4) Die Studierenden (Studierende). Sie werden durch ihre Matrikelnummer, den Namen, Vornamen und die E-Mail-Adresse (matrikelNr, name, vname, email) und ihre Wohnadresse (plz, ort, strasse) erfasst. Außerdem wird der Beginn des Studiums (beginnStudium), das Ende (endeStudium), der gewählte Studiengang (studiengang) und das Fachsemester (fachsemeser) festgehalten. Außerdem soll in den Daten vermerkt werden, in welchem Semester sie welche Lehrveranstaltung besucht und welche Note sie erzielt haben. Es kommt durchaus vor, dass ein Studierender eine bestimmte Lehrveranstaltung mehrfach besuchen muss. Als Operationen werden die Ein- und Ausschreibung (immatrikulieren() und exmatrikulieren()) angelegt.
|
|
|
(5) Der Lehrbetrieb: Eine Lehrveranstaltung wird in einem bestimmten Semester von genau einem Dozenten gehalten. Ein Dozent gibt mal keine (Fortbildungssemester), eine oder mehrere Lehrveranstaltungen.
|
|
8.11.2 Lösungsschritte |
|
Liest man den Anforderungskatalog, erkennt man auf Anhieb folgende Klassen, denen Ihre Objekte werden jeweils identifiziert und beschrieben: |
|
- Lehrveranstaltungen (LV)
- Dozenten (Doz)
- Studierende
|
|
Beginnen wir mit den Lehrveranstaltungen. Hier liegt ein Schlüssel vor (lvNR) und zwei beschreibende Attribute, bezLV und bezStudiengang. Punkt (2) macht deutlich, dass in diesem Klassendiagramm neben den Lehrveranstaltungen auch die einzelnen Termine erfasst werden sollen. Die Attribute sind tag, beginn, ende. Wir ergänzen einen Schlüssel: id. De Verknüpfung von Lehrveranstaltungen und Terminen führt zu einer Assoziation zwischen LV und LVTermine mit den Wertigkeiten 1 bzw. 1..* mit folgender Bedeutung: Eine Lehrveranstaltung hat mindestens einen Termin und ein Termin gehört zu genau einer Lehrveranstaltung. Spätestens da erkennt man, dass es sich um eine Komposition handelt. Die Objekte von LVTermine sind existentiell abhängig von den Objekten in LV. |
|
Die einzelnen Termine finden in Räumen statt. Diese sind auf Grund der angegebenen Attribute als Klasse erkennbar. Die notwendige Assoziation zwischen LVTermine und LVRäume hat die Wertigkeiten 0..1 und 1: Ein Termin (eine Veranstaltung) findet in genau einem Raum statt, ein Raum kann auch mal leer stehen, beherbergt aber ansonsten genau eine Veranstaltung. Damit ergibt sich ein erstes Fragment des gesuchten Klassendiagramms. |
|
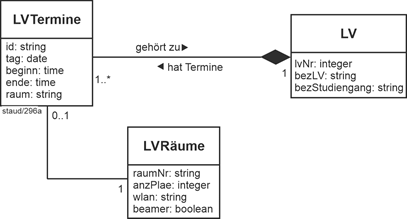
|
|
Abbildung 8.11-1: Lehrveranstaltungen und ihre Termine |
|
Id: Identifizierende Information, hier in der objektorientierten Methodologie oft systemgeneriert. |
|
Liest man in Punkt (3) die Anforderungen bzgl. der Dozenten genauer, entdeckt man, dass eine Generalisierung / Spezialisierung (Gen/Spez) vorliegt: Beschrieben werden Dozenten im allgemeinen und dann spezifisch noch die internen und externen Dozenten: |
Dozenten |
- Alle Dozenten (Doz-Allg) mit: dozNr, name, vname mit der Methode haltenVorlesung().
- Interne Dozenten (Doz-Intern) mit: büroNr und email
- Externe Dozenten (Doz-Ext) mit: herkunft
|
|
Dies erfordert das Einrichten von drei Klassen. Die Gen/Spez wird grafisch ausgedrückt. Vgl. die folgende Abbildung. |
|
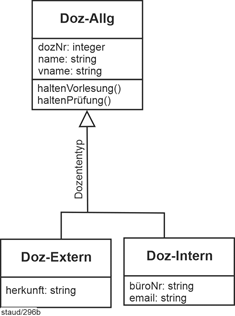
|
|
Abbildung 8.11-1: Lehrveranstaltungen und ihre Termine |
|
Auch die Studierenden (Punkt 4) finden sich in einer Objektklasse wieder. Der Schlüssel ist matrikelNr, die beschreibenden Attribute sind name, vname und email. Da es augenscheinlich nur um eine einzige Adresse gehen soll (die Hauptadresse für die Hochulmitteilungen), werden die Adressattribute plz, ort, strasse ebenfalls hier eingefügt. Außerdem die Attribute für den Anfang und das Ende des Studiums (beginnStudium, endeStudium), der gewählte Studiengang (studiengang) und das Fachsemester (fachsemeser). |
Studierende |
Als Methoden werden immatrikulieren() und exmatrikulieren() angelegt. Für die jederzeitige Feststellung der Anzahl der Studierenden wird ein Klassenattribut anzahl und eine Klassenmethode anzahlStud() hinzugetan. |
|
Für den Besuch der Lehrveranstaltungen benötigen wir erstmal eine Assoziation zwischen LV und Studierende. Die Wertigkeiten sind 3..* (eine Lehrveranstaltung muss, um stattfinden zu können, mindestens drei anwesende Studierende haben) bzw. * (ein Studierender kann keine oder beliebig viele Lehrveranstaltungen besuchen. Für die Beschreibung der Assoziation durch semester und note benötigen wir eine Assoziationsklasse. Sie wird LVBesuche genannt und erhält die Attribute semester und note. Damit werden nicht nur die Veranstaltungsbesuche erfasst, sondern auch eventuelle Mehrfachbesuche. |
Assoziationsklasse LVBesuche |
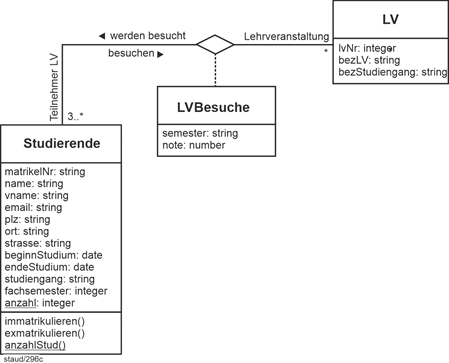
|
|
Abbildung 8.11-3: Studierende und Lehrveranstaltungen |
|
In Punkt 5 wird der Lehrbetrieb angesprochen. Dabei geht es um Lehrveranstaltungen, die von Dozenten gehalten werden, also um die Assoziation zwischen Doz-Allg und LV. Diese hat die Wertigkeiten * (keine, eine oder mehr Lehrveranstaltungen) bzw. 1 (genau ein Dozent pro Lehrveranstaltung). Um das Semester festzuhalten, in dem die Lehrveranstaltung gehalten wird, muss eine Assoziationsklasse Lehrbetrieb angelegt werden. Diese erhält das Attribut semester. Vgl. die folgende Abbildung. |
Lehrbetrieb |
8.11.3 Lösung |
|
Nun können die Fragmente zusammengefügt werden. Falls an dieser Stelle isolierte Modellfragmente entdeckt werden, sollte die Umsetzung der Anforderungen nochmals überprüft werden. Denn normalerweise sind in solchen Modellen alle Komponenten verbunden. |
|
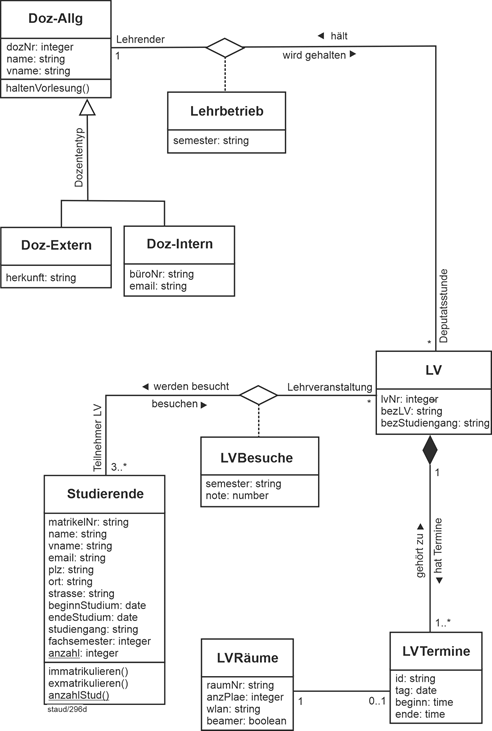
|
|
Abbildung 8.11-4: Klassendiagramm Lehrbetrieb (nach UML 2.5) |
|
Doz-Allg: Dozenten (Generalisierung); Doz-Extern: Externe Dozenten; Doz-Intern: Interne Dozenten |
|
LV: Lehrveranstaltung; LVTermine: Lehrveranstaltungstermine; LVBesuche: Lehrveranstaltungsbesuche |
|
LVRäume: Räume, in denen LLehrveranstaltungen stattfinden |
|
8.12 Studierendenakten |
|
8.12.1 Anforderungsbeschreibung |
|
Für ein objektorientiertes Modell rund um die Studierendenakten (StudAkten), in denen die Leistungen der Studierenden festgehalten werden, soll folgendes erfasst werden: |
|
|
(1) Die Lehrveranstaltungen über eine Veranstaltungsnummer (lvNr), ihre Bezeichnung (bezLV) und den zuständigen Studiengang (studiengang).
|
|
|
(2) Die Dozenten über eine Dozentennummer (dozNr), den Namen (name) und Vornamen (vname).
|
|
|
(3) Die Studierenden (Studierende) durch ihre Matrikelnummer (matrikelNr), den Namen, Vornamen (matrikelNr, name, vname), ihre Wohnadresse (plz, ort, strasse) und ihren Mail-Account (mail). Als Methoden werden Immatrikulation und Exmatrikulation angelegt.
|
|
|
(4) In einer Studierendenakte soll für jeden Studierenden festgehalten werden, welche Prüfungen absolviert wurden. Zu erfassen ist jeweils der Prüfling, der Prüfer, die zugehörige Lehrveranstaltung, das Datum (datum) der Prüfung, die erzielte Note (note) und die Gewichtung (gewichtung) der Note für die Zeugnisse. Als Methode wird eintragen (der Note) angelegt.
|
|
|
(5) Erfasst werden soll außerdem, welche Prüfungen Dozenten halten.
|
|
8.12.2 Lösungsschritte |
|
Im Mittelpunkt dieses Projekts steht eine Klasse StudAkten. Die Analyse der Anforderungen zeigt sehr schnell, dass es sich um eine Klasse handelt, die eine Beziehung beschreibt. Es ist die Beziehung Prüfung zwischen Studierenden, Dozenten und Lehrveranstaltungen, denn es gilt natürlich: |
Assoziationsklasse |
Eine Prüfung wird von Studierenden bzgl. einer Lehrveranstaltung und mit einem oder mehreren Dozenten als Prüfer(n) realisiert. |
|
Da es nicht nur die Beziehung als solche gibt, sondern auch eine Beschreibung der Beziehung und zugehörige Methoden, ist StudAkten eine Assoziationsklasse auf dieser Beziehung. Sie ist notwendig, weil beim Prüfungsbesuch Daten anfallen, die direkt zur Assoziation gehören und nicht bei den beteiligten Klassen untergebracht werden können. |
|
Betrachten wir noch die Min-/Max-Angaben, die wir durch Nachfrage präzisieren konnten: Eine Prüfung bezieht sich auf genau eine Lehrveranstaltung. Es nehmen jeweils ein Prüfungsteilnehmer und 1 bis 2 Dozenten teil. Ein erster Entwurf in der von der UML vorgesehenen “schlanken“ Form sieht damit wie folgt aus: |
|
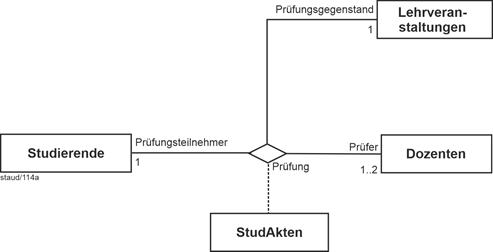
|
|
Abbildung 8.12-1: Studierendenakten – Version 1 |
|
Klassendiagramm ohne Attribute und Methoden. |
|
StudAkten ist als Assoziationsklasse notwendig für die Attribute, die sich nicht auf die Studierenden, Lehrveranstaltungen und Dozenten als solche beziehen, sondern auf deren Kombination im Prüfungsgeschehen. |
|
Nun müssen die Attribute und Methoden zugewiesen werden. In die Klasse Lehrveranstaltungen gehören die Attribute lvNr, bezLV und studiengang. Die Dozenten erhalten die Attribute dozNr, name und vname. Die Studierenden (Studierende) werden durch die Attribute matrikelNr, name, vname, plz, ort, strasse und mail beschrieben. Die Methoden immatrikulieren() und exmatrikulieren() erlauben die entsprechenden Vorgänge. |
Attribute und Methoden zuordnen |
Obige drei Klassen stehen in der Dreierbeziehung Prüfung. Da damit Attribute und Methoden vorliegen, die sich auf die 3-stellige Assoziation beziehen, beruht die Studierendenakte darauf und wird zu einer Assoziationsklasse. Hier muss auch die historische Dimension realisiert werden. Dazu dienen die Attribute datum, note und gewichtung. Ergänzt wird pruefungId, als Attribut, das jede Prüfung identifiziert. |
|
8.12.3 Lösung |
|
Damit ergibt sich die folgende Lösung. |
|
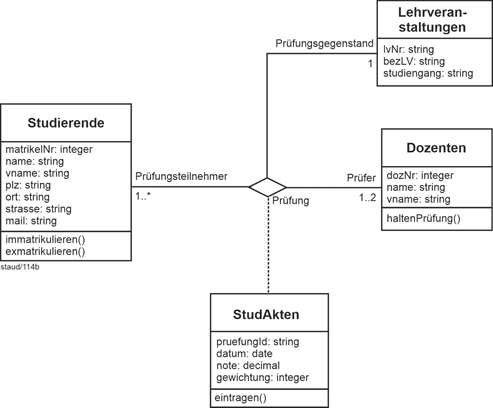
|
|
Abbildung 8.12-2: Rund um die Studierendenakten – Version 2 |
|
Soweit die Aufgaben. Weitere Beispiele objektorientierter (Daten-)Modelle finden sich in [Staud 2019]:
Staud, Josef Ludwig: Unternehmensmodellierung - Objektorientierte Theorie und Praxis mit UML 2.5. Berlin u.a. 2019 (Springer Verlag) |
|
|
|

|
|
|
|
9 SQL |
|
Diese Aufgaben dienen dazu, die Grundlagen von SQL zu trainieren, rund um das Anlegen der Datenbank, das Einrichten, Befüllen, Korrigieren, Löschen der Relationen und das Abfragen der Datenbank. |
|
Für die SQL-Befehle wurde MySQL (Xampp Control Panel v3.2.4) genutzt. In anderen SQL-Dialekten sind zum Teil andere Bezeichnungen, Befehlsstrukturen, usw. realisiert. In diesem einführenden Kontext betrifft dies evtl. Bezeichnungen von Datentypen und die Gestaltung der verschiedenen JOIN-Varianten. |
|
|
|
9.1 Datenbank MarktDBS einrichten |
|
9.1.1 Aufgabe |
|
Richten Sie die nachfolgend beschriebene Datenbank ein. Die folgende Abbildung zeigt die grafische Fassung des Datenmodells. Es liegen eine n:m-Beziehung zwischen DBS und Haendler und eine 1:n-Beziehung zwischen Produzenten und DBS vor. |
|
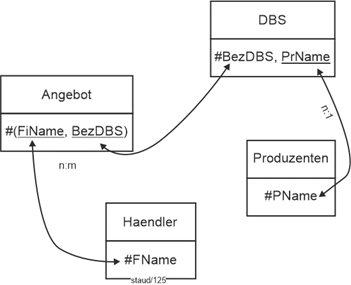
|
|
Abbildung 9.1-1: Datenmodell MarktDBS (Markt für Datenbanksysteme) |
|
Hier die textlichen Notationen: |
|
Produzenten (#PName, Stadt, Web) |
|
Diese Relation hält einige wichtige Informationen zu den Produzenten von Datenbanksystemen fest. Das Attribut Web soll die Webadresse des Unternehmens erfassen. PName ist der Produzentenname, Stadt der Name des Ortes, in dem der Hauptsitz des Unternehmens liegt. |
|
DBS (#BezDBS, Typ, Plattform, LPreis, PName, Datum) |
|
Damit werden die auf dem Markt befindlichen Datenbanksysteme beschrieben. LPreis steht für Listenpreis, PName für den Namen des Produzenten des Datenbanksystems. |
|
Angebot (#(BezDBS, FiName), MPreis) |
|
Die Relation hält fest, welches Datenbanksystem von welchem Händler zu welchem Preis angeboten wird. MPreis bedeutet Marktpreis, es meint also den Preis, den der jeweilige Händler für das Datenbanksystem verlangt. BezDBS erfasst die Bezeichnung des Datenbanksystems. Dieses Attribut ist hier Fremdschlüssel. FiName bedeutet Firmenname des Händlers. Auch dieses Attribut ist hier Fremdschlüssel. Die beiden Attribute zusammen stellen die n:m-Verknüpfung zwischen Datenbanksystemen und Händlern dar. |
|
Haendler (#FName, Ort, Straße, Rabatte) |
|
Die Relation beschreibt abstrahiert die Händler, die auf dem Markt Datenbanksysteme wie Oracle, ACCESS, usw. anbieten. FName bedeutet Firmenname, die Bezeichnung des Unternehmens. |
|
Vergeben Sie geeignete Datentypen. |
|
9.1.2 Lösung |
|
Einrichten der Datenbank. |
|
|
create database MarktDBS
|
|
|
default character set latin1
|
|
|
collate latin1_german1_ci;
|
|
Relation Produzenten |
|
|
Create table produzenten (pname char(5), stadt char(11), web varchar(10) not null, primary key (pname));
|
|
Relation DBS |
|
|
create table dbs (bezdbs char(10), typ varchar(10) not null, plattform varchar(10) default 'UNIX', lpreis decimal(7,2), pname char(5) references produzenten (pname), datum date, primary key (bezdbs));
|
|
Relation Haendler |
|
|
create table haendler (fname char(5), ort char(10), strasse char(14), rabatt decimal(2,0), primary key(fname));
|
|
Relation Angebot |
|
|
create table angebot (bezdbs char(10), finame char(5), mpreis decimal(8,2), primary key (bezdbs, finame), foreign key (bezdbs) references dbs(bezdbs), foreign key (finame) references haendler(fname));
|
|
Hinweis: Bezeichnungen von relational verknüpften Schlüsseln und Fremdschlüsseln müssen nicht gleich sein, vgl. hier haendler.fname und angebot.finame. Sie müssen aber denselben Datentyp mit derselben Länge aufweisen. |
|
9.2 Einfüllen von Daten in DBS |
|
9.2.1 Aufgabe |
|
Füllen Sie in die Relationen der oben eingerichteten Datenbank MarktDBS die nachfolgend angegebenen Daten ein. |
|
Produzenten |
|
| pname |
stadt |
web |
| P1 |
Hamburg |
www.p1.de |
| P2 |
Frankfurt |
www.p2.de |
| P3 |
Berlin |
www.p3.com |
| P4 |
Rom |
www.p4.it |
| P5 |
Passau |
www.p5.inf |
| |
DBS
|
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS1 |
RDBS |
UNIX |
9500.10 |
P1 |
2019-07-20 |
| DBS10 |
RDBS |
WINDOWS |
600.88 |
P4 |
2021-03-20 |
| DBS11 |
RDBS |
WINDOWS |
800.90 |
P5 |
2020-11-20 |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
| DBS3 |
RDBS |
LINUX |
2301.00 |
P2 |
2022-02-26 |
| DBS4 |
NoSQL |
WINDOWS |
2000.77 |
P4 |
2019-02-20 |
| DBS5 |
OODBS |
LINUX |
900.66 |
P1 |
2021-04-20 |
| DBS6 |
OODBS |
WINDOWS |
1800.55 |
P2 |
2022-06-20 |
| DBS7 |
OODBS |
UNIX |
5000.40 |
P3 |
2015-07-20 |
| DBS8 |
RDBS |
LINUX |
1200.30 |
P2 |
2021-08-20 |
| DBS9 |
NoSQL |
LINUX |
3000.20 |
P1 |
2022-01-01 |
| |
Haendler
|
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE2 |
München |
Hummelweg 99 |
6 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| HAE4 |
Stuttgart |
Bahnhofstr. 20 |
8 |
| HAE5 |
Ravensburg |
Hammerstraße 3 |
20 |
| HAE6 |
Vilshofen |
An der Donau 7 |
5 |
| |
Angebot
|
|
| bezdbs |
finame |
mpreis |
| DBS1 |
HAE3 |
7100.00 |
| DBS11 |
HAE4 |
500.00 |
| DBS3 |
HAE3 |
NULL |
| DBS4 |
HAE2 |
1800.00 |
| DBS5 |
HAE3 |
NULL |
| DBS6 |
HAE1 |
1700.50 |
| DBS7 |
HAE4 |
4500.00 |
| DBS8 |
HAE2 |
1140.00 |
| DBS8 |
HAE5 |
1000.00 |
| DBS8 |
HAE6 |
1150.00 |
| DBS9 |
HAE1 |
2200.50 |
| DBS9 |
HAE2 |
2500.00 |
| DBS9 |
HAE4 |
3150.00 |
| |
9.2.2 Lösung |
|
Relation Produzenten |
|
|
insert into produzenten values ('P3', 'Berlin', 'www.p3.com');
|
|
|
insert into produzenten values ('P1', 'Hamburg', 'www.p1.de');
|
|
|
insert into produzenten values ('P2', 'Frankfurt', 'www.p2.de');
|
|
|
insert into produzenten values ('P4', 'Rom', 'www.p4.it');
|
|
|
insert into produzenten values ('P5', 'Passau', 'www.p5.info');
|
|
Relation DBS |
|
|
insert into dbs values
|
|
|
('DBS1', 'RDBS', 'UNIX', 9500.10, 'P1', '2019-07-20'),
|
|
|
('DBS2', 'RDBS', 'UNIX', 3000.20, 'P1', '2020-10-20'),
|
|
|
('DBS9', 'NoSQL', 'LINUX', 3000.20, 'P1', '2022-01-01'),
|
|
|
('DBS8', 'RDBS', 'LINUX', 1200.30, 'P2', '2021-08-20'),
|
|
|
('DBS7', 'OODBS', 'UNIX', 5000.40, 'P3', '2015-07-20'),
|
|
|
('DBS6', 'OODBS', 'WINDOWS', 1800.55, 'P2', '2022-06-20'),
|
|
|
('DBS5', 'OODBS', 'LINUX', 900.66, 'P1', '2021-04-20'),
|
|
|
('DBS4', 'NoSQL', 'WINDOWS', 2000.77, 'P4', '2019-02-20'),
|
|
|
('DBS3', 'RDBS', 'LINUX', 2301.00, 'P2', '2022-02-26'),
|
|
|
('DBS10', 'RDBS', 'WINDOWS', 600.88, 'P4', '2021-03-20'),
|
|
|
('DBS11', 'RDBS', 'WINDOWS', 800.90, 'P5', '2020-11-20');
|
|
Relation Haendler |
|
|
insert into haendler VALUES
|
|
|
('HAE1', 'Frankfurt', 'Hammerweg 5', 10),
|
|
|
('HAE5', 'Ravensburg', 'Hammerstraße 3', 20),
|
|
|
('HAE2', 'München', 'Hummelweg 99', 6),
|
|
|
('HAE3', 'Passau', 'Langstr. 1', 12),
|
|
|
('HAE6', 'Vilshofen', 'An der Donau 7', 5),
|
|
|
('HAE4', 'Stuttgart', 'Bahnhofstr. 20', 8);
|
|
Relation Angebot |
|
|
Insert into angebot values ('DBS3', 'HAE3', NULL),
|
|
|
('DBS11', 'HAE4', 500.00),
|
|
|
('DBS9', 'HAE1', 2200.50),
|
|
|
('DBS9', 'HAE2', 2500.00),
|
|
|
('DBS8', 'HAE5', 1000.00),
|
|
|
('DBS9', 'HAE4', 3150.00),
|
|
|
('DBS7', 'HAE4', 4500.00),
|
|
|
('DBS6', 'HAE1', 1700.50),
|
|
|
('DBS4', 'HAE2', 1800.00),
|
|
|
('DBS5', 'HAE3', NULL),
|
|
|
('DBS1', 'HAE3', 7100.00),
|
|
|
('DBS8', 'HAE6', 1150.00),
|
|
|
('DBS8', 'HAE2', 1140.00);
|
|
9.3 Unvollständige Daten |
|
9.3.1 Aufgabe |
|
|
a) Geben Sie alle teilweise unvollständigen Tupel (Zeilen) der nachfolgend angegebenen Relation in DBS ein.
|
|
|
b) Löschen Sie die Tupel zu den Datenbanksystemen mit den Bezeichnungen DBS12, DBS22, DBS44 und DBS55 mit einem einzigen Befehl.
|
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS12 |
RDBS |
Windows |
8000.00 |
P3 |
0001-01-23 |
| DBS22 |
RDBS |
UNIX |
2000.99 |
P1 |
0000-00-00 |
| DBS44 |
OOBS |
UNIX |
NULL |
P3 |
NULL |
| DBS55 |
|
UNIX |
NULL |
P2 |
NULL |
| |
9.3.2 Lösung |
|
|
a)
|
|
|
insert into dbs values ('DBS12', 'RDBS', 'Windows', 8000 , 'P3', '1.1.23');
|
|
|
insert into dbs (bezdbs, typ, lpreis, pname, datum) values ('DBS22', 'RDBS', 2000.99 , 'P1', '20.1.2018');
|
|
|
insert into dbs (bezdbs, typ, pname) values ('DBS44', 'OOBS', 'P3');
|
|
|
insert into dbs (bezdbs, pname) values ('DBS55', 'P2');
|
|
|
b)
|
|
|
delete from dbs where bezdbs IN ('DBS12', 'DBS22', 'DBS44', 'DBS55');
|
|
9.4 DBS - Test Eingabe |
|
9.4.1 Aufgabe |
|
|
a) Testen Sie folgende Eingabe:
|
|
|
insert into dbs (bezdbs) values ('DBS9');
|
|
Wie reagiert mySQL? |
|
|
b) Geben Sie folgenden Befehl ein:
|
|
|
insert into dbs (bezdbs) values ('DBS99');
|
|
Wie reagiert mySQL? |
|
9.4.2 Lösung |
|
a) |
|
Kein Eintrag, weil BezDBS Schlüssel ist und die Eingabe zu einem Doppeleintrag führen würde. |
|
b) |
|
Es fehlt ein Eintrag beim Fremdschlüssel typ. Deshalb gibt mySQL eine Warnung aus. |
|
9.5 Temporaer – Einrichten und Löschen |
|
9.5.1 Aufgabe |
|
|
a) Erzeugen Sie in einer beliebigen von Ihnen angelegten Datenbank die Relation Temporaer mit den Attributen Attr_1, Attr_2 und Attr_3. Die Datentypen sind smallint(1), char(5) und date.
|
|
|
b) Geben Sie diese Tupel ein und die Relation dann aus.
|
|
|
(5, 'za', '31.12.2023');
|
|
|
(4, 'zb', '20-04-24');
|
|
|
(9, 'za', '2019-12-24');
|
|
|
(8, 'zb', '2024-01-20');
|
|
Temporaer |
|
| attr_1 |
attr_2 |
attr_3 |
| 5 |
za |
0000-00-00 |
| 4 |
zb |
2020-04-24 |
| 9 |
za |
2019-12-24 |
| 8 |
zb |
2024-01-20 |
| |
|
c) Interpretieren Sie die Datumsangaben in der erzeugten Relation.
|
|
|
d) Löschen Sie die Tupel, die in attr_1 den Eintrag 4 oder 5 und in attr_2 den Eintrag zb haben. Geben Sie die neue Tabelle aus.
|
|
|
e) Erstellen Sie eine Tabellenausgabe mit Tupeln deren Datumsangaben vor dem 1.1.23 liegen.
|
|
|
f) Löschen Sie die verbliebenen Tupel
|
|
|
g) Löschen Sie die Relation
|
|
9.5.2 Lösung |
|
|
a)
|
|
|
create table temporaer
|
|
|
(attr_1 smallint(1), attr_2 char(5), attr_3 date);
|
|
|
b)
|
|
|
insert into temporaer
|
|
|
values (5, 'za', '31.12.2023');
|
|
|
insert into temporaer
|
|
|
values (4, 'zb', '20-04-24');
|
|
|
insert into temporaer
|
|
|
values (9, 'za', '2019-12-24');
|
|
|
insert into temporaer
|
|
|
values (8, 'zb', '2024-01-20');
|
|
Temporaer |
|
| attr_1 |
attr_2 |
attr_3 |
| 5 |
za |
0000-00-00 |
| 4 |
zb |
2020-04-24 |
| 9 |
za |
2019-12-24 |
| 8 |
zb |
2024-01-20 |
| |
|
c)
|
|
|
Die erste Datumsangabe konnte von mySQL nicht interpretiert werden.
|
|
|
Die zweite entspricht der voreingestellten Standardnotation für Datumsangaben.
|
|
|
Die dritte und vierte Angabe wurde von MySQL automatisch angepasst.
|
|
Anmerkung: Jedes Datenbanksystem hat eine voreingestellte Standardnotation für Datumsangaben, die an die eigenen Bedürfnisse angepasst werden kann.
|
|
|
d)
|
|
|
delete from temporaer where (attr_1=4 or attr_1=5) and attr_2='zb';
|
|
|
select * from temporaer;
|
|
| attr_1 |
attr_2 |
attr_3 |
| 5 |
za |
0000-00-00 |
| 9 |
za |
2019-12-24 |
| 8 |
zb |
2024-01-20 |
| |
|
e)
|
|
|
select * from temporaer where attr_3 < '2023-01-01';
|
|
| attr_1 |
attr_2 |
attr_3 |
| 5 |
za |
0000-00-00 |
| 9 |
za |
2019-12-24 |
| |
|
f)
|
|
|
delete from temporaer;
|
|
|
g)
|
|
|
drop table temporaer;
|
|
9.6 DBS ergänzen und bearbeiten |
|
9.6.1 Aufgabe |
|
|
a) Tragen Sie diese Tupel in die Relation DBS ein:
|
|
|
DBS12 ORDBS UNIX 5000 P3
|
|
|
DBS14 ORDBS LINUX 2000 P2
|
|
|
DBS13 IRS Windows 9000 P1 2009-11-01
|
|
|
b) Geben Sie dann eine Tabelle mit genau diesen Tupeln und dieser Attributsreihenfolge aus.
|
|
|
c) Geben Sie die Bezeichnung, den Typ und den Preis der Systeme aus, die mit UNIX oder LINUX laufen. Sortieren Sie nach der Bezeichnung
|
|
9.6.2 Lösung |
|
|
a)
|
|
|
insert into dbs (bezdbs, typ, plattform, lpreis, pname) values ('DBS12', 'ORDBS' , 'UNIX', 5000.00, 'P3');
|
|
|
insert into dbs (bezdbs, typ, plattform, lpreis, pname) values ('DBS14', 'ORDBS' , 'LINUX', 2000.00, 'P2');
|
|
|
insert into dbs values ('DBS13', 'IRS' , 'Windows', 9000.00, 'P1', '2009-11-01');
|
|
|
b)
|
|
|
SELECT * FROM DBS where bezdbs IN ('DBS12', 'DBS14', 'DBS13');
|
|
DBS - Auswahl |
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS12 |
ORDBS |
UNIX |
5000.00 |
P3 |
NULL |
| DBS13 |
IRS |
Windows |
9000.00 |
P1 |
2009-11-01 |
| DBS14 |
ORDBS |
LINUX |
2000.00 |
P2 |
NULL |
| |
|
c)
|
|
|
select bezdbs, typ, lpreis from dbs where plattform='UNIX' or plattform='LINUX' order by typ, lpreis;
|
|
UNIX oder LINUX
|
|
| bezdbs |
typ |
lpreis |
| DBS9 |
NoSQL |
3000.20 |
| DBS5 |
OODBS |
900.66 |
| DBS7 |
OODBS |
5000.40 |
| DBS14 |
ORDBS |
2000.00 |
| DBS12 |
ORDBS |
5000.00 |
| DBS8 |
RDBS |
1200.30 |
| DBS3 |
RDBS |
2301.00 |
| DBS2 |
RDBS |
3000.20 |
| DBS1 |
RDBS |
9500.10 |
| |
9.7 DBS - Projektion, Selektion |
|
9.7.1 Aufgabe |
|
Ausgangspunkt sind die zwei Relationen DBS und Produzenten von Aufgabe 9.1: |
|
DBS |
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS1 |
RDBS |
UNIX |
9500.10 |
P1 |
2019-07-20 |
| DBS10 |
RDBS |
WINDOWS |
600.88 |
P4 |
2021-03-20 |
| DBS11 |
RDBS |
WINDOWS |
800.90 |
P5 |
2020-11-20 |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
| DBS3 |
RDBS |
LINUX |
2301.00 |
P2 |
2022-02-26 |
| DBS4 |
NoSQL |
WINDOWS |
2000.77 |
P4 |
2019-02-20 |
| DBS5 |
OODBS |
LINUX |
900.66 |
P1 |
2021-04-20 |
| DBS6 |
OODBS |
WINDOWS |
1800.55 |
P2 |
2022-06-20 |
| DBS7 |
OODBS |
UNIX |
5000.40 |
P3 |
2015-07-20 |
| DBS8 |
RDBS |
LINUX |
1200.30 |
P2 |
2021-08-20 |
| DBS9 |
NoSQL |
LINUX |
3000.20 |
P1 |
2022-01-01 |
| |
Produzenten;
|
|
| pname |
stadt |
web |
| P1 |
Hamburg |
www.p1.de |
| P2 |
Frankfurt |
www.p2.de |
| P3 |
Berlin |
www.p3.com |
| P4 |
Rom |
www.p4.it |
| P5 |
Passau |
www.p5.inf |
| |
|
a) Die folgende Tabelle gibt Informationen der Datenbanksysteme zusammen mit dem Produzenten und seinem Firmensitz an. Formulieren Sie die Abfrage.
|
|
| Datenbanksystem |
DBS-Typ |
Listenpreis |
Produzent |
Stadt |
| DBS1 |
RDBS |
9500.10 |
P1 |
Hamburg |
| DBS2 |
RDBS |
3000.20 |
P1 |
Hamburg |
| DBS3 |
RDBS |
2301.00 |
P2 |
Frankfurt |
| DBS8 |
RDBS |
1200.30 |
P2 |
Frankfurt |
| |
|
b) Die folgende Tabelle gibt die Datenbanksysteme an, deren Produzenten in Hamburg ansässig sind und deren Peis über dem Durchschnittspreis aller Datenbanksysteme liegt. Formulieren Sie die Abfrage.
|
|
| Datenbanksystem |
DBS-Typ |
Listenpreis |
Produzent |
Stadt |
| DBS1 |
RDBS |
9500.10 |
P1 |
Hamburg |
| DBS2 |
RDBS |
3000.20 |
P1 |
Hamburg |
| DBS7 |
OODBS |
5000.40 |
P3 |
Hamburg |
| DBS9 |
NoSQL |
3000.20 |
P1 |
Hamburg |
| |
Hinweis: Ein Teil der Selektion erfolgte über eine Rechenoperation. |
|
|
c) Die folgende Tabelle gibt für die Typen von Datenbanksystemen in der Relation die Anzahl, den Durchschnittspreis, den maximalen Preis und den kleinsten Preis an. Formulieren Sie die Abfrage.
|
|
DBS-Typen und ihre Preise |
|
| DBS-Typ |
Anzahl |
Durchschnittspreis |
Kleinster Preis |
Maximaler Preis |
| RDBS |
6 |
2,900.56 |
600.88 |
9,500.10 |
| OODBS |
3 |
2,567.20 |
900.66 |
5,000.40 |
| NoSQL |
2 |
2,500.49 |
2,000.77 |
3,000.20 |
| |
Aufpassen: amerikanische Zahlendarstellung. |
|
9.7.2 Lösung |
|
|
a)
|
|
|
select d.bezdbs as Datenbanksystem, d.typ as "DBS-Typ", d.lpreis as Listenpreis, d.pname as Produzent, p.stadt as Stadt
|
|
|
from dbs d, produzenten p
|
|
|
where d.pname=p.pname and (d.typ='RDBS' and d.lpreis > 1000);
|
|
|
b)
|
|
|
select d.bezdbs as Datenbanksystem, d.typ as "DBS-Typ", d.lpreis as Listenpreis, d.pname as Produzent, p.stadt as Stadt
|
|
|
from dbs d, produzenten p
|
|
|
where p.stadt='Hamburg' and lpreis > (select avg(lpreis) from dbs);
|
|
|
c)
|
|
|
select typ as "DBS-Typ", count(*) as Anzahl,
|
|
|
format(avg(lpreis),2) as Durchschnittspreis,
|
|
|
format(min(lpreis),2) as "Kleinster Preis",
|
|
|
format(max(lpreis),2) as "Maximaler Preis"
|
|
|
from dbs group by (typ) order by typ desc;
|
|
9.8 DBS – Unix-Systeme |
|
Ausgangspunkt ist die Relation DBS von Aufgabe 9.1. |
|
9.8.1 Aufgabe |
|
Erstellen Sie eine Tabelle mit den Attributen BezDBS, Typ und LPreis für die Datenbanksysteme, die unter UNIX laufen. Sortieren Sie aufsteigend nach dem Preis. |
|
9.8.2 Lösung |
|
|
select bezdbs, typ, lpreis
|
|
|
from dbs where plattform='UNIX' order by lpreis;
|
|
Datenbanksysteme mit Unix |
|
| bezdbs |
typ |
lpreis |
| DBS2 |
RDBS |
3000.20 |
| DBS7 |
OODBS |
5000.40 |
| DBS1 |
RDBS |
9500.10 |
| |
9.9 MarktDBS – Händler außerhalb RV |
|
9.9.1 Aufgabe |
|
Geben Sie eine Tabelle mit den Händlern aus, die nicht in Ravensburg (RV) ansässig sind (mit allen Attributen). |
|
9.9.2 Lösung |
|
|
select * from haendler where NOT ort = 'Ravensburg' order by fname;
|
|
Händler von außerhalb Ravensburg |
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE2 |
München |
Hummelweg 99 |
6 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| HAE4 |
Stuttgart |
Bahnhofstr. 20 |
8 |
| HAE6 |
Vilshofen |
An der Donau 7 |
5 |
| |
9.10 MarktDBS – spezielle Händler |
|
9.10.1 Aufgabe |
|
Bestimmen Sie aus der Relation Haendler alle Händler, die nicht in Ravensburg oder in Stuttgart ansässig sind und die mehr als 9 % Rabatt geben. |
|
9.10.2 Lösung |
|
|
select * from haendler where
|
|
|
(NOT (ort = 'Ravensburg' or ort = 'Stuttgart') and rabatt > 9);
|
|
Spezielle Haendler |
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| |
9.11 MarktDBS – Defizite in Haendler |
|
9.11.1 Aufgabe |
|
|
a) Ergänzen Sie folgende Tupel in Haendler:
|
|
| fname |
ort |
strasse |
rabatt |
| HAE10 |
Waldhausen |
Hauptstraße 1 |
0 |
| HAE7 |
NULL |
NULL |
NULL |
| HAE8 |
Ulm |
NULL |
NULL |
| HAE9 |
Ravensburg |
Galgenhalde 7 |
NULL |
| |
|
b) Bestimmen Sie alle Händler, die keinen Rabatt geben.
|
|
|
c) Bestimmen Sie alle Händler, bei denen die Rabattangabe fehlt.
|
|
|
d) Bestimmen Sie die Händler, bei denen ein Leereintrag vorhanden ist oder mehrere.
|
|
|
e) Bestimmen Sie die Händler, bei denen alle Angaben vorhanden sind.
|
|
9.11.2 Lösung |
|
|
a)
|
|
|
insert into haendler (fname) values ('HAE7');
|
|
|
insert into haendler (fname, ort) values ('HAE8', 'Ulm');
|
|
|
insert into haendler (fname, ort, strasse) values ('HAE9', 'Ravensburg', 'Galgenhalde 7');
|
|
|
insert into haendler values ('HAE10', 'Waldhausen', 'Hauptstraße 1', 0);
|
|
|
b)
|
|
|
select * from haendler where rabatt=0;
|
|
Explizit kein Rabatt |
|
| fname |
ort |
strasse |
rabatt |
| HAE10 |
Waldhausen |
Hauptstraße 1 |
0 |
| |
|
|
|
|
c)
|
|
|
select * from haendler where rabatt is null;
|
|
Fehlende Rabattangaben
|
|
| fname |
ort |
strasse |
rabatt |
| HAE7 |
NULL |
NULL |
NULL |
| HAE8 |
Ulm |
NULL |
NULL |
| HAE9 |
Ravensburg |
Galgenhalde 7 |
NULL |
| |
|
d)
|
|
|
select * from haendler where rabatt is null or strasse is null or ort is null;
|
|
Händler mit Leereinträgen
|
|
| fname |
ort |
strasse |
rabatt |
| HAE7 |
NULL |
NULL |
NULL |
| HAE8 |
Ulm |
NULL |
NULL |
| HAE9 |
Ravensburg |
Galgenhalde 7 |
NULL |
| |
|
e)
|
|
|
select * from haendler where not (rabatt is null or strasse is null or ort is null);
|
|
“Vollständige” Händler
|
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE10 |
Waldhausen |
Hauptstraße 1 |
0 |
| HAE2 |
München |
Hummelweg 99 |
6 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| HAE4 |
Stuttgart |
Bahnhofstr. 20 |
8 |
| HAE5 |
Ravensburg |
Hammerstraße 3 |
20 |
| HAE6 |
Vilshofen |
An der Donau 7 |
5 |
| |
9.12 DBS – Select mit Berechnungen |
|
Ausgangspunkt ist die Relation DBS aus Aufgabe 9.1. |
|
9.12.1 Aufgabe |
|
Erstellen Sie einen SQL-Befehl, der - wie in der folgenden Tabelle dargestellt – von der Relation DBS die Datenbankbezeichnung, den Preis des Datenbanksystems, den Preis erhöht um 19% sowie die Differenz der beiden Preise ausgibt. Geben Sie nur die Tupel aus, die eine Preisangabe haben. Vergessen Sie nicht, die Spaltenüberschriften zu vergeben. |
|
Tabelle mit Berechnungen |
|
| DBS |
Listenpreis |
LP mit MWSt |
MWSt |
| DBS1 |
9500.10 |
11,305.12 |
1,805.02 |
| DBS10 |
600.88 |
715.05 |
114.17 |
| DBS11 |
800.90 |
953.07 |
152.17 |
| DBS2 |
3000.20 |
3,570.24 |
570.04 |
| DBS3 |
2301.00 |
2,738.19 |
437.19 |
| DBS4 |
2000.77 |
2,380.92 |
380.15 |
| DBS5 |
900.66 |
1,071.79 |
171.13 |
| DBS6 |
1800.55 |
2,142.65 |
342.10 |
| DBS7 |
5000.40 |
5,950.48 |
950.08 |
| DBS8 |
1200.30 |
1,428.36 |
228.06 |
| DBS9 |
3000.20 |
3,570.24 |
570.04 |
| |
Aufpassen: teilweise amerikanische Zahlendarstellung. |
|
9.12.2 Lösung |
|
|
select bezdbs as "DBS",
|
|
|
lpreis as "Listenpreis",
|
|
|
format(lpreis*1.19,2) as "LP mit MWSt",
|
|
|
format(lpreis*1.19-lpreis,2) as "MWSt"
|
|
|
from dbs where not lpreis is null;
|
|
9.13 DBS - Preisspannen |
|
9.13.1 Aufgabe |
|
Es geht wieder um DBS von MarktDBS aus Aufgabe 9.1. Bestimmen Sie den Befehl, der zur folgenden Tabelle führt. Die Tabelle enthält alle Tupel bei denen der Preis NICHT zwischen 2000 und 5000 Euro liegt. Beachten Sie die Sortierung. |
|
DBS - Auswahl |
|
| bezdbs |
typ |
lpreis |
| DBS10 |
RDBS |
600.88 |
| DBS11 |
RDBS |
800.90 |
| DBS5 |
OODBS |
900.66 |
| DBS8 |
RDBS |
1200.30 |
| DBS6 |
OODBS |
1800.55 |
| DBS7 |
OODBS |
5000.40 |
| DBS1 |
RDBS |
9500.10 |
| |
9.13.2 Lösung |
|
|
select bezdbs, typ, lpreis
|
|
|
from dbs
|
|
|
where NOT lpreis between 2000 and 5000
|
|
|
order by lpreis;
|
|
9.14 Datenbank BaeKuch |
|
9.14.1 Aufgabe |
|
Legen Sie eine Datenbank BaeKuch (Bäcker / Kuchen) an. Richten Sie die folgende Relation Baecker ein und befüllen Sie sie mit den angegebenen Daten. Die Datentypen sind number(2) für NR, varchar2(10) für NAME, derselbe für ORT, number(1) für STATUS. Schlüssel ist NR. |
|
Baecker |
|
| nr |
name |
ort |
status |
| 1 |
Zirske |
Biberach |
2 |
| 2 |
Roth |
Ravensburg |
1 |
| 3 |
Faller |
Weingarten |
1 |
| 4 |
Alf |
Ulm |
4 |
| 5 |
Knollo |
Weingarten |
3 |
| 6 |
Maier |
Ulm |
4 |
| |
9.14.2 Lösung |
|
|
create database BaeKuch default character set latin1 collate latin1_german1_ci;
|
|
|
create table baecker (nr smallint(2), name varchar(10), ort varchar(10), status smallint(1), primary key (nr));
|
|
|
insert into baecker values (6, 'Maier', 'Ulm', 4);
|
|
|
insert into baecker values (1, 'Zirske', 'Biberach', 2);
|
|
|
insert into baecker values (3, 'Faller', 'Weingarten', 1);
|
|
|
insert into baecker values (2, 'Roth', 'Ravensburg', 1);
|
|
|
insert into baecker values (4, 'Alf', 'Ulm', 4);
|
|
|
insert into baecker values (5, 'Knollo', 'Weingarten', 3);
|
|
9.15 Kuchen in BaeKuch |
|
9.15.1 Aufgabe |
|
Richten Sie in der Datenbank BaeKuch die Relation Kuchen ein und befüllen Sie sie mit den angegebenen Daten. Bez (Bezeichnung) hat den Datentyp char(15), Kalstueck (Kalorien pro Stück) den Datentyp number(5), Preis number(5,2), BaeckerNr number(2). BaeckerNr ist Fremdschlüssel bzgl. Kuchen. Hier die Daten: |
|
Kuchen |
|
| bez |
kalstueck |
preis |
baeckernr |
| Obstschnitte |
600 |
0.75 |
6 |
| Apfelkuchen |
650 |
1.75 |
6 |
| Kirschkuchen |
720 |
2.10 |
1 |
| Kirschtorte |
720 |
2.20 |
2 |
| Mohnkuchen |
920 |
1.98 |
1 |
| Sahnetorte |
1300 |
2.05 |
3 |
| |
9.15.2 Lösung |
|
|
create table kuchen (bez char(15),
|
|
|
kalstueck smallint(5), preis decimal(5,2),
|
|
|
baeckernr smallint(2) references baecker(baecker));
|
|
|
insert into kuchen values ('Obstschnitte', 600 , 0.75 , 6);
|
|
|
insert into kuchen values ('Apfelkuchen', 650 , 1.75 , 6);
|
|
|
insert into kuchen values ('Kirschkuchen', 720 , 2.10 , 1);
|
|
|
insert into kuchen values ('Kirschtorte', 720 , 2.20 , 2);
|
|
|
insert into kuchen values ('Mohnkuchen', 920 , 1.98 , 1);
|
|
|
insert into kuchen values ('Sahnetorte', 1300 , 2.05 , 3);
|
|
9.16 BaeKuch - Join |
|
9.16.1 Aufgaben |
|
|
a) Verknüpfen Sie die beiden Relationen Kuchen und Baecker mit all ihren Attributen entlang der Bäckernummer und geben Sie die verknüpfte Tabelle aus.
|
|
|
b) Die folgende Tabelle gibt einige Attribute von Kuchen und Bäckern aus. Formulieren Sie die Abfrage.
|
|
Kuchen und ihre Bäcker |
|
| Kuchen |
Kalorien |
Preis |
Bäcker |
Ort |
| Apfelkuchen |
650 |
1.75 |
Maier |
Ulm |
| Kirschkuchen |
720 |
2.10 |
Zirske |
Biberach |
| Kirschtorte |
720 |
2.20 |
Roth |
Ravensburg |
| Mohnkuchen |
920 |
1.98 |
Zirske |
Biberach |
| Obstschnitte |
600 |
0.75 |
Maier |
Ulm |
| Sahnetorte |
1300 |
2.05 |
Faller |
Weingarten |
| |
|
c) Bäcker Zirske nimmt auch Obstschnitten (550 Kilokalorien, 0.90 Euro) und Kirschtorten (700 Kilokalorien, 2.10 Euro) in sein Sortiment auf. Tragen Sie diese neuen Angebote in die entsprechende Relation ein und geben Sie die Relation sortiert nach den Bezeichnungen aus.
|
|
Anmerkung: Weitere Aufgaben zu dieser Datenbank folgen unten. |
|
9.16.2 Lösung |
|
|
a)
|
|
|
select * from kuchen k, baecker b where b.nr=k.baeckernr;
|
|
Join über baecker / kuchen |
|
| bez |
kalstueck |
preis |
baeckernr |
nr |
name |
ort |
status |
| Obstschnitte |
600 |
0.75 |
6 |
6 |
Maier |
Ulm |
4 |
| Apfelkuchen |
650 |
1.75 |
6 |
6 |
Maier |
Ulm |
4 |
| Kirschkuchen |
720 |
2.10 |
1 |
1 |
Zirske |
Biberach |
2 |
| Kirschtorte |
720 |
2.20 |
2 |
2 |
Roth |
Ravensburg |
1 |
| Mohnkuchen |
920 |
1.98 |
1 |
1 |
Zirske |
Biberach |
2 |
| Sahnetorte |
1300 |
2.05 |
3 |
3 |
Faller |
Weingarten |
1 |
| |
|
b)
|
|
|
select k.bez as Kuchen, k.kalstueck as Kalorien, k.preis as Preis, b.name as "Bäcker", b.ort as Ort from kuchen k, baecker b where b.nr=k.baeckernr order by Kuchen;
|
|
|
c)
|
|
|
insert into kuchen values ('Obstschnitten', 550, 0.90, 1);
|
|
|
insert into kuchen values ('Kirschtorte', 700, 2.10, 1);
|
|
|
select * from kuchen order by bez;
|
|
Kuchen mit neuen Angeboten
|
|
| bez |
kalstueck |
preis |
baeckernr |
| Apfelkuchen |
650 |
1.75 |
6 |
| Kirschkuchen |
720 |
2.10 |
1 |
| Kirschtorte |
720 |
2.20 |
2 |
| Kirschtorte |
700 |
2.10 |
1 |
| Mohnkuchen |
920 |
1.98 |
1 |
| Obstschnitte |
600 |
0.75 |
6 |
| Obstschnitte |
550 |
0.90 |
1 |
| Sahnetorte |
1300 |
2.05 |
3 |
| |
9.17 Kuchen - Maskierung 1 |
|
9.17.1 Aufgabe |
|
BaeKuch wird in Aufgabe 9.14 eingerichtet. Geben Sie von der Relation Kuchen in der Datenbank BaeKuch alle Tupel aus, bei denen „torte“ in der Bez(eichnung) vorkommt. |
|
9.17.2 Lösung |
|
|
select * from kuchen where bez like '%torte%';
|
|
Torten! |
|
| bez |
kalstueck |
preis |
baeckernr |
| Kirschtorte |
720 |
2.20 |
2 |
| Sahnetorte |
1300 |
2.05 |
3 |
| Kirschtorte |
700 |
2.10 |
1 |
| |
9.18 Kuchen - Maskierung 2 |
|
9.18.1 Aufgabe |
|
Es geht um Datenbank BaeKuch von Aufgabe 9.14 und die Relation Kuchen. Geben Sie alle Tupel aus, bei denen in der Bezeichnung „Kuchen“ vorkommt aber nicht „Apfel“ (da Sie gegen Äpfel allergisch sind). |
|
9.18.2 Lösung |
|
|
select * from kuchen
|
|
|
where bez like '%kuchen%'
|
|
|
and not bez like 'Apfel%';
|
|
| bez |
kalstueck |
preis |
baeckernr |
| Kirschkuchen |
720 |
2.10 |
1 |
| Mohnkuchen |
920 |
1.98 |
1 |
| |
9.19 MarktDBS – Daten ändern |
|
9.19.1 Aufgabe |
|
|
a) Geben Sie das Tupel (die Zeile) aus, das in BezDBS den Eintrag DBS3 hat.
|
|
|
b) Verändern Sie den Preis von DBS3 zu 2901 Euro und setzen Sie das Datum für DBS3 auf 1.1.2024.
|
|
|
c) Geben Sie das veränderte Tupel zu DBS3 aus.
|
|
9.19.2 Lösung |
|
|
a)
|
|
|
select * from dbs where bezdbs='DBS3';
|
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS3 |
RDBS |
LINUX |
2301.00 |
P2 |
2022-02-26 |
| |
|
b)
|
|
|
update dbs set lpreis=2901 where bezdbs='DBS3';
|
|
|
update dbs set datum='2024.1.1' where bezdbs='DBS3';
|
|
|
c)
|
|
|
select * from dbs where bezdbs='DBS3';
|
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
| DBS3 |
RDBS |
LINUX |
2901.00 |
P2 |
2024-01-01 |
| |
|
|
9.20 MarktDBS - Attribut ergänzen |
|
9.20.1 Aufgaben |
|
|
a) Fügen Sie der Relation DBS das Attribut DBNr (Datenbanknummer) hinzu. Geben Sie die veränderte Relation aus.
|
|
|
b) Ergänzen Sie in der Relation DBS das Tupel von DBS1 mit DBNr=101.
|
|
|
b) Löschen Sie das Attribut DBNr wieder.
|
|
9.20.2 Lösung |
|
|
a)
|
|
|
alter table dbs add DBNr smallint(4);
|
|
|
select * from dbs;
|
|
DBS mit Attribut DBNr |
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
DBNr |
| DBS1 |
RDBS |
UNIX |
9500.10 |
P1 |
2019-07-20 |
NULL |
| DBS10 |
RDBS |
WINDOWS |
600.88 |
P4 |
2021-03-20 |
NULL |
| DBS11 |
RDBS |
WINDOWS |
800.90 |
P5 |
2020-11-20 |
NULL |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
NULL |
| DBS3 |
RDBS |
LINUX |
2901.00 |
P2 |
2024-01-01 |
NULL |
| DBS4 |
NoSQL |
WINDOWS |
2000.77 |
P4 |
2019-02-20 |
NULL |
| DBS5 |
OODBS |
LINUX |
900.66 |
P1 |
2021-04-20 |
NULL |
| DBS6 |
OODBS |
WINDOWS |
1800.55 |
P2 |
2022-06-20 |
NULL |
| DBS7 |
OODBS |
UNIX |
5000.40 |
P3 |
2015-07-20 |
NULL |
| DBS8 |
RDBS |
LINUX |
1200.30 |
P2 |
2021-08-20 |
NULL |
| DBS9 |
NoSQL |
LINUX |
3000.20 |
P1 |
2022-01-01 |
NULL |
| |
|
b)
|
|
|
update dbs set dbnr=101 where bezdbs = 'DBS2';
|
|
|
select * from dbs where bezdbs='DBS2';
|
|
DBS gekürzt
|
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
DBNr |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
101 |
| |
|
c)
|
|
|
alter table dbs drop column DBNr;
|
|
9.21 DBS – Rabatte ergänzen |
|
9.21.1 Aufgaben |
|
|
a) Ergänzen Sie die Relation DBS um ein Attribut Rabatt (smallint(2))
|
|
|
b) Tragen Sie in Rabatt Werte ein nach folgender Festsetzung:
|
|
|
- Für alle RDBS auf der Plattform UNIX gilt ein Rabatt von 10%, für die übrigen Plattformen 15%.
|
|
|
- Für NoSQL-Datenbanken gilt auf allen Plattformen 33%.
|
|
|
- OODBS haben unter UNIX und LINUX 12% Rabatt, unter Windows 40%.
|
|
|
c) Geben Sie dann die Daten aus, sortiert nach Typ und Plattform.
|
|
9.21.2 Lösung |
|
|
a)
|
|
|
alter table dbs add (rabatt smallint(2));
|
|
|
b)
|
|
|
update dbs set rabatt=10 where typ='RDBS' and plattform='UNIX';
|
|
|
update dbs set rabatt=15 where typ='RDBS' and NOT plattform='UNIX';
|
|
|
update dbs set rabatt=33 where typ='NoSQL';
|
|
|
update dbs set rabatt=12 where typ='OODBS' and (plattform='UNIX' or plattform='Linux');
|
|
|
update dbs set rabatt=40 where typ='OODBS' and plattform='Windows';
|
|
|
c)
|
|
|
select * from dbs order by typ, plattform;
|
|
Neue Rabattsätze |
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
rabatt |
| DBS9 |
NoSQL |
LINUX |
3000.20 |
P1 |
2022-01-01 |
33 |
| DBS4 |
NoSQL |
WINDOWS |
2000.77 |
P4 |
2019-02-20 |
33 |
| DBS5 |
OODBS |
LINUX |
900.66 |
P1 |
2021-04-20 |
12 |
| DBS7 |
OODBS |
UNIX |
5000.40 |
P3 |
2015-07-20 |
12 |
| DBS6 |
OODBS |
WINDOWS |
1800.55 |
P2 |
2022-06-20 |
40 |
| DBS3 |
RDBS |
LINUX |
2901.00 |
P2 |
2024-01-01 |
15 |
| DBS8 |
RDBS |
LINUX |
1200.30 |
P2 |
2021-08-20 |
15 |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
10 |
| DBS1 |
RDBS |
UNIX |
9500.10 |
P1 |
2019-07-20 |
10 |
| DBS11 |
RDBS |
WINDOWS |
800.90 |
P5 |
2020-11-20 |
15 |
| DBS10 |
RDBS |
WINDOWS |
600.88 |
P4 |
2021-03-20 |
15 |
| |
9.22 DBS - Funktionen berechnen für Gruppen |
|
9.22.1 Aufgabe |
|
Ausgangspunkt ist DBS von MarktDBS. Erstellen Sie eine Tabelle, bei der für alle Datenbanksystemtypen (DBS-Typ) der Durchschnittspreis, der maximale Preis (H-Preis), der niedrigste Preis (N-Preis) und die Anzahl der zum Typ gehörenden Systeme angegeben wird. |
|
9.22.2 Lösung |
|
|
select typ as "DBS-Typ",
|
|
|
format(avg(lpreis),2) as "Durchschnitt",
|
|
|
format(max(lpreis),2) as "H-Preis",
|
|
|
format(min(lpreis),2) as "N-Preis",
|
|
|
count(*) as "Anzahl" from dbs
|
|
|
group by typ order by max(lpreis) desc;
|
|
DBS-Typen und ihre Preise |
|
| DBS-Typ |
Durchschnitt |
H-Preis |
N-Preis |
Anzahl |
| RDBS |
3,000.56 |
9,500.10 |
600.88 |
6 |
| OODBS |
2,567.20 |
5,000.40 |
900.66 |
3 |
| NoSQL |
2,500.49 |
3,000.20 |
2,000.77 |
2 |
| |
9.23 DBS - Gruppen auswählen |
|
9.23.1 Aufgabe |
|
|
a) Erstellen Sie eine Tabelle für alle Typen von Datenbanksystemen (DBS-Typen) und dem Durchschnittspreis der zum Typ gehörenden Systeme.
|
|
|
b) Formulieren Sie den Befehl, der alle die DBS-Typen ausgibt, deren Durchschnittspreis über 2600,00 Euro liegt.
|
|
9.23.2 Lösung |
|
|
a)
|
|
|
select typ, format(avg(lpreis),2) as Durchschnitt from dbs group by typ;
|
|
DBS-Typen und ihr Durchschnittspreis |
|
| typ |
Durchschnitt |
| NoSQL |
2,500.49 |
| OODBS |
2,567.20 |
| RDBS |
3,000.56 |
| |
|
b)
|
|
|
select typ, format(avg(lpreis),2) from dbs
|
|
|
group by typ
|
|
|
having avg(lpreis) > 2550;
|
|
DBS-Typen mit höheren Durchschnittspreisen
|
|
| typ |
format(avg(lpreis),2) |
| OODBS |
2,567.20 |
| RDBS |
3,000.56 |
| |
9.24 MarktDBS – Union |
|
Wir gehen aus von der oben eingeführten Relation Haendler aus MarktDBS in ihrer ersten Fassung. Löschen Sie die evtl. hinzugefügten Tupel. |
|
Haendler |
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE2 |
München |
Hummelweg 99 |
6 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| HAE4 |
Stuttgart |
Bahnhofstr. 20 |
8 |
| HAE5 |
Ravensburg |
Hammerstraße 3 |
20 |
| HAE6 |
Vilshofen |
An der Donau 7 |
5 |
| |
9.24.1 Aufgabe |
|
|
a) Erstellen Sie eine Relation haendler_alt mit den folgenden Attributen.
|
|
|
fname: char(5)
|
|
|
ort: char(10)
|
|
|
strasse: char(20)
|
|
|
rabatt: Smallint(2)
|
|
Geben Sie diese Daten ein: |
|
Relation haendler_alt |
|
| fname |
ort |
strasse |
rabatt |
| HAEA |
München |
Hauptstr. 76 |
0 |
| HAEB |
Saulgau |
Kirschstr. 3 |
0 |
| HAEC |
Konstanz |
Am Ufer 10 |
0 |
| |
|
b) Führen Sie die Tupel von Haendler und Haendler_alt zusammen und geben Sie die Tabelle aus.
|
|
9.24.2 Lösung |
|
|
a)
|
|
|
create table haendler_alt
|
|
|
(fname char(5), ort char(10), strasse char(20),
|
|
|
rabatt smallint(2));
|
|
|
insert into haendler_alt values ('HAEA', 'München', 'Hauptstr. 76', 0);
|
|
|
insert into haendler_alt values ('HAEB', 'Saulgau', 'Kirschstr. 3', 0);
|
|
|
insert into haendler_alt values ('HAEC', 'Konstanz', 'Am Ufer 10', 0);
|
|
|
b)
|
|
|
select * from haendler
|
|
|
UNION
|
|
|
select * from haendler_alt;
|
|
Mit UNION vereinigt |
|
| fname |
ort |
strasse |
rabatt |
| HAE1 |
Frankfurt |
Hammerweg 5 |
10 |
| HAE2 |
München |
Hummelweg 99 |
6 |
| HAE3 |
Passau |
Langstr. 1 |
12 |
| HAE4 |
Stuttgart |
Bahnhofstr. 20 |
8 |
| HAE5 |
Ravensburg |
Hammerstraße 3 |
20 |
| HAE6 |
Vilshofen |
An der Donau 7 |
5 |
| HAEA |
München |
Hauptstr. 76 |
0 |
| HAEB |
Saulgau |
Kirschstr. 3 |
0 |
| HAEC |
Konstanz |
Am Ufer 10 |
0 |
| |
9.25 Datenbank Ang/Abt |
|
9.25.1 Aufgabe |
|
|
a) Legen Sie eine Datenbank AbtAng (Abteilungen / Angestellte) an.
|
|
|
b) Richten Sie die Relationen ABT (eilung) und ANG (estellte) ein
|
|
Die Attribute und Datentypen sind wie folgt: |
|
|
ABT.AbtBez: char(9) - Schlüssel
|
|
|
ABT.AbtLeiter: varchar(10) – Pflichtfeld
|
|
|
ABT.Standort: varchar(10),
|
|
|
ANG.PersNr: smallint(4) - Schlüssel
|
|
|
ANG.Name: varchar(10) – Pflichtfeld
|
|
|
ANG.Abteilung: char(9)
|
|
|
ANG.EinstDatum: date
|
|
Die beiden Relationen sind verknüpft, ang.abteilung ist Fremdschlüssel. Es soll sich um eine typische 1:m-Beziehung handeln: Ein Angestellter ist in genau einer Abteilung, eine Abteilung hat mehrere Angestellte. Vergeben Sie für den Fremdschlüssel die Bezeichnung FS_ang_abt (Fremdschlüssel bzgl. ABT und ANG). |
|
|
c) Befüllen Sie die beiden Relationen mit den folgenden Daten.
|
|
Relation ANG |
|
| PersNr |
Name |
Abteilung |
EinstDatum |
| 1001 |
Rumpel |
Org |
2023-11-1 |
| 1002 |
Müller |
Org |
2018-09-21 |
| 2001 |
Steiner |
IT |
2021-03-20 |
| 1010 |
Widmer |
Prod |
2022-05-19 |
| 1011 |
Jäger |
IT |
2019-05-20 |
| 1004 |
Prall |
Org |
2020-01-01 |
| 3001 |
Zart |
Prod |
2021-05-03 |
| |
Relation ABT
|
|
| AbtBez |
AbtLeiter |
Standort |
| IT |
Steiner |
Weingarten |
| Org |
Müller |
Ulm 1 |
| Prod |
Widmer |
Wangen |
| |
|
d) Verknüpfen Sie Abt und Ang mittels Join und geben Sie die Tabelle aus.
|
|
9.25.2 Lösung |
|
|
a)
|
|
|
create database AbtAng default character set latin1 collate latin1_german1_ci;
|
|
|
b)
|
|
|
create table abt (AbtBez char(9),
|
|
|
AbtLeiter varchar(10) not null,
|
|
|
Standort varchar(10),
|
|
|
primary key (AbtBez));
|
|
|
create table ang (PersNr smallint(4), Name varchar(10) not null, Abteilung char(9), EinstDatum date,
|
|
|
constraint fs_ang_abt foreign key (abteilung) references abt(abtbez));
|
|
|
c)
|
|
|
insert into abt values ('Org', 'Müller', 'Ulm 1');
|
|
|
insert into abt values ('IT', 'Steiner', 'Weingarten');
|
|
|
insert into abt values ('Prod', 'Widmer', 'Wangen');
|
|
|
insert into ang values (1001, 'Rumpel', 'Org', '2023.11.1');
|
|
|
insert into ang values (1002, 'Müller', 'Org', '2018.09.21');
|
|
|
insert into ang values (2001, 'Steiner', 'IT', '2021.3.20');
|
|
|
insert into ang values (1010, 'Widmer', 'Prod', '2022.5.19');
|
|
|
insert into ang values (1011, 'Jäger', 'IT', '2019.5.20');
|
|
|
insert into ang values (1004, 'Prall', 'Org', '2020.1.1');
|
|
|
insert into ang values (3001, 'Zart', 'Prod', '2021.5.3');
|
|
|
d)
|
|
|
select * from abt, ang where abt.abtbez=ang.abteilung order by abtbez;
|
|
Join mit Abt und Ang |
|
| AbtBez |
AbtLeiter |
Standort |
PersNr |
Name |
Abteilung |
EinstDatum |
| IT |
Steiner |
Weingarten |
1011 |
Jäger |
IT |
2019-05-20 |
| IT |
Steiner |
Weingarten |
2001 |
Steiner |
IT |
2021-03-20 |
| Org |
Müller |
Ulm 1 |
1001 |
Rumpel |
Org |
2023-11-01 |
| Org |
Müller |
Ulm 1 |
1002 |
Müller |
Org |
2018-09-21 |
| Org |
Müller |
Ulm 1 |
1004 |
Prall |
Org |
2020-01-01 |
| Prod |
Widmer |
Wangen |
3001 |
Zart |
Prod |
2021-05-03 |
| Prod |
Widmer |
Wangen |
1010 |
Widmer |
Prod |
2022-05-19 |
| |
9.26 Marktführer in MarktDBS |
|
9.26.1 Vorbemerkung |
|
Hier wird die Datenbank MarktDBS um eine Relation MSegment (Marktsegment) erweitert, die Informationen zum Marktführer in den einzelnen Segmenten (RDBS, No SQL, OODBS) dieses Marktes enthält. Marktführer ist das Datenbanksystem mit dem jeweils höchsten Marktanteil. Hier zur Erinnerung die Relation DBS, die dabei eine Rolle spielt. |
|
DBS in MarktDBS |
|
| bezdbs |
typ |
plattform |
lpreis |
pname |
datum |
rabatt |
| DBS1 |
RDBS |
UNIX |
9500.10 |
P1 |
2019-07-20 |
10 |
| DBS10 |
RDBS |
WINDOWS |
600.88 |
P4 |
2021-03-20 |
15 |
| DBS11 |
RDBS |
WINDOWS |
800.90 |
P5 |
2020-11-20 |
15 |
| DBS2 |
RDBS |
UNIX |
3000.20 |
P1 |
2020-10-20 |
10 |
| DBS3 |
RDBS |
LINUX |
2901.00 |
P2 |
2024-01-01 |
15 |
| DBS4 |
NoSQL |
WINDOWS |
2000.77 |
P4 |
2019-02-20 |
33 |
| DBS5 |
OODBS |
LINUX |
900.66 |
P1 |
2021-04-20 |
12 |
| DBS6 |
OODBS |
WINDOWS |
1800.55 |
P2 |
2022-06-20 |
40 |
| DBS7 |
OODBS |
UNIX |
5000.40 |
P3 |
2015-07-20 |
12 |
| DBS8 |
RDBS |
LINUX |
1200.30 |
P2 |
2021-08-20 |
15 |
| DBS9 |
NoSQL |
LINUX |
3000.20 |
P1 |
2022-01-01 |
33 |
| |
9.26.2 Aufgaben |
|
|
a) Richten Sie in der Datenbank MarktDBS eine Relation MSegment (Marktsegment) mit folgenden Attributen ein: Bez, Mafu und Anteil. Bez ist Schlüssel und enthält die Bezeichnung des Marktsegments entsprechend den Datenbanksystemtypen der Relation DBS. Mafu (Marktführer) enthält die Bezeichnung des Datenbanksystems, das Marktführer im jeweiligen Marktsegment ist. Es ist Fremdschlüssel zum Schlüssel bez von DBS. Anteil enthält den Marktanteil des Marktführers.
|
|
|
b) Tragen Sie folgende Daten in MSegment ein und geben Sie die Relation aus:
|
|
Relation MSegment |
|
| bez |
mafu |
Anteil |
| NoSQL |
DBS9 |
65 |
| OODBS |
DBS6 |
15 |
| RDBS |
DBS1 |
20 |
| |
|
c) Verknüpfen Sie DBS und MSegment so, dass zu jedem Datenbanksystem, das nicht Marktführer ist, der Marktführer angegeben wird. Die Ausgabetabelle soll die Attribute dbs.bezdbs, dbs.typ, dbs.lpreis, msegment.mafu und msegment.anteil enthalten. Vergeben Sie passende Spaltenüberschriften.
|
|
|
d) Erstellen Sie die grafische Fassung des Datenmodells MarktDBS.
|
|
9.26.3 Lösung |
|
|
a)
|
|
|
create table MSegment (bez char(5), mafu char(10), Anteil smallint(2),
|
|
|
primary key(bez),
|
|
|
foreign key (mafu) references dbs(bezdbs));
|
|
|
b)
|
|
|
insert into msegment values ('RDBS', 'DBS1', 20);
|
|
|
insert into msegment values ('OODBS', 'DBS6', 15);
|
|
|
insert into msegment values ('NoSQL', 'DBS9', 65);
|
|
|
SELECT * FROM msegment;
|
|
| bez |
mafu |
Anteil |
| NoSQL |
DBS9 |
65 |
| OODBS |
DBS6 |
15 |
| RDBS |
DBS1 |
20 |
| |
|
c)
|
|
|
SELECT a.bezdbs as Datenbanksystem, a.typ as Segment, lpreis as Listenpreis,
|
|
|
b.mafu as Marktführer, b.anteil as Anteil FROM dbs a, msegment b
|
|
|
where a.typ=b.bez and not(a.bezdbs=b.mafu) order by a.typ;
|
|
Datenbanksysteme und ihre Marktführer
|
|
| Datenbanksystem |
Segment |
Listenpreis |
Marktführer |
Anteil |
| DBS4 |
NoSQL |
2000.77 |
DBS9 |
65 |
| DBS5 |
OODBS |
900.66 |
DBS6 |
15 |
| DBS7 |
OODBS |
5000.40 |
DBS6 |
15 |
| DBS8 |
RDBS |
1200.30 |
DBS1 |
20 |
| DBS11 |
RDBS |
800.90 |
DBS1 |
20 |
| DBS2 |
RDBS |
3000.20 |
DBS1 |
20 |
| DBS3 |
RDBS |
2901.00 |
DBS1 |
20 |
| DBS10 |
RDBS |
600.88 |
DBS1 |
20 |
| |
|
d)
|
|
|
Das grafische Datenmodell von MarktDBS ergibt sich wie folgt:
|
|
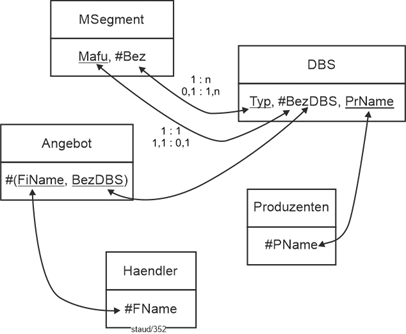
|
|
Abbildung 9.37-2: Datenmodell Markt für Datenbanksysteme – Erweitert |
|
9.27 Marktführer und ihre Anteile |
|
9.27.1 Aufgabe |
|
Ausgangspunkt sind die Relationen DBS und MSegment. Erzeugen Sie eine Tabelle, in der für jedes Marktsegement der Marktführer, sein Marktanteil und dessen Listenpreis angegeben ist. |
|
9.27.2 Lösung |
|
|
select b.mafu as "Marktführer", b.anteil as "Marktanteil",
|
|
|
a.lpreis as "Listenpreis"
|
|
|
from dbs a, msegment b
|
|
|
where b.mafu=a.bezdbs;
|
|
|
|
|
| Marktführer |
Marktanteil |
Listenpreis |
| DBS8 |
55 |
1200.30 |
| DBS9 |
65 |
3000.20 |
| DBS4 |
15 |
2000.77 |
| DBS6 |
80 |
1800.55 |
| DBS1 |
20 |
9500.10 |
| |
9.28 Datentypen in MarktDBS |
|
9.28.1 Aufgabe |
|
|
a) Legen Sie in MarktDBS eine Relation DT (Datentypen) mit folgenden Attributen an :
|
|
|
- BezDT (Bezeichnung Datentyp) mit char(12)
|
|
|
- BezDBS (Bezeichnung Datenbanksystem) mit char(10)
|
|
|
- BezDT und BezDBS sind zusammen Schlüssel der Relation. BezDBS ist Fremdschlüssel bzgl. DBS.
|
|
|
b) Geben Sie die folgenden (teilweise fiktiven) Daten ein:
|
|
| bezdt |
bezdbs |
| audio |
DBS6 |
| blob |
DBS1 |
| char |
DBS1 |
| char |
DBS3 |
| char |
DBS7 |
| date |
DBS1 |
| date |
DBS3 |
| datum |
DBS5 |
| decimal |
DBS4 |
| float |
DBS7 |
| fulltext |
DBS8 |
| integer |
DBS4 |
| integer |
DBS8 |
| number(x,y) |
DBS1 |
| text |
DBS2 |
| text |
DBS5 |
| time |
DBS3 |
| varchar |
DBS3 |
| video |
DBS6 |
| zahl |
DBS2 |
| zeichen |
DBS8 |
| |
|
c) Fügen Sie die Relationen DBS und DT zusammen, so dass zu jedem Datenbanksystem die jeweiligen Datentypen ausgegeben werden. Sortieren Sie die Ausgabe nach BezDBS und BezDT.
|
|
9.28.2 Lösung |
|
|
a)
|
|
|
create table dt (bezdt char(12), bezdbs char(10),
|
|
|
primary key (bezdt, bezdbs),
|
|
|
foreign key (bezdbs) references dbs(bezdbs));
|
|
|
b)
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS1', 'char');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS1', 'number(x,y)');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS1', 'blob');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS1', 'date');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS2', 'text');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS2', 'zahl');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS3', 'char');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS3', 'varchar');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS3', 'date');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS3', 'time');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS4', 'integer');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS4', 'decimal');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS5', 'text');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS5', 'datum');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS6', 'audio');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS6', 'video');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS7', 'char');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS7', 'float');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS8', 'integer');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS8', 'zeichen');
|
|
|
insert into dt (bezdbs, bezdt) values ('DBS8', 'fulltext');
|
|
c) |
|
Zur Lösung der Aufgabe muss ein Verbund (Join) mit DBS und DT realisiert werden. |
|
|
select a.bezdbs, a.typ, a. plattform, b.bezdt
|
|
|
from dbs a, dt b
|
|
|
where a.bezdbs = b.bezdbs order by a.bezdbs, b.bezdt;
|
|
| bezdbs |
typ |
plattform |
bezdt |
| DBS1 |
RDBS |
UNIX |
blob |
| DBS1 |
RDBS |
UNIX |
char |
| DBS1 |
RDBS |
UNIX |
date |
| DBS1 |
RDBS |
UNIX |
number(x,y) |
| DBS2 |
RDBS |
UNIX |
text |
| DBS2 |
RDBS |
UNIX |
zahl |
| DBS3 |
RDBS |
LINUX |
char |
| DBS3 |
RDBS |
LINUX |
date |
| DBS3 |
RDBS |
LINUX |
time |
| DBS3 |
RDBS |
LINUX |
varchar |
| DBS4 |
NoSQL |
WINDOWS |
decimal |
| DBS4 |
NoSQL |
WINDOWS |
integer |
| DBS5 |
OODBS |
LINUX |
datum |
| DBS5 |
OODBS |
LINUX |
text |
| DBS6 |
OODBS |
WINDOWS |
audio |
| DBS6 |
OODBS |
WINDOWS |
video |
| DBS7 |
OODBS |
UNIX |
char |
| DBS7 |
OODBS |
UNIX |
float |
| DBS8 |
RDBS |
LINUX |
fulltext |
| DBS8 |
RDBS |
LINUX |
integer |
| DBS8 |
RDBS |
LINUX |
zeichen |
| |
|
|
|
9.29 Create mit Subselect |
|
9.29.1 Aufgabe |
|
Wir arbeiten mit der Datenbank MarktDBS. Erstellen Sie ausgehend von der oben erstellten Relation DT mit einem Subselect-Befehl eine Relation DT_numerisch mit den beiden Attributen BezDT und BezDBS, die nur die Tupel der numerischen Datentypen enthält. Geben Sie die neue Relation aus. |
|
9.29.2 Lösung |
|
|
create table dt_numerisch as
|
|
|
select * from dt
|
|
|
where bezdt='decimal'
|
|
|
or bezdt='float'
|
|
|
or bezdt='integer'
|
|
|
or bezdt='number(x,y)'
|
|
|
or bezdt='zahl';
|
|
|
|
|
|
select * from dt_numerisch;
|
|
| bezdt |
bezdbs |
| decimal |
DBS4 |
| float |
DBS7 |
| integer |
DBS4 |
| integer |
DBS8 |
| number(x,y) |
DBS1 |
| zahl |
DBS2 |
| |
|
|
|
9.30 Produzenten von Datenbanksystemen |
|
9.30.1 Aufgabe |
|
Erstellen Sie eine Tabelle mit Datenbanksystemen und ihren Produzenten für die Produzenten, die in Hamburg oder Passau ansässig sind und die RDBS anbieten. Die Tabelle soll die Attribute BezDBS, Typ, PName und Stadt enthalten. |
|
9.30.2 Lösung |
|
Die Lösung erfordert einen Join mit DBS und Produzenten. |
|
|
select a.bezdbs, a.typ, b.pname, b.stadt
|
|
|
from dbs a, produzenten b where a.pname=b.pname and
|
|
|
((b.stadt='Hamburg' or b.stadt='Passau') and a.typ='RDBS')
|
|
|
order by a.pname;
|
|
|
|
|
| bezdbs |
typ |
pname |
stadt |
| DBS2 |
RDBS |
P1 |
Hamburg |
| DBS1 |
RDBS |
P1 |
Hamburg |
| DBS11 |
RDBS |
P5 |
Passau |
| |
9.31 Join mit DBS, Angebot, Haendler |
|
9.31.1 Aufgabe |
|
Die folgende Tabelle („Angebotsüberblick zur Datenbank MarktDBS“) entsteht aus einem Join der Relationen DBS, Angebot und Haendler. Wie lautet der Befehl. Beachten Sie die Sortierung. Wieso fehlt DBS2? |
|
Verbund über DBS, Angebot, Haendler |
|
| DB-Bez |
Listenpreis |
DB-A |
H-A |
Marktpreis |
H-Ort |
| DBS1 |
9500.10 |
DBS1 |
HAE3 |
7100.00 |
Passau |
| DBS11 |
800.90 |
DBS11 |
HAE4 |
500.00 |
Stuttgart |
| DBS3 |
2901.00 |
DBS3 |
HAE3 |
NULL |
Passau |
| DBS4 |
2000.77 |
DBS4 |
HAE2 |
1800.00 |
München |
| DBS5 |
900.66 |
DBS5 |
HAE3 |
NULL |
Passau |
| DBS6 |
1800.55 |
DBS6 |
HAE1 |
1700.50 |
Frankfurt |
| DBS7 |
5000.40 |
DBS7 |
HAE4 |
4500.00 |
Stuttgart |
| DBS8 |
1200.30 |
DBS8 |
HAE2 |
1140.00 |
München |
| DBS8 |
1200.30 |
DBS8 |
HAE5 |
1000.00 |
Ravensburg |
| DBS8 |
1200.30 |
DBS8 |
HAE6 |
1150.00 |
Vilshofen |
| DBS9 |
3000.20 |
DBS9 |
HAE1 |
2200.50 |
Frankfurt |
| DBS9 |
3000.20 |
DBS9 |
HAE2 |
2500.00 |
München |
| DBS9 |
3000.20 |
DBS9 |
HAE4 |
3150.00 |
Stuttgart |
| |
9.31.2 Lösung |
|
|
select dbs.bezdbs as "DB-Bez", dbs.lpreis as Listenpreis,
|
|
|
angebot.bezdbs as "DB-A",
|
|
|
angebot.finame as "H-A",
|
|
|
angebot.mpreis as Marktpreis,
|
|
|
haendler.ort as "H-Ort"
|
|
|
from dbs, angebot, haendler
|
|
|
where dbs.bezdbs=angebot.bezdbs
|
|
|
and angebot.finame=haendler.fname
|
|
|
order by angebot.bezdbs, angebot.finame;
|
|
DBS2 fehlt, weil kein Tupel für dieses Datenbanksystem in Angebot vorliegt. |
|
9.32 5er-Join über MarktDBS |
|
9.32.1 Aufgabe |
|
Erstellen Sie mit Hilfe der Daten von MarktDBS eine Tabelle („Gesamtüberblick zur Datenbank MarktDBS“), die folgende Attribute enthält: |
|
- DB: Bezeichnung des Datenbanksystems
- L-Preis: Listenpreis des Datenbanksystems
- M-Preis: Marktpreis
- Hae: Bezeichnung des Händlers, der das Datenbanksystem auf den Markt bringt
- Prod: Produzent des Datenbanksystems
- TYP: Marktsegment (Typ des Datenbanksystems)
- MaFu: Marktführer im jeweiligen Segment
- Anteil: Anteil des Marktführers am Weltmarkt
|
|
Die Tabelle soll nach den Bezeichnungen der Datenbanksysteme und den Händlern sortiert sein. |
|
9.32.2 Lösung |
|
Für die Lösung ist ein Join über die Relationen dbs, angebot, haendler, produzenten und msegment nötig. |
|
|
select a.bezdbs as "DB", a.lpreis as "L-Preis",
|
|
|
b.mpreis as "M-Preis", c.fname as "Hae" , d.pname as "Prod" ,
|
|
|
e.bez as Typ, e.mafu as "MaFu", e.anteil as Anteil
|
|
|
from dbs a, angebot b, haendler c, produzenten d, msegment e
|
|
|
where a.bezdbs=b.bezdbs
|
|
|
and b.finame=c.fname
|
|
|
and a.pname=d.pname
|
|
|
and rtrim(a.typ)=rtrim(e.bez)
|
|
|
order by a.bezdbs, c.fname;
|
|
|
|
|
| DB |
L-Preis |
M-Preis |
Hae |
Prod |
Typ |
MaFu |
Anteil |
| DBS1 |
9500.10 |
7100.00 |
HAE3 |
P1 |
RDBS |
DBS1 |
20 |
| DBS11 |
800.90 |
500.00 |
HAE4 |
P5 |
RDBS |
DBS1 |
20 |
| DBS3 |
2901.00 |
NULL |
HAE3 |
P2 |
RDBS |
DBS1 |
20 |
| DBS4 |
2000.77 |
1800.00 |
HAE2 |
P4 |
NoSQL |
DBS9 |
65 |
| DBS5 |
900.66 |
NULL |
HAE3 |
P1 |
OODBS |
DBS4 |
15 |
| DBS6 |
1800.55 |
1700.50 |
HAE1 |
P2 |
OODBS |
DBS4 |
15 |
| DBS7 |
5000.40 |
4500.00 |
HAE4 |
P3 |
OODBS |
DBS4 |
15 |
| DBS8 |
1200.30 |
1140.00 |
HAE2 |
P2 |
RDBS |
DBS1 |
20 |
| DBS8 |
1200.30 |
1000.00 |
HAE5 |
P2 |
RDBS |
DBS1 |
20 |
| DBS8 |
1200.30 |
1150.00 |
HAE6 |
P2 |
RDBS |
DBS1 |
20 |
| DBS9 |
3000.20 |
2200.50 |
HAE1 |
P1 |
NoSQL |
DBS9 |
65 |
| DBS9 |
3000.20 |
2500.00 |
HAE2 |
P1 |
NoSQL |
DBS9 |
65 |
| DBS9 |
3000.20 |
3150.00 |
HAE4 |
P1 |
NoSQL |
DBS9 |
65 |
| |
9.33 Preiswertere Datenbanksysteme |
|
9.33.1 Aufgabe |
|
Vorübung mit SelfJoin für die nächste Aufgabe. Grundlage dieser Aufgabe ist wiederum die Relation DBS aus der Datenbank MarktDBS, wie sie in den obigen Aufgaben entstanden ist. Erstellen Sie eine Tabelle, in der jedes Datenbanksystem tupelweise mit allen kombiniert wird, die billiger sind. Aus darstellungstechnischen Gründen konzentrieren wir uns auf relationale Datenbanksysteme (RDBS) und die Attribute BezDBS, Typ und LPreis. |
|
9.33.2 Lösung |
|
|
SELECT a.bezdbs as "DBS a", b.bezdbs as "DBS b", a.typ as Typ, a.lpreis as "Listenpreis a", b.lpreis as "Listenpreis b"
|
|
|
FROM dbs a, dbs b
|
|
|
WHERE a.lpreis > b.lpreis and a.typ='RDBS' order by a.bezdbs, b.bezdbs;
|
|
|
|
|
| DBS a |
DBS b |
Typ |
Listenpreis a |
Listenpreis b |
| DBS1 |
DBS10 |
RDBS |
9500.10 |
600.88 |
| DBS1 |
DBS11 |
RDBS |
9500.10 |
800.90 |
| DBS1 |
DBS2 |
RDBS |
9500.10 |
3000.20 |
| DBS1 |
DBS3 |
RDBS |
9500.10 |
2901.00 |
| DBS1 |
DBS4 |
RDBS |
9500.10 |
2000.77 |
| DBS1 |
DBS5 |
RDBS |
9500.10 |
900.66 |
| DBS1 |
DBS6 |
RDBS |
9500.10 |
1800.55 |
| DBS1 |
DBS7 |
RDBS |
9500.10 |
5000.40 |
| DBS1 |
DBS8 |
RDBS |
9500.10 |
1200.30 |
| DBS1 |
DBS9 |
RDBS |
9500.10 |
3000.20 |
| DBS11 |
DBS10 |
RDBS |
800.90 |
600.88 |
| DBS2 |
DBS10 |
RDBS |
3000.20 |
600.88 |
| DBS2 |
DBS11 |
RDBS |
3000.20 |
800.90 |
| DBS2 |
DBS3 |
RDBS |
3000.20 |
2901.00 |
| DBS2 |
DBS4 |
RDBS |
3000.20 |
2000.77 |
| DBS2 |
DBS5 |
RDBS |
3000.20 |
900.66 |
| DBS2 |
DBS6 |
RDBS |
3000.20 |
1800.55 |
| DBS2 |
DBS8 |
RDBS |
3000.20 |
1200.30 |
| DBS3 |
DBS10 |
RDBS |
2901.00 |
600.88 |
| DBS3 |
DBS11 |
RDBS |
2901.00 |
800.90 |
| DBS3 |
DBS4 |
RDBS |
2901.00 |
2000.77 |
| DBS3 |
DBS5 |
RDBS |
2901.00 |
900.66 |
| DBS3 |
DBS6 |
RDBS |
2901.00 |
1800.55 |
| DBS3 |
DBS8 |
RDBS |
2901.00 |
1200.30 |
| DBS8 |
DBS10 |
RDBS |
1200.30 |
600.88 |
| DBS8 |
DBS11 |
RDBS |
1200.30 |
800.90 |
| DBS8 |
DBS5 |
RDBS |
1200.30 |
900.66 |
| |
9.34 Billiger als der Marktführer |
|
9.34.1 Aufgaben |
|
Grundlage dieser Aufgabe ist wiederum die Datenbank MarktDBS, wie sie in den obigen Aufgaben entstanden ist. Es soll die in der Überschrift genannte Frage beantwortet werden: Welches Datenbanksystem ist billiger als der Marktführer. Die Aufgabe wird mit Hilfe der Relationen DBS und MSegment gelöst. Zur Erinnerung hier nochmals die Relation MSegment (Marktsegment): |
|
|
SELECT * FROM msegment;
|
|
| bez |
mafu |
Anteil |
| NoSQL |
DBS9 |
65 |
| OODBS |
DBS6 |
15 |
| RDBS |
DBS1 |
20 |
| |
Erinnerung: Marktführer ist das Datenbanksystem mit dem höchsten Marktanteil. |
|
Nun die Aufgabe: Erstellen Sie eine Tabelle mit allen Datenbanksystemen, die billiger sind als der Marktführer ihres Marktsegments. |
|
9.34.2 Lösung |
|
Zur Beantwortung dieser Frage sind drei VERBUND-Operationen über dbs a, dbs b und typen c nötig: |
|
|
(1) WHERE a.typ=c.bez
|
|
verknüpft jedes Datenbanksystem mit jedem, das vom selben Typ ist. Damit entstehen Tupel, die Attribute aus a und c verknüpfen. |
|
|
(2) AND c.mafu=b.bezdbs
|
|
verknüpft die oben erhaltenen Tupel mit b (das ja auch DBS ist) dergestalt, dass jeweils die Angaben des Marktführers angehängt werden. |
|
|
(3) AND a.lpreis > b.lpreis
|
|
schränkt nun auf die ein, bei denen der Preis des Systems größers ist als der des Marktführers. Die gesamte Abfrage mit Ergebnistabelle: |
|
|
select a.bezdbs as DBS, a.lpreis as "Preis 1", b.lpreis as "Preis MaFü", c.bez as Marktsegment, c.mafu as Marktführer
|
|
|
from dbs a, dbs b, msegment c
|
|
|
where a.typ=c.bez
|
|
|
and c.mafu=b.bezdbs
|
|
|
and a.lpreis < b.lpreis
|
|
|
order by c.bez;
|
|
Billiger als der Marktführer |
|
| DBS |
Preis 1 |
Preis MaFü |
Marktsegment |
Marktführer |
| DBS4 |
2000.77 |
3000.20 |
NoSQL |
DBS9 |
| DBS5 |
900.66 |
1800.55 |
OODBS |
DBS6 |
| DBS11 |
800.90 |
9500.10 |
RDBS |
DBS1 |
| DBS2 |
3000.20 |
9500.10 |
RDBS |
DBS1 |
| DBS3 |
2901.00 |
9500.10 |
RDBS |
DBS1 |
| DBS8 |
1200.30 |
9500.10 |
RDBS |
DBS1 |
| DBS10 |
600.88 |
9500.10 |
RDBS |
DBS1 |
| |
9.35 Datenbank Lehrbetrieb |
|
9.35.1 Vorbemerkung |
|
Wir richten, ausgehend von einem Datenmodell, eine Datenbank Lehrbetrieb ein. Im Folgenden der Aufbau der Relationen, die hier für die Einzelaufgaben benötigt werden. Es handelt sich um Relationen zu Studierenden (Stud), Veranstaltungen (Veranst) und zum Veranstaltungsbesuch (VBesuch). |
|
Relation Stud |
|
| Name |
Typ |
Null |
| #MNR  |
char(8) |
Nein |
| Name |
varchar(10) |
Ja |
| Vorname |
varchar(10) |
Ja |
| EMail |
varchar(15) |
Ja |
| |
Relation Veranst
|
|
| Name |
Typ |
Null |
| #VNR |
smallint(4) |
Nein |
| Bezv |
varchar(20) |
Ja |
| Typs |
varchar(20) |
Ja |
| Bezs |
varchar(20) |
Ja |
| semplan |
smallint(1) |
Ja |
| |
Anmerkung: Bezv: Bezeichnung Vorlesung; Bezs: Bezeichnung Studiengang |
|
Relation VBesuch |
|
| Name |
Typ |
Null |
| MNR |
char(8) |
Nein |
| VNR |
smallint(4) |
Nein |
| Semester |
varchar(6) |
Nein |
| |
Schlüssel und Fremdschlüssel: #(MNr, VNr, Semester) |
|
9.35.2 Aufgaben |
|
|
a) Richten Sie die Datenbank Lehrbetrieb ein. Geben Sie die Befehle an (in der richtigen Reihenfolge!), mit denen obige Relationen erzeugt werden. Beachten Sie die Schlüssel VNr, MNr, den Schlüssel von VBesuch und die nötigen Fremdschlüssel.
|
|
|
b) Geben Sie die Befehle an, mit denen die folgenden Tupel in die Relation Veranst eingetragen werden.
|
|
Veranst |
|
| VNR |
Bezv |
Typs |
Bezs |
semplan |
| 8011 |
DBS |
NULL |
NULL |
3 |
| 9001 |
Geschäftsprozesse |
Bachelor |
WI und EBUS |
3 |
| 9010 |
Inf und Org |
Bachelor |
WI und EBUS |
1 |
| |
|
c) Die fehlenden Daten zum ersten Tupel (8011, DBS) konnten beschafft werden: TYPS=Bachelor und BEZS=WIPlus. Geben Sie den Befehl an, mit dem sie eingegeben (ergänzt) werden können.
|
|
Veranst
|
|
| VNR |
Bezv |
Typs |
Bezs |
semplan |
| 8011 |
DBS |
Bachelor |
WIPlus |
3 |
| 9001 |
Geschäftsprozesse |
Bachelor |
WI und EBUS |
3 |
| 9010 |
Inf und Org |
Bachelor |
WI und EBUS |
1 |
| |
|
d) Geben Sie die Befehle an, mit denen die folgenden Tupel in die Relation Stud eingegeben werden.
|
|
Stud
|
|
| MNR |
Name |
Vorname |
EMail |
| 2001 |
Feger |
Otto |
ottoATfeger.de |
| 7001 |
Blocher |
Rosi |
rosiATblo-cher.de |
| 7006 |
Klar |
Thomas |
thomasATklar.de |
| 7007 |
Zorro |
Eduard |
ediATzorro.de |
| 7009 |
Grummel |
Alexandra |
alexATgrum-mel.de |
| |
|
e) Die Relation veranst wird um folgende drei Tupel ergänzt. Formulieren Sie die Befehle für diese Eingaben.
|
|
Veranst
|
|
| VNR |
Bezv |
Typs |
Bezs |
semplan |
| 9002 |
DBS I |
Bachelor |
WI und EBus |
2 |
| 9003 |
DBS II |
Bachelor |
WI und E-Bus |
3 |
| 9005 |
GPM |
Master |
WI |
2 |
| |
|
f) Geben Sie die Befehle für die Eingabe der folgenden Tupel in die Relation VBesuch an:
|
|
VBesuch
|
|
| MNR |
VNR |
Semester |
| 2001 |
9005 |
WS2223 |
| 7001 |
9001 |
WS2223 |
| 7001 |
9002 |
WS2223 |
| 7007 |
9001 |
SS23 |
| 7007 |
9002 |
SS23 |
| 7009 |
9001 |
SS23 |
| 7009 |
9002 |
SS23 |
| 7009 |
9010 |
WS2223 |
| |
|
g) Mit welchem Befehl wurde aus obigen drei Relationen die nachfolgende gebildet. Für sie wurden die Daten aller drei Relationen entlang der relationalen Verknüpfungen wieder zusammengefügt.
|
|
Verknüpfte Relationen
|
|
| Name |
E-Mail-Adresse |
KursNr |
VNr |
Bezeichnung LV |
SemPlan |
| Blocher |
rosiATblocher.de |
7001 |
9001 |
Geschäftsprozesse |
3 |
| Blocher |
rosiATblocher.de |
7001 |
9002 |
DBS I |
2 |
| Feger |
ottoATfeger.de |
2001 |
9005 |
GPM |
2 |
| Grummel |
alexATgrummel.de |
7009 |
9001 |
Geschäftsprozesse |
3 |
| Grummel |
alexATgrummel.de |
7009 |
9002 |
DBS I |
2 |
| Grummel |
alexATgrummel.de |
7009 |
9010 |
Inf und Org |
1 |
| Zorro |
ediATzorro.de |
7007 |
9001 |
Geschäftsprozesse |
3 |
| Zorro |
ediATzorro.de |
7007 |
9002 |
DBS I |
2 |
| |
9.35.3 Lösungen |
|
|
a)
|
|
|
create database Lehrbetrieb default character set latin1 collate latin1_german1_ci;
|
|
Die Reihenfolge: zuerst VBesuch, danach die beiden anderen in beliebiger Reihenfolge. Die Befehle: |
|
|
create table veranst (VNR smallint(4), Bezv varchar(20), Typs varchar(20), Bezs varchar(20), semplan smallint(1), primary key(VNR));
|
|
|
create table stud (MNR char(8), Name varchar(10), Vorname varchar(10), EMail varchar(10), primary key (MNR));
|
|
|
create table vbesuch (MNR char(8), VNR smallint(4), Semester varchar(6), primary key(MNR,VNR,Semester), foreign key (mnr) references stud(Mnr), foreign key (vnr) references veranst(vnr));
|
|
|
b)
|
|
|
insert into veranst values(9001,'Geschäftsprozesse','Bachelor','WI und EBUS',3);
|
|
|
insert into veranst values(9010,'Inf und Org','Bachelor','WI und EBUS',1);
|
|
|
insert into veranst (vnr, bezv, semplan) values (8011, 'DBS', 3);
|
|
|
c)
|
|
|
update veranst set typs='Bachelor' where vnr=8011;
|
|
|
update veranst set bezs='WIPlus' where vnr=8011;
|
|
Möglich ist auch: |
|
|
update veranst set typs='Bachelor', bezs='WIPlus' where vnr =8011;
|
|
|
d)
|
|
|
insert into stud values (7007, 'Zorro', 'Eduard', 'ediATzorro.de');
|
|
|
insert into stud values (7006, 'Klar', 'Thomas', 'thomasATklar.de');
|
|
|
insert into stud values (7009, 'Grummel', 'Alexandra', 'alexATgrummel.de');
|
|
|
insert into stud values (7001, 'Blocher', 'Rosi', 'rosiATblocher.de');
|
|
|
insert into stud values (2001, 'Feger', 'Otto', 'ottoATfeger.de');
|
|
|
e)
|
|
|
insert into veranst values (9002, 'DBS I', 'Bachelor', 'WI und EBus', 2);
|
|
|
insert into veranst values (9003, 'DBS II', 'Bachelor', 'WI und EBus', 3);
|
|
|
insert into veranst values (9005, 'GPM', 'Master', 'WI', 2);
|
|
|
f)
|
|
|
insert into vbesuch values (2001, 9005, 'WS2223');
|
|
|
insert into vbesuch values (7001, 9001, 'WS2223');
|
|
|
insert into vbesuch values (7001, 9002, 'WS2223');
|
|
|
insert into vbesuch values (7007, 9001, 'SS23');
|
|
|
insert into vbesuch values (7007, 9002, 'SS23');
|
|
|
insert into vbesuch values (7009, 9001, 'SS23');
|
|
|
insert into vbesuch values (7009, 9002, 'SS23');
|
|
|
insert into vbesuch values (7009, 9010, 'WS2223');
|
|
|
g)
|
|
|
select a.name as Name, a.email as "E-Mail-Adresse", b.mnr as KursNr, b.vnr as VNr, c.bezv as "Bezeichnung LV", c.semplan as SemPlan
|
|
|
from stud a, vbesuch b, veranst c
|
|
|
where a.mnr=b.mnr and b.vnr=c.vnr order by name;
|
|
9.36 Datenbank Kraftfahrzeuge (KFZ) |
|
9.36.1 Datenbank |
|
Folgende Relationen zu Kraftfahrzeugen („AUTOS“) und möglichen Zusatzausstattungen werden für die Aufgaben benötigt: Autos, Zubehoer, Verfuegbarkeit (des Zubehörs für einzelne Autotypen). An den Relationen können Sie erkennen, dass ein Kraftfahrzeug mehrere Zusatzausstattungen haben kann und eine Zusatzausstattung u.U. für mehrere Autos geeignet ist. |
|
- Autos hat die Attribute Bezeichnung (bez char(8)) und Typ (typ char(10)). Der Primärschlüssel ist bez.
- Zubehoer hat die Attribute Inventarnummer (Invnr smallint(4)), Bezeichnung (bez character(20)) und Beschreibung (beschr (varchar(30)). Der Primärschlüssel ist Invnr.
- Verfuegbarkeit hat die Attribute Autobezeichnung (bezAuto char(8)), Inventarnummer (InvNR smallint(4)) und Preis (preis decimal(6,2) sowie den zusammengesetzten Schlüssel (bezauto, invnr).
9.36.2 Aufgaben |
|
|
a) Geben Sie die Befehle an (in der richtigen Reihenfolge!), mit denen obige Relationen erzeugt werden. Beachten Sie die Schlüssel und die nötigen Fremdschlüssel. Denken Sie an die relationale Verknüpfung.
|
|
|
b) Geben Sie in die drei Relationen die folgenden Daten ein. Beachten Sie dabei die Reihenfolge der Relationenbearbeitung.
|
|
Relation autos |
|
| bez |
typ |
| Audi abc |
Limousine |
| Audi xyz |
Sport |
| BMW aaa |
Sport |
| BMW bbb |
Van |
| BMW ccc |
Limousine |
| BMW dd |
Sport |
| VW abc |
Kombi |
| VW bcd |
Limousine |
| VW cde |
SUV |
| |
Relation zubehoer
|
|
| InvNr |
bez |
beschr |
| 1001 |
Spoiler |
Am Heck zu montieren |
| 1002 |
Xenon-Licht |
Spezielle Lichtausstattung |
| 1003 |
Getönte Scheiben |
Zur Verdunkelung |
| |
Relation verfuegbarkeit
|
|
| bezAuto |
InvNr |
preis |
| Audi abc |
1003 |
700.05 |
| Audi xyz |
1002 |
3100.01 |
| BMW aaa |
1001 |
1000.01 |
| BMW bbb |
1001 |
1100.01 |
| BMW bbb |
1002 |
2500.01 |
| VW bcd |
1002 |
1800.01 |
| VW cde |
1001 |
7800.00 |
| |
|
c) Mit welchen Befehlen werden in Verfuegbarkeit die beiden folgenden Tupel eingefügt:
|
|
|
VW bcd 1003 900,01
|
|
|
VW cde 1003
|
|
|
d) Der Preis für das Zubehör mit der InvNr 1003 ändert sich beim Auto „VW cde“ zu 999,99 Euro. Wie lautet der Befehl für diese Datenaktualisierung?
|
|
Damit liegen in der Relation dann folgende Daten vor: |
|
Verfügbarkeit |
|
| bezAuto |
InvNr |
preis |
| Audi abc |
1003 |
700.05 |
| Audi xyz |
1002 |
3100.01 |
| BMW aaa |
1001 |
1000.01 |
| BMW bbb |
1001 |
1100.01 |
| BMW bbb |
1002 |
2500.01 |
| VW bcd |
1002 |
1800.01 |
| VW bcd |
1003 |
900.01 |
| VW cde |
1001 |
7800.00 |
| VW cde |
1003 |
999.99 |
| |
e)
|
|
Mit welchem Befehl wurde aus obigen drei Relationen die nachfolgende gebildet. Für sie wurden Daten aller drei Relationen entlang der relationalen Verknüpfungen zusammengefügt. Benutzen Sie Kurzbezeichnungen (correlation names) für die Relationen. |
|
Verknüpfte Relationen |
|
| bez |
typ |
bez |
beschr |
preis |
| Audi abc |
Limousine |
Getönte Scheiben |
Zur Verdunkelung |
700.05 |
| Audi xyz |
Sport |
Xenon-Licht |
Spezielle Lichtausstattung |
3100.01 |
| BMW aaa |
Sport |
Spoiler |
Am Heck zu montieren |
1000.01 |
| BMW bbb |
Van |
Spoiler |
Am Heck zu montieren |
1100.01 |
| BMW bbb |
Van |
Xenon-Licht |
Spezielle Lichtausstattung |
2500.01 |
| VW bcd |
Limousine |
Xenon-Licht |
Spezielle Lichtausstattung |
1800.01 |
| VW bcd |
Limousine |
Getönte Scheiben |
Zur Verdunkelung |
900.01 |
| VW cde |
SUV |
Spoiler |
Am Heck zu montieren |
7800.00 |
| VW cde |
SUV |
Getönte Scheiben |
Zur Verdunkelung |
999.99 |
| |
f)
|
|
Ergänzen Sie die Relation Autos um ein Attribut LPreis (Listenpreis) mit einem numerischen Datentyp, der 10-stellige Zahlen mit zwei Stellen rechts vom Komma zulässt. |
|
g) |
|
Ergänzen Sie in Autos die Listenpreise, wie es die folgende Relation angibt. |
|
Autos |
|
| bez |
typ |
LPreis |
| Audi abc |
Limousine |
55000.01 |
| Audi xyz |
Sport |
60000.01 |
| BMW aaa |
Sport |
50000.01 |
| BMW bbb |
Van |
60000.01 |
| BMW ccc |
Limousine |
65000.01 |
| BMW dd |
Sport |
67000.01 |
| VW abc |
Kombi |
30000.01 |
| VW bcd |
Limousine |
45000.01 |
| VW cde |
SUV |
52000.01 |
| |
h)
|
|
|
Mit welchem Befehl bestimmen Sie den Durchschnittspreis aller Autos?
|
|
|
Mit welchem Befehl können Sie die Durchschnittspreise für jeden Autotyp bestimmen, so wie es die folgende Abbildung zeigt:
|
|
Durchschnitt der Autotypen |
|
| typ |
Durchschnitt |
| Kombi |
30000.01 |
| Limousine |
55000.01 |
| Sport |
59000.01 |
| SUV |
52000.01 |
| Van |
60000.01 |
| |
i)
|
|
Folgende Tabelle zeigt nur die Autos, deren Preis über dem Durchschnitt aller Autos liegt. Wie lautet der Befehl mit dem diese Tabelle erzeugt wird? |
|
| bez |
typ |
LPreis |
| Audi abc |
Limousine |
55000.01 |
| Audi xyz |
Sport |
60000.01 |
| BMW bbb |
Van |
60000.01 |
| BMW ccc |
Limousine |
65000.01 |
| BMW dd |
Sport |
67000.01 |
| |
j)
|
|
Mit welchem Befehl wird die folgende Tabelle erzeugt? |
|
Kraftfahrzeuge und ihr Zubehör |
|
| KFZ |
Typ |
Zubehör |
Beschreibung Zubehör |
Preis |
| VW cde |
SUV |
Spoiler |
Am Heck zu montieren |
7800.00 |
| VW cde |
SUV |
Getönte Scheiben |
Zur Verdunkelung |
999.99 |
| VW bcd |
Limousine |
Xenon-Licht |
Spezielle Lichtausstattung |
1800.01 |
| VW bcd |
Limousine |
Getönte Scheiben |
Zur Verdunkelung |
900.01 |
| BMW bbb |
Van |
Spoiler |
Am Heck zu montieren |
1100.01 |
| BMW bbb |
Van |
Xenon-Licht |
Spezielle Lichtausstattung |
2500.01 |
| BMW aaa |
Sport |
Spoiler |
Am Heck zu montieren |
1000.01 |
| Audi xyz |
Sport |
Xenon-Licht |
Spezielle Lichtausstattung |
3100.01 |
| Audi abc |
Limousine |
Getönte Scheiben |
Zur Verdunkelung |
700.05 |
| |
9.36.3 Lösungen |
|
|
a)
|
|
|
create table autos (bez char(8), typ char(10), primary key(bez));
|
|
|
create table zubehoer (InvNr smallint(4), bez char(20), beschr varchar(30), primary key(invnr));
|
|
|
create table verfuegbarkeit (bezAuto char(8), InvNr smallint(4), preis decimal(6,2),
|
|
|
primary key (bezAuto, InvNr),
|
|
|
foreign key (bezauto) references autos(bez),
|
|
|
foreign key (invnr) references zubehoer(invnr));
|
|
|
b)
|
|
Verfügbarkeit |
|
|
insert into verfuegbarkeit values ('BMW aaa', 1001, 1000.01);
|
|
|
insert into verfuegbarkeit values ('BMW bbb', 1001, 1100.01);
|
|
|
insert into verfuegbarkeit values ('BMW bbb', 1002, 2500.01);
|
|
|
insert into verfuegbarkeit values ('Audi abc', 1003, 700.05);
|
|
|
insert into verfuegbarkeit values ('Audi xyz', 1002, 3100.01);
|
|
|
insert into verfuegbarkeit values ('VW bcd', 1002, 1800.01);
|
|
|
insert into verfuegbarkeit values ('VW cde', 1001, 7800.00);
|
|
Autos |
|
|
insert into autos values ('BMW aaa', 'Sport');
|
|
|
insert into autos values ('BMW bbb', 'Van');
|
|
|
insert into autos values ('BMW dd', 'Sport');
|
|
|
insert into autos values ('BMW ccc', 'Limousine');
|
|
|
insert into autos values ('Audi xyz', 'Sport');
|
|
|
insert into autos values ('Audi abc', 'Limousine');
|
|
|
insert into autos values ('VW abc', 'Kombi');
|
|
|
insert into autos values ('VW bcd', 'Limousine');
|
|
|
insert into autos values ('VW cde', 'SUV');
|
|
Zubehör |
|
|
insert into zubehoer values (1001, 'Spoiler', 'Am Heck zu montieren');
|
|
|
insert into zubehoer values (1002, 'Xenon-Licht', 'Spezielle Lichtausstattung');
|
|
|
insert into zubehoer values (1003, 'Getönte Scheiben', 'Zur Verdunkelung');
|
|
|
c)
|
|
|
insert into verfuegbarkeit values ('VW bcd', 1003, 900.01);
|
|
|
insert into verfuegbarkeit (bezAuto, InvNr) values ('VW cde', 1003);
|
|
|
d)
|
|
|
update verfuegbarkeit set preis=999.99 where invnr=1003 and bezauto='VW cde' ;
|
|
|
e)
|
|
|
Select a.bez, a.typ, z.bez, z.beschr, v.preis
|
|
|
from autos a, zubehoer z, verfuegbarkeit v
|
|
|
where a.bez=v.bezAuto and
|
|
|
v.InvNr=z.InvNr order by a.bez;
|
|
|
f)
|
|
|
Alter table autos add LPreis decimal(10,2) not null after typ;//“not null after typ“ ist optional
|
|
|
g)
|
|
|
update autos set lpreis=50000.01 where bez='BMW aaa';
|
|
|
update autos set lpreis=60000.01 where bez='BMW bbb';
|
|
|
update autos set lpreis=65000.01 where bez='BMW ccc';
|
|
|
update autos set lpreis=67000.01 where bez='BMW dd';
|
|
|
update autos set lpreis=55000.01 where bez='Audi abc';
|
|
|
update autos set lpreis=60000.01 where bez='Audi xyz';
|
|
|
update autos set lpreis=30000.01 where bez='VW abc';
|
|
|
update autos set lpreis=45000.01 where bez='VW bcd';
|
|
|
update autos set lpreis=52000.01 where bez='VW cde';
|
|
|
h)
|
|
Durchschnittspreis aller Autos: |
|
|
select format(avg(lpreis), 2) from autos;
|
|
Durchnittspreis der Autotypen: |
|
|
select typ, format(avg(lpreis), 2) AS Durchschnitt from autos group by typ;
|
|
|
i)
|
|
|
select * from autos where lpreis > (select avg(lpreis) from autos);
|
|
|
j)
|
|
|
select a.bez as KFZ, a.typ AS Typ, z.bez as "Zubehör", z.beschr as "Beschreibung Zubehör", v.preis as Preis
|
|
|
from autos a, zubehoer z, verfuegbarkeit v
|
|
|
where a.bez=v.bezAuto and z.invnr=v.invnr order by a.bez desc;
|
|

|
|
|
|
|
10 Etwas relationale Theorie |
|
Für eine umfassende Einführung in die relationale Modellierung vgl. [Staud 2021]: |
|
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen (2. Auflage). Hamburg 2021 (tredition) |
|
Auszüge finden sich auf http://www.staud.info/rm1/rm_t_1.htm |
|
Dieses Kapitel soll a) wichtige Aspekte der relationalen Datenmodellierung zusammenfassend darstellen und b) mit den textlichen und grafischen Notationen dieses Textes vertraut machen. |
|
|
|
10.1 Vorgehensweise |
|
Grundlage der relationalen Datenmodellierung ist, dass die zu erfassende Semantik des Anwendungsbereichs auf attributbasierte Tabellen (Relationen) abgebildet wird. Vgl. [Staud 2021] bzw. www.staud.info/rm1/rm_t_1.htm für eine umfassende Einführung. |
Attribute |
Alles ist attributbasiert, die Aufteilung auf einzelne optimierte Relationen (Tabellen) und die Verknüpfung dieser Relationen durch Schlüssel-/Fremdschlüsselbeziehungen (relationale Verknüpfungen). |
|
Die relationalen Verknüpfungen werden durch Kardinalitäten und Min-/Max-Angaben beschrieben. Kardinalitäten erfassen, wieviele Elemente (Tupel) der einen mit Elementen der anderen Relation zu verknüpfen sind. Z.B. 1:1, 1:n, 1:m. Die Angaben n und m stehen für ganzzahlige Werte größer Null. Min-/Max-Angaben beschreiben die Verknüpfungen vertiefter. Vgl. Abschnitt 2.3. |
Verknüpfungen |
Im Folgenden werden, wenn nicht anderweitig angegeben, die Begriffe Objekte und Beziehungen im umgangssprachlichen Sinn verwendet, also nicht im „strengeren Sinn“ der objektorientierten Theorie. |
|
Bei der ersten Konfrontation mit dem Anwendungsbereich und der Anforderungsbeschreibung müssen die für die spätere Datenbank notwendigen Attribute abgeleitet bzw. festgelegt werden. Ist dies geschehen, müssen folgende Aufgaben gelöst werden, um ein relationales Datenmodell zu erstellen: |
Aufgaben |
|
(1) Relationen suchen und festlegen. Alles (alle Realweltphänomene, Objekte, Entitäten, …), was identifiziert UND beschrieben wird, wird (erstmal) zu einer Relation. Konkret sucht man nach Realweltphänomenen (hier schlicht: alles was durch Attribute beschrieben wird), die a) durch ein Attribut (oder mehrere) identifiziert und b) durch ein Attribut oder mehrere darüberhinaus beschrieben werden. Dies sind im Datenbankkontext entweder Objekte oder Beziehungen zwischen diesen. Aus diesen Attributen entstehen die ersten Entwürfe für Relationen. Beispiel: Angestellte mit #PersNr und Name, Vorname. Projektmitarbeit mit #(PersNr, ProjBez), Beginn, Rolle. Bei jeder solchen Zusammenstellung zu Relationen ist sicherzustellen, dass für jeweils eine Ausprägung des Schlüssels genau eine Ausprägung bei jedem Nichtschlüsselattribut vorhanden ist. Denn: Ein Attribut hat in relationalen Datenbanken pro Objekt nur genau eine Ausprägung.
|
|
|
(2) Sicherstellen, dass die für eine Relation ausgewählten Attribute wirklich alle Objekte oder Beziehungen der Relation beschreiben. D.h.: Das Attribut muss auf alle anwendbar sein, so dass keine semantisch bedingten Leereinträge (vgl. [Staud 2021, S. 183f]) auftreten. Beispiel: ProgrSpr (beherrschte Programmiersprache) in einer Datenbank zu Angestellten, in der auch Nicht-Programmierer erfasst sind.
|
|
|
(3) Gefundene Relationen hinsichtlich der 1NF präzisieren, d.h. Mehrfacheinträge beseitigen und neue Relationen anlegen. Dabei entstehen die ersten Beziehungen (Schlüssel-/Fremdschlüssel-Beziehungen). Wegweisend ist hierfür die grundsätzliche Regel: Alle Relationen sind (zumindest lose)::i::Lose Verknüpfung::j:: miteinander verknüpft. Diese bedeutet nicht, dass jede Relation mit allen anderen direkt verbunden ist, sondern, dass jede Relation mit dem Gesamtmodell verknüpft sein muss.
|
|
|
(4) Gefundene Relationen hinsichtlich der weiteren Normalformen präzisieren. Dabei entstehen i.d.R. weitere Schlüssel-/Fremdschlüssel-Beziehungen. Die Zerlegungen im Rahmen der Normalisierung dürfen zu keinem Informationsverlust führen. D.h., es ist immer darauf zu achten, dass durch relationale Verknüpfungen entlang von Schlüsseln und Fremdschlüsseln die in der Ausgangsrelation vorhandene Information erhalten bleibt.
|
|
|
(5) Weitere Beziehungen klären und im Datenmodell anlegen. Dies betrifft semantisch begründete Beziehungen, die sich nicht direkt aus der Attributkonstellation oder der Methode ergeben.
|
|
|
(6) Muster Generalisierung / Spezialisierung (Gen/Spez) erkennen und anlegen.
|
|
|
(7) Weitere Muster (Einzel/Typ, Aggregation, Komposition) abklären und anlegen.
|
|
|
(8) Zeitliche Aspekte klären und modellieren, auch die in der Anforderung vergessenen.
|
|
10.2 Ergebnis der Datenmodellierung |
|
Vgl. [Staud 2021, Abschnitt 13.3] und www.staud.info/rm1/rm_t_1.htm#Abschnitt14.3 |
|
Das fertige Datenmodell sollte folgenden Bedingungen genügen: |
|
- Jede Relation muss in 5NF sein. Dafür genügt ein Herbeiführen der 3NF und ein Prüfen, ob die BCNF erfüllt ist und ob keine mehrfachen mehrwertigen Attribute (wegen 4NF) oder fehlerhafte Verbundabhängigkeiten (wegen 5NF) vorliegen.
- In jeder Relation sind nur Attribute, die für alle Objekte Gültigkeit haben. Dies ergibt sich auch aus den Normalformen, soll aber nochmals deutlich gemacht werden. Es darf also keine semantisch bedingten Leereinträge geben. Ausnahmen sind Attribute zum Anfang und Ende von Zeitabschnitten.
- Normalerweise gibt es keine unterschiedlichen Relationen mit identischem Schlüssel. Ausnahmen sind Relationen im Rahmen einer Generalisierung / Spezialisierung.
|
|
Wird dies alles realisiert, ist auch eine zentrale Regel des Datenbankentwurfs zur Vermeidung von Redundanz umgesetzt: |
|
Jede (hier ja immer attributbasierte) Information darf in einer Datenbank nur einmal vorkommen. |
|
Da wir in den SQL-Datenbanken [Anmerkung] nur Attributsausprägungen von Objekten und Beziehungen abspeichern, ist die präzisere Formulierung folgende: Jede Attributsausprägung, die ein Objekt oder eine Beziehung beschreibt, darf in einer Datenbanken nur einmal erfasst werden. Klassisches Gegenbeispiel: Kunden, die mit alten und früheren Adressen in der Datenbank erfasst sind. |
Etwas genauer |
10.3 Methodische Muster – Methode sucht Syntax |
|
Vgl. Kapitel 5 in [Staud 2021] und www.staud.info/rm1/rm_t_1.htm#Kapitel6 |
|
Methodische Muster ergeben sich aus der relationalen Theorie. Daraus, wie mit Hilfe der relationalen Theorie die Semantik des Anwendungsbereichs in Datenmodelle umgesetzt wird. Im Zentrum stehen dabei die Zerlegungen und Verknüpfungen von Relationen, die aufgrund der Relationenstruktur notwendig sind. Hier ist zentral: |
|
- Es gibt in einer Relation keine mehrwertigen Einträge (Mehrfacheinträge). D.h., ein Attribut hat pro Objekt nur genau eine Ausprägung. Dies realisiert die 1NF.
- Die Relationen müssen entsprechend den weiteren Normalformen gestaltet werden. Vgl. die Kapitel 7, 9-13 in [Staud 2021].
|
|
Daraus ergeben sich Zerlegungen mit nachfolgendem Verknüpfungsbedarf (1:1, 1:n, n:m). |
|
Hinweis: Die nachfolgenden Modellfragmente eignen sich auch sehr gut als Lesehilfen für die im Aufgabenteil vorgestellten relationalen Datenmodelle. |
|
10.3.1 Kardinalität 1:1 |
|
Mehr dazu in [Staud 2021, Abschnitt 5.3] und www.staud.info/rm1/rm_t_1.htm#Kapitel6 |
|
Ist die Semantik so, dass ein Element der einen Relation mit einem der anderen verknüpft ist, dann liegt die Kardinalität 1:1 vor. Als Beispiel können aus einer Personaldatenbank die Relationen Angestellte und PC genommen werden, wenn durch die Semantik festgelegt ist, dass jeder Mitarbeiter nur einen PC zugewiesen bekommt und jeder PC von nur einem Mitarbeiter genutzt wird. |
Eine/r zu Einer/m |
Auch hier kann durch die Min-/Max-Angaben präzisiert werden: |
|
- 1,1 : 1,1 bedeutet, dass jedes Tupel der einen Relation mit genau einem der anderen verknüpft wird und umgekehrt (Angestellte – Adressen).
|
|
Im Beispiel: Ein Angestellter bekommt genau einen PC zugewiesen und jeder PC ist nur einem Angestellten zugeordnet. |
|
Die relationale Theorie lässt dafür zwei Lösungen zu, die in der folgenden Abbildung angegeben sind. Eine der beiden Relationen „liefert“ ihren Schlüssel als Fremdschlüssel in die andere. Damit ist die Semantik und die Verknüpfung korrekt in der Datenbank verankert. Hier die grafische Darstellung. |
|
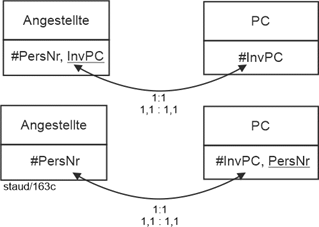
|
|
Abbildung 10.3-1: Kardinalität 1:1 mit Min-/Max-Angaben 1,1 : 1,1 |
|
Nun die weiteren Varianten: |
|
- 1,1 : 0,1 oder 0,1 : 1,1 bedeutet, dass von der Relation mit dem optionalen Attribut (Minimum 0) der Schlüssel als Fremdschlüssel in die andere Relation kommt.
|
|
Im Beispiel: Falls nicht jeder PC einen Angestellten zugewiesen bekommt, wird InvPC zum Fremdschlüssel in Angestellte. Falls nicht jeder Angestellte einen PC hat, wird PersNr zum Fremdschlüssel in PC. Vgl. die folgende Abbildung für die grafische Realisierung. |
|
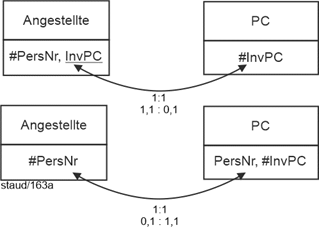
|
|
Abbildung 10.3-2: Kardinalität 1:1 mit Min-/Max-Angaben 0,1 : 1,1 oder 1,1 : 0,1 |
|
Die letzte Variante: |
|
- 0,1 : 0,1 bedeutet, dass in beiden Relationen die Teilnahme an der Beziehung optional ist. Die relationale Theorie verlangt dafür die Einrichtung einer eigenen Relation mit einem aus den Schlüsseln der beiden Relationen bestehenden Schlüssel.
|
|
Im Beispiel: Die neue Relation AngPC (Angestellte/PC) erhält den Schlüssel #(PersNr, InvPC). Jeder Fremdschlüssel stellt die Verbindung zu der Relation her, in der er Schlüssel ist. Vgl. die folgende Abbildung für die grafische Realisierung. |
|
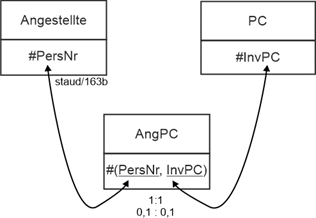
|
|
Abbildung 10.3-3: Kardinalität 1:1 mit Min-/Max-Angaben 0,1 : 0,1 |
|
10.3.2 Kardinalität 1:n |
|
Mehr dazu in [Staud 2021, Abschnitt 5.5] und www.staud.info/rm1/rm_t_1.htm#Abschnitt6.5 |
|
Oftmals ist ein Element der einen Relation mit mehreren Elementen einer anderen Relation semantisch verbunden. Dies ist eine Beziehung mit Kardinalität 1:n (1:n-Beziehung). In diesem Fall wird i.d.R. der Schlüssel der einen Relation als Fremdschlüssel in die andere genommen und zwar so, dass keine Mehrfacheinträge entstehen. Ein Beispiel ist die Beziehung zwischen Rechnungsköpfen (RechKöpfe) und Kunden. |
Eine/r zu Vielen |
|
|
Abbildung 10.3-4: Kardinalität 1:n |
|
RechKöpfe: Rechnungsköpfe; ReNr: Rechnungsnummer; KuNr: Kundennummer |
|
Lesehinweis: Die Kardinalitäten und Min-/Max-Angaben werden immer für eine bestimmte Richtung angegeben. Diese ist entweder textlich (hier oben für Kunden => RechKöpfe 1:n bzw. 1,n : 1,1) oder durch die Grafik präzisiert. In der obigen Grafik gilt also: Ein Kunde kann mehrere Rechnungsköpfe verursacht haben, ein Rechnungskopf gehört zu einem Kunden, usw. |
|
Auch hier gibt es wieder Varianten durch Min-/Max-Angaben (Richtung Kunden – Rechnungsköpfe): |
|
1,1 : 1,n (Pflichtteilnahmen) |
|
Dies bedeutet, dass alle Elemente der einen und auch alle der anderen Relation an der Beziehung teilhaben müssen. Diese Situation liegt im obigen Beispiel vor. Textliche Notation am obigen Beispiel: Kunden (#KuNr, …) und RechKöpfe (#ReNr, KuNr, …) |
|
0,1 : 1,n (optional bzw. Pflicht) |
|
Dies bedeutet, dass in der Relation ohne Fremdschlüssel (oben: Kunden) auch Einträge ohne Verknüpfung vorliegen können. Im obigen Beispiel gäbe es also „Kunden ohne Rechnungsköpfe“. Für die Relation mit Fremdschlüssel gilt weiterhin, dass alle Einträge verknüpft sein müssen (im Beispiel: zu allen Rechnungsköpfen gehören Kundennummern). |
|
1,1 : 0,m (Pflicht bzw. optional) |
|
Dies bedeutet, dass in der Relation mit dem Fremdschlüssel auch keine Verknüpfung vorhanden sein kann. Dann wäre ein Fremdschlüssel nicht „befüllt“. Dies verbietet die relationale Theorie, weshalb eine eigene Relation angelegt werden muss. Im obigen Beispiel: |
|
Kunden (#KuNr, …) |
|
RechKöpfe (#ReNr, …) |
|
RechnungenKunden (#ReNr, KuNr, …) |
|
0,1 : 0,m |
Alles optional |
Dies bedeutet, dass auf beiden Seiten auch mal keine Verknüpfung vorliegen muss. Wieder besteht die Lösung aus einer zusätzlichen Relation, diesmal allerdings mit leicht verändertem Aufbau: |
|
Kunden (#KuNr, …) |
|
RechKöpfe (#ReNr, …) |
|
RechnungenKunden (#(ReNr, KuNr), …) |
|
10.3.3 Kardinalität n:m |
|
Mehr dazu in [Staud 2021, Abschnitt 5.6] und /www.staud.info/rm1/rm_t_1.htm#Abschnitt6.6 |
|
Liegen zwei Relationen vor und sagt die Semantik, dass ein Element der einen Relation mit mehreren der anderen verknüpft sein kann und umgekehrt, dann spricht man von einer n:m-Beziehung, bzw. von einer Kardinalität n:m. In einem solchen Fall wird eine eigene Relation (Verbindungsrelation) für die Verknüpfung eingerichtet, in der die Schlüssel der zu verknüpfenden Relationen zusammen den Schlüssel ausmachen. Ein Beispiel ist die Beziehung zwischen Kunden und Adressen, falls unter einer Adresse auch mehrere Kunden wohnen können. |
Viele zu Vielen |
Die folgende Abbildung zeigt die grafische Darstellung eines solchen Modellfragments: |
|
|
Adressen – KuAdr - Kunden |
Abbildung 10.3-5: Kardinalität n:m mit allen möglichen Min-/Max-Angaben |
|
KuAdr: Kunden/Adressen |
|
AdrNr: Adressnummer; KuNr: Kundennummer |
|
Die Kardinalität n:m bedeutet hier also: eine Adresse kann keinem, einem oder mehreren Kunden zugeordnet sein. Ein Kunde kann mit keiner, einer oder mehreren Adressen verknüpft sein. In der Abbildung sind auch alle möglichen Varianten durch Min-/Max-Angaben angegeben: |
|
- 1,n : 1,m bedeutet, dass alle Objekte beider Relationen an der Beziehung teilhaben müssen. Es liegen also Pflichtangaben vor und später in der Maske Pflichtfelder.
- 1,m : 0,n bzw. 0,m : 1,n bedeutet, dass die Objekte auf einer Seite nicht an der Beziehung teilhaben müssen (optionale Beziehung).
- 0,n : 0,m bedeutet, dass beide Seiten nicht an der Beziehung teilhaben müssen.
|
|
Die modelltechnische Lösung bleibt in allen Fällen gleich, allerdings muss beim späteren Einrichten der Datenbank (insbesondere bei der Maskengestaltung) auf die Thematik Pflichtfeld/optionales Feld geachtet werden. |
|
Im obigen Beispiel mit der Richtung Adressen – Kunden: |
|
- Die Min-/Max-Angaben von 1,n : 1,m bedeuten: Eine Adresse ist mindestens einem Kunden zugeordnet. Ein Kunde hat mindestens eine Adresse (in der Datenbank).
- Variante 1,m : 0,n: Eine Adresse ist mindestens einem Kunden zugeordnet. Ein Kunde in der Datenbank kann auch keine Adressangaben haben.
- Variante: 0,m : 0,m bedeutet: Eine Adresse ist keinem, einem oder mehreren Kunden zugeordnet. Ein Kunde ist mit keiner, einer oder mehreren Adressen erfasst. Es gäbe also Adressen ohne Kunden und Kunden ohne Adressangaben.
|
|
Lesehinweis: Bei Verbindungsrelationen (Relationen zur Verknüpfung anderer) werden die Kardinalitäten und Min-/Max-Angaben für alle drei verknüpften Relationen angegeben und grafisch unter der Verbindungsrelation angeordnet. |
|
10.4 Semantische Muster – Semantik sucht Syntax |
|
Mehr dazu in [Staud 2021, Kapitel 14] sowie /www.staud.info/rm1/rm_t_1.htm#Kapitel15 |
|
10.4.1 Muster Einzel/Typ |
|
Wir tun es jeden Tag, wir typisieren indem wir abstrahieren. Aus den vielen Kraftfahrzeugen, die wir sehen, werden Automobile, Lastwagen, Sportwagen, usw. Aus den einzelnen Tieren im Zoo (die vielleicht sogar Namen erhalten), machen wir Gorillas, Schimpansen, Giraffen, Elefanten, usw. Im ersten Schritt machen wir dabei aus Individuen (einzelnen Elementen) zusammenfassende Typen. Einige Beispiele: |
Von Individuen zu Gruppen / Kategorien |
- In der Technik wird in bestimmten Situationen das einzelne Stück erfasst (einzelne Kraftfahrzeuge, Festplatten, Flugzeugersatzteile, ...), zum anderen auch die gleichartigen Gruppen (Kraftfahrzeuge, Festplatten, Flugzeugersatzteile eines Typs, ...). Vgl. Abbildung 14.2-2 in [Staud 2021].
- In einem Zoo werden evtl. die einzelnen Tiere (Schimpanse Eddi, Orang Utan Franz, Elefant Paul, ...) durch Attribute benannt und erfasst, zum anderen auch die Gattungen (Schimpansen, Orang Utans, Elefant der Gattung, ...). Natürlich nur für Großtiere, die für uns Menschen als Individuen in Erscheinung treten. Vgl. Abbildung 14.2-1 in [Staud 2021].
- Bei Menschen wird oftmals der einzelne Mensch erfasst (mit Personalnummern, Namen, usw.) und auch die Gruppe, zu der er gehört (Mitarbeiter IT, Leiharbeiter, Leitendes Management, ...).
|
|
Solche Typisierungen können auch mehrstufig sein (z.B. als Klassifikationen), in diesem Kontext (relationale Datenmodellierung) genügt meist allerdings der erste Schritt vom Einzelnen zu den Typen. |
Mehrstufig |
Liegen in einem Anwendungsbereich solche Einzel- und Typ-Informationen zu bestimmten Realweltphänomenen vor, wird dies Muster Einzel/Typ genannt. Dies muss dann in der Datenmodellierung berücksichtigt werden. Relationen auf Einzel-Ebene haben andere Attribute als Relationen auf Typ-Ebene und beide Ebenen müssen auch verknüpft werden. Dies wird im Folgenden in zahlreichen Aufgaben sehr deutlich werden. |
|
Betrachten wir das Beispiel aus dem Beispiel zum Anwendungsbereich Zoo. Hier werden für „größere Tiere“ (also z.B. keine Insekten) in der Anforderungsbeschreibung ein Name (Schimpanse Carlo), eine identifizierende Tiernummer (als Schlüssel) und weitere beschreibende Attribute angenommen. Dies führt z.B. zu folgender Relation: |
Beispiel „Zoo“ |
Tiere (#TNr, Name, Gattung, GebTag, Geschlecht) |
|
Das Attribut Gattung deutet auf die Typisierung, die Typ-Ebene. Hier könnten grob („Säugetiere, Reptilien, Fische, …“) oder wohl eher feiner („Schimpanse, Gorilla, Elefanten, …“) die Tiere bestimmten Gattungen zugeordnet werden. Dies ist dann erstmal ein Attribut der Relation Tiere. So weit so gut. Nun kommt aber z.B. in der Anforderungsbeschreibung ein Text wie dieser: |
|
„Für jede Gattung wird auch festgehalten, wieviele Tiere davon im Zoo vorhanden sind (z.B. 5 Afrikanische Elefanten oder 20 Schimpansen) (Anzahl) und wie ihr Durchschnittsalter (DuAlter) ist.“ |
|
Er macht deutlich, dass jetzt die einzelnen Gattungen mit Hilfe der beiden Attribute beschrieben werden. Für diese muss damit eine eigene Relation angelegt werden. Legen wir BezGatt (Gattungsbezeichnung) als Schlüssel fest und fügen Anzahl sowie Durchschnittliches Alter (DuAlter) als beschreibende Attribute hinzu, erhalten wir: |
|
Tiere-Gattung (#BezGatt, Anzahl, DuAlter) |
|
Der Klarheit wegen nennen wir das Attribut Gattung von Tiere um in BezGatt und die Relation Tiere in Tiere-Einzeln und erhalten: |
|
Tiere-Einzeln (#TNr, Name, BezGatt, GebTag, Geschlecht) |
|
Das Attribut BezGatt realisiert, als Schlüssel und Fremdschlüssel, die relationale Verknüpfung zwischen den beiden Relationen und hält somit fest, zu welcher Gattung ein einzelnes Tier gehört. Die Kardinalitäten und Min-/Max-Angaben sind von Tiere-Einzeln zu Tiere-Gattung wie folgt: n:1 bzw. 1,1 : 1,m. |
|
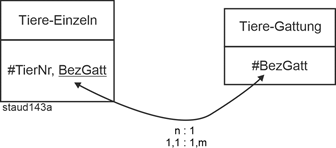
|
|
Abbildung 10.4-1: Muster Einzel/Typ in grafischer Notation |
|
Dieses Muster Einzel/Typ kommt in so gut wie jedem Anwendungsbereich vor und wird trotzdem häufig übersehen. In den nachfolgenden Aufgaben ist es in vielen Ausprägungen vertreten. |
|
10.4.2 Muster Generalisierung / Spezialisierung |
|
Mehr dazu in [Staud 2021, Abschnitt 14.1] und www.staud.info/rm1/rm_t_1.htm#Kapitel15 |
|
Eine in der attributbasierten Modellierung häufig vorkommende Situation ist die Folgende: In der Menge der zu beschreibenden Objekte gibt es neben denen, die Attribute gemeinsam haben auch solche, die zusätzlich eigene, spezifische Attribute haben. In einem solchen Fall spricht man von einer Generalisierung / Spezialisierung. Nehmen wir als Beispiel ein Fragment aus dem Datenmodell Obst (Aufgabe 3.3). Hier werden für die Lieferanten zahlreiche Attribute gefunden. Die gemeinsamen kommen in die Relation Lieferanten, die für Landwirte und Großhändler spezifischen in eigene Relationen. Die Relationen Landwirte und Großhändler sind dann Spezialisierungen von Lieferanten, die Relaton Lieferanten ist eine Generalisierung der beiden anderen. So wird dies in der relationalen Modellierung erfasst: |
|
Landwirte (#LiefNr, Name, Vorname, Typ) |
|
Großhändler (#LiefNr, FName, Land, Fax) |
|
Lieferanten (#LiefNr, Typ, ZV, AbrArt, PLZ, Ort, Straße, E-Mail, Tel) |
|
Die grafische Darstellung ist wie folgt: |
|
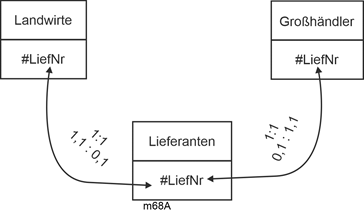
|
|
Abbildung 10.4-2: Generalisierung / Spezialisierung in grafischer Notation |
|
Die Spezialisierungen (hier Landwirte und Großhändler) stehen mit Hilfe des Schlüssels (der in allen Fällen gleich ist) mit der Generalisierung in folgender Verbindung: |
|
- Kardinalität 1:1
- Min-/Max-Angaben (von der Generalisierung ausgehend): 0,1 : 1,1. Denn nicht jeder Lieferant ist Landwirt bzw. Großhändler („0,1“) und jeder Landwirt/Großhändler ist Lieferant („1,1“).
|
|
Wer die objektorientierte Theorie kennt, dem kommt dies sicherlich bekannt vor. Dort umfasst es auch Methoden und führte zum Konzept der Vererbung. In obigem Beispiel: Landwirte bzw. Großhändler erben die Attribute von Lieferanten. |
Vererbung |
10.4.3 Aggregation |
|
Mehr dazu in [Staud 2021, Abschnitt 14.3] sowie www.staud.info/rm2/rm_f_15.htm |
|
Die nächsten zwei Muster, Aggregation und Komposition, drücken Enthaltensein aus. Im Falle der Aggregation können die „enthaltenen“ Objekte auch alleine existieren, im Falle der Komposition nicht. |
Enthaltensein |
Beginnen wir mit der Aggregation. Wie wird sie in der relationalen Modellierung realisiert? Dies geschieht, indem die hinzuzufügende Komponente mit dem Schlüssel der Hauptkomponenten ausgestattet wird, der dort Fremdschlüssel ist. |
|
Betrachten wir als Beispiel Personal Computer (PC) und Komponenten (externe Festplatten, DVD-Laufwerke, …). Solche Komponenten haben die Eigenschaft, dass sie datenbanktechnisch und auch sonst ohne einen bestimmten PC existieren können. Sie können z.B. vom einen zum anderen PC wechseln. Dies sollte im Datenmodell ausgedrückt werden, indem die Verknüpfung entsprechend gestaltet wird. Die Kardinalität sei immer 1:n, die Min-/Max-Angaben können variieren. Zuerst der Fall (von PC ausgehend): 0,n : 1,1 oder 1,n : 1,1. Dabei ergibt sich das nachfolgende Modellfragment. |
|
Textlich : |
|
PC (#InvNrPC, Proz, ArbSp) |
|
Komponenten (#InvNrKomp, Bez, Funktion, InvNrPC) |
|
Grafisch : |
|
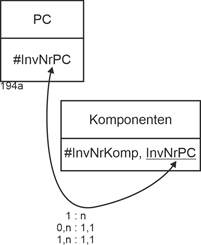
|
|
Abbildung 10.4-3: Muster Aggregation mit Pflichtteilhabe |
|
InvNr: Inventarnummer |
|
PC: Personal Computer |
|
Bez: Bezeichnung |
|
Proz: Prozessor |
|
ArbSp: Arbeitsspeicher |
|
Komp: Komponente |
|
Im obigen Fall muss die Komponente zu jedem Zeitpunkt (irgend einem) einem PC zugewiesen sein. Für den Fall, dass die Verknüpfung optional gehalten werden soll, muss für die Verknüpfung eine eigene Relation PCKomp eingerichtet werden. Dann ergeben sich folgende Relationen und die Min-/Max-Angaben (von PC über PCKomp zu Komponenten) 0,n : 0,1. |
|
PC (#InvNrPC, Proz, ArbSp) |
|
Komponenten (#InvNrKomp, Bez, Funktion) |
|
PCKomp (#InvNrKomp, InvNrPC) |
|
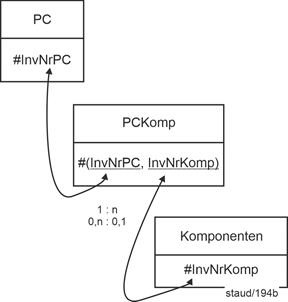
|
|
Abbildung 10.4-4: Muster Aggregation mit optionaler Teilhabe |
|
10.4.4 Komposition |
|
Mehr dazu in [Staud 2021, Abschnitt 14.4] und www.staud.info/rm1/rm_t_1.htm#Abschnitt15.4 |
|
Manchmal verlangt die Semantik eine besonders enge Verknüpfung in Form einer umfassenden Existenzabhängigkeit (in der objektorientierten Theorie Komposition genannt). Eine solche Semantik sollte im Datenmodell ausgedrückt werden. In relationalen Datenbanken geschieht dies wie folgt: |
Existenzabhängigkeit |
Der Schlüssel der „unabhängigen“ Relation wird zu einem Teil des Schlüssels der „abhängigen“ Relation. Durch die Einbindung in den Schlüssel kann es dann dort kein Tupel ohne Verweis auf die andere Relation geben. Die Min-/Max-Angaben müssen dann auf der abhängigen Seite 1,1 sein. Dadurch wird a) die Verknüpfung gesichert und b) garantiert, dass es keine Mehrwertigkeit gibt. |
|
Ein Beispiel mit Kardinalität 1:n ist die Verknüpfung von Rechnungsköpfen (RechKöpfe) und Rechnungspositionen (RechPos). Rechnungspositionen kann es nicht ohne zugehörige Rechnungsköpfe geben. Die Lösung sieht hier wie folgt aus: |
|
RechKöpfe (#ReNr, …) |
|
RechPos (#(ReNr, PosNr), …) |
|
ReNr in RechPos ist Fremdschlüssel und leistet die Verknüpfung mit RechKöpfe. Damit ist die Kardinalität 1:n festgelegt: Ein Wert von ReNr in RechKöpfe kommt mindestens einmal im Schlüssel von RechPos vor. Ein Wert von ReNr in RechPos kommt genau einmal in ReNr von RechKöpfe vor. Dies drücken dann auch die Min-/Max-Angaben 1,1 : 1,n aus. |
|
Die Existenzabhängigkeit drückt sich darin aus, dass jede Rechnungsposition den Verweis auf einen Rechnungskopf benötigt, weil die ReNr Teil des Schlüssels von RechPos ist und nach der relationalen Theorie ein Schlüssel (natürlich) immer vollständig sein muss. Umgekehrt gilt: Wird ein bestimmter Rechnungskopf gelöscht, müssen auch die existenzabhängigen Rechnungspositionen gelöscht werden. Falls nicht, entsteht ein Beitrag zu sog. Stammdatenkrise. |
|
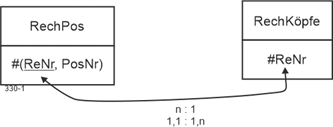
|
|
Abbildung 10.4-5: Existenzabhängigkeit (Komposition) in relationalen Datenmodellen |
|
RechKöpfe: Rechnungsköpfe |
|
RechPos: Rechnungspositionen |
|
PosNr: Positionsnummer |
|
|
|
11 Etwas HTML |
|
Hier sollen einige HTML-Komponenten, die in den Programmen von Kapitel 4 benötigt werden und deren Kenntnis nicht grundsätzlich vorausgesetzt werden kann, erläutert werden. |
|
|
|
11.1 Formulare |
|
In den PHP-Programmen von Kapitel 4 kommen sehr oft HTML-Formulare zum Einsatz. Deshalb sollen sie hier kurz wiederholt werden. Für eine vertiefte Betrachtung bzw. Wiederholung vgl. [Wolf 2021, Kapital 7]. |
|
Ein Beispiel aus den Programmen von Kapitel 4: |
|
|
<form action="KiGaTabelle.php" method="post">
|
|
|
<p><input type="submit" value="Los geht's">
|
|
|
</form>
|
|
Obiges gehört zum Button „Daten aller Kinder anzeigen“ in Abschnitt 4.1 |
|
Am Anfang der Definition eines Formulars steht <form, am Ende </form>. Action und method sind Attribute von HTML-Formularen. |
|
Dem Attribut action wird die URL zugewiesen, die aufgerufen wird, wenn das Formular abgesendet wird. An diese werden die eingegebenen Daten übertragen. Im obigen Beispiel wird mit einem lokalen Server gearbeitet und mit action die Ausführung eines lokal vorliegenden PHP-Programms angefordert (vgl. unten). |
action |
Das Attribut method legt fest, wie die Daten von der Webseite an den Server übermittelt werden. In den Beispielen hier wird immer die HTTP-Request-Methode post verwendet, die für umfangreichere Datenmengen geeignet ist. Vgl. zur technischen Realisierung [Wolf 2021, S. 241 sowie Abschnitt 7.6.2]. |
method |
Innerhalb eines Formulars können zahlreiche Eingabefelder angelegt werden. In der zweiten Zeile oben steht das erste Beispiel. Der input type submit führt zu einer Schaltfläche (button), die das Absenden des Formulars auslöst. Mit value=“Los geht’s“ wird die Beschriftung der Schaltfläche festgelegt. |
Input types |
Wir benötigen von den vielen zur Verfügung stehenden input types hier nur folgende: |
|
- Input type=“text“
- input type=“radio“
- input type=“submit“
- input type=“reset“
|
|
Ein weiteres Beispiel (vgl. Abschnitt 2.6.1, Programm KiGaNeueintrag): |
|
|
<form action="KiGaneueintrag.php" method="post">
|
|
|
<p><input type="text" name="id"> KindID</p>
|
|
|
<p><input type="text" name="na"> Name</p>
|
|
|
<p><input type="text" name="vn"> Vorname</p>
|
|
|
<p><input name="ad"> AdressID (eine ganze Zahl, 1 - 10)</p>
|
|
|
<p><input name="ei"> Eintrittsdatum (in T.M.JJJJ)</p>
|
|
|
<p><input name="gt"> Geburtstag (in T.M.JJJJ)
|
|
|
<p><input name="gk"> Geschwisterkind: 1 (ja), 0 (nein)</p>
|
|
|
<p><input type="submit" name="gesendet">
|
|
|
<input type="reset"></p>
|
|
|
</form>
|
|
Wie zu sehen ist, kann bei diesem Type auch auf die Festlegung verzichtet werden. |
|
Hier ist das Eingabefeld <input type=“text“ …> stark vertreten, weil es um die Erfassung von Daten für einen Datenbankeintrag geht. Es entstehen Eingabefelder für eine Eingabemaske. Die mit obigen Befehlen entstehende ist in Abschnitt 2.6 angegeben. |
text |
Mit dem Input type submit wird das Formular abgesendet und die eingegebenen Daten werden an die mit dem action-Attribut angegebene URL übertragen. Die Eigenschaft name wird benötigt, um abzufragen, ob das Formular bereits gesendet wurde (vgl. Funktion isset() in Abschnitt 2.6.2). |
submit |
Der Input type reset gibt die Möglichkeit, die Einträge in die Eingabefelder auf den Anfangswert zurückzusetzen. |
reset |
Bleibt noch der Input type radio, der in Abschnitt 2.7 benötigt wird. Er gibt die Möglichkeit, auf einfache Weise ein Auswahlmenü zu erstellen. Mit <input type='radio' name='auswahl‘> wird es angefordert. Mit dem Attribut name erhält es die Bezeichnung auswahl. Damit wird im weiteren Verlauf geprüft, ob wirklich eine Auswahl für den zu löschenden Datensatz getroffen wurde. Vgl. Abschnitt 2.7 für den Zusammenhang. |
radio |
Der folgende Auszug aus dem Programm KiGaLoeschen_a.php (Abschnitt 4.1) zeigt, innerhalb einer Tabelle, den Aufbau des Auswahlmenüs. Die While-Schleife liest Zeile für Zeile ein, die Tabelle hat für jeden Datensatz eine Zeile und darin für jedes Attribut einen Spalte. |
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
echo "<tr><td><input type='radio' name='auswahl'"
|
|
|
. " value='" . $dsatz["KindID"] . "'></td>"
|
|
|
. "<td><center>" . $dsatz["KindID"] . "</td>"
|
|
|
. "<td>" . $dsatz["Name"] . "</td>"
|
|
|
. "<td>" . $dsatz["Vorname"] . "</td>"
|
|
|
. "<td><center>" . $dsatz["AdressID"] . "</td>"
|
|
|
. "<td><center>" . db_datum_aus($dsatz["Eintrittsdatum"])
|
|
|
. "</td>"
|
|
|
. "<td>" . db_datum_aus($dsatz["Geburtstag"]) . "</td>"
|
|
|
. "<td><center>" . $dsatz["GKindJN"] . "</td></tr>";
|
|
11.2 Zusammenspiel HTML und PHP |
|
Für Einsteiger ist es nicht einfach, das Zusammenspiel von HTML, PHP und JavaScript zu verstehen. Deshalb hier ein Beispiel mit HTML und PHP aus den Aufgaben von Kapitel 4. Es handelt sich um das PHP-Programm KiGaTabelle.php, das mit Hilfe eines SQL-Befehls die Daten aller Kinder des Kindergartens aus der Datenbank erfasst und in einer Tabelle auf der Webseite ausgibt. |
|
kindergarten ist die Bezeichnung der Demo-Datenbank, die in Kapitel 2 vorgestellt wird. KiGa als Kürzel für Kindergarten wird dabei einige Male als Teil der Bezeichnung von PHP-Programmen verwendet. |
|
Die Dateien dieser Programme haben das Suffix php, hier also KiGaTabelle.php. Nur wenn es sich um reine HTML-Dateien handelt, so wie unten beim Beispiel Kindergarten für die Leitseite, ist das Suffix html. Hier also kindergarten.html. Das Programm ist in einem <html>-Container untergebracht, weshalb es mit <html> beginnt und mit </html> endet. Vgl. die folgende Abbildung. Da hier eine Tabelle für die Ausgabe gefordert ist, folgt – noch im HTML-Teil der Beginn der Tabellendefinition bis einschließlich der Festlegung der Spaltenüberschriften. |
|
Danach kommt der dynamische Teil, das PHP-Programm. Es startet mit <?php und endet mit ?>. In ihm wird zuerst die Anmeldung an die Datenbank ($con), die Speicherung des SQL-Befehls in eine Variable ($sql) und das Ausführen der Abfrage sowie das Speichern des Abfrageergebnisses ($res) realisiert. |
<?php
?> |
Danach wird dieses Ergebnis Zeile für Zeile in eine Tabellenstruktur geschrieben. Dies geschieht mit dem PHP-Befehl echo für die Ausgabe auf dem Bildschirm. Mit dem Schließen der Variablen $res und $con endet der dynamische Teil, d.h. das PHP-Programm. Der folgende Befehl schließt die Tabellendefinition, danach werden der <body>-Container und der <html>-Container geschlossen. Das sollte den grundsätzlichen Aufbau solcher Dateien deutlich machen, weiteres findet sich in Kapitel 4 in den Aufgabenlösungen. |
|

|
|
Abbildung 11.2-1: PHP-Programm KiGaTabelle.php |
|
KiGa steht für Kindergarten. |
|
Näheres zu diesem Programm findet sich in Abschnitt 4.1. |
|
12 Etwas PHP- Vom Web zur Datenbank |
|
Hier eine Kurzdarstellung der Techniken, mit denen eine Webseite mittels PHP mit der Datenbank verknüpft wird. Das betrifft i.w. Techniken, die dazu dienen, eine Webseite mit der Datenbank zu verbinden, so dass die Webseite als grafische Bedienoberfläche (Graphical User Interfac; GUI) dienen kann. |
|
Für eine Einführung in PHP vgl. |
|
- Theis, Thomas: Einstieg in PHP 8 und MySQL. Ideal für Programiereinsteiger (15. Auflage). Bonn 2023 (Rheinwerk-Verlag)
|
|
Das hier im Mittelpunkt stehende Thema wird dort in Kapitel 3 vorgestellt. Für einen Gesamtüberblick vgl. |
|
- Wenz, Christian und Hauser, Tobias: PHP 8 und MySQL. Das umfassende Handbuch (4. Auflage). Bonn 2021 (Rheinwerk-Verlag)
|
|
Hier wird das Thema Datenbankzugriff mit MySQL in Kapitel 20 behandelt. |
|
Die Webseite zu PHP mit allen Informationen zur Sprache und zu Releases ist |
|
|
|
|
Dort findet sich auch das offizielle Handbuch zu PHP. |
|
|
|
12.1 Zwei Klassen - mysqli und mysqli_result |
|
Für den Datenbankzugriff wird zuerst die Klasse mysqli benötigt. Vgl. für eine umfassende Beschreibung das PHP-Handbuch, insbesondere: |
mysqli |
|
https://www.php.net/manual/de/class.mysqli.php
|
|
Wir benötigen hier das Attribut $affected_rows. In diesem steht nach einer Datenbankabfrage die Anzahl der gefundenen Datensätze. Damit kann z.B. die Situation abgefangen werden, dass es gar keine Treffer gibt. |
|
Folgende Methoden werden in den obigen Programmen benötigt: |
|
- mysqli__connect() für den Aufbau der Verbindung zur Datenbank auf dem SQL-Server. Die vier wichtigsten Parameter sind Servername, Benutzername, Passwort und Datenbankbezeichnung.
- mysqli::close für das Schließen einer zuvor geöffneten Datenbankverbindung. Konkret wird die Verbindung geschlossen sowie die dafür genutzten Ressourcen und Speicher freigegeben.
- @new, um ein neues Objekt einer Klasse zu erstellen, z.B. mit $con = @new mysqli("localhost", "root", "", "KuReAr").
- mysqli::execute_query für das Vorbereiten einer SQL-Anweisung, das Binden der Parameter und das Ausführen der SQL-Anweisung auf der Datenbank. War die Abfrage erfolgreich, liefert sie eine Referenz auf ein Objekt der Klasse mysqli_result, die in der Variablen $res gespeichert wird. Z.B. so: $res = $con->execute_query($sql).
|
|
Die Klasse mysqli_result stellt das Ergebnis einer Datenbankabfrage dar. Eine umfassende Beschreibung findet sich hier: |
Mysqli_result |
|
https://www.php.net/manual/de/class.mysqli-result.php
|
|
Wir benötigen von dieser Klasse die Methode mysqli_result::fetch_assoc. Diese ruft die nächste Zeile einer Ergebnismenge (assoziatives Array) ab. |
|
12.2 Demo-Datenbank KuReAr |
|
Die weiteren Ausführungen stützen sich auf die Datenbank KuReAr (Kunden, Rechnungen, Artikel). Es handelt sich um eine verkürzte Fassung der Aufgabe aus Abschnitt 3.1. |
|
Textliche Notation |
|
Artikel (#ArtNr, Beschreibung, Preis) |
|
Kunden(#KuNr, Name, Vorname) |
|
RechKoepfe(#ReNr, ReDatum, KuNr) |
|
RechPos(#(PosNr, ReNr), ArtNr, Anzahl) |
|
|
|
Grafische Notation |
|
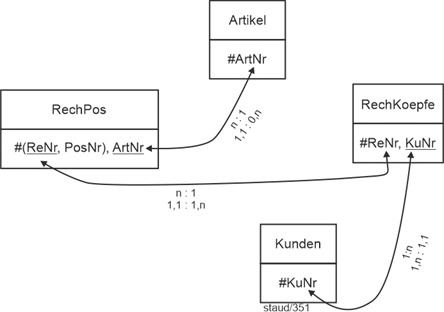
|
|
Abbildung 12.2-1: Demo-Datenbank KuReAr (Kunden – Rechnungen – Artikel) |
|
Zum Nachvollziehen: Befehle zum Einrichten und Befüllen der Datenbank |
|
Anmerkung: Diese Datenbank wurde mit MySQL/XAMPP eingerichtet. |
|
|
create database KuReAr default character set latin1 collate latin1_german1_ci;
|
|
Jetzt im phpMyAdmin-Verzeichnis der Datenbanken auf der linken Seite die neue Datenbank anwählen. Dann die folgenden Relationen in dieser Reihenfolge einrichten. |
|
|
create table artikel (ArtNr smallint(4), beschreibung varchar(10), preis decimal(7,2), primary key (ArtNr));
|
|
|
create table kunden (KuNr smallint(5), name char(10), vorname char(10), primary key (KuNr));
|
|
|
create table RechKoepfe (ReNr smallint(6), KuNr smallint(5), primary key (ReNr), ReDatum date, foreign key (KuNr) references kunden(KuNr));
|
|
|
create table RechPos (ReNr smallint(6), PosNr tinyint(3) unsigned, ArtNr smallint(4), anzahl smallint(2),
|
|
|
primary key (ReNr, PosNr),
|
|
|
foreign key (ArtNr) references artikel(ArtNR),
|
|
|
foreign key (ReNr) references RechKoepfe(ReNr));
|
|
Anschließend die Daten einfüllen: |
|
|
insert into kunden values
|
|
|
(1010, 'Anger', 'Albert'),
|
|
|
(1001, 'Bauer', 'Rita'),
|
|
|
(1009, 'Cäser', 'Filippa'),
|
|
|
(1002, 'Dussel', 'Ricco');
|
|
|
SELECT * FROM kunden
|
|
| KuNr |
name |
vorname |
| 1001 |
Bauer |
Rita |
| 1002 |
Dussel |
Ricco |
| 1009 |
Cäser |
Filippa |
| 1010 |
Anger |
Albert |
| |
|
insert into artikel values
|
|
|
(100, 'Gamer-PC', 2500.00),
|
|
|
(101, 'Büro-PC', 1200.00),
|
|
|
(102, 'Entwickler-PC', 3200.00),
|
|
|
(554, 'SmartPh', 330.00);
|
|
|
SELECT * FROM artikel
|
|
| ArtNr |
beschreibung |
preis |
| 100 |
Gamer-PC |
2500.00 |
| 101 |
Büro-PC |
1200.00 |
| 102 |
Entwickler |
3200.00 |
| 554 |
SmartPh |
330.00 |
| |
|
insert into rechkoepfe values
|
|
|
(23001, 1002, '2023-03-27'),
|
|
|
(23010, 1009, '2023-05-20'),
|
|
|
(23050, 1001, '2023-11-19'),
|
|
|
(23020, 1010, '2023-01-07');
|
|
|
SELECT * FROM rechkoepfe
|
|
| ReNr |
KuNr |
ReDatum |
| 23001 |
1002 |
2023-03-27 |
| 23010 |
1009 |
2023-05-20 |
| 23020 |
1010 |
2023-01-07 |
| 23050 |
1001 |
2023-11-19 |
| |
|
insert into rechpos values
|
|
|
(23001, 1, 101, 2),
|
|
|
(23001, 2, 554, 1),
|
|
|
(23010, 1, 101, 3),
|
|
|
(23050, 1, 102, 2),
|
|
|
(23050, 2, 101, 3);
|
|
|
SELECT * FROM rechpos
|
|
| ReNr |
PosNr |
ArtNr |
anzahl |
| 23001 |
1 |
101 |
2 |
| 23001 |
2 |
554 |
1 |
| 23010 |
1 |
101 |
3 |
| 23050 |
1 |
102 |
2 |
| 23050 |
2 |
101 |
3 |
| |
|
|
Zur Prüfung den gesamten Datenbestand in einer Tabelle: |
|
|
select ku.kunr as KNr, ku.name as Name, ku.vorname as VName,
|
|
|
rk.ReNr, rk.redatum as Datum,
|
|
|
rp.PosNr as PNr, rp.ArtNr, rp.anzahl as Anz,
|
|
|
ar.beschreibung as Beschr, ar.preis as Preis
|
|
|
from kunden ku, rechkoepfe rk, rechpos rp, artikel ar
|
|
|
where rk.kunr=ku.kunr and rk.renr=rp.renr
|
|
|
and rp.artnr=ar.artnr order by rk.renr, rp.posnr;
|
|
Datenbank KuReAr |
|
| KNr |
Name |
VName |
ReNr |
Datum |
PNr |
ArtNr |
Anz |
Beschr |
Preis |
| 1002 |
Dussel |
Ricco |
23001 |
2023-03-27 |
1 |
101 |
2 |
Büro-PC |
1200.00 |
| 1002 |
Dussel |
Ricco |
23001 |
2023-03-27 |
2 |
554 |
1 |
SmartPh |
330.00 |
| 1009 |
Cäser |
Filippa |
23010 |
2023-05-20 |
1 |
101 |
3 |
Büro-PC |
1200.00 |
| 1001 |
Bauer |
Rita |
23050 |
2023-11-19 |
1 |
102 |
2 |
Entwickler |
3200.00 |
| 1001 |
Bauer |
Rita |
23050 |
2023-11-19 |
2 |
101 |
3 |
Büro-PC |
1200.00 |
| |
12.3 Verknüpfung WebSeite Datenbank |
|
Im ersten Teil des Programms abfrage002.php wird die Relation Kunden über eine Webanforderung abgefragt und angezeigt. Zuerst durch einfaches Anzeigen der Datensätze, dann in Form einer Tabelle. Hier das Programm mit Erläuterungen. |
|
Vor dem PHP-Teil |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Tabellen mit Kunden und Rechnungsköpfe</title>
|
|
|
<link rel="stylesheet" type="text/css" href="KuReAr.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<p><br>Einfache Ausgabe der Relation <i>Kunden</i>:</p>
|
|
PHP-Teil 1 – Einfache Ausgabe der Daten |
|
Der Verbindungsaufbau wird mit der Funktion mysqli_connect() realisiert. Die vier wichtigsten Parameter sind |
|
- Servername
- Benutzername
- Passwort
- Datenbankbezeichnung
|
|
New ist der Konstruktor der Klasse mySQLi. Im unten stehenden Befehl liefert er eine Referenz, die in der Variablen $con gespeichert wird. |
|
|
<?php
|
|
|
$con = @new mysqli("localhost", "root", "", "KuReAr");
|
|
Das At-Sign @ wird hier Silence-Operator genannt. Er dient vor der Bezeichnung einer Funktion dazu, Fehlermeldungen von Funktionen zu unterdrücken. Dies dient der Abwehr von Hackerangriffen (vgl. [Theis 2023, S. 187]). |
|
Durch eine SQL-Abfrage wird die Erfassung der Daten vorbereitet: |
|
|
$sql = "SELECT * FROM kunden";
|
|
Mit dem Befehl |
|
|
$res = $con->execute_query($sql)
|
|
wird die SQL-Abfrage auf der Datenbank ausgeführt und das Ergebnis in die Variable $res gespielt. Mit der Methode fetch_assoc() können die Datensätze gelesen werden. Die Daten stehen als assoziatives Feld zur Verfügung. DBFeldName ist der Schlüssel, in DBFeldWert steht der zugehörige Wert. |
|
Für die Abfrage der Datensätze kann eine WHILE-Schleife verwendet werden. Der mögliche Fehler, dass die Treffermenge leer ist, wird durch entsprechende Programmkonstrukte abgefangen. Vgl. die Beispiele unten. Der Aufruf erfolgt durch $res (ressource). Jeder Datensatz wird in die Variable $dsatz geschrieben. |
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
echo "Kundennummer: " . $dsatz["KuNr"] . "; "
|
|
|
. "Name: " . $dsatz["name"] . "; "
|
|
|
. "Vorname: " . $dsatz["vorname"] . "<br><br>";
|
|
Damit werden die Datensätze einzeln nacheinander ausgegeben. Mit $res->close() und $con->close() werden abschließend die Ressourcen freigegeben und die Verbindung geschlossen. |
|
|
$res->close();
|
|
|
$con->close();//Schließen der Verbindung, Freigabe Ressourcen
|
|
|
?>
|
|
Damit entsteht folgende sehr schlichte Ausgabe der Daten der Relation. |
|
|
Kundennummer: 1001; Name: Bauer; Vorname: Rita
|
|
|
Kundennummer: 1002; Name: Dussel; Vorname: Ricco
|
|
|
Kundennummer: 1009; Name: Cäser; Vorname: Filippa
|
|
|
Kundennummer: 1010; Name: Anger; Vorname: Alber
|
|
PHP-Teil 2 – Ausgabe der Daten in einer Tabelle |
|
Nun die zweite Ausgabe, wieder in abfrage002.php realisiert. Jetzt werden dieselben Daten in einer Tabelle ausgegeben. Die Tabelle wird mit HTML erstellt und vor dem PHP-Abschnitt begonnen: |
|
|
<table>
|
|
|
<caption><br>Ausgabe als Tabelle</caption>
|
|
|
<thead>
|
|
|
<th>KuNr</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
</thead>
|
|
Es folgt der PHP-Abschnitt mit der Anwahl der Datenbank und der Durchführung und Umsetzung der SQL-Abfrage. |
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql ="select * from kunden";
|
|
|
$res = $con->execute_query($sql);
|
|
Dann werden in einer While-Schleife die HTML-Befehle für die Tabellenstruktur und die Daten aus der assoziativen Variablen $dsatz ausgegeben. |
|
|
while($dsatz = $res->fetch_assoc())//Solange Datensätze vorliegen
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><left>" . $dsatz["KuNr"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["name"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["vorname"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
Nach dem PHP-Abschnitt folgen die restlichen Befehle in HTML-Notation. |
|
|
</table>
|
|
|
</body>
|
|
|
</html>
|
|
Das Programm führt zur folgenden tabellarischen Ausgabe. |
|
| KuNr |
Name |
Vorname |
| 1001 |
Bauer |
Rita |
| 1002 |
Dussel |
Ricco |
| 1009 |
Cäser |
Filippa |
| 1010 |
Anger |
Albert |
| |
Der Übersichtlichkeit halber hier die Datei abfrage002.php am Stück und ohne Anmerkungen. Die PHP-Programme sind fett gesetzt. Dadurch wird das Zusammenspiel zwischen den originalen HTML-Abschnitten, den PHP- und den von PHP erzeugten deutlich. |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Tabellen mit Kunden und Rechnungsköpfe</title>
|
|
|
<link rel="stylesheet" type="text/css" href="KuReAr.css">
|
|
|
</head>
|
|
|
<body>
|
|
|
<p><br>Einfache Ausgabe der Relation <i>Kunden</i>:</p>
|
|
|
|
|
|
<?php
|
|
|
$con = @new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql = "SELECT * FROM kunden";
|
|
|
$res = $con->execute_query($sql);
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
echo "Kundennummer: " . $dsatz["KuNr"] . "; "
|
|
|
. "Name: " . $dsatz["name"] . "; "
|
|
|
. "Vorname: " . $dsatz["vorname"] . "<br>";
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
<table>
|
|
|
<caption><br>Ausgabe als Tabelle:</caption>
|
|
|
<thead>
|
|
|
<th>KuNr</th>
|
|
|
<th>Name</th>
|
|
|
<th>Vorname</th>
|
|
|
</thead>
|
|
|
|
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql ="select * from kunden";
|
|
|
$res = $con->execute_query($sql);
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><left>" . $dsatz["KuNr"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["name"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["vorname"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table></body></html>
|
|
12.4 Weitere Beispiele |
|
Obiges reicht zum Einstieg und für das Einrichten von Web-Abfragen auf mySQL-Datenbanken mit einem lokalen Server. Die folgenden Beispiele im Programm abfrage002.php deuten den weiteren Weg an, wenn es um Spaltenüberschriften, um nicht-triviale Abfragen und um verknüpfte Relationen geht. |
Datei abfrage002.php |
Zuerst das Programm mit Anmerkungen: |
|
|
<!DOCTYPE html>
|
|
|
<html lang="de">
|
|
|
<head>
|
|
|
<meta charset="utf-8">
|
|
|
<title>Tabellen mit Kunden und Rechnungsköpfen</title>
|
|
Hier wird auch eine Stylesheet-Datei eingesetzt. Sie isst unten angegeben. |
|
|
<link rel="stylesheet" type="text/css" href="KuReAr.css">
|
|
|
</head>
|
|
|
<body>
|
|
Die erste Tabelle soll Spaltenüberschriften erhalten. Sie wird hier gestartet. Da es sich um eine tabellarische Ausgabe handelt, kommt nach einem erklärenden Text die Tabellendeklaration. |
|
|
<p class="text_1"><br>Relation Kunden - mit
|
|
|
Spaltenamp;uuml;berschriften:</p>
|
|
|
<table>
|
|
|
<caption class="text_2">Relation Kunden</caption>
|
|
|
<thead>
|
|
|
<th>Kundennummer</th>
|
|
|
<th>Kundenname</th>
|
|
|
<th>Kundenvorname</th>
|
|
|
</thead>
|
|
Es folgen Verbindungsaufbau und Erfassen der SQL-Abfrage in der Variablen $sql. Dabei wurden Spaltenüberschriften verwendet. Geschieht dies, müssen für die Funktion fetch_assoc() die Spaltenüberschriften verwendet werden. Ansonsten gibt es eine Fehlermeldung. |
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql ="select kunr as Kundennummer, name as Kundenname,
|
|
|
vorname as Kundenvorname from kunden";
|
|
|
$res = $con->execute_query($sql);
|
|
Mit $res->num_rows wird die Anzahl der gefundenen Datensätze ermittelt. Falls die Trefferzahl Null ist, wird eine entsprechende Meldung ausgegeben. |
|
|
if($res->num_rows == 0) echo "Keine Ergebnisse";
|
|
Die folgende While-Schleife wird in dem Fall gar nicht begonnen. |
|
Die While-Schleife startet nur, falls eine Zuordnung eines Datensatzes in die Variable $dsatz erfolgen kann. Nur dann ist der Gesamtausdruck wahr. |
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
Sobald Spaltenüberschriften vergeben werden, müssen diese als Schlüssel des assoziativen Feldes genommen werden. Die ursprünglichen Attributsbezeichnungen sind dann nicht mehr einsetzbar. |
|
|
echo "<td><left>" . $dsatz["Kundennummer"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Kundenname"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Kundenvorname"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
|
|
|
?>
|
|
|
</table>
|
|
Obiges erzeugt folgende Tabelle zu den Kunden - mit Spaltenüberschriften: |
|
Relation Kunden |
|
| Kundennummer |
Kundenname |
Kundenvorname |
| 1001 |
Bauer |
Rita |
| 1002 |
Dussel |
Ricco |
| 1009 |
Cäser |
Filippa |
| 1010 |
Anger |
Albert |
| |
Datei KuReAr.css mit den Stylesheets
|
|
|
h1 { font-size:16pt; font-weight: bold; text-align: left;
|
|
|
font-family: Calibri, Arial, sans-serif; color: blue;
|
|
|
margin-bottom:10px; margin-right:0px; margin-top:5px;
|
|
|
margin-left:0px;}
|
|
|
p {color: black; font-family: Arial, sans-serif; margin-bottom:10px;
|
|
|
margin-right:10px; margin-top:10px; margin-left:10px;}
|
|
|
table {font-family: Arial, sans-serif;}
|
|
|
td {border: 1px solid black; vertical-align: middle;
|
|
|
text-align: left;padding: 3px}
|
|
|
thead {font-size: 10pt; color: black;
|
|
|
font-family: Arial, sans-serif;}
|
|
|
.text_1 { font-family: Arial, sans-serif; font-size:12pt;
|
|
|
color:red;}
|
|
|
.text_2 { font-family: Arial, sans-serif; font-size:14pt;
|
|
|
font-weight: bold;}
|
|
Maskierung im SQL-Befehl |
|
Nun ein Beispiel mit Maskierung im SQL-Befehl. Es sollen die Daten der Kinder ausgegeben werden, deren Namen mit A oder mit D beginnen. |
|
|
<p class="text_1"><br>Wie oben, jetzt mit Auswahl durch
|
|
|
Maskierung:</p>
|
|
|
<table>
|
|
|
<caption class="text_2">
|
|
|
Ausgewamp;auml;hlte Daten (B... or D...)</caption>
|
|
|
<thead>
|
|
|
<th>Kundennummer</th>
|
|
|
<th>Kundenname</th>
|
|
|
<th>Kundenvorname</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
Der Unterschied zu oben liegt in der SQL-Abfrage. Diese enthält in der Where-Klausel mit |
|
|
“… name like ‘A’ or name like ‘D’“
|
|
die Suchparameter. |
|
|
$sql ="select kunr as Kundennummer, name as Kundenname,
|
|
|
vorname as Kundenvorname from kunden
|
|
|
where name like 'A%' or name like 'D%'";
|
|
|
$res = $con->execute_query($sql);
|
|
|
if($res->num_rows ==0) echo "Keine Ergebnisse";
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><left>" . $dsatz["Kundennummer"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Kundenname"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Kundenvorname"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Obiges erzeugt folgende Tabelle, jetzt mit Auswahl durch Maskierung: |
|
Ausgewählte Daten (B … or D …) |
|
| Kundennummer |
Kundenname |
Kundenvorname |
| 1002 |
Dussel |
Ricco |
| 1010 |
Anger |
Albert |
| |
Zwei verknüpfte Relationen
|
|
Nun die Ausgabe zweier verknüpfter Relationen: Kunden und Rechnungsköpfe. Verknüpft wird über die Kundennummer (KuNr), die in der einen Relation Schlüssel und in der anderen Fremdschlüssel ist. |
|
Zuerst der HTML-Teil. Es sollen wieder Spaltenüberschriften ausgegeben werden. |
|
|
<p class="text_1"><br>Zwei verknamp;uuml;pfte Relationen (Kunden und RechKoepfe):</p>
|
|
|
<table>
|
|
|
<caption class="text_2">Kunden und Rechnungskamp;ouml;pfe</caption>
|
|
|
<thead>
|
|
|
<th>Kundennummer</th>
|
|
|
<th>Kundenname</th>
|
|
|
<th>Rechnungsdatum US</th>
|
|
|
<th>Rechnungsdatum Deutsch</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
include "zeit2.inc.php";
|
|
Die Datei zeit2.inc.php enthält u.a. die Funktion wandlung_e_d(), mit der unten das US-Datumsformat in das deutsche umgewandelt wird. Der Quellcode dieser Datei ist unten angegeben. |
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
Im SQL-Befehl muss die Verknüpfung durchgeführt werden: |
|
|
$sql ="select ku.kunr as Kundennummer, ku.name as Kundenname,
|
|
|
rk.renr as Rechnungsnummer, rk.ReDatum as RDatum
|
|
|
from rechkoepfe rk, kunden ku
|
|
|
where ku.kunr=rk.kunr";
|
|
|
$res = $con->execute_query($sql);
|
|
|
if($res->num_rows ==0) echo "Keine Ergebnisse";
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><left>" . $dsatz["Kundennummer"] . "</td>";
|
|
|
echo "<td><left>" . $dsatz["Kundenname"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Rechnungsnummer"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["RDatum"] . "</td>";
|
|
|
echo "<td><center>" . wandlung_e_d($dsatz["RDatum"]) . "</td>";
|
|
In der Ausgabetabelle werden die deutsche und die US-amerikanische Datumsversion verlangt. Für die deutsche Version muss die Funktion wandlung_e_d() aus der oben angeführten Datei zeit2.inc.php eingesetzt werden. |
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Hier die Tabelle mit den verknüpften Daten der beiden Relationen: |
|
Kunden und Rechnungsköpfe |
|
| Kundennummer |
Kundenname |
Rechnungsnummer |
Rechnungsdatum US |
Rechnungsdatum Deutsch |
| 1001 |
Bauer |
23050 |
2023-11-19 |
19.11.2023 |
| 1002 |
Dussel |
23001 |
2023-03-27 |
27.03.2023 |
| 1009 |
Cäser |
23010 |
2023-05-20 |
20.05.2023 |
| 1010 |
Anger |
23020 |
2023-01-07 |
07.01.2023 |
| |
Testen Sie Ihre „relationale Kompetenz“ und bestimmen Sie die Normalform obiger Relation. Das hilft dann auch, das relationale Design mit seinen Zerlegungen und dann wieder Verknüpfungen (in der Abfrage) zu verstehen. |
|
Wie man sehen kann, wird die Breite der Spalten durch die Spaltenüberschrift bestimmt. Dies kann natürlich auch anders gestaltet werden, wie die folgenden Beispiele zeigen. |
|
Programm zeit2.inc.php |
|
|
<?php
|
|
|
function db_datum_aus($db_datum)
|
|
|
{
|
|
|
$feld = mb_split("-", $db_datum);
|
|
|
$tag = intval($feld[2]);
|
|
|
$monat = intval($feld[1]);
|
|
|
$jahr = intval($feld[0]);
|
|
|
$ausgabe = sprintf("%'.02d.%'.02d.%'.04d", $tag, $monat, $jahr);
|
|
|
return $ausgabe;
|
|
|
}
|
|
|
function wandlung_e_d($db_datum)
|
|
|
{
|
|
|
$feld = mb_split("-", $db_datum);
|
|
|
$tag = intval($feld[2]);
|
|
|
$monat = intval($feld[1]);
|
|
|
$jahr = intval($feld[0]);
|
|
|
$ausgabe = sprintf("%'.02d.%'.02d.%'.04d", $tag, $monat, $jahr);
|
|
|
return $ausgabe;
|
|
|
}
|
|
|
?>
|
|
Drei verknüpfte Relationen in einer Tabelle |
|
Die folgende Tabelle führt die Daten zu Rechnungsköpfen, Rechnungspositionen und Kunden zusammen. Außerdem werden die Spalten enger gehalten. |
|
Weiter im Programm: |
|
|
<p class="text_1"><br>Drei verknamp;uuml;pfte Relationen<br>(Kunden, RechKoepfe und RechPos):</p>
|
|
|
<table>
|
|
|
<caption class="text_2">Kunden, Rechnungskamp;ouml;pfe und
|
|
|
-positionen</caption>
|
|
|
<thead>
|
|
|
<th>KuNr</th>
|
|
|
<th>KuName</th>
|
|
|
<th>RNr</th>
|
|
|
<th>RechnDatum</th>
|
|
|
<th>PosNr</th>
|
|
|
<th>ArtNr</th>
|
|
|
<th>Anzahl</th>
|
|
Um die Spalten enger zu halten, wurden oben die Spaltenüberschriften kürzer gefasst. |
|
|
</thead>
|
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql ="select ku.kunr, ku.name, rk.renr, rk.ReDatum,
|
|
|
rp.PosNr as Position, rp.ArtNr as Artikel,
|
|
|
rp.anzahl as Anzahl
|
|
|
from rechkoepfe rk, kunden ku, rechpos as rp
|
|
|
where ku.kunr=rk.kunr and rk.renr=rp.renr";
|
|
|
$res = $con->execute_query($sql);
|
|
|
if($res->num_rows ==0) echo "Keine Ergebnisse";
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
?>";
|
|
|
}echo "<tr>";
|
|
|
echo "<td><center>" . $dsatz["kunr"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["name"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["renr"] . "</td>";
|
|
|
echo "<td><center>" . wandlung_e_d($dsatz["ReDatum"]) . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Position"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Artikel"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Anzahl"] . "</td>";
|
|
|
echo "</tr
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Hier die damit erzeugte Tabelle: |
|
Kunden, Rechnungsköpfe und -positionen |
|
| KuNr |
KuName |
RNr |
RechnDatum |
PosNr |
ArtNr |
Anzahl |
| 1001 |
Bauer |
23050 |
19.11.2023 |
1 |
102 |
2 |
| 1001 |
Bauer |
23050 |
19.11.2023 |
2 |
101 |
3 |
| 1002 |
Dussel |
23001 |
27.03.2023 |
1 |
101 |
2 |
| 1002 |
Dussel |
23001 |
27.03.2023 |
2 |
554 |
1 |
| 1009 |
Cäser |
23010 |
20.05.2023 |
1 |
101 |
3 |
| |
Testen Sie Ihre „relationale Kompetenz“ und bestimmen Sie die Normalform obiger Relation. Das hilft dann auch, das relationale Design mit seinen Zerlegungen und dann wieder Verknüpfungen (in der Abfrage) zu verstehen. |
|
Die gesamte Datenbank in einer Tabelle |
|
Die folgende Tabelle könnte die Datengrundlage für die Erstellung von Rechnungen sein, da sie die Informationen zu Rechnungsköpfen, Rechnungspositionen, Kunden und Artikeln zusammenführt. |
|
In einem korrekt erstellten Datenmodell sind alle Relationen in looser Kopplung, d.h. insgesamt miteinander verbunden. Dies wird hier genutzt, um die Verknüpfung über die vier Relationen zu zeigen und die dabei entstehenden Tupel in eine einzige Tabelle zu schreiben. |
|
Weiter im Programm: |
|
|
<p class="text_1"><br>Und jetzt alle vier Relationen:</p>
|
|
|
<table>
|
|
|
<caption class="text_2">Die gesamte Datenbank:
|
|
|
Kunden - Rechnungen - Artikel</caption>
|
|
|
<thead>
|
|
|
<th>KuNr</th>
|
|
|
<th>KuName</th>
|
|
|
<th>ReNr</th>
|
|
|
<th>RechnDatum</th>
|
|
|
<th>PosNr</th>
|
|
|
<th>ArtNr</th>
|
|
|
<th>Beschreibung</th>
|
|
|
<th>Preis</th>
|
|
|
<th>Anzahl</th>
|
|
|
</thead>
|
|
|
<?php
|
|
|
$con = new mysqli("localhost", "root", "", "KuReAr");
|
|
|
$sql ="select ku.kunr as KuNr, ku.name as KuName,
rk.renr as Rechnungsnr, rk.ReDatum as RDatum,
rp.PosNr as Position, rp.ArtNr as Artikel,
|
|
|
ar.beschreibung as Beschreibung, ar.preis as Preis,
rp.anzahl as Anzahl
|
|
|
from rechkoepfe rk, kunden ku, rechpos as rp, artikel as ar
|
|
|
where
ku.kunr=rk.kunr and rk.renr=rp.renr and rp.artnr=ar.artnr";
|
|
Mit obiger Zeile werden die notwendigen Joins durchgeführt. |
|
|
$res = $con->execute_query($sql);
|
|
|
if($res->num_rows ==0) echo "Keine Ergebnisse";
|
|
|
while($dsatz = $res->fetch_assoc())
|
|
|
{
|
|
|
echo "<tr>";
|
|
|
echo "<td><center>" . $dsatz["KuNr"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["KuName"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Rechnungsnr"] . "</td>";
|
|
|
echo "<td><center>" . wandlung_e_d($dsatz["RDatum"]) . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Position"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Artikel"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Beschreibung"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Preis"] . "</td>";
|
|
|
echo "<td><center>" . $dsatz["Anzahl"] . "</td>";
|
|
|
echo "</tr>";
|
|
|
}
|
|
|
$res->close();
|
|
|
$con->close();
|
|
|
?>
|
|
|
</table>
|
|
Die damit erzeugte Tabelle: |
|
Rechnungen, Kunden, Artikel |
|
| KuNr |
KuName |
ReNr |
RechnDatum |
PosNr |
ArtNr |
Beschreibung |
Preis |
Anzahl |
| 1002 |
Dussel |
23001 |
27.03.2023 |
1 |
101 |
Büro-PC |
1200.00 |
2 |
| 1009 |
Cäser |
23010 |
20.05.2023 |
1 |
101 |
Büro-PC |
1200.00 |
3 |
| 1001 |
Bauer |
23050 |
19.11.2023 |
2 |
101 |
Büro-PC |
1200.00 |
3 |
| 1001 |
Bauer |
23050 |
19.11.2023 |
1 |
102 |
Entwickler |
3200.00 |
2 |
| 1002 |
Dussel |
23001 |
27.03.2023 |
2 |
554 |
SmartPh |
330.00 |
1 |
| |
Das Programm schließt mit den folgenden zwei Befehlen. |
|
|
</body>
|
|
|
</html>
|
|
Testen Sie Ihre „relationale Kompetenz“ und bestimmen Sie die Normalform obiger Relation. Das hilft dann auch, das relationale Design mit seinen Zerlegungen und dann wieder Verknüpfungen (in der Abfrage) zu verstehen. |
|
|
|
13 Literatur |
|
O |
|
OMG 2017
Object Management Group (OMG): OMG Unified Modeling Language (OMG UML). Version 2.5.1 December 2017. (OMG Document Number: formal/17-12-05. www.omg.org/spec/UML/About-UML/) |
|
P |
|
Prata 2005
Prata, Stephen: C++. Primer Plus (Fifth Edition). Indianapolis 2005 |
|
Rumbaugh, Jacobson und Booch 2005
Rumbaugh, James; Jacobson, Ivar; Booch, Grady: The Unified Modeling Language Reference Manual. Second Edition. Boston u.a. 2005 |
|
S |
|
Staud 2019
Staud, Josef: Unternehmensmodellierung – Objektorientierte Theorie und Praxis mit UML 2.5. (2. Auflage). Berlin u.a. 2019 (Springer Gabler) |
|
Staud 2021
Staud, Josef Ludwig: Relationale Datenbanken. Grundlagen, Modellierung, Speicherung, Alternativen. 2. Auflage 2021. Verlag tredition GmbH,
Paperback: 978-3-347-35883-6
Hardcover: 978-3-347-35884-3
E-Book: 978-3-347-35885-0 |
|
Staud 2022
Staud, Josef: Semantische Datenmodellierung für effiziente Datenbanken: ERM, SERM, SAP-SERM. (in Arbeit, Stand 2022/02). Vorab: www.staud.info/erm2/er_t_1.htm |
|
T |
|
Theis 2023
Theis, Thomas: Einstieg in PHP 8 und MySQL. Ideal für Programiereinsteiger (15. Auflage). Bonn 2023 (Rheinwerk-Verlag) |
|
W |
|
Wenz und Hauser 2021
Wenz, Christian und Hauser, Tobias: PHP 8 und MySQL. Das umfassende Handbuch (4. Auflage). Bonn 2021 (Rheinwerk-Verlag) |
|
Wolf 2023
Wolf, Jürgen: HTML und CSS. Das umfassende Handbuch. (5. Auflage). Bonn 2023 (Rheinwerk-Verlag) |
|
|
|
|
|
|